
短文本先验模型判定技术研究与实践*
2017-10-17 07:19粟栗戴晶安宁宇张峰
电信工程技术与标准化 2017年10期
粟栗,戴晶,安宁宇,张峰
(1 中国移动通信有限公司研究院,北京 100053; 2 中国移动集团公司信息安全管理与运行中心,北京 100053)
短文本先验模型判定技术研究与实践*
粟栗1,戴晶2,安宁宇1,张峰1
(1 中国移动通信有限公司研究院,北京 100053; 2 中国移动集团公司信息安全管理与运行中心,北京 100053)
为了应对违规信息的快速、多样化发展,运营商对违规信息的治理手段也需要与时俱进,需要对违规信息的覆盖更全面、判定更精准。基于以上目标,本文提出了一种基于先验模型的短文本违规信息识别与过滤方法。该方法从文字特征层、关键词模式层、内容特征层3个层面对于违规信息进行分析,最后利用综合分析判定层结合之前的训练对短信进行最终的判定。我们在保证较高违规信息判定准确率的前提下,可以大幅度提高违规信息判定的召回率,较好的解决目前违规信息判定问题,为运营商节省大量人力。
违规信息过滤;先验模型;文字特征;关键词模式;内容特征
目前随着运营商对信息治理的逐步深入,治理手段为多样化组合。目前的治理措施包括用户黑名单、关键词正则策略、用户发送行为判定、相同与近似内容自动比对等技术。上述治理方法中,用户黑名单、相同与近似内容比对的技术有很高的准确率,但分析范围有限;关键词正则策略、用户发送行为判定等技术收集的疑似信息范围较广,但仍有较高的误判率,需要人工审核进行最终判定。
为了尽量多的避免违规信息骚扰用户,一般在人工审核负担运行的范围内,尽量多设置策略进行疑似数据采集。因此,若能有方法减少疑似信息中的误判,将利于减轻人力负担。
本文提出一种4层先验模型,基于文字特征、关键词模式、内容特征进行训练,能自动生成4层违规信息综合判定模型,能对疑似数据中的正常信息、违规信息进行有效判定,能达到判定准确率98%以上,召回率达到60%以上。使用该模型能对数据进行二次判定筛选,进一步提升系统的自动化能力。
1 现有判定技术分析
目前对于违规信息的主要发现技术有4类。
(1)关键词正则表达式过滤。通过关键词组合对短信进行筛选,发现违规信息。
(2)基于用户的发送行为进行筛选。该方法通过设定单位时间内发送量的阈值,对可能发送违规信息的号码进行判定;或基于用户发送对象的离散程度、用户收发短信的数量比等特征进行判定。
(3)重复或近似信息比对。通过Simhash、Jaccard等方法对文本信息内容进行分析,与已有的违规信息样本/模板进行比对,发现可疑信息。
(4)基于内容特征的机器学习算法。例如贝叶斯、Word2Vec等方法进行训练与识别。
