
基于计算机视觉的身份证号码识别算法
2017-09-14 06:48广东南方职业学院李美玲
电子世界 2017年17期
广东南方职业学院 李美玲
深圳大学信息工程学院 张俊阳
基于计算机视觉的身份证号码识别算法
广东南方职业学院 李美玲
深圳大学信息工程学院 张俊阳
针对图像采集过程中闪光灯开启造成的高亮区域,本文先通过自适应阈值分割算法去除身份证图像背景区域,并使用形态学操作提取并筛选轮廓的方法定位身份证号码区域,使用深度学习神经网络对切分得的字符进行识别。算法识别准确率高,文中使用了OpenCV库及caffe开源深度学习框架验证算法。
身份证号码定位;caffe;OpenCV;身份证号码识别
1 引言
图像是智能机器获取信息的重要来源之一,随着计算机视觉技术的发展,计算机视觉技术已经在工业上获得许多成功应用,例如零件缺陷检测、汽车自动辅助驾驶等领域。OCR字符识别技术也取得了重大的进展。身份证识别技术为OCR识别技术之一,目前身份证识别主要有基于匹配分类和基于机器学习的方法[1]。而随着深度学习的发展,深度学习正在颠覆传统领域,使用深度学习识别字符图像具有快速、准确率高等优势。
2 算法实现
本文主要针对的是拍摄设备近距离采集的身份证图像,要求身份证图像上号码信息较为清晰,人眼基本可辨别,且图像上身份证区域占据主要部分,无复杂背景干扰,当前图像采集器材分辨率、微距拍摄等功能已能满足要求,故在实际应用中是可行的。
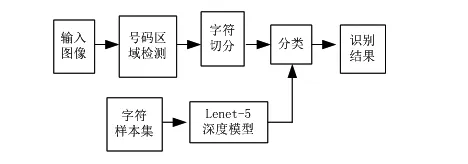
图1 基于计算机视觉的身份证识别算法框图
图1为基于计算机视觉的身份证识别算法框图,文中首先提取原始图像的R分量作为分析对象,针对拍摄亮度不足时,补光灯造成的图像亮度不均或存在高光等问题,采用自适应阈值图像分割算法去除身份证非字符区域,然后使用形态学操作使字符粘连的方法提取字符轮廓,根据轮廓面积及长宽比例提取身份证号码区域,最后切分身份证字符并使用已训练的lenet-5深度学习网络模型进行识别。
2.1 身份证号码区域检测
2.1.1 图像灰度化
身份证样张上字体为黑色,背景则为纯颜色,为使字体与背景具有更大的区分度,取身份证图的R通道作为图像的灰度化处理,为便于后期定位身份证号码区域时字符之间相互粘合,结合身份证图片长宽比例,依次在3种分辨率下尝试定位身份证号码区域,这3种缩放分辨率分别为:
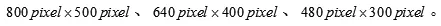
2.1.2 图像二值化
本文针对的是近距离拍摄的身份证图像,身份证整体轮廓占主要部分,由于身份证样张上字符颜色与背景颜色通常存在明显的差别,当采集的身份证图像光照均匀时,采用Otsu全局阈值二值化图像,二值化效果好;但由于光线不足,拍摄设备开启补光灯等原因造成高光区域时,Otsu全局阈值二值化效果不佳,这是由于Otsu算法没有考虑局部灰度信息的干扰[2]。
对Otsu二值化方法作出改进。
将图像切分为N×N块,对每一分块使用Otsu二值化算法计算得阈值,对其进行排序,排序后的阈值记为,对其中的中位数做均值滤波,使用滤波后的中位值作为图像二值化的全局阈值。经过实验将N设为5,滤波器核大小设为9。

图2 身份证图像二值化
图2为身份证图像二值化处理的效果图,可看出对于光照均匀或存在高光的图像,算法都能得到清晰的二值化号码。
2.1.3 形态学操作
对二值化图像作反色操作,并使用核大小为[15,3]的矩形结构元素对其做形态学闭运算,使号码字符发生粘连为一块区域,然后使用Opencv库自带轮廓检测方法检测各区域轮廓,并依据身份证号码轮廓面积及长宽比例筛选各区域,将筛选剩余的区域中最长的区域作为身份证号码区域,文中将长宽比例为 r =15,比例筛选范围设定为面积筛选范围设定为。
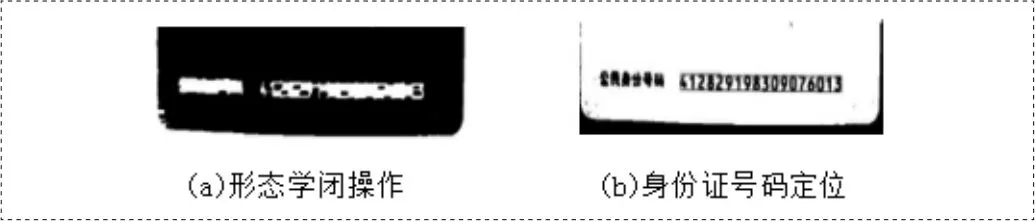
图3 形态学闭操作及号码定位
图3为形态学操作及号码区域定位的效果图,由于形态学的粘连效果受到结构元素大小的影响,故本文固定闭运算结构元素大小,并尝试在三种分辨率下提取身份证号码区域,以正确切分号码的位数作为是否定位成功的标志。
