
播存网络环境下UCL推荐多样性优化算法
2017-08-31 19:49董永强
计算机研究与发展 2017年8期
顾 梁 杨 鹏 董永强
(东南大学计算机科学与工程学院 南京 211189) (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189) (guliang@seu.edu.cn)
播存网络环境下UCL推荐多样性优化算法
顾 梁 杨 鹏 董永强
(东南大学计算机科学与工程学院 南京 211189) (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189) (guliang@seu.edu.cn)
播存网络将广播分发模式引入现有互联网体系结构,极大地降低网络共享过程中产生的冗余流量,可有效缓解信息过载问题.播存网络采用统一内容标签(uniform content label, UCL)适配用户兴趣和推荐信息资源,在UCL个性化推荐过程中,如何结合播存网络的富语义、高时效特征,有效地提高UCL推荐列表的多样性,成为播存网络中一个亟需解决的关键问题.针对播存网络环境的需求,提出了一种基于语义覆盖树的UCL推荐多样性优化算法UDSCT,将该问题分为UCL语义覆盖树构建和多样化UCL列表查询2个步骤.在UCL语义覆盖树构建阶段,基于语义覆盖树的若干约束条件,充分考虑UCL语义信息及非语义用户评分信息,同时,较新的UCL具有较高的优先权,以保证列表的时效性;在多样化UCL列表查询阶段,采用简单树查询及启发式列表补充操作,可快速高效地获得多样性优化后的UCL推荐列表,并可进一步根据用户请求快速返回指定的UCL集合.通过理论分析及一系列仿真实验验证,结果证明:UDSCT算法相对于基准算法能够获得更好的多样性优化效果及效率,可有效满足播存网络环境的需求.
播存网络;统一内容标签;推荐;多样性;时效性
互联网在给人们带来丰富信息资源的同时,自身流量也与日俱增.造成互联网协议流量激增的主要原因之一是互联网的内容访问日益呈现出幂律分布的特性,即大量用户对热门资源的重复性访问耗费了大量的数据传输带宽.现有互联网架构和内容传输技术体系越来越难以为高效信息共享提供有效的支持.
为改变这种局面,播存网络(Broadcast-Storage network, BSN)[1-2]把信息资源映射为互联网中可拆可聚的活版基元,将广播分发模式引入现有互联网体系结构,采用以“广播+存储”为特征的信息共享方式,通过物理广播将热门信息资源直接辐射分发到用户终端附近的边缘服务器供用户访问,从而利用物理广播的天然优势,突破传统信息共享方式所面临的宽带资源制约,实现“共享不限人数”的新型高效信息共享途径,极大地降低网络中共享过程中产生的冗余流量,从而有效缓解“信息过载”问题.
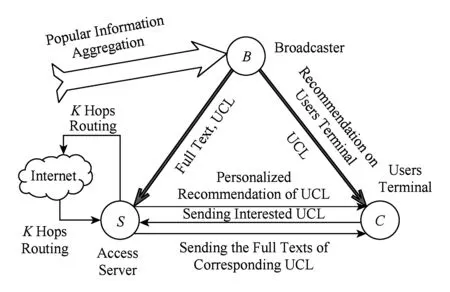
Fig. 1 The model of Broadcast-Storage network[3]图1 播存网络模型[3]
播存网络模型如图1所示[3].其中,统一内容标签(uniform content label, UCL)[4]与信息资源一一对应,包含信息资源的摘要信息,用户通过其接收到的UCL判断是否需要访问信息资源全文.同时,由于UCL数量巨大而用户接收能力有限,播存网络根据用户特点建立用户兴趣模型,预测用户对所有UCL的感兴趣程度(量化为预测评分),并采用主动推荐的方式将感兴趣程度较高的UCL推送给用户,帮助用户高效精确地寻找及访问其偏好的信息资源.而由于UCL种类繁杂、数量巨大,在推荐过程中,若仅依据用户对UCL的预测评分,容易造成所推荐的UCL相似度过高、种类单一,难以全面地挖掘播存网络中用户的兴趣.因此,如何在UCL个性化推荐过程中,在保证精度的基础上,尽可能地提高所推荐UCL的类别多样性,成为播存网络中亟需解决的关键问题.
本质上而言,该问题为信息获取领域的结果集合多样性优化问题,并已被证明为NP难问题.目前已有的解决方法多为启发式算法,可大致分为2条思路:置换启发式(swap heuristics, SH)[5]和贪婪启发式(greedy heuristics, GH)[6].假设最终的多样化集合包含k个元素,前者首先从所有待选元素中随机选出k个元素,然后遍历所有剩余的待选元素,逐一与已选出的元素进行替换比较,从而优化最终的集合多样性;后者采用k步筛选,每个筛选过程增加一个元素至集合,并保证当前的集合多样性最高,直至集合中包含k个元素.
然而,在播存网络环境中,传统结果集合多样性优化具有自身的一些局限性,具体表现在3个方面:
1) 难以有效确定加权参数.传统多样性优化方法往往需要设定加权参数以在精度及多样性之间取得平衡.通常,数据集的特征对加权参数的确定有重要影响.而在播存网络环境中,由于UCL分发较为频繁,数据集不断变化,很难确定一个恰当的加权参数能够持续保证UCL推荐的多样性及精度.
2) 缺乏UCL时效性处理机制.播存网络环境中UCL包含信息资源的摘要信息,与信息资源一一对应,更新速度快,具有很强的时效性.传统多样性优化方法很少考虑优化对象的时效性,容易导致优化后的集合中包含比较陈旧的UCL,降低用户体验.
3) 无法快速产生优化结果.UCL数目巨大,在播存网络持续动态运行时,如何基于大量的UCL数据快速及时地为用户提供多样性优化结果尤为重要.传统多样性优化方法通常需要大量的迭代运算,收敛较为缓慢,无法高效满足播存网络的需求.
针对上述3个问题,本文基于语义覆盖树提出了一种适用于播存网络环境的UCL推荐多样性优化算法(UCL diversification based on semantic cover tree, UDSCT),能够克服传统多样性优化方法在播存网络环境中存在的不足,并可充分利用UCL语义信息及非语义用户评分信息,在保证UCL推荐精度的前提下,优化UCL推荐结果的多样性.
1 相关工作
目前,播存网络的相关研究主要围绕互联网访问特征、播存网络的基本架构、UCL的格式设计与标引及播存网络环境中的UCL个性化推荐机制等几个方面展开.
文献[7]提出用户对Web网页的访问是由用户需求行为确定的一个随时间演化的复杂双模式二分网络,并通过实证研究分析发现,其入度分布呈现出典型的无标度特征和集聚现象.文献[8]对互联网中用户访问Web网页时所产生的路由跳数进行了研究与测量,得到每条访问记录所需的平均路由跳数为13.11.文献[7-8]为播存网络模型提供了理论基础与数据支撑.
文献[4]对播存网络的原理与基本模型进行了系统详细的阐述.文献[2]进一步对播存网络模型进行了研究,给出了播存网络的普适模型及其数学描述,并重点研究了4种实现模式,为播存网络提供了严格的定义及规范.播存网络中,用户通过UCL判断是否需要某条信息资源.文献[3]针对播存网络的特点,提出一种播存网络环境下的UCL推荐方法,可根据用户的历史访问记录建立用户特征模型,精确预测用户可能感兴趣的UCL.然而,文献[3]未考虑UCL推荐列表的多样性,本文在文献[3]的基础上重点研究UCL推荐的多样性优化问题.
