
云存储系统Master节点故障动态切换算法
2017-09-19 07:27:32马玮骏何晓晖
计算机技术与发展 2017年9期
马玮骏,王 强,何晓晖,冯 径,马 强
(解放军理工大学,江苏 南京 211101)
云存储系统Master节点故障动态切换算法
马玮骏,王 强,何晓晖,冯 径,马 强
(解放军理工大学,江苏 南京 211101)
为了解决大规模云存储系统中Master节点发生故障导致存储服务不可用的问题,建立了面向云存储系统管理节点发生故障时的故障影响分析模型。该模型以存储服务可用性、数据可靠性和数据可用性为分析目标,通过故障状态、管理节点实时状态以及管理节点故障的限制条件三个维度对故障影响进行分析,为恢复故障提供了有效的方法依据。同时,基于故障影响分析模型,提出了一种基于消息的Master节点故障动态切换算法—DSA-M。该算法通过基于序号的优先级策略实现了Master节点动态申请和切换,保证了云存储服务的高可用性。测试结果表明,DSA-M算法能够在Master节点发生故障时自动进行Master节点的切换和接管,恢复云存储服务的运行;通过控制故障检测周期,能够使得DSA-M算法的性能保持在相对稳定的区间内,随失效时刻的适应性也比较强。
云存储系统;Master节点;故障检测;元数据;动态切换
1 概 述
大规模云存储系统(Huge Cloud Storage System,HCSS)凭借规模大、覆盖范围广、访问量大、存储数据量大等特点,逐步成为业界的研究热点[1],而如何保证云存储系统的高可靠性、高可用性以及故障恢复问题一直是HCSS的重要研究方向。HCSS一般由一个Master节点,多个元数据管理节点和若干个存储节点构成,其中Master节点主要负责收集、检测各个元数据管理节点的工作信息,掌握云存储系统的全局运行状态。因此,当Master节点出现故障时,如何保证云存储服务的高可用性并尽快使其他元数据管理节点实现从普通管理节点至Master节点的无缝切换,是HCSS中需要解决的关键问题之一。
文献[2]给出了一种提高云存储系统可靠性的方法,并提出了多个云存储管理节点相互协作提供存储服务高可用和高可靠性的概念;文献[3]研究了OpenStack类云存储服务的同步瓶颈问题,并给出了一种轻量级的对象同步协议LightSync,减轻了同步负载;文献[4]描述了GFS通过Master节点MASTER状态、操作记录、检查点多机备份的方式确保可靠性和故障恢复的相关方法;文献[5]提出了一种基于纠删码的用于Hadoop平台的高性价比的容错策略,能够使用较低的代价提供云存储的高可靠性;文献[6]提出了一种基于低密度奇偶校验码的云存储系统框架,其中使用了一种裁剪纠错码来提高云存储系统的编码和解码性能;文献[7]从资源分配角度建立了云存储系统可靠性分析模型,并验证了模型的有效性;文献[8]基于云存储节点数据访问频率,提出一种副本备份算法,提高了数据的可靠性和云存储访问性能;文献[9]针对云存储系统的可靠性评价机制进行研究,并给出了面向传统被动容错和新型主动容错两类云存储系统的可靠性评价模型。为了提高云存储服务的可用性和容灾性,近年来一些研究人员将P2P技术融合至云存储架构[10-12]。文献[13]通过结合(n,k)-RS编码和X编码,为云存储系统设计一类新的准确修复编码,在一个或两个节点发生故障时,修复局部性以及修复带宽上都具有显著优势;文献[14]利用数据拆分及编解码的思想来解决云盘存储数据的可靠性问题;文献[15]采用双活容灾存储技术,构建了一个真正意义上的双活云计算数据中心;文献[16]提出了云存储系统故障自动化管理的策略框架、策略描述语言以及策略映射机制,提高了云存储系统故障自动化管理的可实现性。
