
不完备多粒度决策系统的局部最优粒度选择
2017-08-12 15:31顾沈明顾金燕吴伟志李同军陈超君
计算机研究与发展 2017年7期
顾沈明 顾金燕 吴伟志 李同军 陈超君
(浙江海洋大学数理与信息学院 浙江舟山 316022) (浙江省海洋大数据挖掘与应用重点实验室(浙江海洋大学) 浙江舟山 316022)
不完备多粒度决策系统的局部最优粒度选择
顾沈明 顾金燕 吴伟志 李同军 陈超君
(浙江海洋大学数理与信息学院 浙江舟山 316022) (浙江省海洋大数据挖掘与应用重点实验室(浙江海洋大学) 浙江舟山 316022)
(gsm@zjou.edu.cn)
粒计算是知识表示和数据挖掘的一个重要方法.从粒计算来看,一个粒是由多个比较小的颗粒组成的更大的一个单元.在许多实际应用中,由于不同标记尺度对数据集进行分割会得到不同层次的粒度,许多人在用粒计算解决问题时自然而然地考虑不同层次的粒度问题.这就促使思考如何选择一个合适的粒度层次来解决问题.围绕不完备多粒度决策系统,研究了基于局部最优粒度的规则提取方法.1)介绍了不完备多粒度决策系统的概念;2)在协调的不完备多粒度决策系统中定义了最优粒度和局部最优粒度、介绍了基于局部最优粒度的属性约简和规则提取方法,在不协调的不完备多粒度决策系统中引入了广义决策、定义了广义最优粒度和广义局部最优粒度,并给出了基于广义局部最优粒度的属性约简和规则提取方法;3)给出了在公开的数据集上的实验结果.
决策系统;粒计算;局部最优粒度;多粒度;规则提取
粒计算是当前智能信息处理领域中的一个研究热点.它模拟人的思考模式,以粒为基本计算单位,以处理大规模复杂数据并建立有效计算模型为目标.在1979年Zadeh[1]首次提出信息粒化的概念,认为人类认知能力可概括为粒化、组织和因果3个主要特征;1985年Hobbs[2]提出了粒度的概念,描述粒计算雏形的一些基本特征;而粒计算的概念是Lin[3]提出;后来Lin[4]和Yao[5]分别对粒计算的一些基本问题进行了阐述;张铃等人[6]提出的商空间理论被认为粒计算的另一重要模型.
近年来,许多涉及具体应用背景的粒计算模型与方法相继提出[7-13],其中粗糙集对粒计算研究的推动和发展起着重要作用[14-18].粗糙集是由Pawlak[19]提出的一种有效地处理不精确、不确定信息的数学理论方法.属性约简和规则提取是粗糙集理论中非常重要的研究内容[20-21];张文修等人[22]对不协调目标系统进行属性约简;王国胤等人[23]研究了信息观下的属性约简,以及属性约简的不确定度量;Mi等人[24]提出一种基于变精度粗糙集的属性约简方法;苗夺谦等人[25]给出了知识约简的一种启发式算法;Skowron和Rauszer[26]提出的可辨识矩阵为求取属性约简提供了很好的思路.
粗糙集在进行数据分析时,往往把数据表示为属性—值的表格形式,称作信息系统.在经典的信息系统中,每一个对象在每一个属性上只能取一个观测值.这样的信息系统称为单粒度信息系统.单一粒度框架下的知识表示与数据挖掘很难满足复杂问题的需要.人们努力从多层次、多角度来研究复杂问题,这就是多粒度的思想.Qian等人[27]提出乐观粗糙集与悲观粗糙集的多粒度粗糙集模型,其主要思想是通过属性选择进行交、并运算,再进行数据处理.此外,人们观察物体或处理数据时,会根据不同的尺度得到不同层次的观测值,即反映同一对象同一属性在不同粒度层次下的变化情况.针对这种情况,Wu等人[28]提出基于多粒度标记划分的粗糙集数据分析方法,还进一步讨论在此模型下最优粒度的选择问题[29-31];Gu等人[32-33]还给出协调和不协调的多粒度标记决策系统中的知识获取算法.
本文主要针对不完备多粒度决策系统,进一步讨论局部最优粒度的选择问题.分别在协调的、不协调的不完备多粒度决策系统讨论局部最优粒度选择与广义局部最优粒度选择问题,并讨论相应的属性约简与规则提取等问题.
1 相关基础知识
1.1 不完备信息系统
一个信息系统是一个二元组(U,C),其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域;C={a1,a2,…,am}是一个非空有限属性集,对于任意的a∈C,满足a:U→Va,也就是a(x)∈Va,x∈U,其中Va={a(x)|x∈U}称作a的值域[34].
当信息系统中的某些值是未知的,则称为不完备信息系统,仍表示为(U,C).用符号“*”表示未知值或缺省值,即如果a(x)=*,就认为x在属性a上的值是未知的.
对于给定的一个不完备信息系统(U,C),并且A⊆C,记:
RA={(x,y)∈U×U:∀a∈A,
a(x)=a(y)∨a(x)=*∨a(y)=*}.
(1)
显然,RA是自反和对称的,即RA是相似关系,但一般是非传递的[35],记:
SA(x)={y∈U:(x,y)∈RA},x∈U,
(2)
SA(x)称为对象x关于RA的相似类[36],记:
URA={SA(x):x∈U}.
(3)
设(U,C)是一个不完备信息系统,A⊆C,X⊆U,X关于RA的下近似和上近似定义为
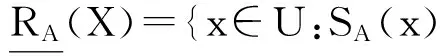
(4)