结果集合多样性优化问题已在信息获取领域得到广泛关注,研究人员已经证明该问题为NP难问题,并提出了多种启发式解决方法.Adomavicius等人在文献[9]中指出,采用启发式算法改变初始推荐列表中项目的排序可使得推荐性能,尤其是多样性得到很大提高,并且启发式优化算法在逻辑上独立于预测算法,算法可部署性较好.根据算法设计思路,现有基于启发式思想的推荐列表多样性优化研究主要可以分为2条思路:置换启发式(swap heuristics, SH)和贪婪启发式(greedy heuristics, GH).
GH方法根据选定的效用函数依次从总集合中选出当前最佳的项目加入子集合,其中效用函数可以采用相关性函数或者距离函数,不同的效用函数会带来差异性的多样性优化效果.Carbonell等人[10]提出采用最大边缘相关(maximal marginal relevance, MMR)作为效用函数的贪婪优化方法,是该领域的先驱性研究之一.此后,研究人员进一步针对效用函数进行研究.文献[11]提出多样性效用函数所需满足的一些公理,并指出目前没有任何一种方法可以同时满足这些公理.Ziegler等人[12]提出了一种基于推荐列表内部相似度最小化思想的多样性优化效用函数,在每次进行贪婪选择时,最小化当前推荐列表的内部综合相似度.Ashkan等人[6]提出一种DUM方法,将推荐列表多样性优化问题转化为子模函数约束条件下的模函数最大化问题,该方法的特色在于仅需要最大化模函数,降低了问题复杂度.
与GH方法不同的是,SH方法首先初始化一个待推荐项目子集合,然后逐步遍历总集合中的其他元素,并与子集合中的某个元素交换,以提高子集合的多样化.Erkut等人[13]分析了SH方法的特点,并将该方法划分为2种:1)选出第1个能够提高当前子集合多样性的项目并进行置换;2)选出能够最大幅度提高当前子集合多样性的项目并进行置换.Erkut等人认为通常情况下前者的效果更好.Vieira等人[5]进一步研究SH方法发现,在置换过程中加入随机性会取得更好的效果,针对这种现象,他们通过分析发现,在优化过程中,一些对当前集合多样性没有提高作用的项目在后续过程中可能会产生有益影响.Liu等人[14]提出一种多置换(multi-swap)策略,在一次置换过程中,考虑同时置换多个项目,加快了算法收敛速度.
除了SH和GH启发式方法,也有研究人员尝试从其他思路解决该问题.文献[15]利用多臂bandits模型学习优化推荐集合多样性,该方法基于用户的点击行为,可及时捕捉用户兴趣变化,及时调整优化效果.但该方法忽略了优化对象的语义信息,抑制了集合多样性的提高.文献[16]引入概率模型解决推荐系统中多样性与相关性之间相对矛盾的问题,并通过控制参数调整二者的重要性.虽然这种混合模型在很多场景下效果不错,但一般情况下很难获得一个通用的算法控制参数.Qin等人[17]提出利用规则熵提高多样性,并证明了方法的有效性,但仍然需要提前设定算法控制参数.Drosou等人[18]提出一种基于覆盖树的方法优化集合多样性,取得了不错的优化效果,但该方法仅基于用户的评分模式,同样缺乏利用优化对象语义信息的机制.
上述研究成果涉及到播存网络及结果集合多样性优化2个方面,为本文研究提供了指引与启发.但是,综合分析以上研究可知,已有多样性优化方法在播存网络环境下存在不少问题:一方面,播存网络环境下UCL数量巨大,更新频繁,而已有方法大多需要基于当前已有数据通过预先运算寻找合适的控制参数,以提高结果集合的多样性,无法高效满足播存网络环境要求;另一方面,播存网络环境下UCL对应于信息资源,具有明显的时效性,已有方法主要针对多样性与相关性,缺乏对时效性的考虑,容易造成优化后的结果集合“过时”,降低播存网络环境中的用户体验;此外,由于UCL的数量巨大,播存网络环境下用户对于UCL的反馈速度要求更为迫切,已有方法大多需要大量迭代运算,效率有待提高完善.
基于以上分析,本文提出一种基于语义覆盖树的UCL推荐多样性优化算法UDSCT,克服已有方法在播存网络环境中存在的不足.首先,本文在普通覆盖树基础上,面向UCL设计了一种时间敏感的语义覆盖树,在构造该树的过程中同时考虑了用户评分模式及UCL语义信息,且时效性较强的UCL优先插入树的顶端;其次,本文基于该树提出了具体的多样性优化算法,包括1种子集合初步查询算法及2种启发式调整算法,本文还设计了用户请求响应机制,可快速反馈与用户指定UCL高度相关的结果集合;最后,本文证明与分析了上述多样性优化算法及用户请求响应机制的正确性及有效性,仿真实验结果表明,该算法具有良好的优化效果,可有效满足播存网络环境下UCL推荐多样性优化的需求.
2 UDSCT算法详细描述
本节首先描述基于语义覆盖树的推荐列表多样性优化算法的总体流程,然后给出算法相关的形式化定义,最后详细描述具体的UCL语义覆盖树构造算法及UCL推荐多样性优化算法.
基于语义覆盖树的UCL推荐列表多样性优化算法的总体流程如图2所示.该算法首先根据时间顺序构建时间敏感的UCL语义覆盖树,然后基于该树通过查询操作及补充算法获得多样化的UCL列表,最后将该UCL推荐给用户并根据用户请求响应聚焦请求.
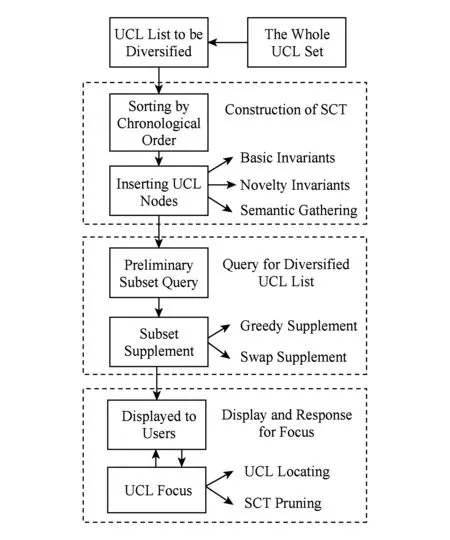
Fig. 2 The flow chart of UDSCT图2 UDSCT算法流程图
2.1UDSCT算法相关定义
为更清楚地描述该问题及其解决算法,本节给出了相关定义.