可以看出,各类云存储系统或多或少都采用了数据冗余来保证数据的可用性和可靠性,数据可靠性指数据能够持久存储并且不丢失的概率,数据可用性是指数据持续可用的概率。数据可靠性可以看作是静态需求,而数据可用性则是动态需求。数据可靠性可以由数据冗余的方式提供保证,很明显,数据可靠,却不一定可用,如果存储系统软硬件出现故障,即便数据被可靠地存储,却不能被用户使用。
因此,云存储系统必须能通过有效的软硬件动态恢复技术使系统发生故障时能够自动恢复软、硬件的正常运行,尽可能地提供持续、正确的存储服务,保证系统存储服务的高可用性,这样才能保证数据的高可用性。
为此,围绕HCSS中Master节点故障失效时持续提供云存储服务的问题,提出了HCSS管理节点(包括Master节点和元数据管理节点)故障分析模型,并以该模型为基础提出Master节点故障自我恢复的相关算法。
2 管理节点故障分析模型
HCSS管理节点主要负责为云存储客户端提供元数据服务,同时需要检测各个存储节点的工作状态。通常HCSS中有多个管理节点,其中Master节点负责所有管理节点的故障检测。使用故障管理对象、故障的限制条件和表现以及故障管理对象的状态三个维度来表示HCSS中管理节点的故障分析模型。
设HCSS管理节点的故障状态空间SCSSM={s1,s2,…,sn};HCSS管理节点故障的限制条件和表现空间CCSSM={c1,c2,…,cm};HCSS管理节点实时状态空间RCSSM={r1,r2,…,rl}。在t时刻,存储服务可用性为SA(t);数据可靠性为DR(t);数据可用性为AD(t)。
记故障发生时间为t1,故障状态为sm,HCSS管理节点为oi,HCSS管理节点实时状态为rj,HCSS管理节点故障的限制条件和表现为ck,故障持续时间为Δt,则故障sm对存储服务可用性的影响记为:
Fsm→SA=fsm→SA(oi,rj,ck)∈[0,1]
(1)
设t2>t1,t2∈(t1,t1+Δt],则t2时刻系统存储服务可用性记为:
SA(t2)=SA(t1)(1-Fsm→SA)
(2)
式(1)中,fsm→SA表示故障sm对存储服务可用性的影响函数,该函数的取值范围为[0,1],取0表示没有影响,取1表示影响最大,使得系统存储服务可用性为0,即无法提供存储服务。
同理,设fsm→DR和fsm→AD分别表示故障sm对系统数据可靠性和数据可用性的影响函数,则t2时刻系统数据可靠性记为:
DR(t2)=DR(t1)(1-Fsm→DR)
(3)
t2时刻系统数据可用性记为:
AD(t2)=AD(t1)(1-Fsm→AD)
(4)
为了讨论简便,下面对影响函数进行二值化:
Fsm→SA=fsm→SA(oi,rj,ck)∈{0,1}
(5)
Fsm→DR=fsm→DR(oi,rj,ck)∈{0,1}
(6)
Fsm→AD=fsm→AD(oi,rj,ck)∈{0,1}
(7)
式(5)~(7)表示将故障影响简化为0和1两种取值,0表示没有影响,1表示有影响,这种简化对于界定故障的检测范围、恢复范围以及恢复时效是很有意义的。对于故障影响为0的故障,可以检测但不一定要及时恢复;对于故障影响为1的故障,是必须要进行检测和及时恢复的。
表1给出了HCSS管理节点在崩溃故障情况下的故障分析。其中,崩溃故障指节点宕机、掉电或系统崩溃等,对HCSS管理节点上存储的元数据随节点崩溃的丢失情况不做任何假设。
通过表1可以看出,与Master节点紧密相关的是r5状态,首先影响的是系统的存储服务可用性以及数据可用性,Master节点崩溃会导致其他HCSS管理节点无法获取全局的状态信息,这必然会影响元数据管理工作,因此系统数据可靠性也会受到影响。
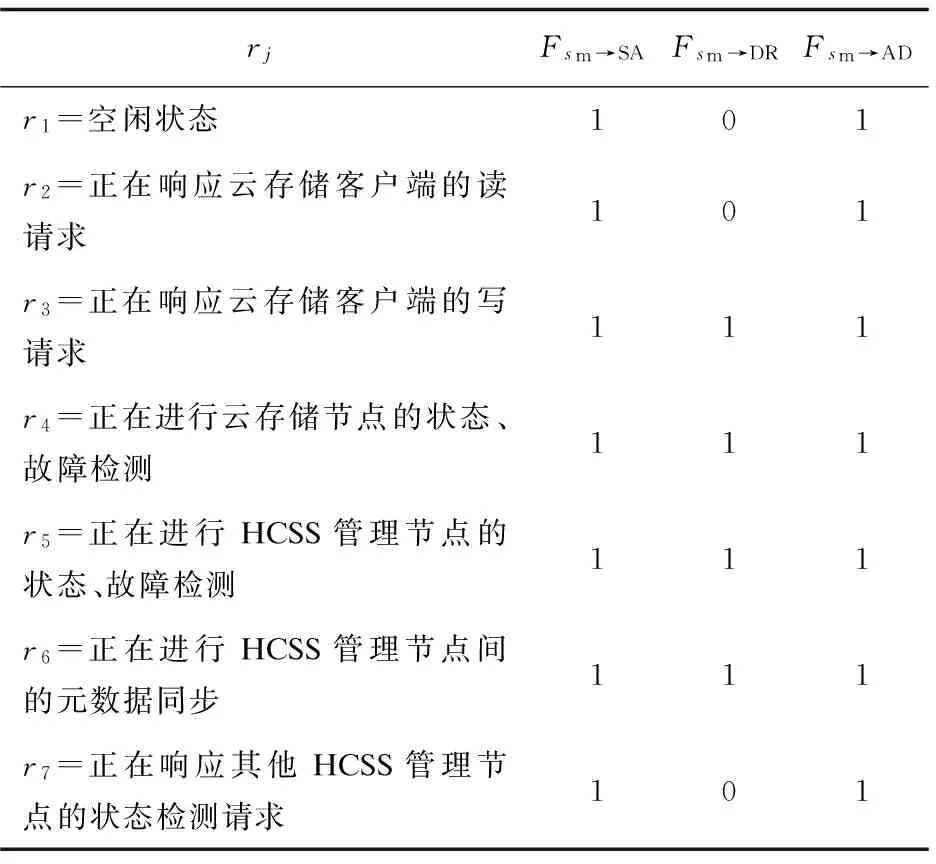
表1 HCSS管理节点崩溃故障影响分析
对于Master节点故障时的存储服务可用性自恢复,关键在于故障恢复软件能否在Master节点发生故障时,在r5状态下,使多个HCSS管理节点能迅速完成Master节点申请和接管,否则Master节点故障将导致系统的存储服务可用性、数据可用性都受到影响,也会影响系统的数据可靠性。
