
一种减少长尾延迟的分布式实时约束传播方法
2017-08-12 15:31马久跃隋秀峰包云岗
计算机研究与发展 2017年7期
任 睿 马久跃 隋秀峰 包云岗
1(中国科学院计算技术研究所 北京 100190)2 (中国科学院大学 北京 100049)
一种减少长尾延迟的分布式实时约束传播方法
任 睿1,2马久跃1,2隋秀峰1包云岗1
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)
(renrui@ict.ac.cn)
提出了一种在数据中心环境下用于减少长尾延迟的分布式实时约束传播方法,该方法能够使当前节点感知请求的全局响应时间约束信息,并能够将请求的实时约束信息传播到整个处理路径;节点可以利用请求的实时约束信息进行请求调度或加速请求执行时间,以此来减少长尾延迟现象.同时,针对划分聚合模式和串行依赖模式2种数据中心应用,提出了阶段服务模型和并行单元模型,并基于这2种模型实现了分布式实时约束传播框架.最后,在分布式实时约束传播框架上实现了实时约束感知调度算法,通过实验进行了简单的验证,初步的实验结果显示了分布式实时约束传播方法能够在一定程度上减少长尾延迟.
实时约束传播;长尾延迟;数据中心;划分聚合模式;串行依赖模式
随着互联网应用的普及,电子邮件、搜索、电子商务、社交网络、在线视频等互联网服务已经成为人们生活的一部分.对互联网应用来说,服务质量是互联网应用的关键指标,快速的响应时间不仅预示了好的用户体验,成为互联网企业让用户满意、留住用户的关键之一,同时也是互联网企业收入的关键因素[1].有研究表明,如果服务响应时间增加,公司收入就会减少.例如亚马逊发现Amazon.com的加载时间每增加100 ms就会导致销售额降低1%[2];当服务的响应时间从0.4 s增加到0.9 s,谷歌的广告收入会降低20%[3];微软搜索引擎Bing的服务响应时间从50 ms增加到2 000 ms时,用户满意度下降了3.8%,而每个用户带给企业的收益下降了4.3%[4].
为了保障互联网应用的服务质量,数据中心运营商通常会通过预留资源的方式来解决,但这样做会降低数据中心的资源利用率.例如谷歌报告了某在线应用数据中心5 000台服务器在6个月期间的CPU利用率统计,该报告显示,整个数据中心的平均CPU利用率仅为30%左右,资源利用率并不高;而同一时期,批处理负载的数据中心资源利用率为75%[5].
当然,一些企业为了提高资源利用率,会将多个应用部署到同一个节点上共享资源,但是资源共享又会带来干扰,干扰则会进一步影响在线应用或延迟敏感应用的服务质量,导致不可避免的性能波动,产生长尾延迟现象[6];而且长尾延迟现象在数据中心环境下会被进一步放大[6-7].因此,对很多互联网企业来说,他们不得不在资源利用率与服务质量之间二选一.
面对数据中心资源利用率和应用服务质量的矛盾,本文针对如何降低性能波动和减少长尾延迟的问题,提出了在数据中心环境下的一种分布式实时约束传播方法,该方法能够将请求的全局响应时间约束信息传播到整个处理路径[8].该设计方法受启发于纽约曼哈顿的交通信号灯,纽约市交管中心会及时跟踪曼哈顿岛上所有交通信号灯的动态变化,各个路口的信号灯被分割成多个有机的整体,即十几个路口的信号灯会同时或依次变灯,例如一个红灯之后的多个路口都变成绿灯,从而大大提高了车辆的通行速度.此外,我们分别针对串行依赖模式和划分聚合模式的数据中心应用,提出了阶段服务模型和并行单元模型,将分布式实时约束传播方法应用到这2种模型上,实现了一个分布式实时约束传播框架.最后,在分布式实时约束传播框架上,我们利用在请求全生命周期过程中所传播的实时约束信息来对请求进行优先级调度,用以减少长尾延迟现象,并通过实验进行了验证.
1 国内外相关工作
近年来,为了保障数据中心应用的服务质量,学术界、工业界在各个层次上进行了探索.
谷歌的Dean与Barroso[6]阐述了数据中心的长尾延迟问题.他们分析了导致长尾延迟的首要原因是资源共享,包括体系结构层次的CPU核、Cache、访存带宽、网络带宽等,而干扰不仅来自应用,还来自于系统软件层次的后台守护作业以及监控作业等[1].此外,还有部分学者研究了不同资源对长尾延迟和性能的影响各不相同,例如Ousterhout等人[9]分析了大规模数据分析框架的性能瓶颈,发现一些特定负载的性能主要受限于CPU,而网络IO对性能的影响较小.
为了缓解干扰所引起的长尾延迟现象,Dean等人[6]还介绍了谷歌所采用相关技术,例如操作系统容器隔离技术、应用优先级管理、请求备份、同步后台管理进程等[7].但是,谷歌采用的超时发送备份请求和同步后台管理进程等技术虽然对改善划分聚合模式应用的长尾延迟有帮助,却并不能显著改善串行依赖模式应用的响应时间.此外,微软对Bing搜索引擎则采用并行查询的方式来减少响应时间延迟,例如自适应并行查询方法[10]、可预测的并行查询方法[11]、Few-to-Many增量并行方法[12]等,主要思路是通过增加搜索索引服务请求的执行并行度,加快请求的响应时间,而这种方法主要适用于改善划分聚合模式应用的长尾延迟.
另一部分工作则是通过减少网络延迟来减少长尾延迟现象[13-16].例如Kapoor等人[13]提出了Chronos架构,以降低数据中心应用的长尾延迟,该架构基于NIC上应用层数据包头字段的请求划分、应用实例负载均衡和NIC负载均衡模块的加载来消除关键通信路径上的共享资源,如内核和网络协议栈,以减少应用延迟以及相关干扰[1];此外,DeTail[14]用于减少数据中心网络中的网络流完成时间延迟;DCTCP[15]是一个类似于TCP的网络协议,可以容忍流高峰和减少短小流的延迟.D2TCP[16]是一种新的传输协议,可用于进行带宽分配和避免拥塞.