定义1.k-UCL列表多样性优化.令I={i1,i2,…,im}为UCL列表,U为多样性度量函数,k为正整数(k≤|I|),k-UCL列表多样性优化目标为寻找I的最优化子列表S*,满足条件:
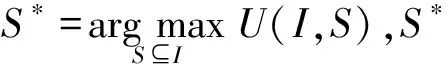
(1)
在获得当前最优UCL子列表后S*,系统将其呈现给用户,用户可能对其中的某一个UCL感兴趣,并希望得到一个与该UCL相关度更高的子列表.本文将这个过程定义为聚焦,形式化描述如下:
定义2. UCL聚焦.在定义1的基础上,聚焦操作根据用户的反馈查询当前最优UCL列表S*中更符合用户兴趣的子列表S′,使得:
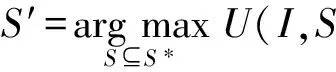
(2)
以上定义均基于语义覆盖树实现,语义覆盖树由覆盖树发展演化而来,覆盖树最初由Beygelzimer等人在文献[19]中提出,用以快速查找最近邻.覆盖树为分层的树数据结构,树中的每一层均覆盖其下面所有的层,树中的层数用整数l标示,且l从上往下逐步减小.对于给定的一个项目(如UCL)列表S,S中的每个项目均对应于覆盖树中的至少一个节点.
定义3. 覆盖树.令Cl表示第l层的节点列表,d(p,q)表示节点p和q之间的距离,覆盖树必须同时满足3个约束条件:
1) 嵌套性.Cl-1⊂Cl,即如果p出现在第l层(p∈Cl),则它必出现在第l层之下的所有层(p∈Cj,j>l).
2) 覆盖性.对于每一个p∈Cl,有且仅有一个q∈Cl-1作为p的父节点,且q满足d(p,q)≤1/2l-1.
3) 分离性.所有的p,q∈Cl,均满足d(p,q)>1/2l.
基于覆盖树的以上特性,可以总结出其在UCL推荐多样性优化问题方面所具有的独特优势.一方面,覆盖树由多层节点构成,每一层都包含了不同数目的节点并且同层节点之间的距离均存在最低阈值,该阈值随着树高度的降低而逐步减小,即上层中的节点之间最小距离较大,而下层中的节点之间最小距离较小,这种特性保证了每一层以及整个覆盖树的节点多样性.另一方面,覆盖树可以根据用户的请求在覆盖树中的合适高度选取节点列表返回给用户,查询过程简单、运算量小,可以保证UCL推荐多样性优化算法的高效性.
但是,覆盖树在解决播存网络环境下UCL推荐多样性优化问题时仍然存在着2个较为明显的缺陷.1)覆盖树并不考虑节点的内容语义信息,无法有效利用UCL所包含的丰富语义信息;2)在UCL推荐多样性优化过程中,UCL的时效性对用户体验有着重要影响,覆盖树缺乏针对时效性的处理机制.
为此,本文对覆盖树进行相应扩展,设计了一种时间敏感的UCL语义覆盖树.
定义4. UCL语义覆盖树.语义覆盖树为覆盖树的一种特例,在覆盖树的基础上增加了时效性及语义信息等限制条件,UCL语义覆盖树需同时满足3个约束条件:
1) 基本条件.覆盖树所满足的3个约束条件:嵌套性、覆盖性和分离性.
2) 时效性.对于所有的UCLp∈Ci,令UCLs为p在l-1层的父节点,则有ts≤tp,其中ts,tp分别表示UCLs和p的时间.
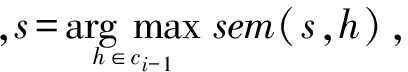
上述条件中,时效性保证了每个父节点均比其子节点更加新颖,从而使得从上往下遍历树寻找匹配用户兴趣时能够优先选择时效性更高的UCL.而语义聚集性则确保了在构建树的过程中,父节点与子节点之间的语义相似度更高,间接地促进了UCL列表的多样性效果.
2.2UDSCT算法描述
在介绍完相关基本概念后,本节将继续介绍如何完成UCL语义覆盖树的构造、如何基于该树完成UCL推荐多样性优化以及如何进一步快速响应用户的聚焦请求.
2.2.1 UCL语义覆盖树构造
UCL语义覆盖树采用自顶向下、逐个插入UCL的方式构造,首先选择最新的UCL作为树的根,然后遵循“新颖优先”的原则插入其他UCL.需要说明的是,在插入过程中,必须严格保证3个约束条件不被违背.构造的详细过程如算法1所示.
算法1. UCL语义覆盖树的构造.
输入: 待优化UCL列表I;
输出: 列表I对应的UCL语义覆盖树.
/*按照时间顺序对I中的UCL进行排序,依次调用函数Insert()*/
①I=reversedChronological(I);
② ForeachiinI
③ IfindexOf(i)==0
④Troot=i;
⑤ Else
⑥Insert(i,Q0,0);
⑦ EndIf
⑧ EndForeach
/*Insert(itemp,Ql,levell):将UCLp插入到T的第l层*/
⑨C={children of each node inQl};
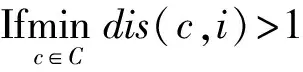
算法1中Insert()是基于文献[19]中的插入算法,但由于该算法仅可用于构建基本覆盖树,故需要对其进行适当改进,在构建过程中除了需要遵循定义3中的约束条件,还需兼顾定义4中的条件.具体而言,算法1首先根据时间顺序将已有UCL列表进行排序,然后依次调用插入函数Insert(itemp,Ql,levell)(行①~⑧),该操作保证了构造过程满足了时效性约束条件,最先插入的最新颖的节点作为树的根.插入函数以待插入的UCL、待插入的层数以及该层已含有的UCL作为输入参数,然后逐层递归地检查直到发现满足分离性约束条件的层数(行⑨~).在第一次找到该层之后,该函数将上一层中满足覆盖性条件的UCL节点识别出放入待插入节点的父节点候选节点集合(行).最终,该算法依次计算待插入UCL的特征向量与父节点候选节点集合中的节点的特征向量的语义关联程度,选出关联度最高的UCL节点作为待插入节点的最终父节点(行).
在构造UCL语义覆盖树的过程中,语义聚集条件使得UCL节点总是选择与其语义最为相关的UCL节点作为父节点,这进一步加强了同层节点之间的多样性,并为之后的UCL聚焦操作提供了重要基础.
2.2.2 多样化UCL结果集合查询
UCL语义覆盖树中的每个节点都对应了UCL推荐列表中的一个UCL,当用户确定想要获取的UCL数目后,只需逐层遍历树的节点,获得合适的UCL列表.具体而言,层数越低,该层的UCL之间距离越大,该层的多样性便越高.下降搜索过程如算法2所示.