3 基于消息的Master节点故障动态切换算法
从故障影响分析模型的分析结果可以看出,由于同一时刻HCSS管理节点集合中只有一个节点作为Master节点,当Master节点出现故障,必须由其他HCSS管理节点动态接管Master节点的所有职能。
因此,提出了一种基于消息的Master节点动态切换算法(Dynamic Switching Algorithm for Master,DSA-M)。通过基于序号的优先级策略实现了Master节点失效时的Master节点动态申请及负载接管,保证了系统的存储服务高可用性。
3.1DSA-M算法设计
DSA-M算法的核心思想是:如果某个HCSS管理节点hj超过一定的时间没有收到Master节点hm的检测消息,就认为hm失效(崩溃),便开始申请为Master节点,如果所有其他节点都同意hj作为Master节点,hj便接管故障检测工作。
3.1.1 超时判定策略
算法中有两个超时时限,第一个是每个HCSS管理节点hj判断故障检测Master节点hm失效的超时时限,该超时通过式(8)进行计算:
(8)

如果hj发现超过Tme仍然没有收到hm的检测消息,则认为hm出现故障;Tme的选择需要谨慎,因为如果选择得过小,则会产生误判,造成频繁而没有必要的申请消息;如果选择得过大,则会造成长时间HCSS管理节点集合中没有Master节点,HCSS管理节点的故障信息以及状态信息不能及时更新。如果出现误判,则Master节点返回不同意消息。
第二个超时时限是每个HCSS管理节点hj在发出Master节点申请消息后,期望别的HCSS管理节点回执的超时时限,该超时记为MDT,取MDT为当前网络往返时延的最大值。这样取值的目的一方面在于避免由于个别被申请节点的时延较大而遗漏确认消息,另一方面在于减少多个节点同时申请Master节点的可能性,从而减少网络通信量。
3.1.2 优先级策略
为了减少通信量,避免多个节点同时申请,为每个节点设定申请的优先级。按照优先级,当某个节点申请成功后,其他节点无需再申请。优先级采用hj在云存储管理节点集合SCSSMN中的序号SNj进行定义,排在前面的节点申请优先级高,hj通过式(9)计算自己在怀疑Master节点失效后开始Master节点申请的等待时延:
TD=(SNj-1)×MDT
(9)
可以看出,排序越靠后的节点,需要等待的时间就越长。这里需要注意一个问题,序号的规定和发布是基于序号的优先级策略中的核心环节,如果序号固定,那必然存在申请不公平的现象,排序靠后的节点可能始终无法获得申请的机会。因此,算法中的序号主要通过Master节点进行生成和发布,而不是固定的,Master节点只需每次检测时更新序号的排列(可以采用随机排列),便能使各个节点的优先级发生实时变化,因此Master节点通过序号的公平分配,即可解决申请过程中的不公平问题。
3.1.3 节点失效处理策略
(1)申请过程中被申请节点失效:申请过程中,如果某个被申请节点失效,则无法响应申请节点的申请消息,此时申请节点可以通过超时机制进行处理,一旦某个被申请节点超时,申请节点便跳过该节点,强制实行接管,这样在第一个故障检测周期内,就能够检测出该失效节点。
(2)申请过程中被申请节点超时(但没有失效):申请过程中,如果某个被申请节点由于网络或者过载等原因超时,申请节点便跳过该节点,强制实行接管,这样在第一个检测周期内,就能够检测出该节点的实时状态,对于被申请节点,一旦收到检测消息,便进行响应,并更新Master节点。
(3)申请过程中申请节点失效:申请过程中,如果申请节点失效,则存在两种情况。第一种是申请进行了一半,此时必定有部分被申请节点无法收到申请消息,假设没有收到申请消息的第一个节点是hj,则一旦到达时间TD,hj会由于没收到申请消息而发出Master节点申请,因此其他节点最多等待TD即可收到申请消息。这里注意申请节点发送消息的顺序,应该与SN的顺序相反,这样,每次申请节点失效后,下一个申请节点可以在最短的时间内发出申请。例如:假设排序后的节点按SN顺序为h1,h2,…,hl,申请节点为h1,被申请节点总数为l-1,则h1发送申请消息的顺序为hl-1,hl-2,…,h2,h1如果在发送完给hk(2
