
基于条件随机场的中文情感分析方法比较研究∗
2017-10-16 09:07周学广
计算机与数字工程 2017年9期
王 茵 周学广 陆 健
基于条件随机场的中文情感分析方法比较研究∗
王 茵1周学广2陆 健2
(1.海军计算技术研究所 北京 100841)(2.海军工程大学信息安全系 武汉 430033)
条件随机场(Conditional random field,CRF)模型是目前开展中文情感分析研究的一个热门工具。文章分析了CRF研究现状,给出了CRF适用于中文信息处理的理由,开展了基于CRF算法的比较研究:运用自然语言处理与中文计算2012年会议的公开评测结果,分别对CRF与隐马尔科夫模型和最大熵马尔可夫模型进行了比较研究,总结了CRF模型的特点。
条件随机场;隐马尔科夫;最大熵马尔可夫;情感分析;中文信息处理
AbstractConditional Random Field(CRF)model is a popular tool to carry out research in Chinese sentiment analysis.This paper analyzes the research status of CRF,CRF applicable for Chinese information processing is given,and a comparative study based on CRF algorithm is carried out.Using natural language processing and Chinese to calculate public evaluation results of that meeting in 2012,CRF and hidden Markov model and maximum entropy Markov model are researched comparatively,the character⁃istics of CRFmodel is summarized.
Key Wordsconditional random fields,hidden markov model,maximum entropy,emotion analysis,Chinese information processing
Class NumberTP391.1
1 引言
为了既保留隐马尔科夫模型(Hidden Markov Model,HMM)[1]和最大熵马尔可夫模型(Maximum Entropy,ME)[2]等条件概率框架的优点,又解决标记偏置的问题,Lafferty等学者提出了CRF(Condi⁃tional Random Field,CRF)模型[3],CRF属于随机场的一种,是判别式概率无向图学习模型,在数据分段、序列标注、命名实体识别、中文分词等自然语言处理任务中都有很好的表现,大大提高了中文分析准确率。
2 相关工作