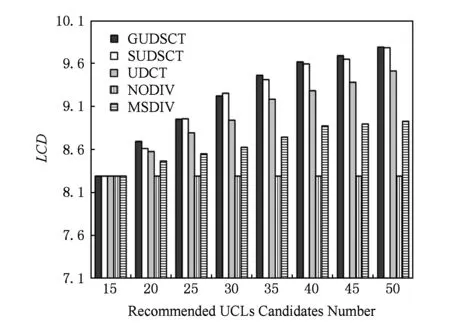
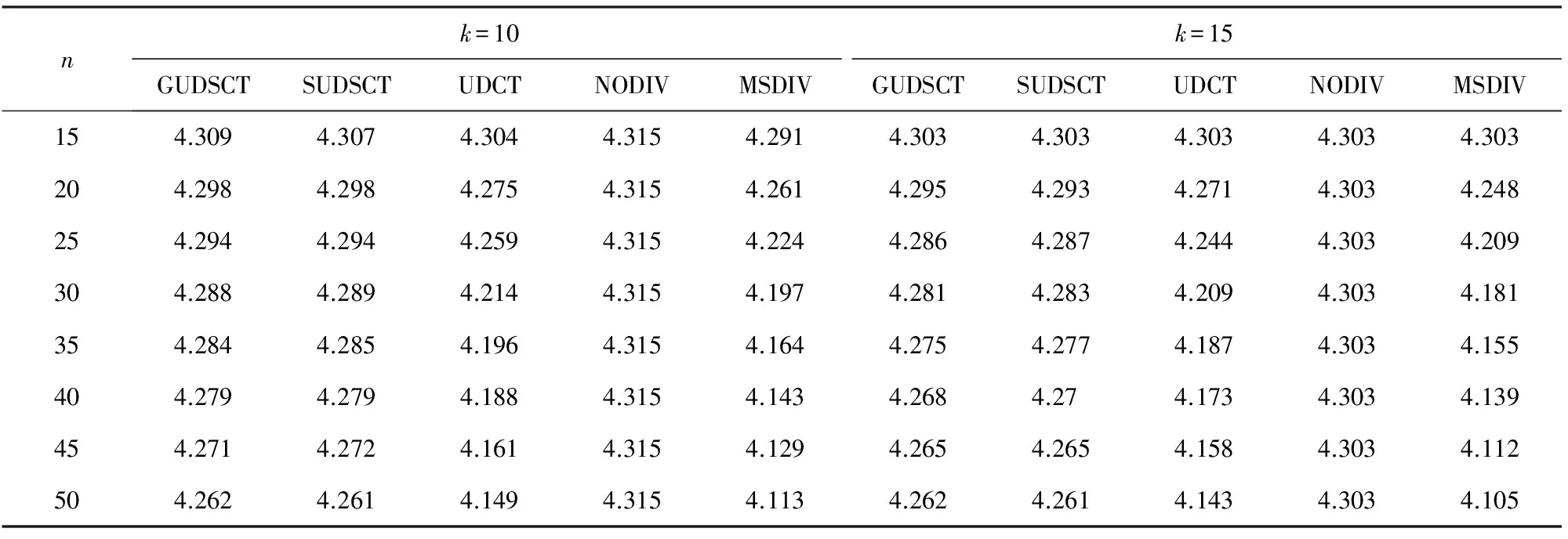
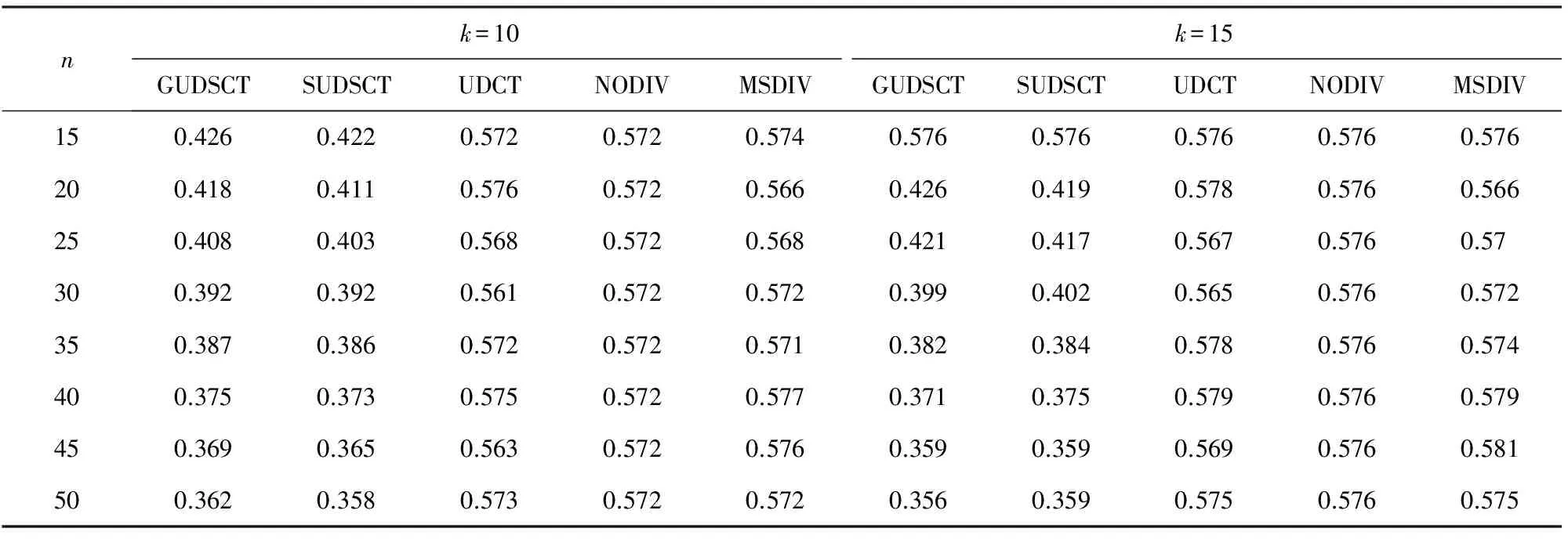
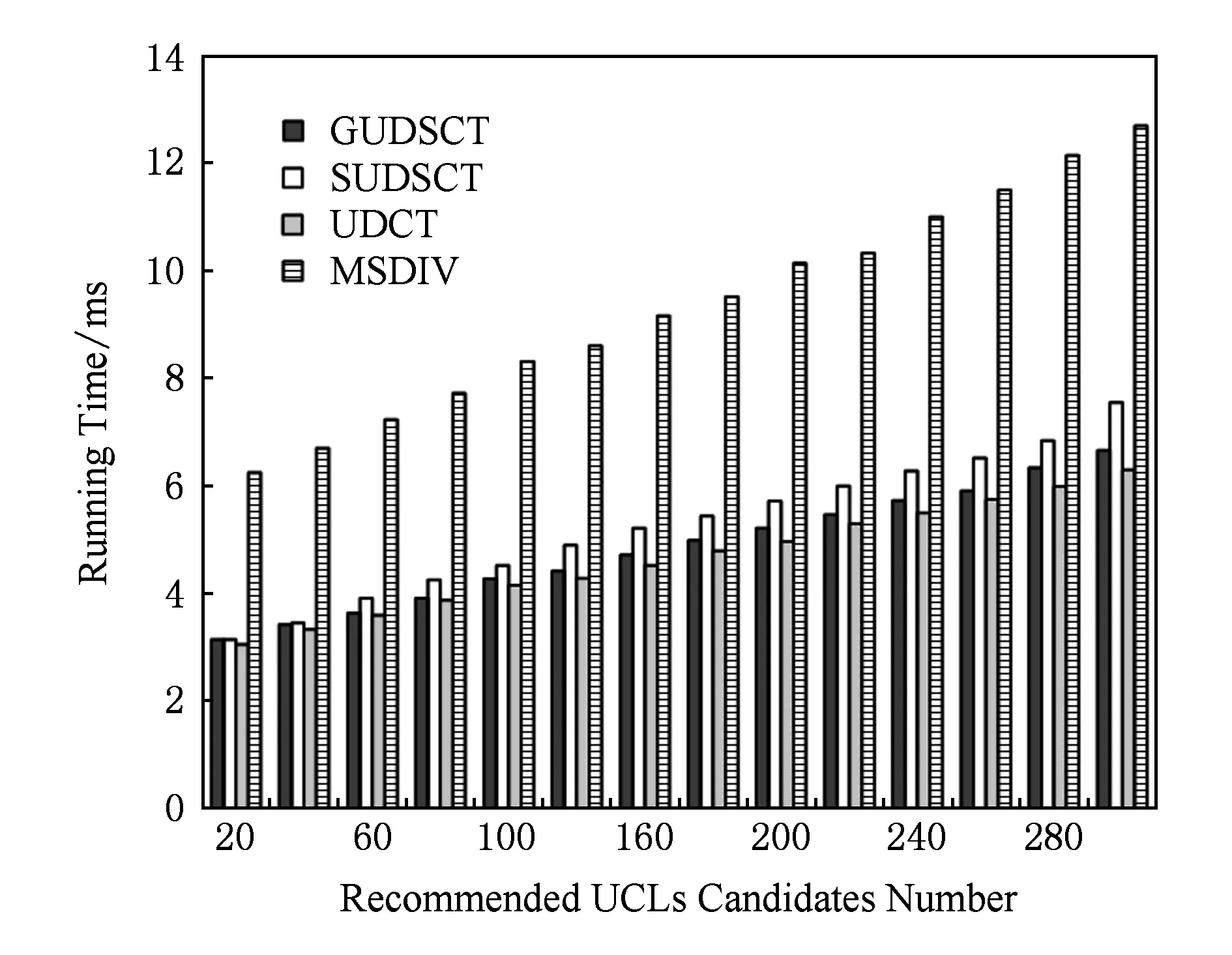
算法2. 多样化列表初步查询算法.