(5)

1.2 决策规则
决策系统是一个二元组S=(U,C∪{d}),其中(U,C)是一个信息系统,C称为条件属性,d∉C称为决策属性,映射d:U→Vd,其中Vd是决策属性d的值域[34].


(6)

规则t→s的可信度定义为

(7)
规则的可信度反映了满足规则前件的实例中有多少可以划分到规则后件表示的决策类中的比例.规则的可信度通常用来作为规则的有效性度量,应用于规则的评价和检验中.
2 不完备多粒度决策系统

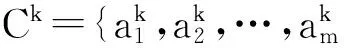

(8)

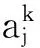
(9)
其中,1≤k≤I-1.这样也得到了I个不完备信息系统Sk=(U,Ck),k=1,2,…,I.
称S=(U,C∪{d})为不完备多粒度决策系统,如果(U,C)是不完备多粒度信息系统,d∉C,是一个单粒度决策属性,d:U→Vd,Vd是决策属性d的值域.显然,对于给定k(1≤k≤I),就有决策系统Sk=(U,Ck∪{d}),因此就有I层不完备的决策系统.
例1. 设论域U={x1,x2,…,x8},属性集C={a1,a2,a3},决策属性d;第1层决策系统S1=(U,C1∪{d}),如表1所示;第2层决策系统S2=(U,C2∪{d}),如表2所示;第3层决策系统S3=(U,C3∪{d}),如表3所示.