另一种情况是所有被申请节点都收到了申请消息后,申请节点失效,在这种情况下,由于各个节点都承认了申请节点为Master节点,因此可以按照针对Master节点的超时机制进行处理,超时时限可以按照式(8)进行设定。由于排序越靠后的节点越先得到申请消息,因此如果靠后的节点由于超时设置太小而超时的话,则会发起申请,但是该申请消息不会被其他节点所接受,于是申请节点会继续等待下一个超时周期。
3.2DSA-M算法描述
DSA-M的算法描述如下所示:
算法1:DSA-M算法。
1:ON no MAIN_DETECT message from MainNode forTme=
2:SCSSMN←SCSSMN-hm;SNj←Sequence Number ofhjinSCSSMN;
3:ON no MAIN_REQUEST message from any Node forTD=(SNj-1)×MDT then
4:SendRequest(hm,MAIN_REQUEST);
5:fori=SNldown to SN1do //hi∈SCSSMN={h1,h2,…,hl}
6:ifi<>SNjthen SendRequest(hi,MAIN_REQUEST);
7:SetTimer;
8:ON ReceiveFromCSSMN(hi,MAIN_AFFIRMATIVE) then OK_COUNT++;
9:if(OK_COUNT=SCSSMN.Count-1)or(Timer>MDT) then
10:SetMainNode(hi);
11:StartDetect;
12:ON ReceiveFromCSSMN(hi,MAIN_NEGATIVE) then ResetToStep4;
13:ON ReceiveFromCSSMN(hi,MAIN_REQUEST) then
14:ifSNi≤SNjthen
15:SendResponse(hi,MAIN_AFFIRMATIVE);
16:SetMainNode(hi);
17:ResetToStep1;
18:else SendResponse(hi,MAIN_NEGATIVE);
19:ON receive MAIN_DETECT message from MasterNodehithen
20:SendResponse(hi,MAIN_DETECT_RESPONSE);
21:ResetToStep1;
22:ON receive MAIN_REQUEST message from other Node then//hm
23:SendResponse(hi,MAIN_NEGATIVE);
算法1中假设当前Master节点为hm,当前HCSS管理节点为hj。算法将管理节点之间的消息分为五类,分别是:
(1)MAIN_DETECTMaster:节点对其余HCSS管理节点的故障检测消息;
(2)MAIN_DETECT_RESPONSE:HCSS管理节点对故障检测的响应消息;
(3)MAIN_REQUEST:某个HCSS管理节点申请成为Master节点的申请消息;
(4)MAIN_AFFIRMATIVE:某个被申请节点同意申请节点的Master节点申请消息;
(5)MAIN_NEGATIVE:某个被申请节点不同意申请节点的Master节点申请消息。
第1行表示一旦任意一个HCSS管理节点hj(非Master节点)超过Tme都没有收到来自Master节点hm的消息,则启动2~21行的算法任务。
第2行表示在SCSSMN中去除hm进行重新排序,得到每个节点的SN。
第3~12行表示hj超过TD仍然未收到来自其他HCSS管理节点的申请消息MAIN_REQUEST,而执行的算法任务。
