
SVR算法在商机管理中的应用
2017-09-23 03:02蒋丹妮徐玉清
计算机应用与软件 2017年9期
蒋丹妮 徐玉清
(复旦大学软件学院 上海 200433)
SVR算法在商机管理中的应用
蒋丹妮 徐玉清
(复旦大学软件学院 上海 200433)
随着市场竞争日益激烈和信息化技术不断发展,通过数据分析和挖掘来预测新的潜在商机成为了企业商机管理的重要环节。现有机器学习算法主要基于样本数目趋于无限大的假设,但实际问题中样本大多是有限的,甚至是小样本数据,难以保证机器学习结果的合理性。将支持向量回归(SVR)算法用于商机预测建模过程,用于解决小样本、高维数、非线性的学习问题。实验结果表明,与决策树等算法构造的目标函数求解结果相比较,SVR算法在有限样本空间能获得较高精度的预测结果。
商机管理 数据挖掘 支持向量回归机 分类算法
0 引 言
随着信息技术的飞速发展,数据挖掘和分析技术与传统信息系统相互结合,为企业提供了更高的应用价值和生产效率。商机管理通过客户维护、商业机会评估等商机过程管理以及商机客户、商机协作竞争分析等综合业务管理,帮助企业实现商机过程的全面管理和控制,以及有效分析客户价值并维护客户关系。选择合适的算法提高系统的分析精准性,能够使得企业在市场中更具竞争力,发现销售数据中的频繁盈利事件[1]。商机管理主要用于销售人员管理商机的基本信息,包括客户信息、商机状态、商机价值、商机规模、商机可能性等,通过对销售管线要素的定义,形成销售管理模型。
商机管理的核心意义就是实现对于客户关系的分析和预测,客户关系管理(CRM)使得企业与客户之间沟通更加完美[2-3]。商机管理的假设就是每类客户的价值都所有差异,企业主要工作的开展都应该以客户为中心。虽然目前已经有很多企业认识到了商机管理的重要性,但传统企业经营管理方式并没有改变,因此需要引进数据挖掘技术来提高商机管理的能力,对潜在的客户进行深入挖掘分析[4-5]。
在国内,商机管理仍处于发展的起步阶段,大部分是作为CRM产品的子模块,由专业CRM软件公司帮助销售人员按照标准流程进行商机的全流程管控。随着计算机、通信技术和网络应用的飞速发展,信息化和网络化理念已经深入人心,特别是大数据、云计算应用的兴起,很多企业有了相当的信息化基础[6-7]。然而,我国企业在商机数据价值的提炼和转化上仍然存在诸多局限性,大多停留在简单的数据操作阶段。很多企业面临的问题由客户管理转变为如何获取更多的有效信息,挖掘潜在客户特征并进行评估和跟踪。
而在国外,商机管理是伴随CRM发展起来的,互联网技术的迅猛发展更加速了商机管理的成熟应用,特别是Web站点、电子邮件、在线自助服务等使得企业进一步拓宽了服务能力,商机管理系统进入了真正的推广时期。随着大数据和云计算时代的到来,数据的价值得到充分重视,数据挖掘技术在商机管理中发挥的作用越来越大[8-9]。客户分类分析和客户盈利分析是数据挖掘在商机管理中的两类典型应用场景:
(1) 客户分类分析
数据挖掘技术能够实现客户群体的分类和聚类。通过对客户数据的收集、加工、存储以及分析处理,根据不同需求将大量客户数据分成不同类别。决策树是典型的分类方法[10],将决策树的每个叶节点视为一个独立的客户分类,从根节点到叶节点的路径对应一个属性判断序列,通过客户所处的叶节点位置可以预测他们的行为模式;聚类作为一种研究分类问题的统计分析方法,根据客户属性特征对客户进行群体划分从而实现客户细分,典型算法有K-means、SOM(Self-Organizing Map)、模糊聚类[11]等。
(2) 客户盈利分析
数据挖掘技术能够预测客户盈利能力的变化。一是对潜在的客户进行定性分析,该步骤也可以通过客户分类分析完成;二是客户盈利能力的定量分析,通过量化函数对客户的盈利能力进行估计和预测,如果需要做到较为精确的估算,则需要使用科学计算方法进行求解,例如基于统计的时间序列模型[12],典型的有ARIMA、Box-Jenkins、神经网络等数据挖掘算法。
在真实的业务场景中操作时需要克服以下几个问题:首先,每种数据挖掘方法都存在各自的局限性,难以得到理想的训练模型。例如线性分析预测的精度较低,分类回归树泛化的能力较差,人工神经网络需要的样本数较多,聚类分析可重复性差并且容易出错等。另一方面,由于实际问题中的样本数量是有限的,并且有数据噪声的存在,许多分析结果并不一定合理。