Table 1 Decision System of the First Level Granularity表1 第1层粒度的决策系统

Table 2 Decision System of the Second Level Granularity表2 第2层粒度的决策系统
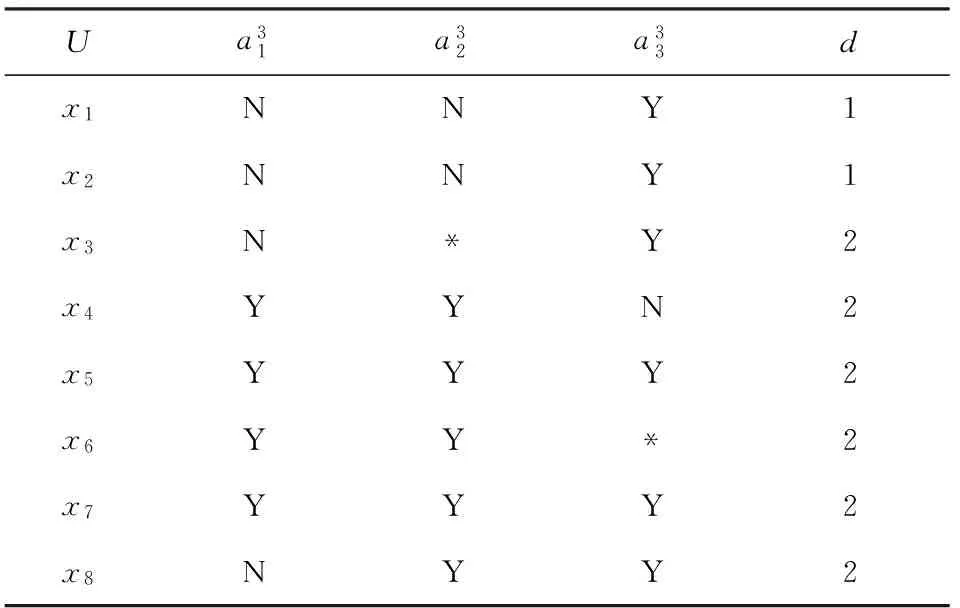
Table 3 Decision System of the Third Level Granularity表3 第3层粒度的决策系统
在不完备多粒度决策系统S=(U,C∪{d})中,对于给定的k(1≤k≤I),有Sk=(U,Ck∪{d}).若RC1⊆Rd,则称S1=(U,C1∪{d})是协调的,同时也称S=(U,C∪{d})是协调的.若S1=(U,C1∪{d})是不协调的,则称S=(U,C∪{d})是不协调的.下面对协调的、不协调的不完备多粒度决策系统分别进行讨论.
3 协调的不完备多粒度决策系统
3.1 局部最优粒度
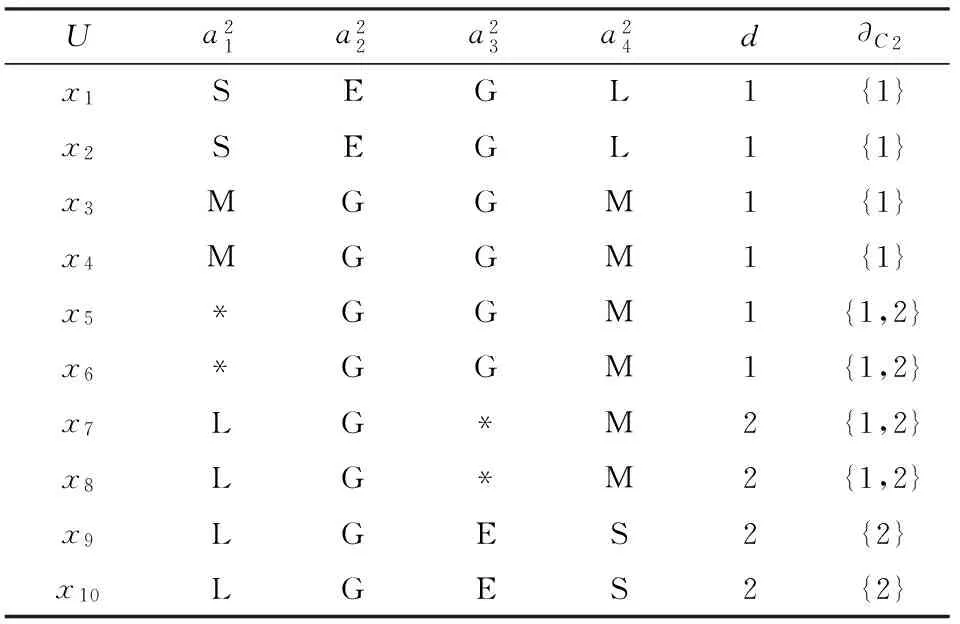
在不完备多粒度决策系统S=(U,C∪{d})中,对于给定的k(1≤k 例2. 例1中的系统S=(U,C∪{d}),在每一层上有相似类: 第1层.SC1(x1)={x1},SC1(x2)={x2},SC1(x3)={x3},SC1(x4)={x4},SC1(x5)={x5},SC1(x6)={x6},SC1(x7)={x7},SC1(x8)={x8}; 第2层.SC2(x1)={x1,x2},SC2(x2)={x1,x2},SC2(x3)={x3},SC2(x4)={x4},SC2(x5)={x5},SC2(x6)={x6,x7},SC2(x7)={x6,x7},SC2(x8)={x8}; 第3层.SC3(x1)={x1,x2,x3},SC3(x2)={x1,x2,x3},SC3(x3)={x1,x2,x3,x8},SC3(x4)={x4,x6},SC3(x5)={x5,x6,x7},SC3(x6)={x4,x5,x6,x7},SC3(x7)={x5,x6,x7},SC3(x8)={x3,x8}. 系统有决策类: Ud={{x1,x2},{x3,x4,x5,x6,x7,x8}}. 显然,S1=(U,C1∪{d})是协调的,所以多粒度决策系统S=(U,C∪{d})是协调的.S2=(U,C2∪{d})是协调的,S3=(U,C3∪{d})是不协调的,所以第2层粒度是全局最优粒度. 在不完备多粒度决策系统中,全局最优粒度是面向系统的.也就说,找到全局最优粒度是指系统达到最优.然而,对于单个对象而言,系统达到最优粒度时单个对象不一定达到最优.有的对象达到最优粒度,有的对象没有达到最优粒度.因此,我们来讨论基于对象的局部最优粒度. 在不完备多粒度决策系统S=(U,C∪{d})中,对于x∈U,给定k(1≤k 例3. 