
基于Lucene的企业电子文档搜索系统的开发研究
2017-09-07 06:37:49林钰杰吴丽贤
电子设计工程 2017年17期
林钰杰,吴丽贤
(广东电网有限责任公司 佛山供电局,广东 佛山528000)
基于Lucene的企业电子文档搜索系统的开发研究
林钰杰,吴丽贤
(广东电网有限责任公司 佛山供电局,广东 佛山528000)
随着企业信息化的发展,企业的信息资源越来越丰富,电子文档已成为企业信息传递、保存的重要形式,如何让员工快速全面地从海量的电子文档中找到所需的内容,日趋显得重要。针对企业电子文档搜索的现状和不足,本文研究了全文检索技术和全文检索工具Lucene,并将其引入到系统开发中,在主流的B/S分层架构基础上,重点对文本提取模块、中文词划分模块、索引模块和搜索模块进行了设计与实现,构建了一个基于Lucene的企业电子文档搜索系统。实践表明,本系统为企业员工提供了一种高效的电子文档检索方式,提高了员工的工作效率,改善了系统用户体验并提升了企业信息化水平。
Lucene;全文检索;电子文档;企业搜索引擎
随着企业规模扩大、业务拓展以及信息化发展,企业内部的电子文档信息每天都在快速增长,这些文档以不同的格式分别保存在磁盘和数据库中,总数据量十分庞大[1]。虽然几乎所有的信息系统都为用户提供了信息检索功能,但基本上仅支持关键字匹配查询,而且只能检索数据库中的信息,对于存储在磁盘上的文件却无能为力。部分系统会采用数据库自带的检索功能,但是检索结果往往不理想[2]。由于企业员工在日常工作中离不开对电子文档的频繁搜索,为避免大量时间和精力的浪费,改善搜索效果,提高工作效率,开发一个适用于企业内部的电子文档搜索系统是势在必行的事情。
全文检索(Full-text Retrieval)是现代信息检索技术的一个重要组成部分,是结构化、非结构化、半结构化数据处理的有力工具,尤其在非结构化数据处理方面,拥有比数据库技术更强大的检索能力[3]。在全文检索领域,Lucene是其中的佼佼者,应用Lucene的项目在全世界范围内已经非常之多,如主流Java开发工具Eclipse、Apache项目的邮件归档系统Eyebrows、著名房地产信息平台搜房网(http://search.soufun.com),来自 MIT的文档管理系统Dspace Federation,等等[4-5]。本文系统正是基于Lucene而构建。
1 全文检索原理
全文检索是指搜索系统对文档中的每一个词进行扫描,并对其建立索引,将这些信息保存在索引文件中。当用户输入关键词进行查询时,搜索系统便据此搜索索引文件并将结果返回给用户[6-7]。图1展示了全文检索的主要原理。
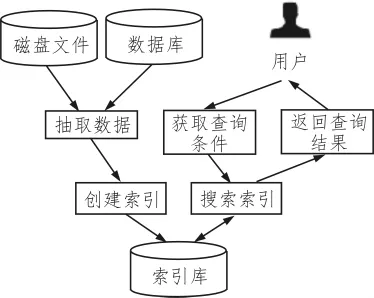
图1 全文检索原理
从图1可以看出,全文检索主要分为索引过程和搜索过程。索引过程是指从所有的结构化、非结构化和半结构化数据中提取信息并创建索引,主要步骤包括:
1)分词组件接收文档并对文档内容切词,去除标点符号和停词,得到词元;
2)分词组件将词元传递给语言处理组件,执行语言相关的处理,得到单词;
3)语言处理组件将单词传给索引组件,创建一个词典并排序,合并相同的单词,形成文档倒排链表。
搜索过程是指根据用户的査询请求搜索创建的索引,然后返回结果,主要步骤包括:
1)用户输入查询语句;
2)对查询语句进行词法分析,识别查询语句中的关键词;
3)对关键词进行语法分析,形成语法树;
4)对语法书进行语言处理,原理同索引过程;
5)利用语法树搜索索引,得到匹配的文档;
6)对匹配结果排序并返回给用户。
2 Lucene搜索技术
2.1 Lucene简介