一部分学者则通过资源隔离或软硬件调度技术来减少资源共享带来的干扰,从而达到减少长尾延迟的目的.目前,操作系统虚拟化技术[17-18]、共享缓存划分技术[19-20]、共享DRAM颗粒划分技术[21-22]等可以实现特定资源的隔离,从而保障多个应用之间的性能隔离,减少性能干扰.软硬件调度技术则可以尽量为高优先级应用分配更多的资源,例如Tang等人[23]提出了一种动静结合的编译方法ReQoS,在确保高优先级应用的服务质量的同时,让低优先级应用也可以自适应地执行,可以减少高优先级应用的长尾延迟.Bobtail[24]则是通过联合调度的方法来减少数据中心应用的长尾延迟.
此外,还可以通过对请求响应时间进行建模和属性分析来理解请求响应延迟的波动情况,例如Cipar等人[25]提出了一种同步SSP模型,该模型对BSP模型进行了改进,可用于避免落后者问题.
除了数据中心应用,由于移动应用越来越普及,而且移动应用的服务端一般会部署在数据中心,所以如何减少移动应用的端对端延迟也显得越来越重要.例如微软提出了AppInsight[26]和Timecard[27],用于监控移动应用请求在各个执行阶段的性能情况和控制移动应用的端对端延迟.

Fig. 1 The examples of request response variability range图1 请求响应时间波动范围举例
2 数据中心应用和长尾延迟
2.1 数据中心应用
在数据中心中,互联网应用大多会被分解为许多服务,然后将这些服务部署到数据中心的服务器上[1].一般而言,服务之间的耦合方式有2种[13],而且这2种模式都会放大长尾延迟现象.
2.2 长尾延迟现象
无论是在单台机器还是数据中心,由于资源共享、后台守护作业、共享文件系统等因素,性能波动和响应延迟波动是不可避免的[2,28].
在数据中心环境下,由于应用的可扩展性和分布式属性,一般情况下,请求响应的延迟波动会被放大[6-7].例如图1(a)显示了在一台机器上执行Equake程序的执行时间分布图[29],图1(b)则显示了谷歌某后端服务在某数据中心的响应时间波动情况[2].我们定义请求的响应延迟波动范围为variabilityrange,请求的响应延迟波动范围可通过式(1)计算得到,其中,Tmax为最大的请求响应时间,Tmin为最小的请求响应时间,Tavg为请求平均响应时间.
variabilityrange=(Tmax-Tmin)Tavg×100%.
(1)
基于图1中的数据,并根据上述定义分别计算单台机器上Equake程序和数据中心某后端服务的响应时间波动范围,发现单台机器上Equake程序的响应延迟波动为5.42%,但是数据中心环境下后端服务的响应延迟波动为5980%,显而易见,数据中心环境下的响应延迟波动远远大于单台机器上的响应延迟波动.
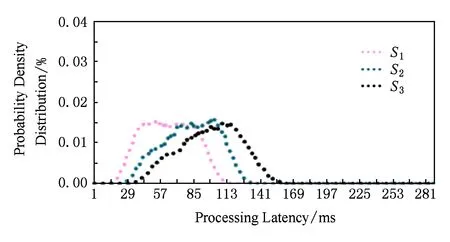
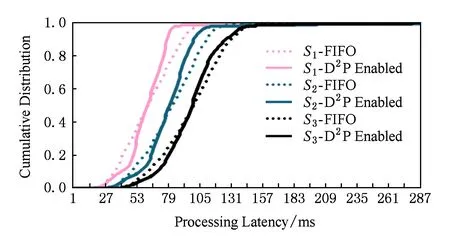
而数据中心环境下响应延迟波动范围变大的原因在于:用户请求可能会被划分为多个子请求并扇出到成百上千台机器上.假设一台机器处理请求的平均响应时间为1 ms,有1%的请求响应时间会大于1 s;如果一个请求需要由100个这样的节点一起处理,那么就会出现63%的请求响应时间大于1 s;或者,请求的服务处于关键路径上,每个服务的处理延迟会随着请求在关键路径上的传递而累加.如图2所示,我们模拟了一个具有5个服务阶段的串行依赖应用,从服务阶段S1到服务阶段S5,90%的响应延迟增大了2.6倍,95%的响应延迟增大了2.4倍.

Fig. 2 Latency variability is amplified when service stage increases图2 响应时间延迟波动随服务阶段的增加而放大
综上所述,数据中心的2种应用模式都会导致处理一个请求需要访问多台服务器,因而只要有一台服务器的处理速度受到干扰,就会导致整个请求的处理时间增加.由此,便产生了长尾延迟现象.
3 分布式实时约束传播方法
为了解决数据中心应用的长尾延迟问题,我们提出了一个分布式实时约束传播方法(distributed deadline propagation, D2P),该方法综合考虑期望响应时间、请求执行时间及网络传输延迟来定义实时约束信息,能够在请求的全生命周期上动态更新并传播请求的全局实时约束信息.本节将介绍分布式实时约束传播方法如何运用在串行依赖模式应用和划分聚合模式应用上.
3.1.1 阶段服务模型
我们定义了阶段服务模型(stage-service model, SSM)来描述串行依赖模式应用.在阶段服务模型中,应用由多个服务组成,各个服务之间的请求串行执行,并且相邻的2级服务请求具有一定的依赖关系.
