
构建适用于深度学习的海浪样本数据集的并行算法实现及性能优化
2017-09-23 02:57邹国良陈长吉郝剑波
计算机应用与软件 2017年9期
邹国良 陈长吉 郝剑波
(上海海洋大学信息学院 上海 201306)
构建适用于深度学习的海浪样本数据集的并行算法实现及性能优化
邹国良 陈长吉 郝剑波
(上海海洋大学信息学院 上海 201306)
采用深度学习算法来实现海浪等级的划分,数据来源于洋山港视频监测及同步海浪测量。针对近岸海浪识别系统中,构建海浪样本数据集中图像处理部分计算量超大的问题,设计一种海浪样本数据集图像处理的并行化运算方案。构建海浪样本数据集时,主要将视频进行关键帧提取,经过加权均值滤波去噪,生成与海浪等级对应标签,实现了海浪样本数据集的构建。在多核计算机上采用OpenMP对海浪样本数据集图像处理过程进行并行算法仿真,同时完善相关代码的性能优化。实验结果表明,设计的并行算法比串行算法大大地提高运算速度和多核利用率,当优化后线程K=8时,加速比可以达到24.29。该算法具有扩展性好、性能高、使用简单方便、价格低廉的优点,具有良好的实用价值。
深度学习 海浪样本数据集 关键帧 加权均值滤波 并行优化 OpenMP
0 引 言
2006年以来,机器学习领域取得了突破性的成功,伴随着计算机技术的长足进步,以及分布式云计算和大数据的兴起,人工智能迎来了春天。而深度学习便是实现云计算对大数据处理的核心算法。深度学习就是模仿人类大脑的学习过程,对外界大数据进行挖掘,找到其内在的联系。近年来,深度学习快速的发展并有着广泛的应用领域[1-2]:主要在语音识别与分类领域、图像识别领域、自然语言理解等。尽管在语音分类、图像识别领域,深度学习展示了惊人的优势,但在海洋领域,很少有人研究,相关成果也少之又少。现有的深度学习算法,基于的数据集太过单一,大部分都是针对特定的数据集开展,如人脸[3]、手写字体库[4]等。因此以洋山港视频监测数据为样本及同步海浪测量数据为依据,采用深度学习算法来实现海浪等级的划分。来构建适用于深度学习的海洋海浪视频数据集具有一定的理论意义。
随着多核计算机的普及和并行计算的快速发展,为了充分利用多核处理器资源,基于多核平台上采用并行计算的思维设计程序算法已成为当今多核的发展趋势[5]。而深度学习主要是通过训练大数据样本来提高其识别精度,训练大数据样本对计算资源有着巨大的需求,是高性能典型应用之一[6]。为了能快速地完成波浪数据集样本的计算任务,需要对串行的波浪数据集程序进行并行化设计,在多核计算机平台上利用OpenMP编程语言实现波浪数据集程序并行算法设计,并进行相关代码的优化。实验结果表明,文中设计的并行算法比串行算法大大地提高运算速度和多核利用率,为采用并行计算处理大数据样本波浪集提供一种高效、经济的实施方案。
本文利用深度学习的优势,基于上海海洋大学建设的洋山港海洋监控系统的实验条件,应用到海洋视频监测系统领域,构建了适合深度学习的海洋海浪样本数据集,提出了一种构建适合深度学习的海浪样本数据集图像预处理的并行化运算方案。所研究的内容可以实现洋山港监控系统业务化,为洋山港码头保驾护航,为上海市海洋业务起了积极的推进作用,更为以后申请上海市和国家海洋局重点海洋项目奠定了扎实的基础。
1 并行编程简介
在并行编程领域,OpenMP是一种基于共享主存技术的并行应用编程接口[7],通过在串行程序中添加编译指导语句,运行时库函数和环境变量等产生相应的可执行并行代码。OpenMP目前已成为并行程序设计的主流模型之一,只支持C/C++和 Fortran 语言,它具有易用性好、支持增量并行和数据并行等优点[8]。
1.1 并行编程模型
OpenMP是基于线程的并行编程模型,执行模式遵循了Fork-Join(派生/连接)[9],OpenMP并行程序的运行过程如图1所示。首先将程序划分为并行区和串行区,进程中的主线程负责执行串行代码,直到进入并行区 ( parallel region) 开始多线程并行执行并行区代码;主线程就立刻派生出一些子线程来并发执行程序的并行部分。当重新执行到程序的串行部分时,这些子线程将终止。运行在不同处理器上的线程之间可通过共享变量来实现数据的交换。如图1所示,OpenMP并行程序运行过程图。

图1 OpenMP并行程序的运行过程
1.2 OpenMP编译指导语句