从能力上考虑,技术1、2都能发现大量的信息,且运行效率较高,但面临的最大的困扰是误判率较高,带来较多人工审核工作,效率较低。技术3具有非常高的精度,但一方面判定效率较低,另一方面对已有的判定库的依赖性大,样本收集有一定难度,可作为二次判定或辅助判定方法。技术4则具备较高的准确率和覆盖率,但训练复杂、效率较低。
例如这样一条关键词策略:(发票|税票)&(增值|普通|6%|17%)&(电话|联系)。当该策略植入系统中,系统即抓取符合条件的信息并判定可能为诈骗短信。
例1,“我司供应各类普通、增值发票:建筑.工程.商业.广告.服务(收0.5%)电话:139xxxxxxxx王生”。
例2,“公司住宿发票要求:(1)必须是增值税发票。(2)必须包含纳税人识别号、公司电话。(3)专票需抵扣联。”
例1为垃圾短信,例2为正常短信。
虽然通过上述4类技术手段的叠加可以取得一定的优化效果,但仍然较难改变使用技术1、2的误判问题。
2 先验模型技术原理
本文提出的先验模型是基于现有的违规信息与正常信息的差异度区分集和组建的数学模型。
2.1 算法基本原理
本文提出一种基于已有人工判定结果进行学习的先验模型,针对违规信息进行判定有覆盖面广且准确的效果,能极大提升违规信息的判定能力。设计“违规信息判定先验模型”包括4个层次:文字特征分析层、关键词模式匹配层、内容特征精确判定层以及综合分析判定层。
对各层次的功能说明如下。
2.1.1 文字特征分析层
本提案提出基于短信内容的构成特点,对已分类文本进行特征分析,形成包含长度、标点符号分布、特殊符号占比的三维违规信息文本特征模型。基于模型判定待检测内容是否具备违规信息特征。该功能用于对部分不包含关键字特征(如新型短信),但具有明显广告等违规特征的短信进行判定。
例1,“就这农卡; 6.2.2.8 4.8.x.x.x. 0 7.8.x.x.0 0 7.1.4. 杨 xx:”。
例2,“想-了-解-某-人-的-说-话-和-短-讯-吗; l 5053l 8xxxx潘总”。
2.1.2 关键词模式匹配层
首先依据已有的分类短信进行学习,构建关键词模式库,然后基于模式库对包含关键词的文本进行判定。本提案提出一种基于正则的有序、带有权重的违规信息关键词分析模型,对每类关键词序列形成动态权重,用于带有关键词的短信内容分析。
该功能适用于对包含关键词的文本进行疑似度确认。下两条短信都是命中相同的关键字,但通过本方案提出动态关键词模式库,判定的疑似度可能不一。
例1,“我司供应各类发票:建筑.工程.商业.广告.服务(收0.5%)电话:139xxxx8371王生”。
例2,“您好!电话:139xxxx8371王生。我司供应:建筑.工程.商业.广告.服务.发票(收0.5%)”。
2.1.3 内容特征精准判定层
该部分首先通过学习建立一个库,包含违规信息中的电话、qq、网址等信息,一旦在被检测信息中命中相关信息,则进行判定。同时,该层还包含语义倾向性分析功能,具有正向或负向关联分析功能。