CRF已经被广泛的应用于舆情分析、情感的分类等相关研究领域中。中文文本的情感分类的研究有Wang[4]等提出的基于启发规则与贝叶斯分类相结合的评论句子情感倾向性的分类方法。王根[5]等提出了基于多重冗余标记CRF的句子情感分析方法,提高了最终分级任务的准确率。喻奇[6]结合情感词定位规则与CRF方法,提出了对观点句的评价对象进行抽取并计算极性的方法。厦门大学的陈怡疆等[7]提出时态树的概念和构造方法,使用树形CRF为未标注时态树的结点加标注,提出的特征函数的模板能满足模型推断的需要。中科院的刘康和赵军[8]提出利用多个CRF模型对句子的褒贬类别和褒贬强度进行判定,实验结果证明其准确率和召回率效果要优于普通文本分类与单层CRF模型。重庆大学的张玉芳和莫凌琳[9]等利用CRF对科研论文的信息进行分层提取,该方法的抽取性能优于基于词或块的CRF模型的信息抽取方法。Chen等[10]利用CRF实现了从评论中抽取多种类型的评论信息。徐冰[11]等则是引入浅层句法特征提高CRF模型的识别精度。王荣洋等[12]提出利用词法、依存关系、相对位置、语义四大类别信息作为CRF的特征抽取出评价对象。郑敏洁等[13]则提出了一种基于层叠CRF的中文句子评价对象抽取方法,有效提高了情感对象为复合词和未登录词时的识别精度。
3 适用于情感分析的CRF模型
情感词的情感倾向预测不是唯一的,也就是说评价词存在歧义现象。例如“性价比高”和“价格高”,同一个字“高”在两个句子中表象出来的情感倾向是不一致的。还有,不同情感倾向的词语,出现的语境也不同。因此,词语的情感倾向和它的上下文有着紧密的联系。然而不论是基于词典,还是基于语料库的方法,它们都把词的情感倾向预测局限于这个词语的本身,忽略了它所出现的上下文。本节提出一个基于识别情感词情感倾向的链式CRF模型,可以用来识别评价词的情感倾向。
3.1 CRF模型原理
CRF属于无向图模型,Lafferty等对CRF定义如下:
令G=(V,E),其中G表示无向图,V和E属于无向图中的集合。在此表达式中,V代表节点集合,E代表边集合,标记序列中,元素和图中的节点一一对应。在已知观察序列条件下X条件下,如果随机变量的分布满足马尔可夫性,即节点与图G中是相邻节点,则称此图是一个CRF。
CRF可以用公式表示,令 X=(X1,X2,…,XT),表示带标注序列,令Y=(Y1,Y2,…,YT),表示对应于X的状态序列。
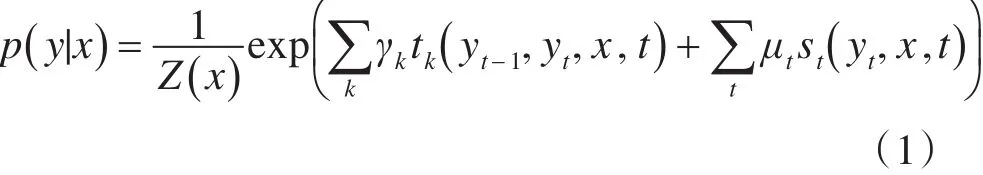
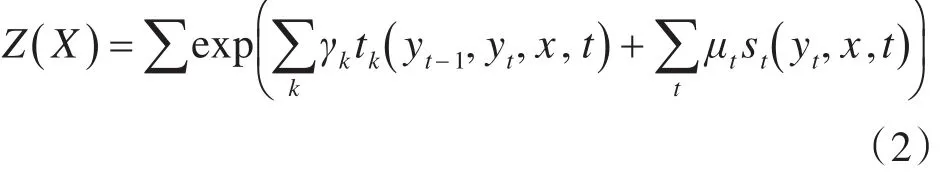
其中,tk和st是特征函数,γk和 μt是对应权重,Z(x)是归一化因子,tk( )yt-1,yt,x,t 是表示特征转移函数,函数取值为0或1。通常,特征函数为0或1,如果满足特征条件时候取1,否则取0。
3.2 可识别情感词情感倾向的链式CRF模型
3.2.1 链式CRF模型
CRF是一个无向图上的指数概率模型,它采用了链式无向图结构计算给定观察值条件下输出状态的条件概率[14]。
令X=(x1,x2,…,xn)为可观测的输入序列(例如词性标注中的句子),Y=(y1,y2,…,yn)为待预测的标记序列(例如词性标注中词性),其中xi表示X的第i个分量,yi是xi对应的标签。线性链CRF定义标记序列Y的条件概率为