商机管理的核心在于构建商机分类与预测模型,利用组合方案挖掘并转化数据价值。支持向量机SVM是一种以有限样本统计学习理论为基础的通用学习方法[13],较好地解决了小样本、高维数、非线性等的学习问题。支持向量回归算法SVR是SVM的一种拓展类型,主要通过在高维空间中构造线性决策函数来实现线性回归,即可以有效地完成非线性拟合。本文基于SVR算法对商机管理的数据挖掘部分进行优化,采用集成优化策略避免单个模型过学习的问题,从而稳定提升模型性能。
1 商机数据预处理
数据预处理是将失效样本、噪声样本、重复样本等数据在建模之前清理,缩小样本范围,改善样本质量,减少甚至消除其对建模的影响。由于销售活动的各个阶段都可以产生数据,数据来源比较分散,所以在建模之前需要先对数据进行预处理。
1.1 客户信息数据整合
以客户信息数据整合为例,商机预测需要的数据主要来源于客户表(CustInfo)、客户详细信息表(CustDetailInfo)、客户维系记录表(CustVisit)、客户订单表(CustOrder)、客户关系群组(CustGroup)、关系群组信息(GroupInfo)、产品表(Product)等。数据整合就是把这些分散的表数据进行整理合并,减少复杂的多表关联方式查询数据。通过客户唯一编号关联各表,最后集成为较简单的数据表,提高模型计算的利用率。
1.2 数据建模变量选择
样本数据预处理完成后,需要选择或构造样本变量。样本变量选择的基本原则是变量应与目标值相关,即对不同类别的样本而言,变量或变量的组合应具有确定的或概率上的差异性。选择与商机识别有关的目标属性,区分数据挖掘需要使用到的信息。使用Apriori算法挖掘与销售成功事件相关联的属性值,并且建立一个具有缺省数据的规则库自动补充一些基本信息。首先将数值型数据离散化;其次是属性融合,由于Apriori适用于单维、单层关联关系的挖掘,而商机相关的属性至少是二维关联关系,因此需要将二维数据映射成单维数据。最后根据预先设定的置信阈值得到与销售成功相关的属性。
1.3 不同数据字段转换
在数据集成、数据抽取和建模变量确定之后,将处理过的数据保存在新的数据库表中。对于某几个属性值在不同表中的含义相同,但字段类型定义或者字段取值不一致的问题,在合并之后进行数据字段的统一转换。对于记录了客户隐私信息或者商业敏感信息的数据字段,将其转换为不含具体意义的数值类型。
1.4 数据清洗和数据修补
通过数据清洗过滤掉不符合要求的“脏数据”。系统仍然可能存在少量的缺失值和错误值,它们在一定程度上影响建模效果。数据的修补方法是灵活多样的,但针对具体问题使用合适的修补方法才能获得好的效果。本文使用“类内同分布随机补值算法”的补值算法,建模结果表明,按照该算法对缺失值进行处理,效果的确是比较理想的。
1.5 数据预处理任务的执行策略
数据预处理任务采用定时增量计算的方式运行。每次计算都根据数据的创建时间,取上一次任务以来增量的数据进行预处理。在分析任务开始时先运行该模块,确保异常数据得到处理。
2 基于SVR算法的商机预测分析
2.1 商机预测分类
商机预测分析利用采集到的商机样本数据,通过SVR算法进行数据挖掘并生成多个分类,例如客户商机可靠性规则、客户价值评估规则、客户流失评估规则、问题与答案关联规则等,这些为系统的商机应用管理提供可预测的能力模型。
构建集成目标函数是整个模型的关键。在商机采集数据预处理之后,本文使用多种方法构建集成目标函数,避免单一模型造成的过学习问题,增强训练模型的泛化能力。将数据划分为训练样本和测试样本两部分,对模型的进行训练和测试。选用测试样本进行测试,如果满足精度要求,则模型训练结束,否则选择另外的参数,直到建立的模型满足精度要求为止。
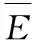
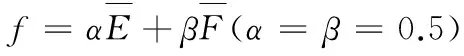
(1)
不同叶节点下C4.5决策树的性能变化趋势如图1所示。由图1可知,在相同样本集上建立的决策树,随着叶节点样本数阈值的变化,其性能是不断波动的;但是在相同叶节点样本数阈值条件下,不同样本集建立的决策树具有稳定的整体性能,该性能随着叶节点样本数阈值的增加而平滑降低。并且构造的目标函数具有收敛性,可以用于表征决策树的稳态性能。

图1 不同叶节点下C4.5决策树的性能
而随着叶节点样本数阈值的增大,单个样本集建立的模型稳定性下降的同时性能函数也逐渐降低。造成该现象的原因一方面是叶节点样本数阈值增大导致了模型的学习精度下降,并引起查全率的下降,从而使得学习性能下降;另一方面,叶节点样本数阈值的增大会造成模型的学习稳定性下降,使得学习性能波动幅度加剧。
不同叶节点下C4.5决策树的泛化能力变化趋势如图2所示。由图2可见,叶节点样本数阈值的变化并未引起泛化能力的显著下降。在叶节点样本数阈值接近70时,稳态泛化能力达到最佳。这是因为叶节点样本数的增加抵消了模型过学习带来的不利影响,从而达到了性能平衡。