例1,“恭喜您中奖啦,领奖详细信息请联系4006723xxxx”。判定结果:命中号码,且判定为正向(与原意一致)。
例2,“4006723xxxx是诈骗电话”。判定结果:命中号码,且判定为负向(与原意相反)。
2.1.4 综合分析判定层
将前3层的判定规则进行训练,确定判定流程,得到最优的判定结果。
2.2 系统架构与算法原理
对系统架构设计如图1所示。系统包含基于已有信息分析、学习、建模的过程,然后基于建立的模型进行违规信息判定。
模型分析算法模块基于正常样本学习库、违规样本学习库、关键字库进行学习与分析形成先验模型。
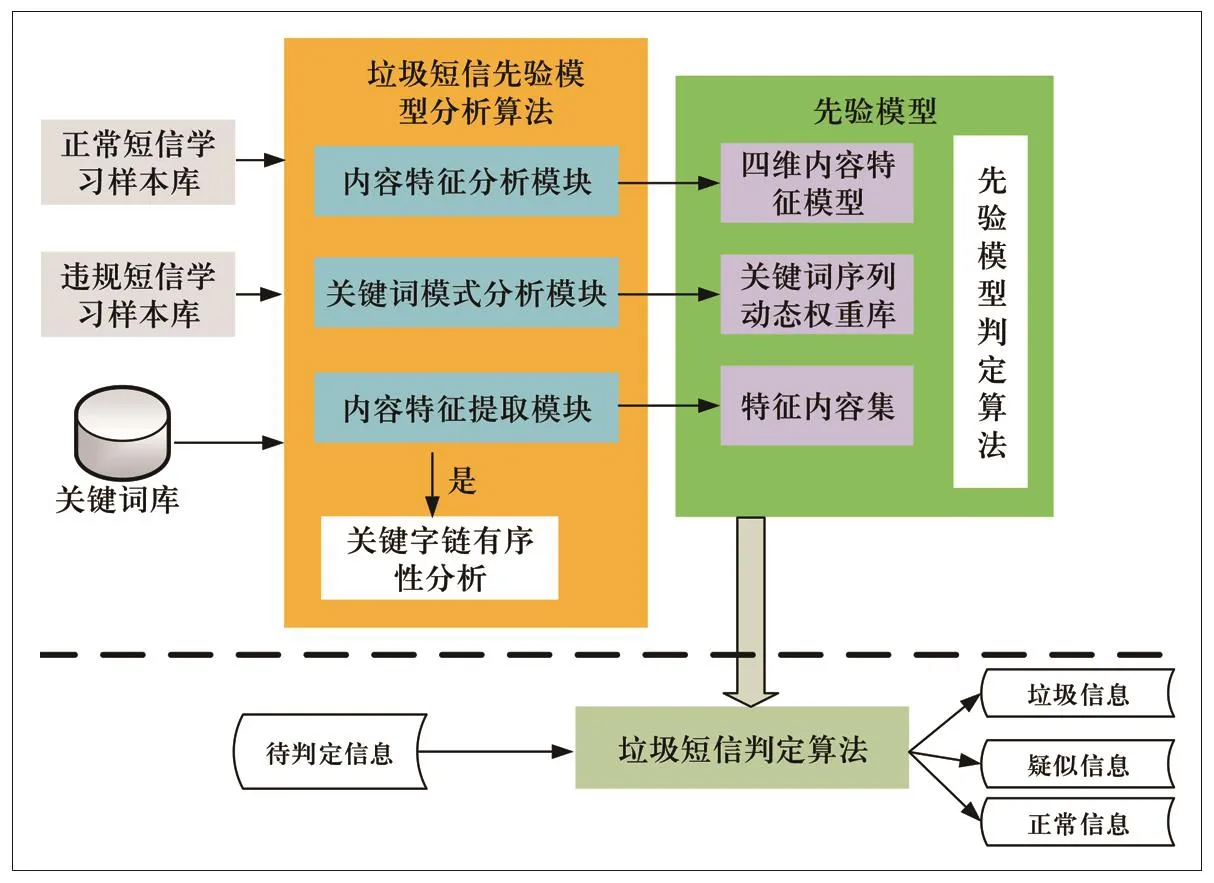
图1 违规信息判定总体架构
2.2.1 内容特征模型算法
设定四维向量:CV=[长度阈值TL,特殊符号数量TM,符号占比Tr,符号间隔均值TS]为内容特征向量表示。
CV的学习过程为基于正常短信样本库、违规短信样本库分析如下指标:长度特征、特殊符号数量、符号占比、符号间隔均值信息。典型表示如下。
2.2.1.1 长度分布特征
在先验模型中,短信的长度阈值(TL)是一个重要的判定手段。根据经验判断,违规信息为了有一定的信息量输出,必然要达到一定的长度,而很多正常短信则会很短。例如聊天类短信“呵呵”,“晚安”。因此我们假定L<TL的短信判定为正常短信;L>TL的短信判定为疑似短信。其中L为判定短信的长度。
2.2.1.2 特殊符号个数分析
首先定义特殊符号训练集,然后基于训练样本分析正常短信样本、违规短信样本中的特殊符号个数。一般来说,出现较多特殊符号的信息为违规信息居多,但也有一个常见的表情符号(如O(∩_∩)O~ (=@__@=)(*^__^*))出现在正常短信中。
例1,“↘代↘验↘↘開↘後↘↘發↘付↘↘嘌↘款↘I39-188-2xxxx何琳”。
例2,“开★┋山东省┋☆┋记账┋★┋増☆值┋☆┋禾兑★据┋188-6681-xxxx王财务”。
通过数据训练,将特殊符号分为正常类型和违规类型,并通过训练确定阈值TM为违规信息判定标记参考。
2.2.1.3 符号占比分析
在部分违规信息中,还使用正常的标点符号进行干扰,有必要对标点符号在内容中的占比进行分析。符号占比大的信息,违规信息的可能性较大;反之则可判定为正常短信。最终确定阈值Tr为违规信息符号占比参考值。
例 1,“^各, 种 ,發 :票 . 可、 开、 ① 363285⑶xxx 何小姐”。
例2,“*有{稅}{嘌}代开I3652444918 黄生”。
2.2.1.4 符号间隔位置分析
一般来说,短信中的符号出现存在一定间隔,而部分违规信息中特殊字符出现呈较为明显的间隔特性,通过训练可确定阈值TS为违规信息判定标记参考。符号间隔大于TS我们认为是正常短信,反之认为是疑似短信。
2.2.2 关键词动态序列权重库生成