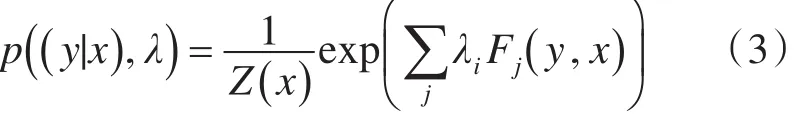
其中Z(x)是归一化因子,是特征函数。特征函数分为两种,一种特征函数只与当前状态相关,另一种特征函数还与当前状态的前一个状态有关。对于离散型特征,函数的取值通常为0或1。是对应特征函数的权重。
特征函数的权重可以使用最大似然估计法通过模型训练获得。对于序列标注,给定一个输入序列X,模型用Viterbi算法求出以输入序列X为条件下具有最大条件概率的标记序列:
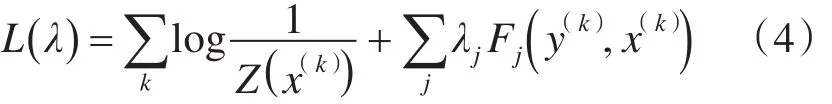
链式CRF的序列标注不仅保存了短文本的特征词,还保存了词之间的顺序关系,可以提高短文本情感倾向性分析的准确度。
3.2.2 CRF的图结构
设X,Y分别表示待标注的观测序列和对应的标记序列的联合分布随机变量,则( )X,Y ,就是以X为全局条件的CRF模型。定义G=( )V,E 是一个无向图结构,Y={YV|v∈V } 节点集V由X和Y的构成,即 X={Xu|u∈V},y={Yv|v∈V } ,边集E表示节点间的关系集。由于无向图G中标记序列的每一个分量都以X为条件,因此,CRF中的联合分布可以由条件概率P(y1,…,yn|X ) 来表示。如果每个随机变量yv都满足关于无向图的马尔可夫属性,对于给定的X和yv以外的所有随机变量Y(W |W≠V,{W ,V}∈v),则随机变量 yv的概率为
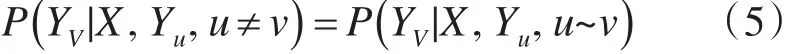
其中,u~v表示的是结点u和结点v相邻,那么,(X ,Y )是一个CRF。
在序列标记任务中,通常情况下遇到的图结构是一个简单的线性结构,在这种结构中,观察序列Y的元素对应的结点形成了一个简单的链式结构,称之为线性链CRF,如图1所示。
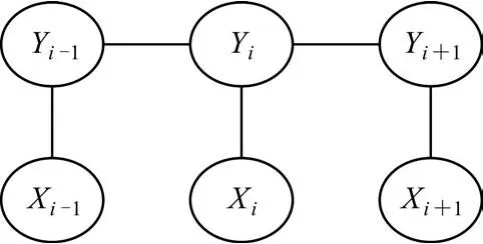
图1 线性链CRF的图模型
因为只将X作为观察序列,因此对其并没有做独立性假设,所以X的各元素间并不存在图结构,由此线性链CRF的模型也可表示为图2。

图2 线性链CRF的另一个图模型
使用CRF进行短文本情感倾向性分析的流程如下:微博测试集首先进行中文分词和去标点工作,然后进行序列标注,第三步,将微博测试集分为训练集和测试集2个集合,对训练集使用CRF获得相关模型,作用于测试集,得到测试结果。
4 CRF与其它模型的对比分析研究
4.1 公开评测实验结果分析
针对微博情感分析公开评测采用2012年NLPCC自然语言处理与中文计算会议发表的《中文微博情感分析评测结果》[15]。评测结果统计了准确率、召回率,以及F值。按照微平均和宏平均计算,微平均以整个数据集为一个评价单元,计算整体的评价指标。宏平均以每个话题为一个评价单元,计算参评系统在该话题中的评价指标,最后计算所有话题上各指标的平均值。结合所有参评单位及实验室上报和公布的实验数据,我们查找了各单位使用的不同情感倾向性分析模型,比较结果形成表1。