阶段服务模型如图3所示,其中,阶段服务模型中的相关参数为
N: 应用所包含的服务阶段的个数;
Si: 应用的第i个服务阶段,1≤i≤N;
LSi: 应用请求在第i个服务阶段的执行时间;
CSi: 应用请求在第i个服务阶段处理完毕后,将请求发送到下一个服务阶段所花费的网络延迟;
elapsed_timeSi: 服务阶段Si的处理延迟,表示从生成请求开始,到第i个服务阶段处理完毕所经历的总延迟;其中,综合考虑了请求在传输过程中的网络延迟和在服务阶段上的请求处理延迟:
elapsed_timeSi=elapsed_timeSi-1+CSi-1+LSi.
(2)
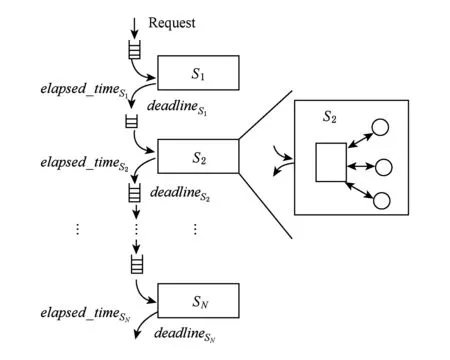
Fig. 3 Stage-service model图3 阶段服务模型
3.1.2 基于SSM的分布式实时约束传播方法
在阶段服务模型下,由于服务都在关键路径上,因此每个阶段的服务请求处理延迟会累加.例如,在图3中,如果一个请求在服务阶段S2和服务阶段S3中的处理延迟位于“长尾”区域,那么,该请求的响应时间将会被放大.本文介绍的分布式实时约束传播方法会在请求的全生命周期中,实时记录请求在每一个服务阶段的处理延迟,并根据用户期望的响应时间实时调整下一个服务阶段的请求处理时间,以达到减少长尾延迟的目的.

Fig. 4 Parallel-unit model图4 并行单元模型
在分布式实时约束传播方法中,实时约束信息定义如下:
expected_deadline: 实时约束信息的初始值,表示用户期望的请求响应时间阈值.
deadlineSi:服务阶段Si的实时约束信息,用elapsed_timeSi和expected_deadline之间的差值表示.当请求传递时,请求在服务阶段的实时约束信息可计算并更新为
deadlineSi=expected_deadline-elapsed_timeSi.
(3)
根据式(3),在请求的传递过程中,通过使用分布式实时约束传播方法,可以在每一个服务阶段更新实时约束信息deadlineSi,并将更新后的实时约束信息传播给下一个服务阶段.如果某个请求的deadlineSi值为0或负数,表明该请求已经超时,即该请求已经不满足用户期望的响应时间阈值.这时,用户可以对超时请求采取一些特殊的措施进行处理.
当请求在不同的服务阶段进行传递时,可以将请求的实时约束信息同时进行传播,那么,对每一个服务阶段而言,系统可以利用实时约束信息进行优先级调度、资源分配或增加并行度,以此来加速紧急请求的处理速度.
3.2.1 并行单元模型
并行单元(parallel-unit,PU)包含一个聚合节点(aggregator)和多个工作节点(worker),其中,聚合节点用于划分请求和聚合工作节点的执行结果,工作节点用于并行执行请求.
此外,在1个并行单元中,还包含3个阶段:划分阶段PP(partition-phase)、聚合阶段AP(aggregate-phase)、计算阶段CP(computation-phase);其中,划分阶段和聚合阶段在聚合节点上执行,计算阶段在工作节点上执行.
并行单元模型如图4所示,并行单元模型中的相关参数为
m: 并行单元中的工作节点个数;
Ai: 第i个聚合节点;
Wj: 第j个工作节点,1≤j≤m;
PP: 聚合节点上的划分阶段;
AP: 聚合节点上的聚合阶段;
CP: 工作节点上的计算阶段;
p: 请求在并行单元中所处于的阶段,p∈{PP,AP,CP};
l: 请求在并行单元中所处的节点,l∈{Ai,Wj};
Ll_p:请求在节点l、阶段p时的处理时间;
elapsed_timel_p: 请求经过节点l、阶段p后所花费的总处理时间;
CWj: 请求从工作节点Wj返回结果到聚合节点时所花费的网络延迟.
3.2.2 基于PUM的分布式实时约束传播方法
基于并行单元模型,我们也可以将分布式实时约束传播方法运用在划分聚合模式的应用上.
基于并行单元模型的分布式实时约束传播方法如图4所示,当请求到达并行单元并且处于聚合节点的划分阶段,或者请求刚到达工作节点的计算阶段,聚合节点和工作节点按照阶段服务模型的实时约束信息计算方法(式(3))来更新划分阶段和计算阶段的实时约束信息.当工作节点返回请求计算结果并且在聚合节点进行请求结果的聚合处理时,即聚合节点处于聚合阶段,由于elapsed_timeAi_AP将受限于最慢的工作节点,并且还受到请求传输过程中网络延迟的影响,所以其计算为
elapsed_timeAi_AP=
max(elapsed_timeWj_CP+CWj+LAi_AP).
(4)
那么,在并行单元的每一个阶段上,实时约束信息计算并动态更新为
deadlinel_p=expected_deadline-elapsed_timel_p,
l_p∈(Ai_PP,Wj_CP,Ai_AP).