大部分违规短信中均包含关键词,关键词动态权重库通过词频统计分析构建。
对正常短信样本库、违规短信样本库,计算每个关键词、关键词序列的命中情况如表1所示。
综合考虑关键词命中正常库、违规库的概率PKey1,PKey2,设定关键词命中的权重:
PKey=Pkey2/Pkey1(Pkey2/Pkey1最高值为100)

表1 关键词命中统计表
通过学习分析,可确定关键词匹配模式正则:
P(?*发票?*广告?*电话?*)=45;
P(销售)=32。
按上述方法,可生成关键词动态序列权重库;一旦学习样本有变动,可动态再次进行权值更新。
2.2.3 特征内容集
针对违规短信中包含的电话、qq、邮箱、URL等唯一标识性信息,可加入特征内容集,形成库,并记录违规库命中次数。一旦待判定的信息中有该类型的信息,则可唯一命中,将待判定信息判定为违规信息。
例如我公司销售各种普通、增值发票,电话13711111111。
上述短信命中了特征内容集中的号码13711111111,其权值为3,判定Hit(SMS)=3。
2.2.4 先验模型综合判定算法
在先验模型的3个判定流程:内容特征模型算法、关键词动态序列权重库以及特征内容集,我们采用串行的判定模式进行判定,判定是先进行一个流程再进行下一个流程。如果在某一个流程中已经对某一条短信做出判定,那下一个流程的判定结果将不再对该短信的判定产生影响。
例如某条信息:“有发票13811145678”。该短信命中关键词“发票”,特征内容集“13811145678”,并且该短信的内容特征模型值(CV)还小于阈值。如果先进行CV判定,则该短信被判定为正常短信,后面的关键词判定、内容特征集判定结果将不产生作用;如果先做关键词判定,则该短信被判定为疑似短信或违规短信;如果先做内容特征集,则该短信被判定为违规短信。
由以上例证可见,不同的判定流程顺序,对最终的判定结果会产生影响。在实际的算法实践中,我们一次性填入所有的判定流程结果,然后根据预先配置好的判定流程顺序,来决定最终的判定结果。例如判定流程:Step1-Step2-Step3,我们先检查Step1是否有判定结果,如果有则先验模型的判定结果就是Step1的判定结果;否则再检查Step2的判定结果,如果为空再检查Step3的判定结果。
3 短文本先验模型算法判定实验
3.1 先验模型训练结果参数
在先验模型的训练过程中,我们使用有人工审核结果的疑似短信作为训练数据、测试数据(默认人工审核结果是短信的正确判定结果)。人工标注短信集共200万余条,我们分为训练短信集与测试短信集分别100万条左右。然后经过先验模型的判定对原短信添加判定结果。我们可以统计得出先验模型的判定效果并与人工判定结果进行比对,比对结果用召回率R(Recall)与查准率P(Precision)表示,定义如下:
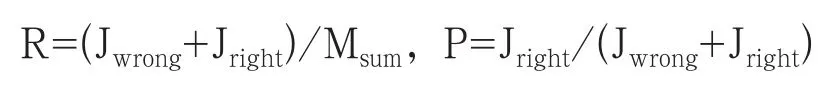