经过比较,可以看出CRF算法提交的结果成绩优异,在准确率,召回率以及F值都获得了十分高的准确率。其中,CRF、DUTIR、ME、SVM&ME、uni⁃gram以及依存分析方法的准确率P值很接近,SVM&ME模型的准正确率最高,比CRF高0.034,我们分析其原因是由于该集成分类器结合了SVM和ME两个分类器的长处,但是在召回率上比CRF少了0.113,导致F值比CRF差。DUTIR模型采用的是基于机器学习的方法进行情感倾向性判断,它的准确率和CRF接近,但是召回率远远少于CRF,导致它的F值也低于CRF。其它模型都远远落后于CRF。从中可以看出CRF算法在短文本情感分析评测中效果显著。通过查阅资料知道,常用的情感分析都是以句子为单位进行微博信息处理和分析,它过于单一,若是以每一条微博为单位,结合微博中的句子的上下文关系,找出观点微博,则更具有应用价值,在这个方面,CRF具有很高的研究价值与应用前景。
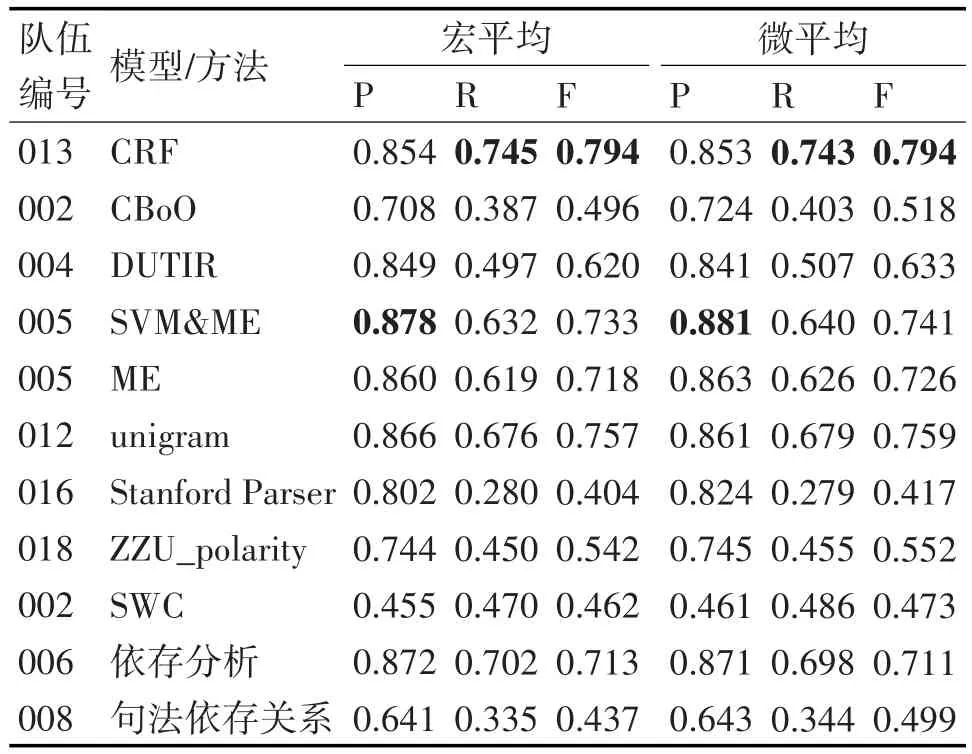
表1 NLPCC2012参评队伍不同情感倾向性分析方法与结果比较[15]
4.2 CRF与M E对比实验及分析
在NLPCC2012评测上,文献[16]提出一种融合ME和SVM模型,用于识别主观句和褒贬极性分类问题。通过构建一个高质量的情感词典,将句子拆分为短句并使用一些规则提取特征,然后利用模型预测短句极性,最后用短句极性预测长句极性。我们利用其中的ME模型评测数据(队伍编号005)与同年CCF自然语言处理中文微博情感分析评测中的文献[17]所采用的CRF模型算法评测数据(队伍编号013)作对比,更深入地分析ME模型与CRF模型的特点,结果如图4所示。
从实验数据可以看到ME在准确率上能够达到较高的识别性能,比CRF高0.6个百分点,但是在召回率上ME比CRF低12.9个百分点,从而导致ME的F值低于CRF。而CRF模型在保证准确率的前提下,召回率和F值依旧有良好的表现。分析结果可知ME存在以下问题:
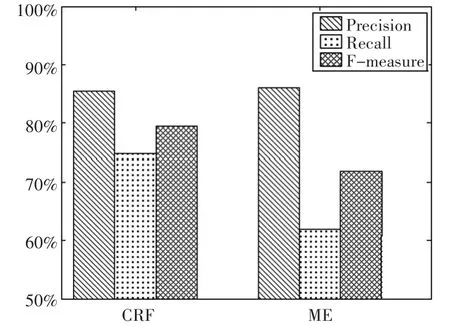
图4 CRF(013)与ME(005)在情感倾向性分析上的数据比较[16~17]
1)ME模型是通过文本的特征对微博文本进行情感分析,受句子长度影响较大,所以由于微博文本句子长度不一,导致ME模型在判断微博情感上存在不少问题。
2)ME模型的瓶颈是需要较大的训练集数量,由于数据稀疏是机器学习方法面临的一个普遍问题,因此对于基于ME的情感分析,必须要有巨大数量的训练集,若是训练集太小,则会导致结果不理想,从而影响分析的全面性。
3)ME模型虽然解决了HMM模型中的条件独立性假设问题,从而将上下文信息引入到模型的学习和识别过程中,提高了准确率,但是在序列标记过程中,ME是逐点判断,这种局部最优解的做法常常使得最终结果陷入局部最优解,在一些情况下出现标记偏置问题。
而CRF模型除了能融合上下文信息外,还能利用观察序列中从局部到全局、从低层到高层的各种形式的上下文信息。此外,CRF模型还具有很强的融合利用任意复杂相关特征的能力,使得它不需要考虑观察序列中特征之间的相关性,不需要花费精力考虑如何使用特征,可以灵活地进行特征选择,不需要额外的独立性假设或内在约束。
4.3 CRF与HMM对比实验及分析