输入: UCL列表I对应的语义覆盖树T、结果子列表中UCL数目k;
输出: 包含k个UCL多样化的子列表S*.
①l=0;
② While (l ③ If |Ql|≥k ④ Break; ⑤ EndIf ⑥l=l+1; ⑦ EndWhile ⑧Sb=Ql-1; ⑨C=Ql-Ql-1; ⑩S*=supplement(Sb,C,k); 对于UCL列表I对应的UCL语义覆盖树以及用户指定的子列表大小,算法2首先定位相邻的两层l和l-1,使得|Ql-1| 算法3. 贪婪补充算法. 输入: 基础子列表Sb、候选集合C、结果子集合中UCL数目k; 输出: 包含k个UCL多样化的子集合S*. ①S*=Sb; ② While (|S*| ④S*=S*∪{p}; ⑤ EndWhile ⑥ returnS*. 算法4. 置换补充算法. 输入: 基础子列表Sb、候选集合C、结果子集合中UCL数目k; 输出: 包含k个UCL多样化的子集合S*. ①S*=Sb,R=Randomk-|S*|(C); ②S*=Sb∪R; ③θ=MAX; ④ While (θ>δ0) do ⑤ra=Random1(C-R),rb=Random1(S*); ⑥θ=div(S*∪{ra}-{rb})-div(S*); ⑦ Ifθ>δ0 ⑧S*=S*∪{ra}-{rb}; ⑨ Else ⑩ Continue; 而在置换补充算法中,首先从候选集合中随机选出k-|S*|个UCL节点并加入到初始子集合S*中,Randomm(S)函数负责随机从S中选择m个UCL.本质上而言,S*由2部分组成:1)来自初始子集合Sb的已确定部分;2)来自候选集的待优化部分.之后,分别随机从剩余的候选集合C-R及待优化部分R中取出2个UCL节点ra和rb,然后计算出是否ra比rb对已选出子集合的多样性提高更大.该多样性的提高被量化为变量θ,为了保证算法的效率,算法4设定了置换阈值δ0,当且仅当θ>δ0时,置换才会进行,否则将忽略该对节点,继续选出下一对进行比较.置换补充算法不断重复随机选节点、多样性比较等操作,直至子集合的多样性几乎保持不变,即θ<δ0. 2.2.3 UCL聚焦响应算法 在将初步多样性优化后的UCL列表呈现给用户后,用户会对其进行浏览并会根据自身兴趣及偏好查找自己感兴趣的UCL.假设该用户对某个UCL感兴趣,并想进一步了解与该UCL更加相关的一些UCL,此时,此时将调用UCL聚焦响应算法,算法的处理流程如算法5所示. 算法5. UCL聚焦响应算法. 输入: UCL列表I对应的语义覆盖树T、用户指定的UCLq、子列表中UCL数目k; 输出: 包含k个UCL的子列表S′. ①l=0; ② While (l ③ Ifq∈Qlength && (∃p∈q.children&&p≠q) ④ Break; ⑤ EndIf ⑥l=l+1; ⑦ EndWhile ⑧T′=new(T) &&q=T′.root; ⑨S′=Query(T′,k); ⑩ returnS′. 算法5首先根据用户请求,从已构造的UCL语义覆盖树中逐层查询用户感兴趣的UCLq(行①~⑦).需要注意的是,根据覆盖树的特性,相同的UCL可能会在树中出现多次,为了找到恰当的节点,算法需要找到第1个带有非自身子节点的q(行③).一旦找到该节点,算法并对该覆盖树进行剪枝处理,仅保留以q为根节点的子树(行⑧).最终,基于该子树,便可以调用子集合查询算法(算法2)获取与该UCL更加相关的UCL列表. 本节将分析UDSCT算法复杂度并总结、证明其具有的相关性质. 3.1算法复杂度 本文所提UDSCT算法主要由构造语义覆盖树及查询2部分组成,其中查询部分仅需定位层数及少量列表补充操作,所占时间、空间极少,因此本文将重点分析构造语义覆盖树所需的时空复杂度.语义覆盖树是普通覆盖树的特例,普通覆盖树构造的时间复杂度为O(nlogn),空间复杂度为O(n)[19].对于语义覆盖树,其构造的主要区别在于需要对UCL节点进行排序并在构建过程中进行语义关联度计算,前者(快速排序)的时间复杂度为O(nlogn),空间复杂度为O(logn),而后者时空复杂度均为O(1),因此,语义覆盖树构造的时间复杂度为:O(nlogn)+O(nlogn)+O(1)=O(nlogn),空间复杂度为O(n)+O(logn)+O(1)=O(n),由此可知,UDSCT算法复杂度较低. 3.2算法性质 基于语义覆盖树具有3条重要性质.首先,对于待插入树的UCLi而言,一旦其在树中的所属层数l确定,则在l-1层中必定有且仅有一个UCL可以当作UCLi的父节点. 证毕. 下面证明UCL语义覆盖树构造算法的正确性. 定理2. UCL语义覆盖树构造算法满足定义4中的所有约束条件. 证明. UCL语义覆盖树共包含5个限制性约束条件,其中,嵌套性、覆盖性和分离性为覆盖树的基本约束条件,由于UCL语义覆盖树为覆盖树的优化数据结构,本文不再赘述这3个约束条件的证明.在构造过程中,算法1首先将待插入UCL节点按照时间顺序排序,然后在插入UCL节点时检查父节点是否比其子节点时效性更高(t.i>t.p),因此,算法的时效性得以保证.而对于语义聚集性,算法在计算待插入UCL节点的父节点时总会从候选集合中选出与其语义相似度最高的节点作为其父节点,如定理1所述,因此,语义聚集性得证.综上所述,最终构造出来的UCL语义覆盖树可同时满足5个约束条件. 证毕. 最后,本文将继续证明,采用聚焦操作得到的UCL覆盖树同样满足UCL语义覆盖树的约束条件. 定理3. 基于UCL语义覆盖树进行聚焦操作,获得的子树同样满足5个限制性约束条件. 证明. 假设q为UCL语义覆盖树T中第m层的UCL节点,且聚焦操作返回的新语义覆盖树为T′,即,q为T′的根节点.对于T′中的任意UCL节点,令L为其在树T中的层数,那么,在树T′中,其所在层数为:L′=L-m.显然T′保留了嵌套性、时效性和语义聚集性.为了证明本定理,本文将论证T′同样满足分离性和覆盖性.对于树T中的任意层n,令m_dis为其中任意2个UCL节点的最小距离,则其必定满足: m_dis>1/2n=(1/2m)×(1/2n-m). 与此同时,在树T′中,其新的层数为L′=n-m,因此可得: m_dis>1/2n=(1/2m)×1/2L′. 也就是说剪枝后的子树保留了分离性条件,其距离下界为(1/2m)×1/2L′,易知,该下界取决于新的层数L′及其根节点在原始树T中的层数.同理可证,算法生成的新树L′同样满足覆盖性条件. 证毕. 4.1数据集及实验过程 为了展示基于UDSCT算法的性能优势并与其它算法进行公平对比,本文在公开数据集MovieLens*http://www.cs.umn.edu/Research/GroupLens/上进行实验,重点测试该算法所生成的最终推荐列表在给定指标上的性能.该数据集包含了943个用户对1 682部电影的评分,评分区间为1~5分,每个用户至少评价20部电影,每部电影还平均带有17个语义标签,可用以代表UCL所包含的语义信息.此外,本文采用随机打时间戳的方法标记每个电影的时间(播存网络中,当UCL数量较大时,其时间戳可视为随机方式生成),以确定构造UCL语义覆盖树时的插入顺序及进行时效性对比. 实验过程如下:实验随机选择100名用户进行测试,首先通过预测算法预测用户的初步推荐列表,然后采用不同的推荐列表多样性优化算法优化列表,最后统计测试不同算法所取得的相关性能指标并进行对比,针对对比结果给出相应分析.为保证实验结果的稳定性,上述过程均重复10组,本文所述结果为10组结果的平均值.另外,在实验过程中,本文采用PCC值度量基本距离,而对于语义距离,本文基于用户对电影的语义标签信息进行计算. 4.2评估标准 为全面测试UDSCT算法的性能,本文将围绕UCL列表平均精度、列表多样性(包括列表内部元素差异度及列表类别多样性)、列表时效性、算法运行时间等指标进行测试. UCL推荐列表平均精度(average list precision,ALP)计算公式为 (3) 其中,n表示列表中的UCL个数,rj表示第j个UCL的评分. 列表内部元素的差异度(list internal difference,LID)计算公式为 (4) 其中,ui表示第i个UCL,sim表示相似度函数,LID值越高,说明列表的多样性越好. UCL列表类别多样性(list category diversity,LCD)的计算公式为 (5) UCL列表时效性(list novelty,LN)的计算公式为 (6) 其中,ti为列表中第i个UCL的时间,tnewest为最新UCL的时间,toldest为最旧UCL的时间,LN值越小,UCL列表的时效性便越高. 