其中Jwrong表示先验模型判定错误的短信量,Jright表示先验模型判定正确的短信量,Msum表示短信总量。召回率表示先验模型判定的短信数量占总短信量的比值,查准率表示判定正确的短信数量占总判定量的比值。
误判率定义如下:F=1-P。
3.2 内容特征模型算法训练与判定结果
在内容特征模型训练中,我们对短信的长度、特殊符号个数、符号占比以及符号间隔位置逐项进行训练分析,确定各项阈值以及内容特征模型整体阈值,具体训练过程如下。
3.2.1 长度阈值训练
根据长度阈值设定,我们对全量训练短信(包括正常短信、违规短信)利用长度阈值判定规则进行判定,结果如图2所示。
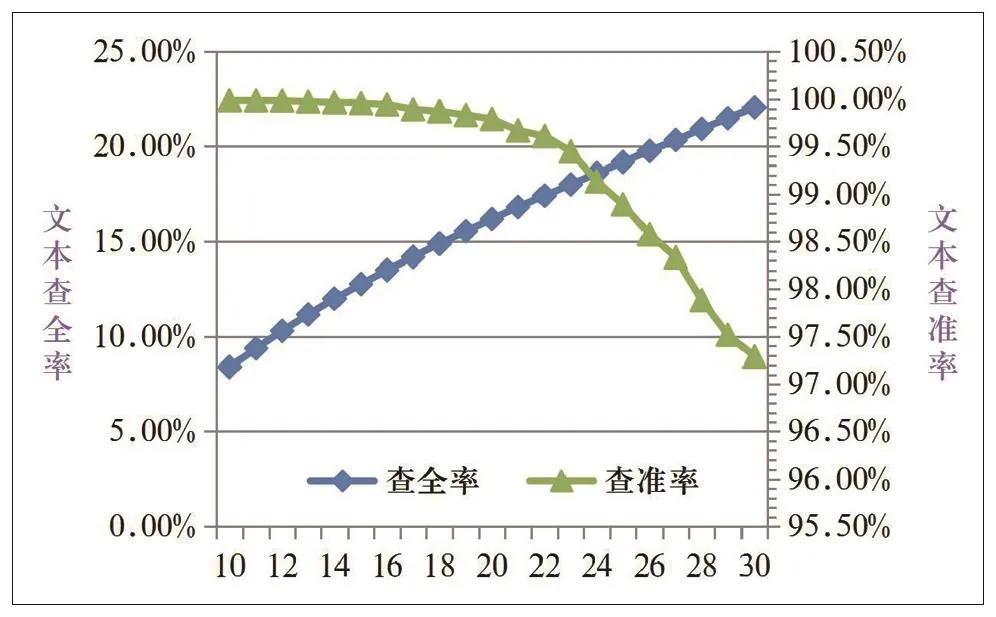
图2 先验模型长度阈值训练
考虑到短信过滤系统需要查准率尽可能的高,所以短信长度阈值的设定我们认为20最理想,所以确定TL=20。
3.2.2 特殊符号数量训练
我们将特殊符号分为正常类型和违规类型,并通过训练确定违规类型阈值为违规信息判定标记参考。通过数据训练,确认某类特殊符号10个以上的60%以上为违规信息,因此确定TM=10。
3.2.3 符号占比训练
在文本中,我们计算特殊符号等符号信息占整体短信文本的比例,训练的结果表示如图3表示。我们看到符号占比的阈值在0.15~0.25之间时,违规短信的数量最多,因此我们将违规短信占比阈值确定为0.15~0.25。
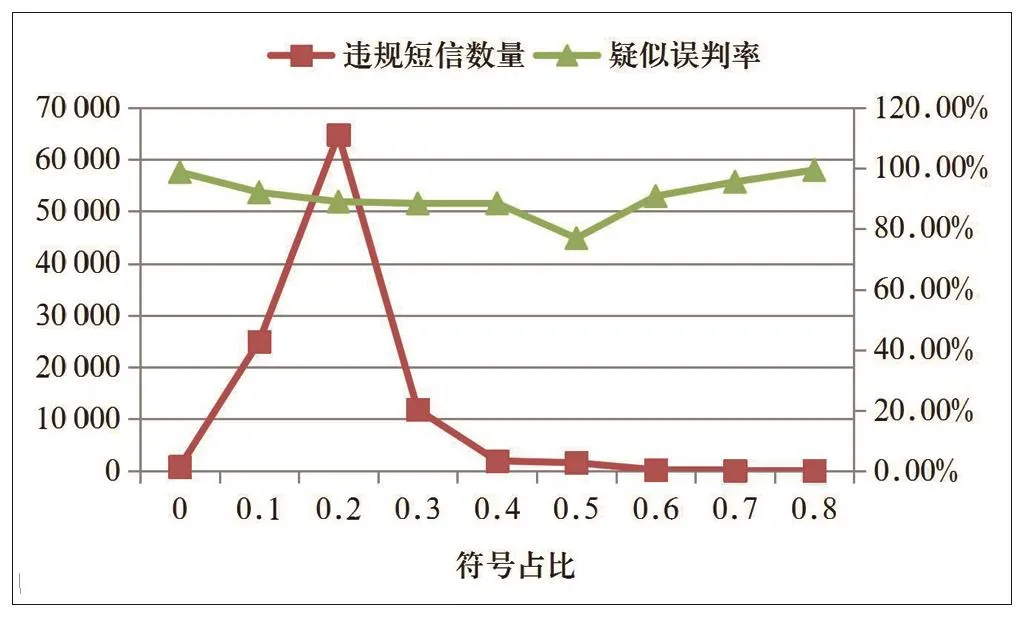
图3 符号占比分析
3.2.4 符号间隔位置训练
对符号间隔采用2次曲线进行拟合后,进行分段积分分析,可确定合适的阈值判定违规信息。例如经过某训练集分析,标点符号间隔在1~3.3之间,违规信息占比为96%;因此,确定TS=1~3.3。
3.2.5 内容特征模型算法综合训练与判定
基于上述训练,可确定四维向量,即CV=[长度阈值TL(TL>20),特殊符号数量TM(TM>10),符号占比Tr(0.15≤Tr≤0.25),符号间隔均值TS(1≤TS≤3.3)]。
若某短信经内容分析,长度、特殊符号数量、符号占比均满足违规阈值要求,符号间隔不满足违规阈值要求,则经过CV阈值判定的结果为:
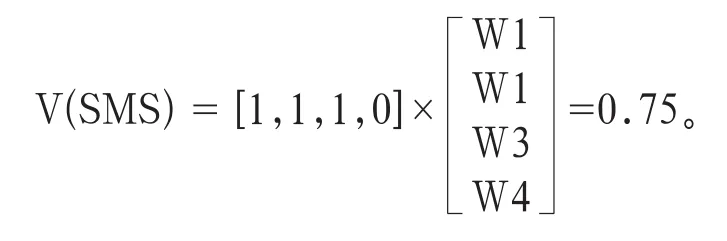
3.3 关键词动态序列权重库训练与判定结果
在关键词训练的第一步,我们首先计算每个关键词进行序列提取,并在训练短信库中的判定准确率。它的定义如下:
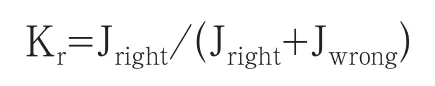
相应的误判率为Kf=1-Kr
因为在先验模型中,关键词序列若命中人工判定的违规短信(即Jright),我们就认为它正确判定,否则是错误判定。
我们对关键词的判定准确率在100万的训练库中进行测试,判定结果如图4所示。

