
基于K-Means和网格化聚类的云数据管理模型研究
2017-10-11 01:37刘加伶程春游朱艳蓉
重庆理工大学学报(自然科学) 2017年9期
刘加伶,程春游,陈 庄,朱艳蓉
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
基于K-Means和网格化聚类的云数据管理模型研究
刘加伶,程春游,陈 庄,朱艳蓉
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
针对云数据的分类具有模糊性、不确定性等特点,将K-Means聚类与网格化互联互通的思想运用到云数据管理的模型中,提出了一种“K-Means网格化的云数据管理模型”方法。通过随机产生的高斯分布数据表明:所提出模型不仅能高效地解决数据在分类、模糊性等方面存在的问题,而且在提高数据分布区域化精度的同时减少了数据管理的个数。利用Matlab工具对数据进行了K-Means网格化验证分析,分析结果能为企业的数据管理提供有益的借鉴。
K-Means;云数据管理;网格化;模型;仿真
Abstract: According to that the cloud data classification has the characteristics of fuzziness and uncertainty, and K-Means clustering and grid interconnection thought is introduced into the Cloud Data Management (CDM) model, and a new method “Cloud Data Management model based on K-Means Grid” is proposed in this paper. The demonstration shows that the present model not only is the more efficient solution to classification data, fuzzy and other characteristics, but also can improve the accuracy of regional data distribution while reducing the number of data management. Using MATLAB tools to verify and analyze data into K-Means grid, and the results of the analysis results can provide useful reference for company data management.
Keywords: K-Means; cloud data management; gridding; model;simulation
21世纪是一个信息化高速发展的时代,数据驱动发展已成为全球发展的新趋势[1],大数据[2](big data)成为现阶段研究热点。同时,各行业对数据的依赖性有增无减,现云数据管理技术[3]正在替代传统的内部部署软件,云数据库和数据库即服务(database as a service,DaaS)平台成为企业不可缺少的工具。比如,Oracle Cloud[5]数据管理云服务提供了一个完整的功能集合构建、部署和管理数据驱动的应用程序。
根据预测[4],平均每18个月企业的数据就会翻一番,而很多企业对用户数据的管理有待改进。同时新的研究对象也提出了新的数据管理要求,传统数据挖掘方法(关联分析、聚类分析、预测、时序模式分析和偏差分析)在数据采集、数据存储、数据分析和可视化等诸多方面存在不足[5]。基于以上情况,本文设计了一种K-Means网格化的云数据管理模型以提高云数据处理效率。
1 相关简介
1.1 云计算
目前,云计算(cloud computing)仍然是IT范围里最热门的技术之一。NIST SP 800-145[6]与UC Berkeley RAD Lab[7]定义云计算是指在硬件和系统软件的数据中心通过互联网提供服务,即云计算就是提供服务。云计算[8-9]是由网格计算(grid computing)、并行处理(parallel computing)、分布式处理(distributed computing)、效用计算网络存储、虚拟化(virtualization)、负载均衡(load ba-lance)等传统的计算机技术与网络技术相结合并发展融合的产物。
1.2 云数据管理
云数据管理(cloud data management,CDM)[10-12]是为了解决云计算中大量数据的高效管理以及特定数据的快速定位问题,即以云计算技术为基础,针对大规模数据的分布式、可扩展的数据管理进行管理。目前,云计算、云存储将是增长最快的服务。数据的云存储[13]存在着一定的安全悖论:数据加密的情况下无法处理;数据不加密情况下安全性和隐私性出现一定的问题;数据加密对应云计算服务模型SaaS、PaaS、IaaS。相比传统的数据管理(人工管理、文件系统、数据库系统),云数据管理除了关注以上内容外,还需注意数据模型的无明确性、数据规模的巨大性、数据类型的无规则性、云数据管理技术的多样性。目前云数据管理没有统一的国家标准,但是根据[14-19]可知,云数据管理模型实施流程如图1所示。

图1 云数据管理模型实施流程
1.3 K-Means的云数据管理
K-Means[20]给出原始数据,根据算法将其中具有相似特征的数据聚为一类,假设原始数据{x1,x2,…,xn}为没有被标记的数据,初始化后为k个随机数据{u1,u2,…,un},其中xn和un都是向量。普通K-means算法在初始化k个中心点时使用数据集前k个点作为中心点或使用默认的随机化方法初始化中心点。本文采用高斯随机化方法从数据集中取k个点作为中心点,其步骤是不断迭代公式(1)(2),直到所有的u都不变化,完成了聚类的计算。