Lucene是Jakarta项目组下的一个子项目,由Apache软件基金会提供支持。Lucene是一个基于Java的全文检索引擎框架,虽然不是一个完整的全文检索引擎,但其原生提供索引、查询、文字处理等模块,可方便开发人员根据需求开发特定的全文检索功能,并集成到各种业务应用系统中[8-9]。
Lucene主要有以下5个特点:
1)Lucene的索引文件基于8位字节长,可兼容不同的系统和平台,具有良好的独立性;
2)Lucene采用了分块索引来优化传统的倒排索引技术,可在合并原有索引的基础上建立小文件索引,从而达到提升索引速度的目的[10];
3)Lucene内置的查询引擎实现了十分强大的检索功能,可为用户提供布尔查询、模糊查询、分组查询等查询方式;
4)Lucene是基于面向对象系统架构设计的,学习难度较低,扩展性良好;
5)Lucene设计了独立于文件格式的文本分析接口,用户只需实现该接口即可扩展对新的文件格式的分析支持。
2.2 Lucene系统架构
Lucene的系统架构可以大致分为查询解析器、对外接口、索引核心和基础结构封装这4个部分[11],如图2所示。在源码上,Lucene共分为7个模块:
1)lucene.index是Lucene中的核心包,包括索引建立、索引优化、索引维护与管理等功能;
2)lucene.store包定义了Lucene的索引存储方式,包括内存存储和磁盘存储;
3)lucene.document包负责 Lucene的索引文件结构管理,通过定义与物理文件对应的逻辑结构Document,为索引文件的处理提供了统一的标准;
4)lucene.util包提供了公用的算法类;
5)lucene.search是Lucene的另一个核心包,主要负责检索管理,能够根据查询条件检索结果;
6)lucene.analysis包实现了一整套完整的分析体系,包括标准分析器和便于扩展的分析类接口;
7)lucene.queryParser是Lucene的查询解析器,可提供查询关键词之间的运算。

图2 Lucene系统架构
2.3 Lucene数据流
图3为Lucene的数据流,其中,虚线箭头对应索引过程,实线箭头对应搜索过程。Lucene共有4种数据流:
1)文本流表示索引目标和交互控制的对象;
2)Token流是Lucene对文字的一种抽象概念,是索引处理中的最小单元;
3)字节流是文件的一种数据格式;
4)查询语句对象流是查询解析时传输的数据。

图3 Lucene数据流
3 系统设计与实现
文中的目标是针对企业内部电子文档应用的需求特点,利用开源搜索工具Lucene来构建一个搜索系统,实现电子文档的全文检索,方便用户快速准确地查找需要的文档。系统的总体框架如图4所示,整个系统按照B/S的三层架构进行设计。下面将对文本提取、中文词划分、索引和搜索这4个核心模块的实现进行详细描述。
3.1 文本提取模块
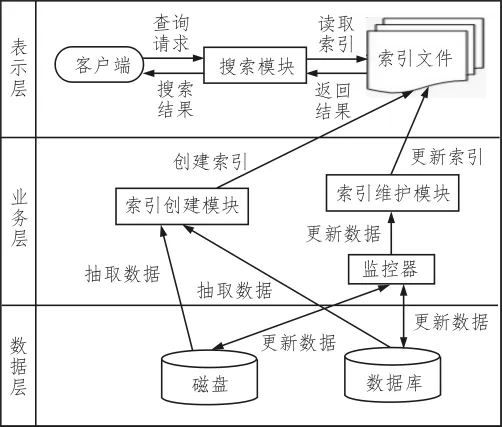
图4 系统总体框架
企业的电子文档大部分为Word、Excel、PDF等格式的文件,但Lucene的处理对象仅限于纯文本格式的数据。因此,系统必须能够从各种格式的文档中抽取出Lucene可处理的文本内容。本文选取Tika作为系统的文本提取工具。Tika也是由Apache软件基金会提供支持,是一个能够检测和提取不同类型文档的文本内容的开源工具[12-13]。通过集成PDFBox、Apache POI、EPUB等第三方功能包并封装为统一的API,Tika可对PDF文档、Office文档、电子图书等多种格式文件进行文本提取处理。而且,Tika还提供了可编程扩展的接口,可方便支持新的文件格式。调用Tika抽取文本的实现代码如下:

3.2 中文词划分模块