第4行表示首先给hm发送申请消息MAIN_REQUEST,防止对Master节点的误判造成系统中存在多个Master节点的情况。
第5~6行表示hj按照SN倒排的顺序对其他HCSS管理节点发出申请消息MAIN_REQUEST。
第7行表示发送完消息即设定一个定时器,用于检测对申请消息响应的超时。
第8行表示hj发出申请消息后收到了某个HCSS管理节点hi的同意消息MAIN_AFFIRMATIVE,此时hj将计数器加1,用于统计收到的同意消息数;第9~11行表示如果hj收到的同意消息数等于被申请节点数,或者等待同意申请消息超时,便置自己为Master节点,同时开始故障检测。
第12行表示如果hj收到某个HCSS管理节点hi的不同意消息MAIN_NEGATIVE,则hj重置本地定时器,恢复到第4步的初始状态,即刚发现hm失效的状态,继续等待TD,ResetToStep4函数负责状态的重置工作。需要注意的是,一旦hj的状态被重置,则它不会再处理任何MAIN_AFFIRMATIVE或者MAIN_NEGATIVE消息。
第13行表示hj收到来自hi的申请消息MAIN_REQUEST,第14~18行表示对消息中hi的序号SNi进行判断,如果SNi≤SNj,表示hi满足申请条件(优先级条件),hj便使用同意申请消息MAIN_AFFIRMATIVE响应hi,同时置hi为Master节点,重置自身的状态到发现Master节点超时时的状态,进入正常的运行流程,ResetToStep1函数负责重置处理;如果SNi>SNj,则表示hi不满足申请条件(优先级条件),hj便使用不同意申请消息MAIN_NEGATIVE响应hi。
第19~21行表示hj收到来自Master节点的故障检测消息,则立即响应MAIN_DETECT_RESPONSE消息,并重置自身的状态到发现Master节点超时时的状态,进入正常的运行流程。
第22~23行是Master节点hm算法,这里表示如果由于网络状态不稳定或者hm过载,造成hj的误判,则hm响应不同意申请消息MAIN_NEGATIVE。
该算法的优点在于:
(1)无需实时获取各个HCSS管理节点的状态,由于Master节点失效,状态检测结果可能会不一致,采用序号的方式进行Master节点申请计算工作,能够在HCSS管理节点状态不一致的情况下完成申请,并正确运行;
(2)采用序号的方式进行申请优先级计算,避免了不必要和过多的申请消息,申请过程中任何HCSS管理节点失效,算法依然能够保证正确性;
(3)Master节点申请和接管对于每个节点只需1次往返消息交互,消息代价很小,复杂度为O(N),N为HCSS管理节点数;
(4)可扩展性好,当HCSS管理节点增多,增加的消息量为常数,与节点数目无关;
(5)正常情况下,Master节点失效后,经过一个故障检测周期加上网络时延的时间,即可完成接管,不论网络条件如何,都能自动进行恢复,保证故障检测的有效性。
因此,DSA-M算法在Master节点处于状态hj并出现故障的情况下,保证了系统的数据可靠性。
4 实验及结果分析
实验采用5个HCSS管理节点,其中5号节点作为初始Master节点,在5个节点上运行DSA-M算法,测试当Master节点失效时,其他HCSS管理节点申请Master节点的性能。
测试中,故障检测超时取800 ms和200 ms,故障检测周期为1 000 ms,初始故障检测Master节点编号为5,故障检测Master节点申请回执超时为100 ms,测试进行100次。
测试过程中,使HCSS管理节点5(故障检测Master节点)停止响应任何请求(模拟崩溃故障,即失效),Master节点失效的时刻是随机的,记录Master节点失效的时刻t1与其他HCSS管理节点申请Master节点成功的时刻t2之差:Δt=t2-t1(申请时间),用于衡量Master节点失效状态下其余节点申请Master节点的性能。