(1)

(2)
1.4 网格化下的云数据管理模型
据 Foster和Kesselman[21]定义:“网格”(或 “计算网格”)是构筑在互联网上的一种新兴技术,通过互联网(Internet)把分散在不同地理位置的电脑组织成一台“虚拟的超级计算机(virtual supercomputer)”,将高性能计算机、大型数据库、传感器、远程设备等融为一体,实现计算、存储、通信、软件、信息、知识资源的全面共享[13],网格化的提出也为打开计算机虚拟化大门奠基了基础。目前众多学者在分析将PB(petabytes)级数据进行网格化[22],云计算作为网格计算、并行处理和分布式处理的发展,已成为产业界、学术界、政府等各界都极度重视的焦点[14],这就更加突出了网格化式的云数据管理在研究中越来越重要的地位。
网格化的云数据管理是对数据业务进行统一化管理,但是分块类的数据繁多,不能实现数据点对点的思想。本文将“数据的监控、数据模糊统计分析、数据的预警提醒”统一纳入云数据管理模型,最终实现了数据的监控、管理、调度指挥“一张网”。
2 云数据管理模型构建
K-Means聚类有助于数据的聚类分析,网格化有助于数据的区域化,将两者进行统一结合建立统计分析的云数据管理模型将有助于企事业的决策分析,实现云数据更加高效的管理与运用,为企业决策者提供有益的借鉴。如图2[15-16]所示为本论文构建的模糊网格化的云数据管理流程。
2.1基于K-Means聚类的云数据管理建模
K-Means聚类[17]的云数据管理主要步骤如下所述:
Step1在数据集中随机选取k个对象作为初始聚类中心c1,c2,…,ck;
Step2计算数据集中每个对象到聚类中心的距离,选取最小距离min|V|,分配到聚类中心,其中V={v1,v2,…,vn},j=1,2,…,k;
Step4当每个簇的聚类中心不再发生变化,聚类准则函数=收敛,则算法结束。否则,返回Step 2继续迭代。
此方法为数据的管理提供了K-Means聚类的方式,但其管理仅达到了分类的效果,还未具体到某一个数据块上。

图2 K-Means网格化的云数据管理流程
2.2 基于网格化的云数据管理建模
网格化的云数据管理[18-19]主要步骤如图5所述。
Step1数据收集。通过数据控制中心收集用户需要存储的数据;
Step2数据分割。数据控制中心按设定的分割规则将步骤Step1中所收集的数据进行分割;
Step3数据重组。将数据进行二次重组,并将每份数据进行编号;
Step4数据存储。将步骤Step 3中重组后的数据分发到子电脑中存储;
Step5数据获取。通过数据控制中心收集需要存储的数据,管理器对数据进行分割,使用哈西算法对数据进行二次重组,最后分发给注册的子电脑,由子电脑进行数据存储,实现了数据自能高效地管理,解决了数据因为过于集中存储而导致的容易丢失的问题。
2.3基于K-Means网格化的云数据管理建模
本文设计了一种K-Means网格化的云数据管理方法,主要通过以下几个步骤完成:
Step1数据汇总
① 首先,将各企事业单位的信息数据进行本地汇总;
② 其次,利用移动通信网络集中上传至公司调度指挥中心;
③ 最后,在相关部门的大力支持与协调下,大数据中心免费为平台提供所需的服务器、存储空间、数据备份等硬件资源,实现数据的集中存储与管理。
Step2网格数据分析决策
① 首先,进行信息传输。依托通信3G/4G网络将数据信息传至大数据中心;利用通信网络专线将各企事业单位的信息数据传输至数据网格化中心,进行大屏集中显示与调度;
② 其次,将网格化数据传输至数据模糊分析中心;
③ 最后,通过网格化数据传输与数据模糊分析中心的集中数据处理,实时分析作业相关数据,确定评价,反馈给责任部门,为决策提出有益的建议;左部分小面积显示数据的网格化划分视频,右部分大视角直观展现各个数据的实时消息。
K-Means网格化的云数据管理思想是通过求解建立的组合阈值模型,确定模糊、网格化聚类各自的赋值比重,使得最终确定的组合赋值更好地反映被评价系统的真实情况。