OpenMP语句指令都是用一个特殊的标识符来标识的Fortran注释[10],必须在编译时加上OpenMP并行参数才能使其生效,不加编译参数,编译的程序仍旧是串行程序。在 C/C++ 程序中,OpenMP的所有编译制导语句均以#PRAGMA OMP开始来标识一段并行程序块,该标识后面可以跟具体的功能指令。!$OMP PARALLEL NUM_THREADS()和!$OMP END PARALLEL这两条并行指令指明并行区,指令!$OMP PARALLEL NUM_THREADS()是设定并行区线程数。!$OMP DO和!$OMP END DO是一组对循环执行并行指令的语句,但每个循环必须是无相关性的。!$OMP sections是开启块并行区,指令!$OMP section在每个并行块之前加上的并行块结构语句等[11]。
2 构建海浪样本数据集
文中的实验数据均来自上海洋山港实验基地,采用高清摄像头24小时全天候摄录,然后将数据拷贝出来,这样就得到了海浪的部分视频数据。所采集的海浪数据集,依托海浪同步视频序列,人工挑选特征明显的视频,由于视频里的声音格式无法在Microsoft Visual Studio 2010里读取,使用HIKVISION格式转换工具将声音格式转换为mp4格式,将格式转换后采用OpenMP进行预处理,包括以下几个步骤:
由于监控视频连续的特性,在一段连续变化的视频序列中,连续的前后视频帧存在的特征值是渐变的,即相邻帧的图像信息值变化不大[12]。视频读取使用VideoCaptur函数来实现,基本流程是用ViderCapture函数建立一个obj,使用get函数得到整个视频的总的帧数。将格式转换后的视频进行关键帧提取,关键帧可以代表一段视频的主要内容,图像熵包含了图像信息量的内容,本文就将图像熵引入关键帧提取中[13],将选取图像的信息熵最大帧作为视频关键帧。图像熵公式定义为:
(1)
式中:xi代表像素(x,y)的灰度值,f(xi)为整个图像像素值在xi中出现的概率。再使用for循环函数,图片命名是连接字符串的strcat函数,得到原始图像分辨率为1 920×1 080。由于海浪的波形具有周期性,所以用OpenMP把得到原始分辨率1 920×1 080图像按照一个波形周期截取分辨率为300×300的一个小块图像。
当高清摄像头全天候摄录海浪图像时,由于受光照、大气、雨水和温度的影响,会使摄取到的视频图像中存在大量噪声,从而会对海浪图像进行准确识别有一定的影响,对含有噪声的海浪图像进行去噪是非常重要。
均值滤波处理就是将图像局部窗口像素进行平均求值,而使图像边缘变得模糊化,将对海浪图像进行提取识别有一定的影响,本文使用加权均值滤波来代替均值滤波。加权均值滤波就是由窗口内各像素样本点的灰度值将滤波窗口中心点的灰度值加权平均获得,权值大小根据像素点与中心像素点相关性的大小而设定。离窗口中心点像素相关性越强的点,所得权值就越大,而处于窗口中心的像素点比其他位置的像素点的权值大,随着离窗口中心位置的像素点距离增加,权值反而要减少,在一定程度上可以使用加权均值处理来减少图像模糊化[14]。其加权均值滤波表达式如下:
(2)
式中:xj(x,y)表示滤波窗口中心点(x,y)领域内像素灰度值,wj(x,y)为滤波窗口中xj(x,y)对应的权重,g(x,y)为中心像素点滤波后的灰度值。本文使用的加权均值化处理,经过加权均值化处理所得图像特征明显,能够有效地抑制噪声像素对其邻域象素的影响,改进了图像边缘信号,极大地改善了滤波效果。但无效的特征信息也存在,然后进行统一处理,把他们的灰度值固定在一定的范围内,然后给其加上与海浪等级所对应的标签。到此为止,海浪等级的一个样本便生成了。重复以上步骤,为了加快训练速度,再把图像缩小至100×100的分辨率,构建对应的标签数据来完成适用于深度学习的近岸海浪识别样本数据集,再输入到CNN网络运行。
根据上海洋山港条件以及国家海洋环境预报中心通用海浪等级标准,划分为3个海浪等级,即一级、二级和三级,每个等级分别选取500幅、1 000幅、1 500幅三类样本图像,为分别构建了1 500、3 000、4 500样本训练集和对应的标签数据,当前已收集到的海浪等级图像经过预处理图像如图2所示。

图2 海浪图像预处理对应等级
3 海浪样本数据集并行化处理
深度学习主要是通过训练大数据样本来提高其识别精度,不足之处是计算量非常庞大。本文主要针对深度学习的近岸海浪识别系统,构建适用于深度学习的海洋样本数据集,对大量的海浪图片进行处理的时间花费很大。要急需提高计算效率,而并行算法是解决大数据量计算时间问题的主要手段之一。并行化实现模式是根据图像数据具有的数据量大、相关性高、规律性强等特点以及图像处理算法具有的领域性、分层性、顺序性、一致性的特征,依据并行化算法特征可分为全局可并行算法、局部可并行算法、不可并行算法三类[15]。