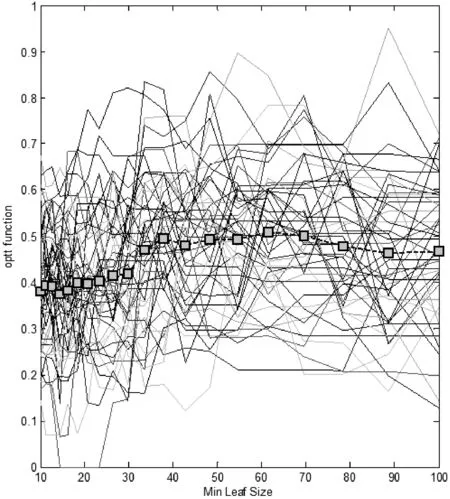
图2 不同叶节点下C4.5决策树的泛化能力
2.2 基于SVR的目标函数优化方法
为了得到最优的稳态模型,将前文的集成目标函数作为优化目标,优化模型参数。事实上,使用贪心算法、遗传算法、粒子群算法、模拟退火算法等均可以求解该优化问题,但由于目标函数是一个统计值,使用上述算法会使得计算十分复杂。下面基于SVR算法对目标函数进行优化。
SVR算法的思想是在参数定义域内按照一定的采样间隔张起一张正交网格,根据网格交点处的目标函数值,通过内插方法预测参数的最优位置。该算法具体步骤如下:确定SVR算法的核函数、核参数、精度误差ε、惩罚变量C。核函数设置为RBF核函数:
k(xi,xj)=exp(-λ‖xi-xj‖2)
(2)
其中λ=1/σ2即为核参数。λ和C的取值没有固定规则可寻,一般选择某一固定值ε,使用交叉验证法,对选取的核函数不断修改核参数和惩罚变量C的值,通过训练样本进行训练学习获取核参数λ和C的最佳组合。误差精度ε是系统要求的预测精度,取值一般在2%~4%,本系统取2%。模型预测评价指标选用式(3),选取最小SRE时的λ和C的取值,重复多次后得到最佳的参数组合。
(3)
确定支持向量表达式。λ和C参数确定后,利用约束公式计算b和w,就可以明确性能函数f(x)的具体表达方式:

(4)
3 实验分析
以某在线英语教育系统为例进行商机挖掘的案例分析。共获取该英语教育系统2014年3月至6月的客户行为数据4 325条记录,经过数据清洗和修复,去除含有缺失值、错误值等记录后得到3 288条合规记录。将该数据按2∶1的比例分为2 192条训练数据以及1 096条测试数据。
由于小样本数据质量较差,数据与需要解决的问题关联度不高,数据不平衡性非常严重,因此数据建模难度较高,难以通过人工调优或传统的寻优方法对模型进行优化。此外,目标函数的构造取决于实际问题需要,不同情况下的优化策略各不相同。
本文使用SVR算法对C4.5决策树构造的目标函数进行趋势分析,找出较好且稳定的一组参数解。将正交网格中的目标函数值使用ξ-SVR进行趋势分析,得到模型性能趋势如图3所示。

图3 上采样率-叶节点样本数阈值-目标函数的SVR趋势
由图3可知,当上采样率为7、叶节点样本数阈值为70时,模型的稳态性能达到最优。实际上,当目标函数不同时模型的最优参数值也不同。
除C4.5决策树之外,本文利用SVR算法对朴素贝叶斯(最佳上采样率、离散化数)和随机森林(最佳上采样率、最佳叶节点样本数阈值)的分类模型进行了优化,方法与C4.5决策树相似。同时,为了横向比较SVR的优化效果,使用人工神经网络(ANN)算法对上述三个分类模型进行优化。调优前和调优后模型的性能对比见表1所示。

表1 模型调优前与调优后性能分析
由表1可知,通过SVR的趋势分析法对集成目标函数优化之后,三种分类模型的稳态性能得到了较好地提升,特别是C4.5决策树构建的目标函数性能提升最大。与ANN算法相比,SVR算法对C4.5决策树和随机森林构建的目标函数优化更加明显,而对朴素贝叶斯模型调优后性能略低于ANN算法,但在可接受范围内。
总体说来,通过对比SVR在不同分类模型中的应用效果,实验结果表明SVR算法对小样本下的商机预测分类模型有明显的性能提升,尤其是在C4.5决策树目标函数寻优的趋势分析上有显著优势。
4 结 语
本文将SVR算法用于商机预测建模过程,用于解决小样本、高维数、非线性的学习问题。通过集成目标函数和基于SVR的趋势分析方法,提升分类模型稳态性,同时使模型具有较好的泛化能力。特别是对于C4.5决策树构建的目标函数,基于SVR的趋势寻优算法显著提升了模型性能。
本方法非常适合中小企业在收集数据样本不足的情况下使用,即在有限的样本数量条件下获得较为科学和精准的分类结果。销售人员可以根据分类情况得到有价值的潜在客户预测,从而采用合适的个性化营销方案提升企业的商机转化效率。
[1] Ait-Mlouk A,Gharnati F,Agouti T.Multi-agent-based modeling for extracting relevant association rules using a multi-criteria analysis approach[J].Vietnam Journal of Computer Science,2016,3(4):235-245.