4.3实验结果 本实验部分将根据第4.2节中所述评估标准,对比分析如下5个算法:基于贪婪策略的UDSCT算法(GUDSCT)、基于置换策略的UDSCT算法(SUDSCT)、基于普通覆盖树的UCL推荐多样性优化算法(UDCT)[18]、基于预测评分排序的无多样性优化初始排序算法(NODIV)、基于多置换策略的多样性优化算法(MSDIV)[14].其中,NODIV算法不包括任何多样性优化操作,用以作为其他方法的对比基准;UDCT算法用以验证本文算法是否可利用UCL语义及时效有效地提高相应的多样性及时效性指标;MSDIV算法用以验证本文算法是否可以快速取得多样性优化结果. 在实验过程中,本文首先对每个目标用户进行评分预测,并从高到低排序,取前n个(n取值为15~50)UCL作为初始列表,然后采用以上算法对列表进行多样性优化,取前k个(k≤n,本文取k=10或15)UCL作为最终推荐列表,并计算各项指标,在不同算法之间进行对比.另外,需要说明的是,本文将SUDSCT算法与MSDIV算法中的置换阈值δ0=0.01.该参数对算法的多样性及运行速度会有一定影响,本文通过实验发现,当δ0=0.01时,实验效果较好.而每次置换的元素个数会对MSDIV算法的运行时间有一定影响,为保证MSDIV算法能够取得较少的运行时间,本文将其设置为5. 4.3.1 UCL推荐多样性 本部分将根据UCL推荐列表内部元素差异度LID及列表类别多样性LCD两个指标测试不同算法的多样性优化效果. 图3和图4分别展示了k=10和k=15两种情况下不同算法之间LID值的对比结果.需要指出的是,LID值介于0,1之间. Fig. 3 LID comparison of different methods when k=10图3 k=10时不同方法LID对比 Fig. 4 LID comparison of different methods when k=15图4 k=15时不同方法LID对比 不难发现,在所有算法中NODIV算法的LID值最低,无论候选集合包含多少个UCL(从15~50),其LID值始终维持在0.3以下.从图中还可以发现GUDSCT与SUDSCT算法的LID值一直较为接近,均高于其他3种算法,也就是说基于UCL语义覆盖树的UDSCT算法具有更好的多样性优化效果.而UDCT算法的曲线介于UDSCT算法与MSDIV之间,这表明基于覆盖树的算法所具有的多样性优化效果比典型的启发式算法更好,但弱于基于UCL语义覆盖树的算法.本文认为,UDCT算法与UDSCT算法之间存在的这种差异正是由于UDCT算法缺乏对UCL语义信息的考虑.此外,随着候选集合的增大,所有多样性优化算法的LID值均逐渐升高,同时,GUDSCT与SUDSCT算法增幅较大. 图5和图6分别展示了最终推荐列表集合大小k=10和k=15两种情况下不同算法之间LCD值的对比结果. Fig. 5 LCD comparison of different methods when k=10图5 k=10时不同方法LCD对比 k=10时,LCD的取值区间为[1.998,10].当所有UCL属于同一个类别时,LCD取值最小,根据式(5)可知,LCD=1+12+…+129≈1.998;当所有UCL均属于不同类别时,LCD取值最大,LCD=10.k=15时,计算过程同上. 整体上而言,图5和图6中数据的变化趋势与图3和图4较为一致,与其他3种算法相比,基于UCL语义覆盖树的GUDSCT与SUDSCT算法仍然展示出明显的性能优势.在k=15,n=50时,与MSDIV方法相比,这2种方法的LCD值提高了将近10%.此外,需要说明的是,当候选集合与最终推荐结果集合含有相同的UCL数目时(即k=n),所有算法的多样性相同,因为此时无需进行多样性优化. Fig. 6 LCD comparison of different methods when k=15图6 k=15时不同方法LCD对比 4.3.2 UCL推荐精度 表1描述了不同算法对于UCL推荐精度ALP的影响.从表1可以观察到,NODIV算法的ALP值保持不变,其他算法的ALP值随着候选集合的变大而逐步降低.这是由于NODIV算法仅根据预测分数对UCL列表排序,而候选集合的增大并不会对前k个UCL的预测分数及排序产生影响,但在其他算法中,一些预测评分较低但会提高列表多样性的UCL可能出现在前k个位置,从而使得ALP值下降. Table 1 ALP Comparison of Different Methods表1 不同方法之间的ALP对比 从表1还可以发现,基于UCL语义覆盖树的2种算法在推荐精度方面均优于UDCT和MSDIV算法,且候选集合愈大,优势愈明显.此外总体上而言,所有优化算法在k=15时取得的ALP值均低于k=10时,这是因为推荐结果集合较大时,若高预测评分数量有限,一些低预测评分UCL将出现在推荐集合中,而当播存网络环境持续长时间运行后,高预测评分UCL数量会逐步增加,这种现象会得到有效缓解. 4.3.3 UCL推荐时效性 不同算法之间的UCL推荐时效性比较结果如表2所示.如4.2节所述,LN值越低,UCL推荐列表的时效性越强.从表2可以发现,GUDSCT与SUDSCT算法具有较强的时效性,在n=50,k=15时,二者的LN值分别达到了0.356和0.359.与之形成鲜明对比的是,UDCT,NODIV,MSDIV等算法的LN值始终在0.57左右浮动,无明显变化.这种现象表明,在这些算法中,UCL在时间上是随机分布的,显然,本文所提基于UCL语义覆盖树的算法可显著提高UCL推荐列表的时效性. Table 2 LN Comparison of Different Methods表2 不同方法之间的LN对比 4.3.4 算法运行时间 UDSCT算法基于语义覆盖树优化UCL推荐列表的多样性,在树构造完毕后,每次优化仅需一次语义覆盖树查询操作及少量的UCL列表调整操作,本实验部分将比较UDSCT算法与其他典型算法的运行时间情况,实验结果分别如图7、图8所示: Fig. 7 Running time comparison of different methods when k=10图7 k=10时不同算法之间的运行时间对比 Fig. 8 Running time comparison of different methods when k=15图8 k=15时不同算法之间的运行时间对比 需要指出的是,由于NODIV算法中无多样性优化操作,故不参加本部分实验. 从图7、图8中首先可以发现,MSDIV算法比基于覆盖树的3种算法(GUDSCT,SUDSCT,UDCT)耗时更久.此外随着候选集合的增大,MSDIV算法的耗时持续攀升,而基于覆盖树的算法则缓慢上升,后者在n=200时的耗时仍少于前者在n=20的耗时,这表明基于覆盖树的算法具有较好的可扩展性. 从图7、图8还可以发现,基于普通覆盖树的UDCT算法比本文所提的UDSCT算法(包括GUDSCT,SUDSCT)耗时更少,深入分析可知,这是因为UDCT算法在构建树的过程中无需排序操作及语义关联运算,节省了部分时间.同时SUDSCT算法耗时比GUDSCT稍久一点,这也不难理解,因为前者在查询后的少量调整过程中仍需要较多的迭代置换尝试. 4.3.5 UCL聚焦操作 在验证UCL聚焦操作性能时,由于该操作主要基于树的裁剪操作,其多样性、精度、时效性等指标取决于当前已构建的UCL语义覆盖树,相关性能已在上述4个实验部分测试,本部分实验主要关注UCL聚焦操作的响应时间,实验结果如图9所示: Fig. 9 Response time of UCL Focus图9 UCL聚焦响应时间 图9主要包括了6组实验结果,横坐标为响应时间,纵坐标为待聚焦的UCL所包含的相关UCL数目,每组实验重复5次,图9所展示的为5次的平均结果.观察图9可以发现,无论相关UCL数目多少,UCL聚焦操作的响应时间总能保持在2.3 ms以内,UCL数目对响应时间仅有轻微影响.分析可知,这是因为在不同的条件下,算法需要进行的定位、剪枝操作基本一致,耗时也差异不大.图9结果表明UDSCT中基于树查询的UCL聚焦操作可快速响应用户的操作请求. 本文针对播存网络环境的现实需求,基于语义覆盖树提出一种UCL推荐多样性优化算法UDSCT,可充分利用UCL语义信息及非语义用户评分信息,在保证UCL推荐精度的前提下,优化UCL推荐结果的多样性.首先,在多样性优化过程中,无需设定或训练任何加权参数,可基于UCL语义信息及非语义用户评分信息,取得稳定可靠的多样性优化效果;其次,在优化排序过程中,UCL越新,其处理优先权就越高,从而有效提高UCL推荐列表的时效性;最后,UDSCT算法收敛速度较快,一旦该UCL语义覆盖树构建完成,仅需要一次查询操作及少量推荐列表调整操作,便可得到多样化的UCL列表.