通过构建海浪图像样本数据集实验流程图,如图3所示,本文所使用的区域分解算法,每一张海浪图像处理过程是相互独立的,不存在数据之间的依赖性,因此可以实现对现有的算法进行并行化处理,中心思想就是将背景网格[16]区域中海浪图像分解成子图像,再分配到不同的处理器上同时运行。本文采用多尺度任务划分,实现多核并行模式,处理流程是把一个大型的任务分解为每个大小一样的子任务并分配给子线程,对数据进行按行划分,本文划分的依据根据海浪特征进行划分,以波浪一个周期为一个子任务,可以减少冗余,缩短时间,再分配给不同的处理器。由于每个子任务相互独立互不影响,并行进行数据块的处理,每个子线程处理结束后向主线程发回最终的结果。文中采用分块并行化处理主要基于两方面因素考虑:一是面对大数据量的波浪影像,要是不进行分模块处理,效率极低以及无法处理,关键是效果也难以得到保证;二是分块处理有助于发挥多核、集群等计算资源的高性能优势,进一步提高计算效率。构建适用于深度学习的海浪样本数据集图像处理并行化实现过程如图3所示。

图3 海浪预处理并行化流程图
并行程序算法结构如下:
#include
main(){
Omp_set_num_threads(K);
#pragma omp parallel for //启动K个线程
VideoCapture导入视频;
get获取总的帧数;
for(i=1;i< streamNumber;i++){//视频处理循环
分帧处理;
关键帧提取;
}
A=[ ]; //定义一个空矩阵;
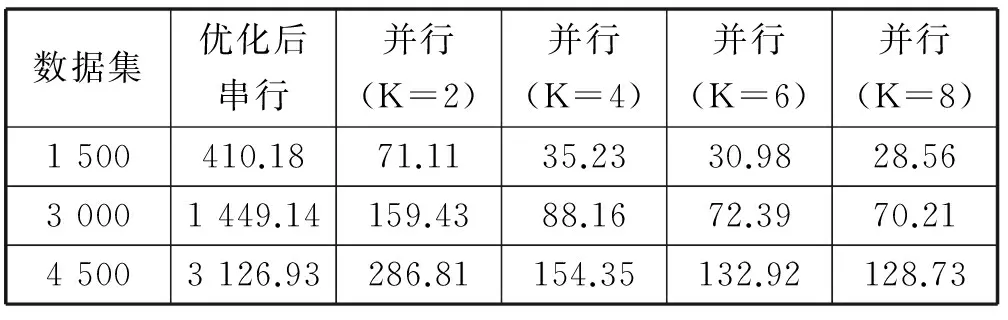
for(i=1;i 进行加权均值化滤波处理; 生成标签; 构建数据集; } } 本文主要采用并行域的扩展与合并和负载均衡这两种主要优化方法对构建适用于深度学习的海浪样本数据集图像处理的程序进行并行优化。 4.1 并行域的扩展与合并 并行域的扩展和合并[17]就是利用程序相邻的并行域区间重构来尽可能合并多个并行域,从而可以缩小程序并行区域的数目,让串行程序与并行程序之间切换减少不必要开销。以本文海浪预处理并行化设计为例,将多个并行域区间进行合并成整个程序大的并行域,分别如图4和图5所示并行域合并前后线程结构的对比。 图4 并行域合并前的线程结构 图5 并行域合并后的线程结构 4.2 负载均衡 负载均衡[18]是导致OpenMP多线程程序性能的重要因素之一,由于区域分块方法,每一个子线程计算区域不同,容易造成负载不平衡,优化效果不明显,存在并行开销问题。为了要保证系统中节点之间负载均衡,采用自适应背景网格方法,一段时间背景网格被自动重新定义,这样可以避免划分不均匀的问题,减弱负载的不平衡,达到程序性能最优化[19]。 5.1 实验环境 在调试和性能分析时,本次试验是基于四核处理器上采用Intel(R) Core(TM) i7—4800MQ CPU @ 2.7 GHz处理器,内存16 GB,操作系统为Win7-64 bit企业版,显卡为Intel(R) HD Graphics Family,编程工具为Microsoft Visual Studio 2010。 5.2 实验结果分析 本实验基于OpenMP编程平台对构建深度学习的海浪样本数据集图像预处理并行化研究。文中的实验数据均来自上海洋山港实验基地,采用高清摄像头24小时全天候摄录,然后将数据拷贝出来,这样就得到了海浪的部分视频数据。构建海浪样本数据集的处理部分主要分为两部分,第一部分是把视频进行关键帧提取,由于洋山港地理水文条件的限制,根据上文海浪划分为3个等级,在每个等级海浪视频上分别选取500幅、1 000幅、1 500幅的特征明显图片来进行实验将为下一步对海浪图像进行加权均值化处理去噪,实现标签完成样本数据集。第一步处理完成后,进行实验第二步把处理好了海浪图片打包成样本数据集,用于深度学习的近岸海浪识别的训练。实验分别对1 500幅、3 000幅、4 500幅特征明显的海浪图片打包成数据集进行并行处理,生成.mat数据文件。 实验流程如图3所示,实验分成两组,第一组实验分成三组数据进行测试,先使用串行算法进行测试,在把串行改成并行算法,再对并行程序算法进行性能优化(如表1、表2所示)。第二组实验采用同第一组实验相同的数据集,OpenMP与MPI、TBB进行对比实验(表3)。MPI是基于消息传递的并行程序,可以轻松支持分布式内存存储和共享式内存存储拓扑结构。广泛支持多种编程语言、操作系统以及硬件平台等[20-21],本文对比采用最新的MPICH[22];TBB是Intel开发的线程构建模板,是基于C++模板库的面向任务的并行编程模式[23-24],本文采用类似文献[25]中的算法。为了保证测试结果的稳定性,计算结果分别取10次的平均值,后面保留两位小数点,以秒为时间单位。 