(5)
4 分布式实时约束传播框架
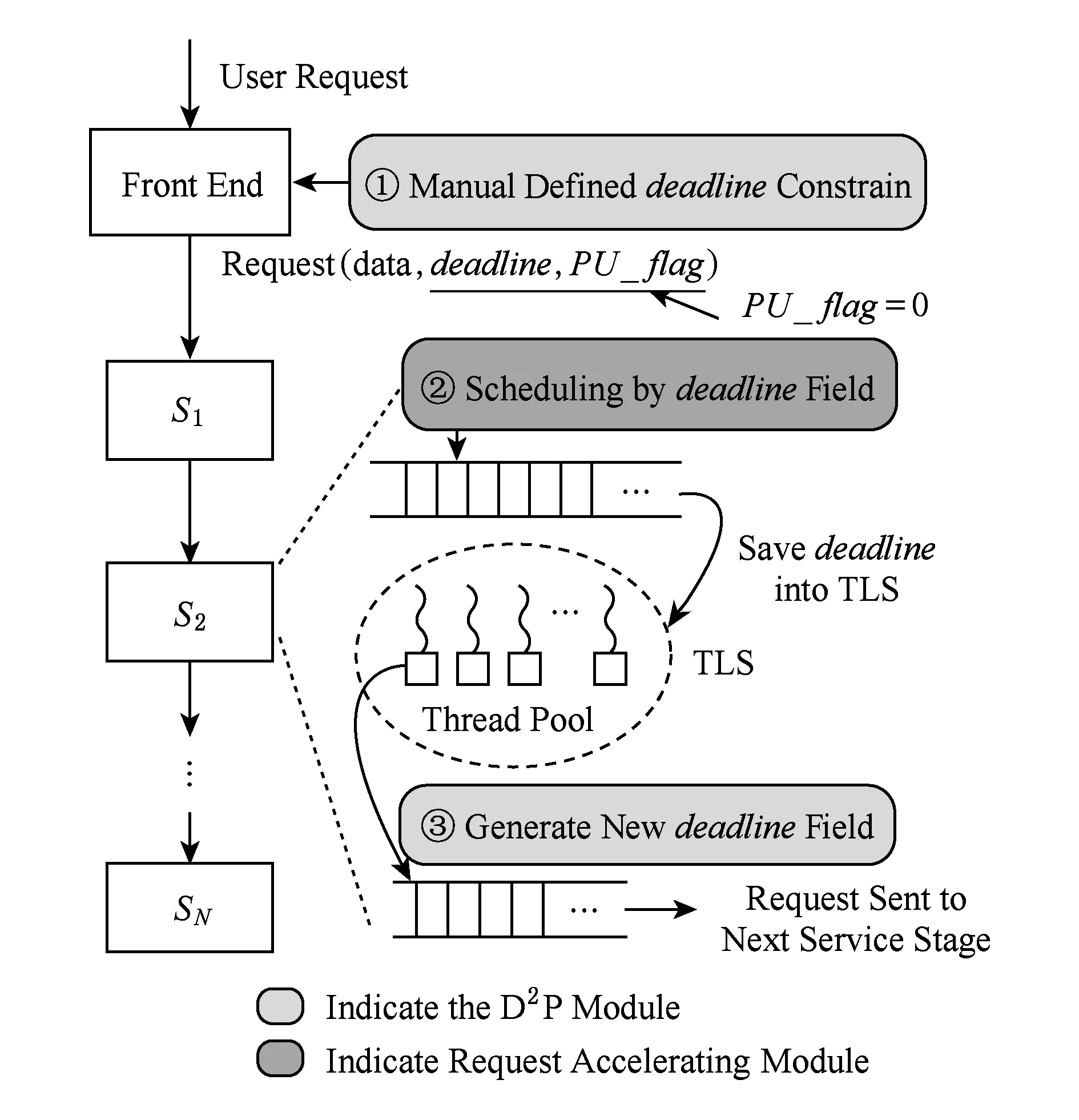
4.1 分布式实时约束传播框架的工作流程
分布式实时约束传播方法作为一种设计方法,可以实现在不同的分布式系统中.本文设计的分布式实时约束传播框架包含2个模块:1)实时约束传播模块(D2P module),用于收集请求在各个阶段节点上的处理延迟,为每个请求附加一个用于保存实时约束信息的实时约束信息域(deadline field)并初始化,在请求传递过程中计算并更新实时约束信息域,并在请求的整个生命周期上进行传播,并提供给请求加速模块使用;2)请求加速模块(request accelerating module),利用实时约束传播模块提供的实时约束信息,进行请求优先级调度,用于加速紧急请求的执行;或者增加请求的并发度,加快请求的执行速度.
分布式实时约束传播框架的工作流程主要包括3个步骤,如图5所示:
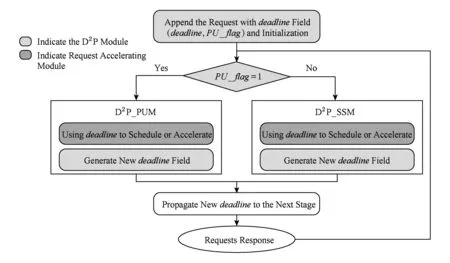
Fig. 5 The workflow of D2P-enabled framework图5 分布式实时约束传播框架的工作流程
步骤1. 当客户端发出一个新请求,实时约束传播模块会为该请求附加一个实时约束信息域(deadline,PU_flag).然后,实时约束传播模块会用预先定义的请求期望响应时间阈值expected_deadline来初始化deadline.如果该请求被划分为多个子请求,那么就认为该请求位于并行单元上,并设置PU_flag=1.当PU_flag=1时,实时约束传播模块会使用基于并行单元模型的分布式实时约束传播方法来计算和更新deadline;否则,实时约束传播模块使用基于阶段服务模型的分布式实时约束传播方法来计算和更新deadline.
步骤3. 当请求在某一个服务阶段或者并行单元上执行完毕,实时约束传播模块会记录这时候请求的elapsed_time,并使用式(3)(5)计算一个更新的deadline,并将更新后的deadline填入到请求的实时约束信息域.此后,更新的实时约束信息域会随着请求传播到下一个服务阶段或并行单元,直到请求返回最终的结果.
4.2 利用分布式实时约束传播框架减少长尾延迟
一般来说,目前主要有4种方法可用于保障服务质量要求和减少长尾延迟:
1) 调度方法.应用级调度算法[28,30]、分布式实时调度算法[31]都可以用于提高紧急请求的优先级,帮助紧急请求尽快完成.