实验结果证明,与基准算法相比,UDSCT算法能够获得更好的效果,可有效满足播存网络环境的需求. [1] Yang Peng, Li Youping. General architecture model of broadcast-storage network and its realization patterns[J]. Acta Electronica Sinica, 2015, 43(5): 974-979 (in Chinese)(杨鹏, 李幼平. 播存网络体系结构普适模型及实现模式[J]. 电子学报, 2015, 43(5): 974-979) [2] Li Youping, Yang Peng. New mechanism for sharing cultural big data[J]. Communications of the CCF, 2013, 5(5): 36-40 (in Chinese)(李幼平, 杨鹏. 共享文化大数据的新机制[J]. 中国计算机学会通讯, 2013, 5(5): 36-40) [3] Gu Liang, Yang Peng, Luo Junzhou. A collaborative filtering recommendation method for UCL in broadcast-storage network[J]. Journal of Computer Research and Development, 2015, 52(2): 475-486 (in Chinese)(顾梁, 杨鹏, 罗军舟. 一种播存网络环境下的UCL协同过滤推荐方法[J]. 计算机研究与发展, 2015, 52(2): 475-486) [4] Xing Ling, Ma Jianguo, Ma Weidong. Information Sharing Theory and Network Architecture[M]. Beijing: Science Press, 2011: 151-168 (in Chinese)(邢玲, 马建国, 马卫东. 信息共享理论与网络体系结构[M]. 北京: 科学出版社, 2011: 151-168) [5] Vieira M R, Razente H L, Barioni M C, et al. On query result diversification[C] //Proc of the 27th IEEE Int Conf on Data Engineering (ICDE 2011). Piscataway, NJ: IEEE, 2011: 1163-1174 [6] Ashkan A, Kveton B, Berkovsky S, et al. Optimal greedy diversity for recommendation[C] //Proc of the 24th Int Conf on Artificial Intelligence. Menlo Park: AAAI, 2015: 1742-1748 [7] Ma Weidong, Li Youping, Ma Jianguo, et al. Empirical study of region user behaviors for Web pages[J]. Chinese Journal of Computers, 2008, 31(6): 960-967 (in Chinese)(马卫东, 李幼平, 马建国, 等. 面向Web网页的区域用户行为实证研究[J]. 计算机学报, 2008, 31(6): 960-967) [8] Begtaševiü F, Van Mieghem P. Measurements of the hopcount in Internet[C] //Proc of the 2nd Int Conf on Passive and Active Measurement. Berlin: Springer, 2001: 23-24 [9] Adomavicius G, Kwon Y. Improving aggregate recommenda-tion diversity using ranking-based techniques[J]. IEEE Trans on Knowledge and Data Engineering, 2012, 24(5): 896-911 [10] Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C] //Proc of the 21st Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 1998: 335-336 [11] Gollapudi S, Sharma A. An axiomatic approach for result diversification[C] //Proc of the 18th Int Conf on World Wide Web. New York: ACM, 2009: 381-390 [12] Ziegler C N, McNee S M, Konstan J A, et al. Improving recommendation lists through topic diversification[C] //Proc of the 14th Int Conf on World Wide Web. New York: ACM, 2005: 22-32 [13] Erkut E, Ulküsal Y, Yeniçeriog'lu O. A comparison of p-dispersion heuristics[J]. Location Science, 1996, 21(10): 1103-1113 [14] Liu Ziyang, Sun Peng, Chen Yi. Structured search result differentiation[J]. Proceedings of the VLDB Endowment, 2009, 2(1): 313-324 [15] Radlinski F, Kleinberg R, Joachims T. Learning diverse rankings with multi-armed bandits[C] //Proc of the 25th Int Conf on Machine learning. New York: ACM, 2008: 784-791 [16] Javari A, Jalili M. A probabilistic model to resolve diversity-accuracy challenge of recommendation systems[J]. Knowledge and Information Systems, 2015, 44(3): 609-627 [17] Qin Lijing, Zhu Xiaoyang. Promoting diversity in recommendation by entropy regularizer[C] //Proc of the 23rd Int Joint Conf on Artificial Intelligence. Menlo Park: AAAI, 2013: 2698-2704 [18] Drosou M, Pitoura E. Dynamic diversification of continuous data[C] //Proc of the 15th Int Conf on Extending Database Technology. New York: ACM, 2012: 216-227 [19] Beygelzimer A, Kakade S, Langford J. Cover trees for nearest neighbor[C] //Proc of the 23rd Int Conf on Machine learning. New York: ACM, 2006: 97-104 ADiversifiedRecommendationMethodforUCLinBroadcast-StorageNetwork Gu Liang, Yang Peng, and Dong Yongqiang (SchoolofComputerScienceandEngineering,SoutheastUniversity,Nanjing211189) (KeyLaboratoryofComputerNetworkandInformationIntegration(SoutheastUniversity),MinistryofEducation,Nanjing211189) By introducing broadcast distribution into TCPIP, Broadcast-Storage network has clear advantages in reducing the redundant traffic in the Internet and remitting information overload problem. Uniform content label (UCL) is used to express the needs of users and help users obtain the information resources in Broadcast-Storage network. In the process of UCL recommendation, one key problem that needs to be solved is that how to improve the diversity of recommendation based on the features of Broadcast-Storage network, e.g., rich semantic information and high novelty. To solve this problem, this paper proposes a diversification method UDSCT for UCL recommendation based on semantic cover tree. UDSCT consists of two components. The first one is constructing the semantic cover tree for UCLs, which obeys some proposed invariants and considers the semantic information of UCL and the ratings from users. Besides that, new UCLs are given priority to improve the novelty of the whole UCL list. The second component is the query of diversified UCL list, which uses simple tree query and heuristic list supplement operation to obtain the diversified UCL list fast and returns specified UCL sets rapidly according to users’ need. Theoretical analysis and a series of experiments results show that, UDSCT outperforms some benchmark algorithms and is suitable for Broadcast-Storage network. Broadcast-Storage network; uniform content label; recommendation; diversity; novelty Gu Liang, born in 1989. PhD candidate. His main research interests include reco-mmendation systems, machine learning, and future network architecture. Yang Peng, born in 1975. Associate professor at the School of Computer Science and Engineering, Southeast University, China. His main research interests include future network architecture, information-centric networking, distributed computing, formal theories and techniques, etc. Dong Yongqiang, born in 1973. Associate professor at the School of Computer Science and Engineering, Southeast University, China. His main research interests include future network architecture, information-centric networking, wireless ad hoc networks, and delay-tolerant opportunistic networking (dongyq@seu.edu.cn). 2017-03-10; :2017-05-15 国家自然科学基金项目(61472080,61672155);中国工程院咨询研究项目(2015-XY-04);国家“八六三”高技术研究发展计划基金项目(2013AA013503);软件新技术与产业化协同创新中心项目 This work was supported by the National Natural Science Foundation of China (61472080, 61672155), the Consulting Project of Chinese Academy of Engineering (2015-XY-04), the National High Technology Research and Development Program (863 Program) of China (2013AA013503), and the Project Funded by the Collaborative Innovation Center of Novel Software Technology and Industrialization. 杨鹏(pengyang@seu.edu.cn) TP393;TP18
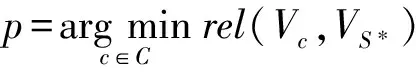
3 算法分析
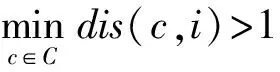
4 性能评估
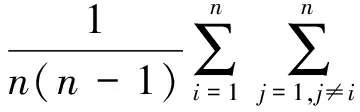

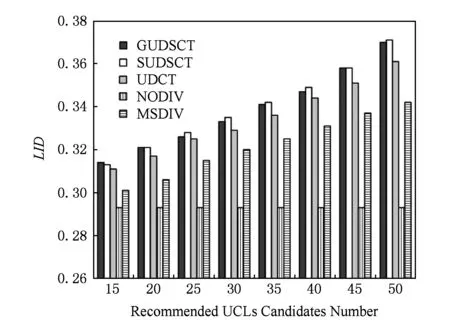
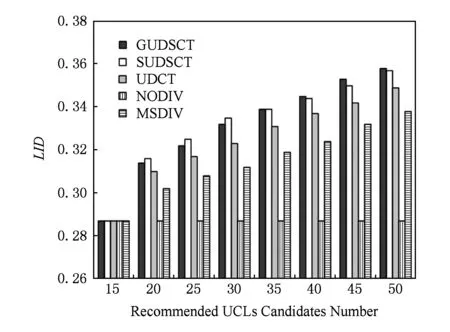

5 结 论


 猜你喜欢
小学生学习指导(中年级)(2021年4期)2021-04-27河北果树(2020年4期)2020-11-26课堂内外(初中版)(2020年5期)2020-06-19开放教育研究(2020年2期)2020-03-31都市生活(2019年5期)2019-08-01中国修辞(2017年0期)2017-01-31中国社会历史评论(2016年2期)2016-06-27长江学术(2016年4期)2016-03-11中学生数理化·中考版(2015年10期)2015-09-10中国铁道科学(2015年2期)2015-06-26
猜你喜欢
小学生学习指导(中年级)(2021年4期)2021-04-27河北果树(2020年4期)2020-11-26课堂内外(初中版)(2020年5期)2020-06-19开放教育研究(2020年2期)2020-03-31都市生活(2019年5期)2019-08-01中国修辞(2017年0期)2017-01-31中国社会历史评论(2016年2期)2016-06-27长江学术(2016年4期)2016-03-11中学生数理化·中考版(2015年10期)2015-09-10中国铁道科学(2015年2期)2015-06-26