(3)

i=1,2,…,n
(4)
使综合评价值尽可能集中并体现不同评价对象之间的差异是综合评价的原则,这样能更好地体现数据的管理。
3 仿真及结果分析
本文实验数据是通过Matlab R2012b开发环境,在Windows 7操作系统的计算机上运行实现的。通过mvnrnd函数产生3组高斯分布数据data1、data2和data3,并将其作为本研究实验数据。其中图3、5、7分别是数据100组、1 000组、10 000 组时进行的K-Means聚类分析,其图像的生成是利用式(1)和式(2)进行图像的聚类;而图4、6、8分别是数据100组、1 000组、10 000组时的K-Means网格化聚类分析,图像的生成是利用式(3)和(4)进行图像的聚类。表1为两种聚类算法随机分类正确率和效率比较。
从图3~8可以看出:K-Means网格化聚类较K-Means更加清晰,能更好地展现聚类的效果。通过图3与图4中100组数据对比可以看出:K-Means网格化聚类效果比较个体,个别群体可以实现1对1的效果; 通过图5与图6中1 000组数据对比可以看出:K-Means网格化聚类能具体地表达出各个分类的效果,并且能对个别的群体进行详细的研究;通过图7与图8中10 000组数据对比可以看出:K-Means网格化聚类在区域化处理过程中已能完全地实现个体化服务,更加快捷地实现群体与个体服务。

图3 100行的K-Means聚类

图4 100行K-Means网格化聚类

图5 1 000行的K-Means聚类
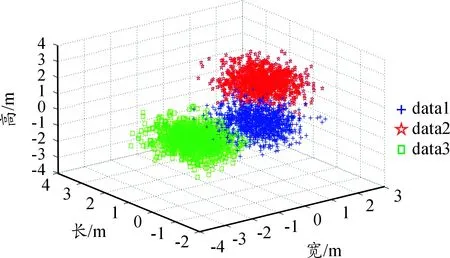
图6 1 000行K-Means网格化聚类
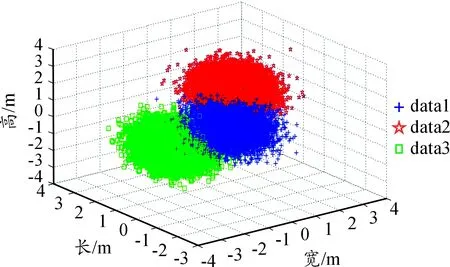
图8 10 000行K-Means网格化聚类