图4 关键词筛选
可以看到随着关键词序列判定阈值的下降,先验模型的召回率也随之下降,但先验模型的准确率在关键词阈值为0.1时最大,查全率在0.2时最高。平衡系统的准确率与查全率,选择0.15 作为关键词筛选的参数。
3.4 特征内容集训练与判定结果
我们将提取的回联号码代入训练库中,计算回联号码的命中准确率,如公式:

Jright为回联号码命中的违规短信,Jwrong为回联号码命中的正常短信。这里应用回联号码的目的是找出违规信息,所以回联号码命中违规短信的,为正确命中;反之命中正常短信的,为错误命中。
经过训练,回联号码的命中率非常高,可以选取0.99作为回联号码命中准确率的阈值,我们选取大于或等于此阈值的回联号码作为黑名单,放入配置文件。
3.5 算法全流程判定结果
我们定义各个判定流程如下。
Step1:内容特征模型算法判定。
Step2:关键词判定。

图5 先验模型判定顺序训练
Step3:特征内容集判定。
不同的判定顺序得到的判定结果如图5所示。
图5中123表示判定顺序为Step1、Step2、Step3,以此类推。判定模型为123时判定准确率最高,而判定模型顺序为321时判定召回率最高。考虑到判定的准确率都在99%以上,因此选择判定顺序321(即Step3、Step2、Step1的顺序)为算法的全流程判定顺序。可判定73%左右的短信,并且判定的准确率达到99%以上。
4 总结
本文提出一种先验模型的信息判定方法,同时具备基于关键词判定的覆盖率,又具备较高的准确率。应用该方法能解决违规信息判定中的如下问题:一是能尽可能发现已知类型违规信息,具有很高的覆盖率;二是通过对已判定的信息进行不断学习,自动优化判定模型,提升对新信息的发现能力;三是能基于已知的特点进行分析,具有较高的准确率,节省人工判定工作量。
通过实际数据检验,采用先验模型判定算法在判定准确率达到98%以上的同时,判定召回率达到60%以上。
AbstractIn order to deal with the rapid and diversified development of spam messages, the governance means of operators towards spam messages need to advance with the times, need to cover more comprehensive and judge more accurate. In view of the objectives, we proposed an identification and filtering method based on prior model for short text spam messages. This method analyze