对于例1中的多粒度决策系统S=(U,C∪{d}),关于每个对象局部最优粒度如下: SC1(x1)⊆SC2(x1)⊆[x1]d,关于x1的局部最优粒度为第2层粒度; SC1(x2)⊆SC2(x2)⊆[x2]d,关于x2的局部最优粒度为第2层粒度; SC1(x3)⊆SC2(x3)⊆[x3]d,关于x3的局部最优粒度为第2层粒度; SC1(x4)⊆SC2(x4)⊆SC3(x4)⊆[x4]d,关于x4的局部最优粒度为第3层粒度; SC1(x5)⊆SC2(x5)⊆SC3(x5)⊆[x5]d,关于x5的局部最优粒度为第3层粒度; SC1(x6)⊆SC2(x6)⊆SC3(x6)⊆[x6]d,关于x6的局部最优粒度为第3层粒度; SC1(x7)⊆SC2(x7)⊆SC3(x7)⊆[x7]d,关于x7的局部最优粒度为第3层粒度; SC1(x8)⊆SC2(x8)⊆SC3(x8)⊆[x8]d,关于x8的局部最优粒度为第3层粒度. 显然,在全局最优的第2层粒度上,只有对象x1,x2和x3达到最优粒度.对象x4,x5,x6,x7,x8的局部最优粒度为第3层粒度.因此,不同的对象会在不同的粒度层次上达到最优粒度. 3.2 局部相对约简 属性约简是粗糙集理论中的一个重要研究内容.一般来说,属性约简是保持决策系统某种特定性质不变条件下的最小属性集合.通常情况下,不同的限制条件下会得到不同的约简结果.下面主要讨论保持协调性不变的条件下基于局部最优粒度的属性约简. 在不完备多粒度决策系统S=(U,C∪{d})中,给定对象x∈U的局部最优粒度层k,存在Bk⊆Ck,使SBk(x)⊆[x]d成立,且对于任意bk∈Bk,SBk-{b}(x)⊆[x]d不成立,则称Bk是Ck关于对象x的局部相对约简. 显然,在不完备多粒度决策系统中,属性约简之前要确定局部最优粒度.在找到局部最优粒度之后,属性约简的方法与单粒度决策系统一致. 3.3 规则提取与实现算法 在粗糙集理论中,隐藏在决策系统中的知识通常是以规则的形式被挖掘出来.在不完备多粒度决策系统中,不同的粒度层次会有不同粒度的决策规则.为了使规则具有较好的代表性,首先根据对象选择局部最优粒度;然后在保持协调性不变的基础上进行属性约简;最后把规则按“条件→决策”的形式从多粒度决策系统中提取出来. 在不完备多粒度决策系统S=(U,C∪{d})中,基于局部最优粒度的规则可以分别获取,具体算法如算法1所示. 算法1. 协调系统的局部最优粒度规则挖掘算法. 输入: 协调的不完备多粒度决策系统S=(U,C∪{d}); 输出: 局部最优粒度下的规则. Setopti_level[1,2,…,n]←1; Fork=2 toIdo Fori=1 tondo IfSCk(xi)⊆[xi]dthen opti_level[i]←k; EndIf EndFor EndFor Fork=Ito 1 do Setno←0; Fori=1 tondo Ifopti_level[i]==kthen no++; B←Ck; Forj=1 tomdo IfSB-{aj}(xi)⊆[xi]dthen B←(B-{aj}); EndIf EndFor t←∅; For eachaj∈Bdo t←t∧(aj,aj(xi)); EndFor opti_level[i]←0; EndIf EndFor EndFor 算法1首先计算了每个对象的最优粒度层次,时间复杂度为O(nI).