2) 资源调整.通过增加紧急请求所需的某些资源,例如为紧急请求增加IO带宽、共享缓存等[19,32],以帮助紧急请求尽快完成,提升请求的执行效率;或通过增加网络带宽、减少网络拥塞等,以减少网络传输上的长尾延迟.
3) 增加并行度.随着多核服务器的发展,单个请求可以利用多核资源并行执行,这也是一种减少请求执行时间的可行方法,尤其会对长请求有效[10-12].
4) 调整精度[27].对一些互联网在线应用来说,适当地降低精度对用户的体验影响不大,那么就可以通过适当地降低精度来降低请求的响应时间,以此减少长尾延迟.
本节针对阶段服务模型和并行单元模型,基于分布式实时约束传播框架,介绍一种分布式实时约束感知的请求调度算法,用于减少请求处理延迟,以达到减少长尾延迟的目的.在分布式实时约束感知的请求调度算法中,为了方便理解,我们直接使用deadline作为调度优先级,当某个请求的deadline的值越小,表明该请求越紧急,那么该请求的优先级越高.此外,编程人员也可以根据自己的需求,将deadline和其他一些参数进行综合,再作为调度的优先级.
4.2.1 基于SSM的分布式实时约束感知调度算法
针对阶段服务模型,在请求的每一个服务阶段上,会根据实时约束信息实时调整下一个服务阶段的请求优先级,具体地,基于阶段服务模型的分布式实时约束感知调度算法的工作流程如下:
步骤1. 请求在服务阶段Si-1执行完成后,实时约束传播模块会根据请求的elapsed_timeSi-1和expected_deadline计算出该请求在服务阶段Si-1的deadlineSi-1的值,并将该deadlineSi-1附加到实时约束信息域(deadline,PU_flag)中,再由实时约束传播模块将deadlineSi-1值传递给服务阶段Si上的请求加速模块.
步骤2. 在服务阶段Si上,请求加速模块会根据当前所有请求的deadlineSi-1判断请求的优先级:如果请求的deadlineSi-1的值越小,表明该请求的优先级越高,该请求属于紧急请求,需要在服务阶段Si上优先执行.那么,请求加速模块会优先调度紧急请求.当请求在服务阶段Si执行完毕,实时约束传播模块会再次根据elapsed_timeSi和expected_deadline更新deadlineSi,并且传递到下一个服务阶段上的请求加速模块.
该算法的算法描述如算法1所示.
算法1. 基于阶段服务模型的分布式实时约束感知调度算法.
输入:elapsed_timeSi,expected_deadline;
输出:deadlineSi.
begin
初始化(deadlineS0,PU_flag):
deadlineS0=0,PU_flag=0;
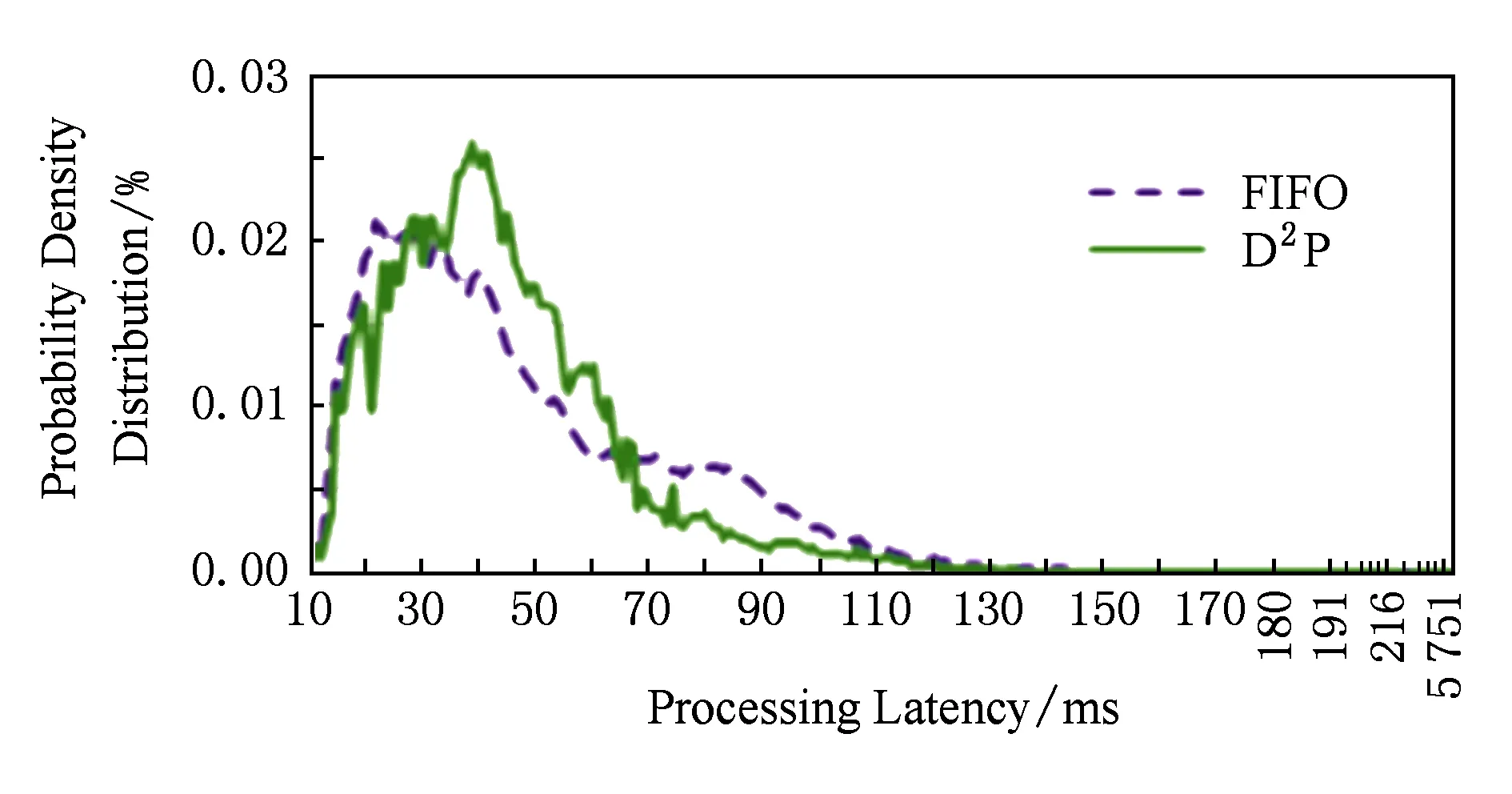
for (i=1;i 记录请求处理时间elapsed_timeSi; 计算deadlineSi: deadlineSi=expected_deadline-elapsed_timeSi; 发送deadlineSi到Si的请求加速模块; end for end 4.2.2 基于PUM的分布式实时约束感知调度算法 针对并行单元模型,由于请求在并行单元上所花费的时间主要在工作节点的计算阶段,所以请求加速模块主要对工作节点上的请求进行加速处理.那么,基于并行单元模型的分布式实时约束感知调度算法的工作流程如下: 步骤1. 进入并行单元的请求,当经过聚合节点划分的各个子请求进入到工作节点时,由实时约束传播模块计算各个请求刚到达工作节点的deadlineWj_CP_in. 步骤2. 实时约束传播模块将deadlineWj_CP_in值传递给该工作节点上的请求加速模块,由请求加速模块根据deadlineWj_CP_in决定请求的调度优先级,然后根据优先级进行调度,优先调度紧急请求. 该算法的算法描述如算法2所示. 算法2. 基于并行单元模型的分布式实时约束感知调度算法. 输入:elapsed_timeWj_CP_in,expected_deadline; 输出:deadlineWj_CP_in. begin 设置PU_flag=1; for (j=1;j 当请求到达worker时由D2P模块记录elapsed_timeWj_CP_in 计算deadlineWj_CP_in: deadlineWj_CP_in=expected_deadline-elapsed_timeWj_CP_in; 发送deadlineWj_CP_in到Wj的请求加速模块; end for end 5.1 实验设置 Fig. 6 The D2P-enabled framework based on SSM图6 基于SSM的分布式实时约束传播框架 在具体的部署方案中,我们总共部署了21台虚拟机,其中,1台虚拟机是数据源spout节点,用于发射查询请求,请求生成速率为100请求数s;1台虚拟机是写数据库Redis的节点;1台虚拟机是合并计算结果的节点,即聚合节点;其他18台虚拟机是中间计算的bolt节点,即工作节点,在每个工作节点上都有一个执行索引查询的任务,用于执行索引查询请求.我们在JStorm拓扑的bolt组件中,对查询请求附加了实时约束信息域,并修改了执行查询任务的bolt组件,使其可以根据请求的实时约束信息对请求进行调度. 5.2 实验结果 为了评估实验,我们采用的评价指标有请求平均处理延迟(mean processing latency)和95%请求处理延迟(95th-percentile processing latency).一般来说,可以使用95%请求处理延迟来表示请求的长尾延迟现象. Table 1 The Compare of FIFO and D2P -enabled Deadline - aware Scheduling in SSM表1 SSM中FIFO调度和实时约束感知调度算法的比较 图7和图8展示了分别使用先进先出调度算法和分布式实时约束感知调度算法的请求处理延迟的概率密度函数(PDF).通过图7和图8的对比,我们可以看到图8中的概率密度函数分布比图7的概率密度函数分布更集中,分布式实时约束感知调度算法可以使请求处理延迟波动降低约25%. Fig. 7 The PDF of request processing latency when using FIFO scheduling algorithm图7 请求处理延迟的概率密度分布(FIFO调度) Fig. 8 The PDF of request processing latency when using D2P-enabled deadline-aware scheduling algorithm图8 请求处理延迟的概率密度分布(实时约束感知调度) 图9则展示了服务阶段S1到S3上请求处理延迟的累积分布函数图,从图9中可以看出,分布式实时约束传播框架是通过优先调度落后请求和延迟调度非紧急请求来达到减少长尾延迟的目的;但是,从服务阶段S1到S3,随着请求处理延迟越来越接近用户期望的请求响应时间,分布式实时约束感知调度算法的作用则会有所削弱. Fig. 9 The CDF of request processing latency图9 请求处理延迟的累积分布函数 针对实验搭建的索引查询服务,我们也比较了使用先进先出(FIFO)调度算法和分布式实时约束感知(D2P-enabled deadline-aware)调度算法的请求平均处理延迟和95%请求处理延迟.如表2所示,相对于先进先出调度算法,分布式实时约束感知调度算法可以将工作节点上的95%请求处理延迟降低约10%. 我们以工作节点W1上的请求处理延迟情况为例,从图10和图11的请求处理延迟概率密度分布图及累计分布函数图可知,分布式实时约束感知调度算法相比先进先出调度算法,能够在一定程度上减少工作节点上的长尾延迟. 此外,我们在实验中观察到,针对同一个查询词,在不同的工作节点上的查询处理时间可能有较大差异.