中文词划分可为中文文本建立正确、合理、高效的索引结构,是实现中文信息检索的前提。分词器是实现中文词划分的关键,分词器的好坏直接关系到搜索引擎的检索效果,良好的分词器能够对文档内容进行准确的切分以得到合理的单词,从而让系统在搜索时能够匹配出相关性更高的文档,使检索效果更加符合实际需要[14-15]。然而,Lucene自带的分词器在中文词划分方面表现并不理想,因此,本文引入算法更为成熟的mmseg4j分词器,以实现电子文档搜索系统的中文词划分功能,主要实现代码如下:


3.3 索引模块
如第1节所述,电子文档在建立索引后才能被系统检索。为此,索引模块需要实现以下3个功能:
1)索引创建。在Lucene中,IndexWriter类主要用于创建索引文件并将其保存于指定的目录中。在实际应用时,由于创建索引往往会产生比较小的索引碎片,因而在调用IndexWriter的构造函数创建实例后,还需要调用 addDocument、optimize、close 等方法把一系列的小索引碎片合并到一个文件中。索引创建的主要实现代码如下,其中,使用的分词器必须要和中文词划分模块中使用的保持一致:


2)索引管理。Lucene的IndexReader类主要负责索引在磁盘上的存放、加载和维护工作,例如,open方法可用于确定引用的具体磁盘文件和目录、lastModified方法可获取索引最近一次更新的时间、getCurrentVersion方法用于获取索引当前的版本号(新建的索引使用一个时间戳来标记,以后每更新一次,版本号就加1),等;
3)索引更新。考虑到企业电子文档绝大部分为归档性、共享性的资源,为避免频繁加载索引而影响效率,这里采用批量形式定时删除再追加指定索引的方式来更新索引目录。
3.4 搜索模块
搜索模块通过前端Web页面接收用户查询请求并进行相应的检索,这一过程包括用户查询信息的解析、查询分析、以及检索算法的运行。在图4中,系统的表现层包含了搜索的一般流程,其可总结为以下3个主要步骤:
1)查询请求接收。根据索引库的格式定义,本文系统提供了多种检索方式,用户可以按题目、作者、日期、摘要等关键词检索文档,也可以对文档正文进行全文检索。Lucene提供了与、或、非共3种逻辑运算,可将查询字段进行逻辑组合;
2)请求信息预处理。本文系统采用Spring MVC框架,在将前端的表单信息提交到后端代码之前,首先应用验证机制把非法数据过滤,如输入为空报错、输入信息类型不符等;然后,在进行检索之前,对提交到后端的信息进行一定的处理,包括编码转换、去除空格等;最后,把正确的信息提交给检索组件进行全文检索运算;
3)文档检索。检索组件接收到提交的信息后,便从其中提取出相应的查询项,调用索引文件进行检索,并把最终匹配的结果返回给前端页面显示。文档检索主要实现代码如下,其中,检索结果保存于collector对象中:

4 结束语
尽管目前互联网搜索引擎已得到迅速发展和全面普及,信息检索领域的自然语言处理和全文检索技术也逐渐成熟,但企业内部的信息系统仍然停留在基于数据库关键字的检索阶段,或者依赖共享文件库的文件系统提供的原始搜索功能,无法很好地满足员工对企业内电子文档的全文查询需求。为改善这种状况,本文深入研究了全文检索技术以及开源全文检索工具Lucene,并以B/S[16]的三层架构为基础,重点对文本提取、中文词划分、索引和搜索这4个模块进行了设计与实现,构建了基于Lucene的企业电子文档搜索系统。系统已在某供电局正式上线运行,有效解决了传统搜索文件方式存在的问题,帮助员工更高效、更准确和更全面地检索到所需的电子文档,节约了员工查找资料的时间,提高了工作效率,降低了办公成本。
[1]魏扣.全文检索技术在我国新型公共档案馆建设中的应用[J].北京档案,2013:11-14.