表1 优化前样本数据集的串并行时间对比 表2 优化后样本数据集的串并行时间对比 完成构建海浪图像样本数据集图像处理优化前串并行运算时间对比如表1所示,进行程序优化后串、并行运算时间对比如表2所示,随着大量的图片打包成数据集时,串行方法明显需要更多的运行时间,反观并行处理的性能提升倍数也随之明显增大。并行方法的优势就是提高计算速度,节约时间。并行计算的性能主要由加速比和并行效率两个方面衡量。 并行算法的加速比定义为: Sk=Ts/Tk (3) 并行算法的并行效率定义为: Ek=Sk/K (4) 式中,Ts为串行算法运行时间,Tk为并行算法运行时间,K为并行运行的线程数。如图所示图6为加速比对比曲线图,图7为并行效率对比曲线图。 图6 加速比对比曲线图 图7 并行效率对比曲线图 从图6加速比对比曲线图上显示是优化前后对比,在优化前线程K=2时,加速比最低值处于(4+),在程序优化后线程K=2时,加速比增加到(5+),并随着数据量不断的增加扩大,加速比也在不断增加但增加缓慢。但随着线程的增加K=8时,加速比增加趋势变大,以优化前数据量为4 500张海浪图片打包成数据集时,加速比可以达到23.45,而经过程序优化后,加速比增加到24.29。从图上数据的趋势观察看,具有一定的扩展性,可以根据实际应用需求来增加线程数,提高并行处理的性能优化。从图7并行效率对比曲线图上可得,当优化前数据量为1 500时,随着并行线程从2增加到8时,并行效率不增反而从2.41降到1.44,优化后并行效率从2.99降到1.80。当优化前数据量从1 500增加到4 500时,当K=2时,并行效率从2.41增加到5.24,当K=8时,并行效率从1.44增加到2.93,优化后,当K=2时,并行效率从2.99增加到5.45,当K=8时,并行效率从1.80增加到3.04。说明当数据量在一定范围内时,系统的额外开销增加会影响并行效率,反之随着数据量不断增大时,这些因素的影响比重会逐步减少,并行效率也会明显提高。但随着波浪数据集样本的数据量越来越多时,所花费的运行时间也在不断的增加。从图6可知,随着并行线程数的增加,运行的时间在不断减少但减少的趋势比较缓慢。 第二组实验在同一数据上进行(以4 500张数据为例),OpenMP性能程序优化后时间,分别与分布式编程MPI和线程构建模板TBB进行试验对比,试验结果如表3所示。 表3 OpenMP、MPI、TBB运行时间对比 表3表明,针对现有的海洋海浪图像数据,本文利用三种并行算法实验数据可得,随着线程个数增加并行运算效率将逐渐下降,当K=2到K=8时,OpenMP运算时间小于TBB运算时间和MPI运算时间。而当K=2到K=4时,MPI并行运算时间小于TBB并行运算时间。分析其主要原因,MPI主要是分布式机器之间数据传输,不易增量开发串行程序的并行性,它更适用于集群方面。在多核单机运行环境中,MPI的时间开销大于OpenMP,运算效率较低。由MPI测得时间数据可得,随着线程个数增加,MPI并行运算时间间隔不断的减小,因此MPI并行运算性能将逐渐下降。TBB是专用于编写高层抽象的C++程序,只针对任务编程,并行编程复杂,不支持动态线程负载平衡功能,相比OpenMP而言性能效果稍有不足。因此本文OpenMP并行算法在实际多核应用中具有使用简单方便、可扩展性好、性能高。 文中主要针对构建适用于深度学习的海浪样本数据集图像处理计算量超大的问题,设计了一种构建适用于深度学习的海浪样本数据集图像处理的并行化算法,并在多核计算机上采用OpenMP对并行算法进行编程实现。文中给出了实验处理的主要工作,在OpenMP多核平台上采用任务分解的并行模型编程,并在OpenMP平台上进行性能优化测试与结果分析。实验结果表明,文中设计的并行算法在OpenMP多核平台上经过程序性能优化加速比从23.45增加到24.29,最少可以在28.56 s对1 500张样本数据集构建成功。相对于其他并行算法模式,该算法具有扩展性好、性能高、使用简单方便,相比采用硬件提速花销基本无,具有良好的实用价值,可以运用到其他对实时性要求高的方面。 [1] Lee H,Yan L,Pham P,et al.Unsupervised feature learning for audio classification using convolutional deep belief networks[C]//International Conference on Neural Information Processing Systems.Curran Associates Inc.2009:1096-1104. [2] Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks[J].Advances in Neural Information