CRF和HMM虽然都是根据观察序列特征进行序列标注,但依据的数学原理、建模的过程以及产生的结果都不相同。基于两种模型依赖的数学基础,文献[18]认为CRF避免了HMM由于理论缺陷所必然存在的问题,较HMM更适合解决序列标注问题;但HMM较之CRF则有数学理论简单,集成特征少,训练时间短的特点。通过HMM与CRF的实验结果,可以更直观地分析两个模型的优缺点,如图5所示(数据来源于文献[18])。
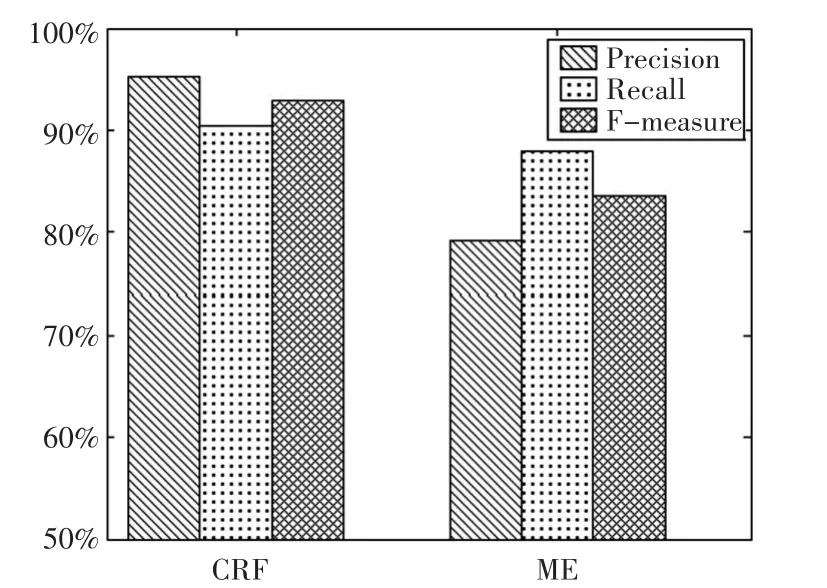
图5 CRF与HMM在人名实体识别开放性测试的实验比较[19]
实验中数据表明,CRF模型在识别准确率(P)上明显优于HMM模型,召回率(R)相差不多,CRF比HMM高出2.56个百分点,从而使得CRF的F值比HMM高出了近10个百分点,虽然HMM比CRF更容易发现人名实体,但是以牺牲模型的准确率为代价的。此外,实验对模型的训练时间进行了比较,发现HMM中3个词典的生成仅需要30min,CRF则需要23h进行参数训练,证明CRF模型较复杂,这也是CRF各项识别指标优于HMM的原因之一。HMM数学复杂度低于CRF,特征训练时间远低于CRF,但是在人名实体抽取应用的准确率、召回率、F值等各项评测指标上都远远落后于CRF。
从文献[18]的实验中我们可以得到HMM与CRF的比较结果:
1)CRF比HMM数学模型复杂度高;
2)HMM仅集成了两个指定特征,参数训练仅仅需要统计三个频次值,而CRF能够在同一个模型中无限制集成不同特征,特别是可加入远距离约束,更能揭示语言学特征,但CRF集成多种特征生成了成千上万个特征函数,导致其权重训练的计算量大,这就让CRF出现了“指数爆炸(Blow Up)”,训练强度远远超过HMM;
3)CRF采用联合条件概率P(T |W )建模,避免了HMM的独立性假设和二元假设,从数学建模的角度而言,CRF较之HMM具有更可靠更合理的数学推导;
4)CRF保留了HMM中的之前标记的状态对当前状态标记的影响,使特征的选择更为合理;
5)HMM是有向图模型,通过Viterbi算法搜索到当前对象为止的最佳路径,不考虑之后对象及其标记概率,而CRF则采用无向图模型,是对整个标记序列求解联合概率,在整个序列范围内归一化,较HMM具有更为合理的数学理论基础,同时也避免了因求解局部观察值概率所带来的标记偏置问题。
5 结语
通过研究可知,CRF模型优点有以下几项:首先,CRF模型由于其自身在结合多种特征方面的优势,使得CRF具有很强的推理能力,并且能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得CRF模型能够获取的信息非常丰富。其次,CRF对特征的融合能力比较强,对于实例较小的时间类ME来说,CRF的识别效果明显高于ME的识别结果。第三,CRF是在所有的状态上建立了一个统一的概率模型,在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态的跳转概率也不会为1,从而解决了标记偏置问题。
CRF模型也存在不足:首先,在使用CRF的过程中,特征的选择和优化是影响结果的关键因素,特征选择问题的好与坏,直接决定了CRF系统性能的高低。其次,CRF训练模型的时间比ME要更长,且获得的模型很大,在一般的PC机上无法运行。
