
FPGA外挂DDR的存储管理设计
2017-08-30 00:17:22海军航空工程学院青岛校区卞金来林成浴蔡慧敏
电子世界 2017年15期
海军航空工程学院青岛校区 卞金来 林成浴 蔡慧敏
FPGA外挂DDR的存储管理设计
海军航空工程学院青岛校区 卞金来 林成浴 蔡慧敏
FPGA芯片的硬件平台上要实现6000个用户的HSUPA上行用户平面L2协议高效实时处理,就需要处理大量的数据缓存,如果给每个用户分配固定的DDR空间,将导致DDR的需求激增。为了减少设计成本,对DDR的空间分配,采用动态分配方式,以提高缓冲数据区的存储效率。在FPGA中设计存储管理模块,负责DDR存储块的动态分配以及DDR存储块的回收。
FPGA;动态分配;存储管理
0 引言
Kintex-7系列支持高达32路12.5G收发器和DDR3-1866,与之前的40nm器件相比,降低一半功耗。并且其还具有可扩展的优化架构、全面的工具、IP以及开发板和套件。
Kintex-7系列片内Block RAM和分布式RAM都有限,如Kintex-7 325T分布式RAM只有4000Kb,块 RAM只有16020Kb。当需要进行缓存大量数据时,只能外挂存储器DDR或者QDR负责存储接收缓冲数据。
当在Kintex-7 325T FPGA芯片的硬件平台上要实现6000个用户的HSUPA上行用户平面L2协议高效实时处理,平均每个用户400kbps吞吐量,获得总共2.4Gbps的HUSPA上行数据平面协议处理吞吐量,利用FPGA对HSUPA的RNC用户面协议处理进行加速,需要在FPGA内需要完成RNC内的RLC层协议、MAC层协议和FP帧协议的加速处理。
当设计需要实现大量用户数据处理,这就需要大量的DDR进行缓存数据,如果给每个用户分配固定的DDR空间,将导致DDR的需求激增。为了减少设计成本,对DDR的空间分配,采用动态分配方式,以提高缓冲数据区的存储效率。在FPGA中设计存储管理模块,负责DDR存储块的动态分配以及DDR存储块的回收。
1 DDR存储管理难点与关键技术
K7-325T片内RAM数目有限,分布式RAM只有4000Kb,块RAM只有16020Kb,无法将6000个用户的上行缓冲数据,只能在DDR中进行缓冲存储,导致大量DDR读写操作。
设计需要支持6000个用户,如果为每个用户都规划固定的缓冲空间将增加所需DDR,增加设计成本,并且FPGA的IO口数量有限,不能支持过大的DDR,这就需要根据需要为用户动态分配DDR存储空间,以提高缓冲数据区的存储效率。
2 DDR存储规划
根据用户空间的大小采用1G容量的DDR。每个DDR的地址空间,一部分采用静态分配方式(256MB),一部分采用动态分配方式(768MB)。DDR存储的收发处理数据结构采用静态分配方式,这样虽然DDR存储器利用率不高,但是可以减少DDR读写次数。而MAC-es接收数据缓冲区和RLC AM接收数据缓冲区采用动态分配方式,以提高缓冲数据区的存储效率。
64位的DDR分配给MAC-es模块使用。其整序缓冲区静态分配,8(字节/元素)×128(元素)×4(逻辑信道)×6000=24,000KB。CFN子帧缓冲队列静态分配,1(字节/元素)×256(元素/队列)×4(逻辑信道)×6000=6,000KB。
32位的DDR分配给RLC模块使用。接收窗口缓冲区静态分配:8(字节/元素)×2048(元素)×6000=96,000KB;重组缓冲区:512×6000=3,000KB
相对于固定分配DDR区域的256MB,开销完全可以接受。
数据缓冲区采用动态分配方式。动态存储器大小为768MB,768MB内存空间按照2KB(64位的DDR)或者512B(32位DDR)大小进行分片编号(即地址)。如此,在64中DDR中,可将后面的768MB划分为384K个2MB的存储块;在32位的DDR中,可将后面的768MB划分为1536K个512B的存储块。
3 DDR存储管理模块设计思路