Processing Systems,2012,25(2):1097-1105. [3] Phillips P J,Moon H,Rizvi S A,et al.The FERET Evaluation Methodology for Face-Recognition Algorithms[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2010,22(10):1090-1104. [4] Lecun Y,Cortes C.The mnist database of handwritten digits[OL].The Courant Institute of Mathematical Sciences,1998.http://yann.lecun.com/exdb/mnist/. [5] 张维琪,樊斐.自适应SSDA图像匹配并行算法设计与实现[J].计算机工程与应用,2014,50(20):64-67. [6] 白明泽,程丽.基于OpenMP的分子动力学并行算法的性能分析与优化[J].计算机应用,2012,32(1):163-166. [7] 吴俊杰,杨学军.面向OpenMP和OpenTM应用的并行数据重用理论[J].软件学报,2010,21(12):3011-3028. [8] Chapman B,Jost G,van der PAS R.Using OpenMP:Portable Shared Memory Parallel Programming[M].Cambridge:MIT Press,2007:23-34. [9] 罗秋明,明仲,刘刚,等.OpenMP编译原理及实现技术[M].北京:清华大学出版社,2012:28-31. [10] Liu Y,Li Y,Teng B,et al.Total horizontal and vertical forces of irregular waves on partially perforated caisson breakwaters[J].Coastal Engineering,2008,55(6):537-552. [11] 李提来,徐学军.OpenMP在水动力数学模型并行计算中的应用[J].海洋工程,2010,28(3):112-117. [12] 周兵,郝伟伟.一种适合于监控视频内容检索的关键帧提取新方法[J].郑州大学学报(工学版),2013,34(3):102-105. [13] Ren L,Qu Z,Niu W,et al.Key frame extraction based on information entropy and edge matching rate[C]//International Conference on Future Computer and Communication.IEEE,2010:V3-91-V3-94. [14] 赵娜娜.视频图像预处理关键技术研究[D].杭州:杭州电子科技大学,2012. [15] 杜根远,张火林,苗放.一种基于MPI和OpenMP的剖分遥感影像并行分割方法[J].计算机应用与软件,2016,33(9):180-183,207. [16] 张雁,吴保国,王晓辉,等.基于网格环境的遥感图像并行分类[J].计算机应用与软件,2015,32(2):194-197,219. [17] 游左勇.OpenMP并行编程模型与性能优化方法的研究及应用[D].四川:成都理工大学,2011. [18] 张志远,周宇峰,刘利,等.MASNUM海浪模式的性能特点分析与并行优化[J].计算机研究与发展,2015,52(4):851-860. [19] 黄鹏,张雄,马上,等.基于OpenMP的三维显式物质点法并行化研究[J].计算力学学报,2010,27(1):21-27. [20] 刘志强,宋君强,卢风顺,等.基于线程的MPI通信加速器技术研究[J].计算机学报,2011,34(1):154-164. [21] 王海涛,刘淑芬.基于Linux集群的并行计算[J].计算机工程,2010,36(1):64-66. [22] 剡公孝,申卫昌,刘骊,等.一种基于MPICH的高效矩阵相乘并行算法[J].计算机工程与应用,2009,45(26):72-73. [23] Intel Corporation Intel threading building blocks(TBB)[EB/OL].[2010-06-30].http//www.threading building blocks org. [24] 胡斌,袁道华.TBB多核编程及其混合编程模型的研究[J].