从理论上讲,CRF由于合理的数学理论、严密的数学推理使其比HMM、ME更适合中文的序列标注或文本情感分析等应用中。
[1]Lawrence,Rabiner L.R.A Tutorial on Hidden Markov Mod⁃els and selected applications in speech recognition[J].Proceedings of the IEEE,1989,77(2):257-286.
[2]Borthwick A.A Maximum Entropy Approach to Named En⁃tity Recognition[D].New York University.Department of Computer Science,Courant Institute 1999:23-24.
[3]J.Lafferty,A McCallum,F.Pereira.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of International Confer⁃ence Machine Learning PP.282-289,2001.
[4]Wang Chao,Lin Jie.Zhang Guangquan.A semantic classi⁃fication approach for online product reviews[C]//Proceed⁃ings of the 2005 IEEE/WIC/ACM International Confer⁃ence on Web Intelligence(WI’5),2005.
[5]王根,赵军.基于多重冗余标记CRF的句子情感分析研究[J].中文信息学报,2007,13(3):9-17.
WANG Gen,ZHAO Jun.Sentence Sentiment Analysis Based on Multi-redundant-labeled CRFs[J].Journal of Chinese Information Processing,2007,13(3):9-17.
[6]喻琦.中文微博情感分析技术研究[D].杭州:浙江工商大学,2013:31-33.
YU Qi.The Research of Sentiment Analysis Techniques for Chinese Microblog[D].Hangzhou:Zhejiang Technolo⁃gy and Business University,2013:31-33.
[7]陈怡疆,徐海波,史晓东,等.基于树形CRF的跨语言时态标注[J].软件学报,2015,26(12):3151-3161.
CHEN Yijiang,XU Haibo,SHIXiaodong,et al.Cross-lin⁃gual Tense Tagging Based on Tree Conditional Random Fields[J].Journal of Software,2015,26(12):3151-3161.