例如对同一个查询词“国际广播电台”,在工作节点W1和W2上的查询处理时间分别为5 457 ms和51 ms;而对查询词“善哉”,在工作节点W6和W7上的查询处理时间分别为107 ms和34 ms.虽然每一次查询都会受到一些随机因素的影响,但也可以看出索引数据的存储位置对请求的查询处理时间有较大的影响.而工作节点上的查询处理结束后,又会 Table 2 The Compare of FIFO and D2P-enabled Deadline - aware Scheduling in PUM表2 PUM中FIFO调度算法和实时约束感知调度算法比较 Fig. 10 The PDF of request processing latency at W1图10 在工作节点W1上请求处理延迟的概率密度分布 Fig. 11 The CDF of request processing latency at W1图11 在工作节点W1上请求处理延迟的累积分布 将查询结果返回给聚合节点进行汇总,聚合节点的处理延迟则会受限于最慢的工作节点;若最慢工作节点上的请求处理延迟未得到较多改善,则对聚合节点的请求处理延迟影响不大.所以,针对并行单元的请求处理延迟优化,还需要思考如何在工作节点上进行数据的存储优化,以及对请求增加并行度,以此来减少并行单元的长尾延迟. 本文提出了在数据中心的一种分布式实时约束传播方法,根据期望响应时间、请求执行时间及网络传输延迟来定义实时约束信息,并且能够将请求的全局实时约束信息传播到整个处理路径.此外,我们分别针对串行依赖模式和划分聚合模式的数据中心应用,提出了阶段服务模型和并行单元模型,将分布式实时约束传播方法应用到这2种模型上,实现了一个分布式实时约束传播框架.最后,在分布式实时约束传播框架上,我们利用请求全生命周期过程中所传播的实时约束信息来对请求进行优先级调度,用以减少长尾延迟现象,并通过实行了验证. 由于在数据中心环境下,影响数据中心应用服务质量和响应延迟的因素较多,如何保障请求全生命周期的服务质量作为一个开放性问题,也还需要进行更深入的探讨,我们也将在真实应用中验证分布式实时约束传播方法,并利用增加请求并行度的方法来减少长尾延迟现象. [1]Bao Yungang. The challenges and opportunities of guaranteeing quality of services in data center[J]. Journal of Integration Technology, 2013, 2(6): 71-81 (in Chinese)(包云岗. 数据中心保障应用服务质量面临的挑战与机遇[J]. 集成技术, 2013, 2(6): 71-81) [2]Krushevskaja D, Sandler M. Understanding latency variations of black box services[C]Proc of the 22nd Int Conf on World Wide Web. New York: ACM, 2013: 703-714 [3]Google. Google’s marissa mayer: Speed wins[EBOL]. (2006-11-09) [2013-04-21]. http:www.zdnet.comblogbtlgoogles-marissa-mayer-speed-wins3925 [4]Schurman E, Brutlag J. The user and business impact of server delays, additional bytes, and HTTP chunking in Web search[C]Proc of Velocity Web Performance and Operations Conf. San Jose, CA: O’Reilly, 2009 [5]Barroso L A, Clidaras J, Hoelzle U. The Datacenter as a Computer: An Introduction to the Design of Warehouse-scale Machines[M]. San Rafael, CA: Morgan & Claypool Publishers, 2009 [6]Dean J, Barroso L A. The tail at scale[J]. Communications of the ACM, 2013, 56(2): 74-80 [7]Dean J. Achieving rapid response times in large online services[C]Proc of Berkeley AMPLab Cloud Seminar. Berkeley: AMPLab, 2012 [8]Ren Rui, Ma Jiuyue, Sui Xiufeng, et al. D2P: A distributed deadline propagation approach to tolerate long-tail latency in datacenters[C]Proc of the 5th Asia-Pacific Workshop on Systems. New York: ACM, 2014: Article No.2 [9]Ousterhout K, Rasti R, Ratnasamy S, et al. Making sense of performance in data analytics frameworks[C]Proc of the 12th Symp on Networked Systems Design and Implementa-tion. Berkeley, CA: USENIX Association, 2015: 293-307 [10]Jeon M, He Y, Elnikety S, et al. Adaptive parallelism for Web search[C]Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 155-168 [11]Jeon M, Kim S, Hwang S W, et al. Predictive parallelization: Taming tail latencies in Web search[C]Proc of the 37th Int ACM SIGIR Conf on Research & Development in Information Retrieva. New York: ACM, 2014: 253-262 [12]Haque M E, Eom Y, He Y, et al. Few-to-Many: Incremental parallelism to reduce tail latency in interactive services[C]Proc of the 20th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2015: 161-175 [13]Kapoor R, Porter G, Tewari M, et al. Chronos: Predictable low latency for data center applications[C]Proc of the 3rd ACM Symp on Cloud Computing. New York: ACM, 2012: Article No.9 [14]Zats D, Das T, Mohan P, et al. DeTail: Reducing the flow completion time tail in datacenter network[J]. ACM SIGCOMM Computer Communication