计算机技术与发展,2009,19(2):98-101. [25] 郑晓薇,张建强.基于TBB任务调度器的N皇后多核并行算法[J].计算机工程与设计,2010,31(15):3423-3426. PARALLELIMPLEMENTATIONOFWAVESAMPLEDATASETFORDEEPLEARNINGALGORITHMANDITSPERFORMANCEOPTIMIZATION Zou Guoliang Chen Changji Hao Jianbo (InstituteofInformation,ShanghaiOceanUniversity,Shanghai201306,China) The deep learning algorithm is used to achieve the classification of ocean waves, data from Yang Shan Port video monitoring and synchronous wave measurement. Aiming at the problem that the construction of the wave sample data set in the image processing part has large computation in the offshore wave recognition system, a parallel computing scheme for image processing of ocean wave sample dataset is designed. When building a wave sample dataset, the key frame was extracted from the video, and the weighted mean filter denoising was used to generate a corresponding label of the wave level. Hence, the construction of the ocean wave sample data set was realized. We adopted OpenMP to perform parallel algorithm simulation for wave sample data set image preprocessing, and improve the performance optimization of related code. Experimental results show that the proposed parallel algorithm greatly improves preprocessing speed and utilization ratio of multi-core over a serial algorithm. Its speedup ratio can reach 24.29 as the thread is increased toK=8. We conclude that the algorithm has good scalability, high performance, convenient use, inexpensiveness and good practical value. Deep learning Wave sample data set Key frames Weighted mean filtering Parallel optimization OpenMP TP391 A 10.3969/j.issn.1000-386x.2017.09.012 2016-11-15。国家自然科学基金项目(11402142)。邹国良,教授,主研领域:海洋信息处理及应用。陈长吉,硕士生。郝剑波,硕士生。4 并行算法性能优化


5 实验结果与分析




6 结 语
猜你喜欢
现代电子技术(2022年8期)2022-04-13
幼儿园(2021年13期)2021-12-02
小读者(2021年2期)2021-11-23
中学生数理化·高一版(2021年2期)2021-03-19
书香两岸(2020年3期)2020-06-29
网络安全技术与应用(2020年1期)2020-01-07
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
科技传播(2013年22期)2013-08-15
西南学林(2011年0期)2011-11-12