short text from three aspects,respectively text feature layer, keyword pattern layer and content feature layer, then ultimately give a final judgment result using comprehensive analysis and determination layer with previous training process. We can not only ensure the precision of spam messages recognition, but also greatly improve the recall of spam message recognition. We give a better solution to the current spam messages recognition problem, which may save a lot of manpower for the operators.
Keywordsspam messages filter; prior model; text feature; keyword pattern; content feature
The research and practice of a prior model decision technique for short text
SU Li1, DAI Jing2, AN Ning-Yu1, ZHANG Feng1
(1 China Mobile Research Institute, Beijing 100053, China; 2 China Mobile Information Security Center, Beijing 100053, China)
TN918
A
1008-5599(2017)10-0033-06
2017-09-18
* 中国移动集团级一类科技创新成果,原成果名称为《基于大数据算法的信息安全管控工具与平台研发(莫扰)》。
猜你喜欢
廉政瞭望·下半月(2022年4期)2022-05-12
中国石油石化(2021年9期)2021-07-17
成都信息工程大学学报(2019年3期)2019-09-25
当代工人(2019年4期)2019-04-22
劳动保护(2018年5期)2018-06-05
当代工人(2018年21期)2018-03-06
自动化学报(2017年5期)2017-05-14
作文通讯·高中版(2017年12期)2017-02-06
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