Review -Special October Issue SIGCOMM’12, 2012, 42(4): 139-150 [15]Alizadeh M, Greenberg A, Maltz D A, et al. Data center TCP (DCTCP)[C]Proc of ACM SIGCOMM 2010. New York: ACM, 2010: 63-74 [16]Vamanan B, Hasan J, Vijaykumar TN. Deadline-aware datacenter TCP (D2TCP)[J]. ACM SIGCOMM Computer Communication Review, 2012, 42(4): 115-126 [17]Canonical. Linux container[EBOL]. [2015-03-21]. https:linuxcontainers.org [18]Barham P, Dragovic B, Fraser K. Xen and the art of virtualization[C]Proc of the 19th ACM Symp on Operating Systems Principles. New York: ACM, 2003: 164-177 [19]Liu Lei, Cui Zehan, Xing Mingjie, et al. A software memory partition approach for eliminating bank-level interference in multicore systems[C]Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 367-376 [20]Cho S, Jin L. Managing distributed, shared L2 caches through OS-level page allocation[C]Proc of the 39th Annual IEEEACM Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2006: 455-468 [21]Jeong M K, Yoon D H, Sunwoo D. Balancing DRAM locality and parallelism in shared memory CMP systems[C]Proc of IEEE Int Symp on High-Performance Computer Architecture. Piscataway, NJ: IEEE, 2012: 1-12 [22]Mi Wei, Feng Xiaobing, Xue Jingling, et al. Software-hardware cooperative DRAM bank partitioning for chip multiprocessors[G]LNCS 6289: Proc of Network and Parallel Computing. Berlin: Springer, 2010: 329-343 [23]Tang Lingjan, Mars J, Wang Wei, et al. ReQoS: Reactive staticdynamic compilation for QoS in warehouse scale computers[C]Proc of the 18th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2013: 89-100 [24]Xu Yunjing, Musgrave Z, Noble B, et al. Bobtail: avoiding long tails in the cloud[C]Proc of the 10th Symp on Networked Systems Design and Implementation. New York: ACM, 2013: 329-341 [25]Cipar J, Ho Q, Kim J K, et al. Solving the straggler problem with bounded staleness[C]Proc of the 14th Workshop on Hot Topics in Operating Systems. Berkeley, CA: USENIX Association, 2013 [26]Ravindranath L, Padhye J, Agarwal S, et al. AppInsight: Mobile app performance monitoring in the wild[C]Proc of the 10th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 107-120 [27]Ravindranath L, Padhye J, Mahajan R, et al. Timecard: Controlling user-perceived delays in server-based mobile applications[C]Proc of the 24th ACM Symp on Operating Systems Principles. New York: ACM, 2013: 85-100 [28]Zhuravlev S, Blagodurov S, Fedorova A. Addressing shared resource contention in multicore processors via scheduling[C]Proc of the 15th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2010: 129-142 [29]Chen T S, Guo Q, Temam O, et al. Statistical performance comparisons of computers[J]. IEEE Trans on Computers, 2015, 64(5): 1442-1455 [30]Delimitrou C, Kozyrakis C. Paragon: QoS-aware scheduling for heterogeneous datacenters[C]Proc of the 18th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2013: 77-88 [31]Wikipedia. Least laxity first[EBOL]. [2013-07-18]. http:en.wikipedia.orgwikiLeast_slack_time_scheduling [32]Lin Jiang, Lu Qingda, Ding Xiaoning, et al. Gaining insights into multicore cache partitioning: Bridging the gap between simulation and real systems[C]Proc of the 14th Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2008: 367-378 [33]Alibaba. Dubbo: Distributed service framework[EBOL]. [2013-07-09]. http:dubbo.io [34]Chinese Academy of Sciences, Institute of Computing