[8]刘康,赵军.基于层叠CRF模型的句子褒贬度分析研究[J].中文信息学报,2008,22(1):123-128.
LIU Kang,ZHAO Jun.Sentence Sentiment Analysis Based on Cascade CRFs Model[J].Journal of Chinese Informa⁃tion Processing,2008,22(1):123-128.
[9]张玉芳,莫凌琳,熊忠阳,等.基于CRF的科研论文信息分 层 抽 取[J].计 算 机 应 用 研 究 ,2009,26(10):3690-3693.
ZHANG Yufang,MO Linglin,XIONG Zhongyang,et al.Hierarchical Information Extraction from Research Papers Based on Conditional Random Fields[J].Application Re⁃search of Computers,2009,26(10):3690-3693.
[10]Chen L,Qi L,Wang F.Comparison of feature-level learn⁃ing methods for mining online consumer reviews[J].Ex⁃pert System with Applications,2012,39 (10) :9588-9601.
[11]徐冰,赵铁军,王山雨.基于浅层句法特征的评价对象抽取研究[J].自动化学报,2011,37(10):1241-1247.
XU Bing,ZHAO Tiejun,WANG Shanyu.Extraction of Opinion Targets Based on Shallow Parsing Features[J].Acta Automatica Sinica,2011,37(10):1241-1247.
[12]王荣洋,鞠久鹏,李寿山,等.基于CRFs的评价对象抽取特征研究[J].中文信息学报,2012,26(2):56-61.
WANG Rongjiu,JU Jiupeng,LI Shoushan,et al.Feature Engineering for CRFs Based Opinion Target Extraction[J].Journal of Chinese Information Processing,2012,26(2):56-61.
[13]郑敏洁,雷志城,廖祥文,等.基于层叠CRFs的中文句子评价对象抽取[J].中文信息学报,2013,27(3):69-76.
ZHENG Minjie,LEI Zhicheng,LIAO Xiangwen,et al.Identify Sentiment-Objects from Chinese Sentences Based on Cascaded Conditional Random Fields[J].2013,27(3):69-76.
[14]Hanna M.Wallach.Conditional Random Fields:An In⁃troduction[R]//Technical Reports,Department of Com⁃puter&Information Science,University of Pennsylva⁃nia,2004:133-136.
[15][DB/OL].http://tcci.ccf.org.cn/conference/2012/pages/page04_eva.htm l,2016-12-1.
[16][DB/OL]http://tcci.ccf.org.cn/conference/2012/pages/page05_eva.htm l.2016-12-1.
[17][DB/OL]http://tcci.ccf.org.cn/conference/2012/pages/page13_eva.htm l.2016-12-1.
[18]王昊,邓三鸿.HMM与CRF在信息抽取应用中的比较研究[J].现代图书情报技术,2007(7):158-162.
WANG Hao,DENG Sanhong.Comparative Study on HMM and CRFs Applying in Information Extraction[J].New Technology of Library and Information Service,2007(7):158-162.
Com parative Study of Chinese Emotion Analysis M ethods Based on Conditional Random Fields
WANG Yin1ZHOU Xueguang2LU Jian2
(1.Computer Technology Institute of Navy,Beijing 100841)(2.Department of Information Security,Naval University of Engineering,Wuhan 430033)
TP391.1
10.3969/j.issn.1672-9722.2017.09.004
2017年4月20日,
2017年5月27日
国家社会科学基金军事学项目(编号:14GJ003-152)资助。
王茵,女,工程师,研究方向:计算机技术与中文信息处理。周学广,男,博士,教授,博士生导师,研究方向:信息安全与密码学。陆健,男,研究方向:信息内容安全。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国生殖健康(2020年5期)2021-01-18
健康体检与管理(2021年10期)2021-01-03
小太阳画报(2019年10期)2019-11-04
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中华诗词(2018年9期)2019-01-19