DDR存储管理模块的任务是对对2个DDR中768MB的空间实现动态管理。考虑构造出2个FREE FIFO,分别用于2个DDR的动态存储空间的存储管理,在FIFO中存储每个动态存储块的分片编号(即地址)。
当需要分配内存块时从头部输出内存块的分片编号;当需要回收内存块时,将使用完成的内存块的分片编号写回FREE FIFO的尾部实现动态存储区内存块的动态回收操作。如图1所示。
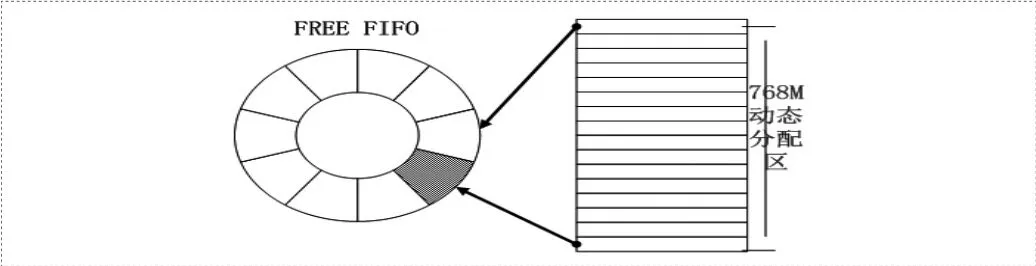
图1 DDR动态存储区与FREE FIFO映射关系图
对于64位的DDR,FIFO数据结构存储384K个块号,每个块号用4字节存储。共需4*384k=1.5M字节。对于32位的DDR,FIFO数据结构存储1536K个块号,每个块号用4字节存储。共需4*1536k = 6M字节。而分布式RAM只有4000Kb,块 RAM只有16020Kb;QDR只有8M。
前面将DDR划分为静态存储区域和动态分配区域。故将这两个FREE FIFO存储到各自的DDR静态存储区域。
这样每次分配和回收内存块时,就会触发对DDR的读或写。DDR的读写较慢,并且需要仲裁,导致分配和回收的效率不高。
为了提高动态分配的效率,考虑在RAM实现利用IP core例化FIFO对DDR中的FREE FIFO进行映射。分别通过IP CORE例化预分配FIFO和延迟回收FIFO实现DDR内存块的动态分配的高效性。FREE FIFO前面的1024个内存块地址提前取到预分配FIFO,用户模块申请时,快速的从预申请队列直接分片,当预分配FIFO中可分配块小于512时,一次性从DDR中读取512个内存块号以待分配。当用户模块释放内存块时,先放入到延迟回收FIFO,等待需要回收的内存块超过512个时,在集中性一次写回FREE FIFO。如图2所示。
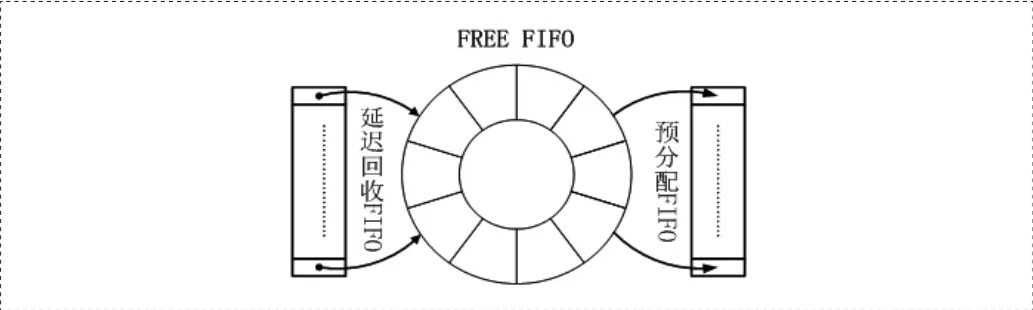
图2 预分配FIFO和延迟回收FIFO与FREE FIFO映射关系图
这样分配时直接读取预分配FIFO提高了分配的速度,并且不需要等待DDR的仲裁和读写。回收时,不是直接回收而是等到待回收的内存块超过512个才一次性回收,大大减少的DDR的写操作次数。
4 结束语
为了高效实使用DDR中缓冲存储区,对DDR的缓冲存储区进行动态存储管理。动态存储管理实现通过在DDR静态存储区域FREE中构建FREE FIFO存储动态存储块的地址信息来实现。
为了避免每次分配和回收存储块时都需要对DDR的读写。分别通过IP CORE例化预分配FIFO和延迟回收FIFO实现DDR内存块的动态分配的高效性。FREE FIFO前面的1024个内存块地址提前取到预分配FIFO,用户模块申请时,快速的从预申请队列直接分片,当预分配FIFO中可分配块小于512时,一次性从DDR中读取512个内存块号以待分配。当用户模块释放内存块时,先放入到延迟回收FIFO,等待需要回收的内存块超过512个时,在集中性一次写回FREE FIFO,大大减少DDR的读写次数,提高效率。
[1]张浩.高速上行分组接入技术在WCDMA RNC中的设计与实现[D].哈尔滨工程大学,2010.
[2]刘琦.WCDMA HSUPA中关键技术的研究和实现[D].西安电子科技大学,2008.
[3]耿琦,韦再雪,杨大成.HSUPA技术及其系统级仿真[J].信息通信技术,2008.
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
火控雷达技术(2018年4期)2019-01-15 05:07:22
电子制作(2017年13期)2017-12-15 09:00:32
科学与财富(2016年29期)2016-12-27 00:31:46
江西通信科技(2015年3期)2015-12-05 05:52:09
项目管理技术(2015年3期)2015-04-23 08:44:29
计算机工程与设计(2012年3期)2012-07-25 11:05:00