Technology. BigdataBench-Jstorm[EBOL]. [2016-04-02]. http:prof.ict.ac.cnbdb_uploadsbdb_streamingSearch-Engine-JStorm.tar.gz Ren Rui, born in 1987. PhD candidate in the Institute of Computing Technology, Chinese Academy of Sciences. Her main research interests include big data system and performance analysis. Ma Jiuyue, born in 1988. PhD. His main research interests include computer archi-tecture and operating system (majiuyue@ncic.ac.cn). Sui Xiufeng, born in 1982. Associate professor. His main research interests include high performance computer architecture, system performance modeling and evaluation, and cloud computing (suixiufeng@ict.ac.cn). Bao Yungang, born in 1980. Professor and PhD supervisor. Member of CCF. His main research interests include computer architecture, operating system and system performance modeling and evaluation (baoyg@ict.ac.cn). A Distributed Deadline Propagation Approach to Reduce Long-Tail in Datacenters Ren Rui1,2, Ma Jiuyue1,2, Sui Xiufeng1, and Bao Yungang1 1(InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049) Long-tail latency is inevitable and may be amplified for highly modular datacenter applications such as Bing, Facebook, and Amazon’s retail platform, due to resource sharing, queuing, background maintenance activities, etc. Thus how to tolerate the latency variability in shared environments is crucial in datacenters. This paper proposes a distributed deadline propagation (D2P) approach for datacenter applications to reduce long-tail latency. The key idea of D2P is inspired by the traffic light system in Manhattan, New York City, where one can enjoy a chain of green lights after one stop at a red light, and it allows local nodes to perceive global deadline information and to propagate the information among distributed nodes. Local nodes can leverage the information to do scheduling and adjust processing speed to reduce long-tail latency. Then, we propose stage-service model and parallel-unit model to describe sequentialdependent pattern and partitionaggregate pattern, and implement a distributed deadline propagation framework. At last, based on distributed deadline propagation framework, we use D2P-enabled deadline-aware scheduling algorithm to reduce long-tail latency in our experiments, and the preliminary experimental results show that D2P has the potential of reducing the long-tail latency in datacenters by local nodes leveraging the propagated deadline information. deadline propagation; long-tail latency; datacenter; partitionaggregates pattern; sequentialdependent pattern 2016-03-31; 2016-08-08 国家自然科学基金国际合作项目(61420106013);国家重点研发计划项目(2016YFB1000201) This work was supported by the International Cooperation Project of National Natural Science Foundation of China (61420106013) and the National Key Research and Development Program of China (2016YFB1000201). 包云岗(baoyg@ict.ac.cn) TP3025 性能评估




6 结束语


 猜你喜欢
机械研究与应用(2022年4期)2022-09-15北京航空航天大学学报(2022年8期)2022-08-31建材发展导向(2021年7期)2021-07-16西藏艺术研究(2019年1期)2019-09-04幽默大师(2018年5期)2018-10-27小哥白尼(野生动物)(2018年2期)2018-05-25能源(2017年10期)2017-12-20能源(2017年5期)2017-07-06雷达与对抗(2015年3期)2015-12-09中国交通信息化(2015年3期)2015-06-05
猜你喜欢
机械研究与应用(2022年4期)2022-09-15北京航空航天大学学报(2022年8期)2022-08-31建材发展导向(2021年7期)2021-07-16西藏艺术研究(2019年1期)2019-09-04幽默大师(2018年5期)2018-10-27小哥白尼(野生动物)(2018年2期)2018-05-25能源(2017年10期)2017-12-20能源(2017年5期)2017-07-06雷达与对抗(2015年3期)2015-12-09中国交通信息化(2015年3期)2015-06-05