测试结果如图1所示。
(10)

(11)
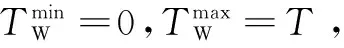
(12)
为了体现测试的全面性,考察当多个节点失效时Master节点申请的性能,失效节点组合按照(5)、(5,1)、(5,1,2),(5,1,2,3)四种,每一种组合内的节点都是同时失效,由DSA-M算法描述可知,申请的优先级是以节点序号计算,只要排序靠前的节点没有失效,排序靠后的节点将无法完成申请,因此以上四种组合使得每个节点(1,2,3,4)都有机会申请Master节点,是最有代表性的一种组合。
此外,由图1的分析可知,申请时间的变化依赖于Master节点失效时刻在故障检测周期内的分布,因此为了讨论方便,假设Master节点失效时刻按照间隔100 ms的规律均匀变化,考察一个检测周期内HCSS管理节点申请Master节点时间与失效节点组合之间的关系,如图2所示。

图2 多个节点失效时申请Master节点成功时间(失效时刻均匀分布)
从图2可以看出,节点失效的不同组合所对应的Master节点申请时间并不相同,这种差异主要来自于Master节点申请优先级的控制。由DSA-M算法描述可知,每个节点发现Master节点失效后,将延迟时间TD发送Master节点申请消息,因此排序越靠后的节点发起申请的延迟就越大,而延迟的时间和节点的序号以及最大往返时延(MDT)相关,测试中MDT=100 ms。图2中Master节点失效后,可以申请成为Master节点的HCSS管理节点有4个,因此当前n个节点都失效时,最大等待时延Twait(申请开始时间)和申请完成时间Tfinish分别为:
Twait=n×MDT
(13)
(14)
式(14)因为有多个节点失效,必然有节点会响应申请消息超时,因此会多一个超时时间MDT,这也是图2中多于1个节点失效时的申请时间要比只有Master节点失效时的申请时间普遍多100 ms左右的原因。因此在多个节点失效的情况下,申请时间可以使用式(15)计算。
(15)
其中,n表示从1号节点开始,连续失效的节点个数。
因此在多个节点失效的情况下,申请时间的变化范围为:

(16)
可以看出,通过控制故障检测周期T,便能够使得DSA-M算法的性能保持在相对稳定的区间内,随失效时刻的适应性也比较强。
5 结束语
存储服务可用性是衡量云存储系统好坏的重要指标之一,当云存储系统中管理节点出现故障时,如何快速恢复系统运行,确保存储服务的可用性是HCSS需要解决的关键问题之一。针对HCSS中Master节点失效导致存储服务不可用的问题,建立了HCSS中管理节点故障影响分析模型,根据模型分析结果,提出了DSA-M算法。当Master节点发生故障时,以多个HCSS管理节点之间并行工作为基础,通过基于序号的优先级策略实现了Master节点的动态申请和切换,保证了云存储服务的高可用性。
测试结果表明,DSA-M算法能够在Master节点发生故障时自动进行Master节点切换和接管,恢复云存储服务的运行。通过控制故障检测周期,能够使DSA-M算法的性能保持在相对稳定的区间内,随失效时刻的适应性也比较强。
[1] 刘 鹏.云计算[M].第3版.北京:电子工业出版社,2015.
[2] 马玮骏,吴海佳,刘 鹏.MassCloud云存储系统构架及可靠性机制[J].河海大学学报:自然科学版,2011,39(3):348-354.
[3] Chekam T T,Zhai E,Li Z,et al.On the synchronization bottleneck of OpenStack swift-like cloud storage systems[C]//IEEE international conference on computer communications.San Francisco:IEEE,2016:135-144.