2.2 投影切分字符
先从R分量上依据定位得的身份证号码区域将其分割出,对分割得的图像作如下操作:
(1)使用Otsu二值化算法分割图像并进行反色,即字体为白色,背景为黑色。
(2)先使用水平投影法确定字符的高度,由于少部分字符之间可能存在粘连,故对垂直投影法做出改进,记身份证号码区域图像的宽度为W,为通过垂直投影法[3]确定的切割位置(包含起始点),若存在 k <18,则存在字符粘连。由于每个字符宽度为,假设粘连在一块的字符总数记为c,则使用下式判断粘连位置及粘连数。
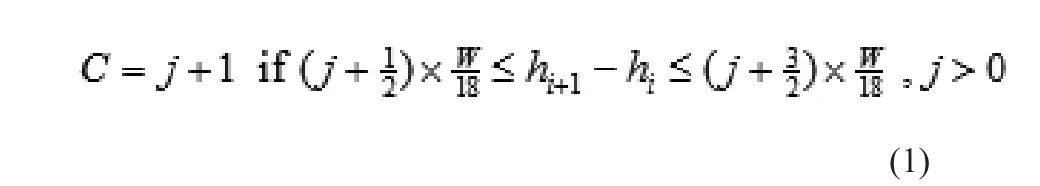
当满足公式(1)时,对[hi, hi+1]进行C均等分,可将粘连的字符分开。图4为正确切分的号码字符。

图4 字符切分结果
2.3 lenet-5深度学习模型
lenet-5是Yann LeCun教授针对手写数字图像所开发的卷积神经网络模型[4],其已经成功应用于商业,识别率可达99%以上,由于身份证号码的字符图像与手写图像具有一定的相似性,且字体结构较为固定,没有手写体随意,故本文采用lenet-5模型对身份证号码图像作训练及分类。图5为lenet-5的网络模型。
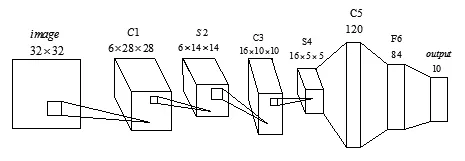
图5 lenet-5深度学习网络
其中,卷积层C1、C3所用卷积核大小均为5×5大小,采样层S2、C3通常为均值采样,感受域大小为2×2,其余则为全连接结构。
3 实验与分析
本文实验配置为Ubuntu14.04,GTX750Ti的机器,从网上及实际拍摄获得身份证图像共576张,分为两部分,其中的300张用于训练,276张用于测试。使用本文算法对训练样本做字符分割,可正确切分字符的样本为287,定位及切分准确率为95.66;
本文使用开源的caffe版本lenet-5进行实验。由于从训练样本获得的字符仅为4895张0~9二值图像,故通过添加噪声、小角度倾斜、不同阈值二值化等方法将字符集扩充为8W,通过10W次迭代,训练准确率为96%左右,在字符识别时,容易错分的是字符“3”和“8”、“0”和“9”。276张用于测试的图像可识别得251张,整体识别率为91%左右,具有较高的应用价值。
4 结论
本文提出了一种基于计算机视觉技术的身份证识别算法,算法对光照均匀图像和存在高光的图像均能有效地定位身份证号码,对垂直投影法作出改进以更适合分割粘连的字符,最后对于除校验位外的字符图像,使用lenet-5深度学习模型进行训练及分类,校验位可由前17位数字计算得到。
[1]李开,陈礼安,曹计昌.基于灰度多值化的身份证号码识别[J].计算机工程与应用,2015(13):191-196.
[2]许向阳,宋恩民,金良海.Otsu准则的阈值性质分析[J].电子学报,2009(12):2716-2719.
[3杨晓娟,宋凯.基于投影法的文档图像分割算法[J].成都大学学报(自然科学版),2009(02):139-141.
[4]高灿.一种基于CNN手写字符识别的改进方法[J].黑龙江科技信息,2017(03):164.
李美玲(1988—),女,广东廉江人,大学本科,主要从事通信工程设计与管理和楼宇智能化工程技术的教学工作。
张俊阳(1991—),男,广东揭阳人,硕士研究生,主要研究领域:模式识别。
猜你喜欢
新作文·小学低年级版(2022年5期)2022-08-30
小学生学习指导(低年级)(2020年6期)2020-07-25
音乐教育与创作(2020年9期)2020-02-21
故事会(蓝版)(2020年1期)2020-01-19
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
奥秘(创新大赛)(2019年10期)2019-10-24
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
华人时刊(2018年23期)2018-03-21