方法数据集运行时间/s数据集运行时间/s数据集运行时间/sK-Means1000.152110000.2282100000.3423K-Means网格聚类1000.062010000.0744100000.0892
从表1可以看出:在两种聚类算法准确率相同的情况下,K-Means网格的聚类算法运行时间低于 K-Means。由此看出本文的算法运行效率高于 K-Means,并能达到较好的聚类效果,证明本文算法具有较强的可行性和实际参考价值。
4 结束语
本文通过分析现有的K-Means聚类和网格化聚类的方法,将两种数据分析方法相结合引入到云数据的管理过程中。对现有的云数据管理模型进行了适当的改进,提出了一种基于K-Means网格化的云数据管理模型。此模型的主要特点是能够进行模糊聚类划分、网格化自动拟合数据分布函数,既能提高聚类的划分,实现个性化服务,又能减少网格数量的个数。
基于K-Means和网格化聚类的云数据管理模型充分考虑原有数据的分布情况,较好地表现了数据的不确定性,而且能随着数据库的数据误差阈值不断进行相应的网格化调整,为高质量地进行高层决策提供管理参考意见。
[1] 王世伟.论大数据时代信息安全的新特点与新要求[J].图书情报工作,2016(6):5-14.
[2] 冯登国,张敏,李昊.大数据安全与隐私保护[J].计算机学报,2014,37(1):246-258.
[3] LE GOALLER J P,CONDE C,LANGHA S.RDBMS in the Cloud:Oracle Database on AWS[Z].2013.
[4] HAITIAN F.A book to read large data commercial marketing[M].Beijing:Tsinghua University Press,2015:308-314.
[5] 朱东华,张嶷,汪雪锋,等.大数据环境下技术创新管理方法研究[J].科学学与科学技术管理,2013,34(4):172-180.
[6] Verizon.Verizon’s 2016 Data Breach investigations Report[R].Verizon Company,2016.
[7] MELL P M,GRANCE T.SP 800-145.The NIST Definition of Cloud Computing[M].USA:National Institute of Standards & Technology,2011.
[8] ARMBRUST,MICHAEL,FOX,et al.Above the Clouds:A Berkeley View of Cloud Computing[J].Eecs Department University of California Berkeley,2015,53(4):50-58.
[9] ABADI B D J.Data management in the cloud:Limitation and Opportunities[J].Institutt for Teknisk Kybernetikk,2010,32(1):3-12.
[10] CHOI D,SONG S.Concurrency Control Method to Provide Transactional Processing for Cloud Data Management System[J].International Journal of Contents,2016,12(1):60-64.
[11] VIET-DINH T.Cloud data management[J].ENS de Cachan,IFSIC,IRISA,KerData Project-Team,2010:1-5.
[12] HUSSEIN N H,KHALID A,KHANFAR K.A Survey of Cryptography Cloud Storage Techniques[J].Int.journal of computer science & mobile computing,2016,5(2):186-191.
[13] FOSTER,KESSELMAN C.The Grid:Blueprint for a new Computing Infrastructure[M].USA:Morgan Kaufmann Publishers,1998,34-37.
[14] 冯登国,张敏,张妍,等.云计算安全研究[J].软件学报,2011,22(1):71-83.
[15] 李海伦,黎荣,丁国富,等.应用遗传模糊聚类实现点云数据区域分割[J].计算机应用研究,2012,29(5):1974-1976.
[16] 吴伟.基于大联动网格化模式社区管理服务平台建设方案研究[D].厦门:厦门大学,2014.
[17] 王勇,唐靖,饶勤菲,等.高效率的K-means最佳聚类数确定算法[J].计算机应用,2014,34(5):1331-1335.
[18] 康暖.一种云计算基于网格化的设备管理方法[P].中国:CN103581319A.2014.
[19] 张新鹏,许春香,张新颜,等.基于代理重签名的支持用户可撤销的云存储数据公共审计方案[J].计算机应用,2016,36(7):1816-1821.
[20] 王志春.初始中心点优化的K-means聚类模型[J].电脑迷,2016(9):50-51.
[21] FOSTER,IAN,CARL KESSELMAN,et al.The Grid 2:Blueprint for a new computing[J].Infrastructure,2003,34(2):18-102.
[22] 杨海涛.城市社区网格化管理研究与展望[M].北京:经济管理出版社,2013:2-30.
(责任编辑陈 艳)
ResearchonCloudDataManagementModelBasedK-MeansandGriddingClustering
LIU Jialing, CHENG Chunyou, CHEN Zhuang, ZHU Yanrong
(College of Computer Science and Engineering, Chongqing University of Technology, Chongqing 400054, China)
2017-05-13
国家自然科学基金资助项目(71573026);重庆市研究生科研创新项目(CYS16222);重庆理工大学研究生创新基金资助项目(YCX2016252)
刘加伶(1963—),女,教授,硕士生导师,主要从事信息管理、数据库技术与应用研究;通讯作者 程春游(1992—),女,硕士研究生,主要从事信息管理与信息系统研究,E-mail:865565305@qq.com。
刘加伶,程春游,陈庄,等.基于K-Means和网格化聚类的云数据管理模型研究[J].重庆理工大学学报(自然科学),2017(9):119-124.
formatLIU Jialing, CHENG Chunyou, CHEN Zhuang, et al.Research on Cloud Data Management Model Based K-Means and Gridding Clustering[J].Journal of Chongqing University of Technology(Natural Science),2017(9):119-124.
10.3969/j.issn.1674-8425(z).2017.09.019
TP391.9
A
1674-8425(2017)09-0119-06
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
奋斗(2021年9期)2021-10-25
铁道通信信号(2020年4期)2020-09-21
铁道通信信号(2019年6期)2019-10-08
环境保护与循环经济(2017年2期)2017-09-26
雷达学报(2017年6期)2017-03-26
中国环境监察(2016年12期)2016-10-24
互联网天地(2016年1期)2016-05-04