[4] Kamath A,Jaiswal A,Dive K.From idea to reality:Google file system[J].International Journal of Computer Applications,2014,103(9):8-10.
[5] Wu C H,Hsu P.Cost-effective and reliable cloud storage for big data[C]//ASE big data & social informatics 2015.New York:ACM,2015.
[6] Wei Y,Yong W F.A cost-effective and reliable cloud storage[C]//2014 IEEE 7th international conference on cloud computing.Anchorage:IEEE,2014:938-939.
[7] Faragardi H R,Shojaee R,Tabani H,et al.An analytical model to evaluate reliability of cloud computing systems in the presence of QoS requirements[C]//International conference on computer and information science.Niigata,Japan:[s.n.],2013:315-321.
[8] Joolahluk J,Wen Y F.Reliable and available data replication planning for cloud storage[C]//IEEE international conference on advanced information networking and applications.Barcelona,Spain:IEEE,2013:772-779.
[9] 赵 畅. 云存储系统可靠性分析[D].天津:南开大学,2014.
[10] Song J,Deng J H.NOVA:a P2P-cloud VoD system for IPTV with collaborative pre-deployment module based on recommendation scheme[C]//International conference on materials science and information technology.Nanjing,China:[s.n.],2013:1566-1570.
[11] Chakareski J.Cost and profit driven cloud-P2P interaction[J].Peer-to-Peer Networking and Applications,2015,8(2):244-259.
[12] Babaolu O,Marzolla M,Trambrini M.Design and implementation of a P2P cloud system[C]//Proceedings of the ACM symposium on applied computing.Trento,Italy:ACM,2012:412-417.
[13] 李小兵,许胤龙,林一施,等.X再生码:一类适用于云存储的准确修复编码[J].计算机应用与软件,2014,31(8):241-244.
[14] 王 帅,常朝稳,王禹同,等.面向多云盘的N+i模式的编码冗余存储机制[J].小型微型计算机系统,2016,37(2):236-240.
[15] 吴礼乐.基于双活容灾存储技术的云计算数据中心的设计及应用[J].电子设计工程,2015,23(6):190-192.
[16] 马玮骏,王 强,何晓晖,等.一种基于策略的云存储系统故障管理方法[J].软件工程,2016,19(6):4-7.
Dynamic Switching Algorithm for Master Node in Huge Cloud Storage System
MA Wei-jun,WANG Qiang,HE Xiao-hui,FENG Jing,MA Qiang
(PLA University of Science and Technology,Nanjing 211101,China)
In order to solve the unavailable problem of storage service on account of the Master node fault in huge cloud storage system,an analysis model for fault effect of management node has been constructed,which takes storage service availability,data reliability and data availability as the analysis target.Three-dimensional element has been employed in the analysis model such as fault status,real-time status and restrictive condition so as to provide an effective method for fault recovery.Based on the analysis model,a dynamic switching algorithm for master node based on message called DSA-M has been presented,in which it implements the dynamic application and switching of Master node by PRI policy based on sequence number and ensures the high availability.Test results show that DSA-M has provided management nodes auto switching and taken over while master node is breakdown and high storage service availability.The performance of DRA-M also can be stable in relative region by reasonable control of fault detection cycle and DRA-M also has strong adaptability for crush moment.
cloud storage system;Master node;fault detection;metadata;dynamic switching
2016-05-09
:2016-08-10 < class="emphasis_bold">网络出版时间
时间:2017-07-05
国家自然科学基金资助项目(61371119)
马玮骏(1980-),男,讲师,博士,研究方向为网络管理、网格计算、分布式存储。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170705.1649.006.html
TP301.6
:A
:1673-629X(2017)09-0085-07
10.3969/j.issn.1673-629X.2017.09.019
猜你喜欢
包装工程(2023年24期)2023-12-27 09:18:26
海洋信息技术与应用(2021年1期)2021-06-11 01:20:34
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
通信产业报(2020年43期)2020-01-15 06:38:43
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
中国教育信息化(2015年12期)2015-08-24 07:58:36
电测与仪表(2015年10期)2015-04-09 11:48:20
河南科技(2015年7期)2015-03-11 16:23:13
中国卫生(2014年12期)2014-11-12 13:12:26
中国卫生(2014年8期)2014-11-12 13:00:50