[2]刘涛.铁路物资目录全文检索技术研究[J].铁道技术监督,2012,40(5):38-41.
[3]梁苑苑,何婉文,王佳.全文检索系统在网站中的应用研究[J].电脑知识与技术,2012,8(4):842-845.
[4]王振风.基于Lucene的分布式全文检索技术的研究与应用[D].上海:东华大学,2015.
[5]向禹,吴世明.基于双层PDF和Lucene技术的全文检索研究与实现[J].现代情报,2014,34(6):75-78.
[6]吴代文,杨方琦.Lucene在数据库全文检索中的性能研究[J].微计算机应用,2011,32(6):53-59.
[7]周敬才,胡华平,岳虹.基于Lucene全文检索系统的设计与实现 [J].计算机工程与科学,2015,37(2):252-256.
[8]周锦程,王丹,余泉,等.基于Lucene的全文检索系统的研究与实现 [J].计算机技术与发展,2011,21(3):67-71.
[9]张琦玉.基于Lucene的应用系统内部搜索的研究与设计[D].南京:南京理工大学,2013.
[10]程芸芸.基于企业搜索引擎重排序的研究与应用[D].武汉:武汉理工大学,2014.
[11]朱崇来.基于Lucene的企业搜索引擎系统研究与实现[D].重庆:重庆理工大学,2012.
[12]胡小玉.大型企业管理系统中实时搜索引擎应用研究[D].北京:北京邮电大学,2014.
[13]罗惠峰.基于Lucene的站内检索系统的设计与优化[D].杭州:浙江工业大学,2015.
[14]曲哲凝.Lucene中文分词在电子档案全文检索中的应用研究[D].大连:大连海事大学,2015.
[15]邵星星.基于Lucene的中文分词技术研究[D].西安:西安电子科技大学,2012.
[16]廖珊.基于C/S与B/S混合结构的机房管理系统设计[J].电子科技,2016(5):172-174.
Research and development of the enterprise electronic document search system based on Lucene
LIN Yu-jie,WU Li-xian
(Foshan Power Supply Bureau,Guangdong Power Grid Limited Corporation,Foshan 528000,China)
With the development of enterprise informationization,the information resource of enterprises is becoming more and more abundant.The electronic document has become an important form of enterprise information transmission and preservation.It is becoming increasingly important that the employees find the desired content quickly and comprehensively from the mass of electronic documents.In view of the present situation and the insufficiency of the enterprise electronic document search,the full-text retrieval technology and the full-text search tool Lucene are studied and introduced into the system development.Based on the mainstream B/S architecture,the text extraction module,the Chinese word segmentation module,the indexing module and the searching module are designed and implemented,and an enterprise electronic document search system based on Lucene is constructed.It is shown that the system provides an efficient way of electronic document retrieval for enterprise employees,improves the work efficiency and the system user experience,and enhances the level of enterprise information.
Lucene; full-text retrieval; electronic document; enterprise search engine
TN99
A
1674-6236(2017)17-0102-05
2016-07-21稿件编号:201607157
林钰杰(1987—),男,广东佛山人,硕士研究生,工程师。研究方向:信息系统开发和管理、营配信息集成。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
信息安全研究(2016年4期)2016-12-01 06:06:54
现代计算机(2016年27期)2016-10-29 01:52:32
专利代理(2016年1期)2016-05-17 06:14:36
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
东莞理工学院学报(2014年3期)2014-07-12 13:21:36
阜阳职业技术学院学报(2013年3期)2013-04-29 13:40:50
电脑迷(2012年4期)2012-04-29 06:12:13
质量与标准化(2010年5期)2010-05-03 04:15:40