[2] Qiu J,Lin Z,Li Y.Predicting customer purchase behavior in the e-commerce context[J].Electronic Commerce Research,2015,15(4):427-452.
[3] Khosravifar B,Bentahar J,Gomrokchi M,et al.CRM:An efficient trust and reputation model for agent computing[J].Knowledge-Based Systems,2012,30(2):1-16.
[4] Tsui P T,Li F C,Pang A H,et al.Using innovative customer relationship management technologies to explore the business opportunities of an ageing population and provide better service[J].SpringerPlus,2015,4(2):1-2.
[5] Beheshti S,Benatallah B,Motahari-Nezhad H R.Scalable graph-based OLAP analytics over process execution data[J].Distributed and Parallel Databases,2016,34(3):379-423.
[6] Tian X,Liu L.Does big data mean big knowledge? Integration of big data analysis and conceptual model for social commerce research[J].Electronic Commerce Research,2017,17(1):169-183.
[7] Loukis E,Kyriakou N,Pazalos K,et al.Inter-organizational innovation and cloud computing[J].Electronic Commerce Research,2016:1-23.
[8] Chan C C H,Hwang Y,Wu H.Marketing segmentation using the particle swarm optimization algorithm:a case study[J].Journal of Ambient Intelligence and Humanized Computing,2016,7(6):855-863.
[9] Liu Q,Huang S,Zhang L.The influence of information cascades on online purchase behaviors of search and experience products[J].Electronic Commerce Research,2016,16(4):553-580.
[10] Murthy S K.Automatic Construction of Decision Trees from Data:A Multi-Disciplinary Survey[J].Data Mining and Knowledge Discovery,1998,2(4):345-389.
[11] Bede B.Fuzzy Clustering[M].Mathematics of Fuzzy Sets and Fuzzy Logic,Berlin,Heidelberg:Springer Berlin Heidelberg,2013:213-219.
[12] Akaike H.A New Look at the Statistical Model Identification[M].Selected Papers of Hirotugu Akaike,Parzen E,Tanabe K,Kitagawa G,New York,NY:Springer New York,1998:215-222.
[13] Caserta M,Lessmann S,Voβ S.A Novel Approach to Construct Discrete Support Vector Machine Classifiers[C]//Advances in Data Analysis,Data Handling and Business Intelligence-Proceedings of the,Conference of the Gesellschaft Für Klassifikation E.v. Joint Conference with the British Classification Society.DBLP,2009:115-125.
APPLICATIONOFSUPPORTVECTORREGRESSIONALGORITHMINBUSINESSOPPORTUNITIESMANAGEMENT
Jiang Danni Xu Yuqing
(SoftwareSchoolofFudanUniversity,Shanghai200433,China)
With the increasingly fierce market competition and the development of information technology, the prediction of potential business opportunities through data analysis and data mining becomes an important part of business opportunities management. Most of machine learning algorithms are principally based on the hypothesis that the number of samples tends to be infinite, but the reality is different so that the reasonableness of the results cannot be guaranteed. Support vector regression (SVR) algorithm is used to predict the reliability of the data modeling process to address small sample, multi-dimension, nonlinear problems of the training model. The results show that SVR algorithm has a high accuracy of predicting results in limited sample space.
Business opportunities management Data mining Support vector regression Classification algorithm
TP3
A
10.3969/j.issn.1000-386x.2017.09.019
2016-11-10。蒋丹妮,硕士生,主研领域:流程管理,数据挖掘。徐玉清,硕士。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
玩具世界(2020年1期)2020-08-26
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子技术与软件工程(2016年24期)2017-02-23
电子制作(2017年24期)2017-02-02
中国机电工业(2016年5期)2016-12-01
海外星云(2016年7期)2016-12-01