但是每次计算涉及相似类的计算,而每个相似类的计算需要时间复杂度为O(nm),所以时间复杂度为O(n2mI).接着根据每个对象的最优粒度层次,计算局部相对约简,有3层循环嵌套,时间复杂度为O(nmI),同样内循环涉及相似类的计算,所以时间复杂度为O(n2m2I).所以总的时间复杂度为O(n2m2I). 例5. 对于例1中的不完备多粒度决策系统S=(U,C∪{d}),根据算法1,可以得到局部最优粒度下的规则: 显然,上述规则的可信度都为1. 4.1 广义局部最优粒度 在不协调的不完备多粒度决策系统S=(U,C∪{d})中,对于任意的k(1≤k≤I),Sk=(U,Ck∪{d})都是不协调的.下面引入对象x的广义决策∂Ck(x): ∂Ck(x)={d(y):y∈SCk(x)},x∈U. (11) 对于Sk=(U,Ck∪{d}),若∀x∈U,都有∂Ck(x)=∂C1(x),则称Sk=(U,Ck∪{d})是广义协调的.对于给定的k(1≤k 同样,广义全局最优粒度是面向系统的,对于单个对象而言,系统达到广义最优粒度时单个对象不一定达到广义最优.有的对象达到广义最优粒度,有的对象没有达到广义最优粒度.因此,我们来讨论基于对象的广义局部最优粒度. 在不完备多粒度决策系统S=(U,C∪{d})中,对于x∈U,给定k(1≤k 例6. 一个不协调的不完备多粒度决策系统S=(U,C∪{d}),论域U={x1,x2,…,x10},属性集C={a1,a2,a3,a4},决策属性d;第1层决策系统S1=(U,C1∪{d}),如表4所示;第2层决策系统S2=(U,C2∪{d}),如表5所示;第3层决策系统S3=(U,C3∪{d}),如表6所示. Table 4 Decision System of the First Level Granularity表4 第1层粒度的决策系统 Table 5 Decision System of the Second Level Granularity表5 第2层粒度的决策系统 Table 6 Decision System of the Third Level Granularity表6 第3层粒度的决策系统 显然,∀x∈{x1,x2,…,x10},∂C2(x)=∂C1(x)成立,而∂C3(x)=∂C1(x)不成立,即S2=(U,C2∪{d})是广义协调的,S3=(U,C3∪{d})不是广义协调的,所以第2层粒度是广义全局最优粒度. 关于每个对象的广义局部最优粒度如下: 当xi∈{x1,x2,…,x8}时,∂C3(xi)=∂C1(xi)成立,即关于对象xi的广义局部最优粒度为第3层粒度; 当xi∈{x9,x10}时,∂C2(xi)=∂C1(xi)成立,而∂C3(xi)=∂C1(xi)不成立,即关于对象xi的广义局部最优粒度为第2层粒度; 显然,不同的对象会在不同的粒度层次上达到广义局部最优粒度. 4.2 广义局部相对约简 在不协调的不完备多粒度决策系统S=(U,C∪{d})中,给定对象x∈U的广义局部最优粒度层k,存在Bk⊆Ck,使∂Bk(x)=∂Ck(x)成立,且对于任意bk∈Bk,∂Bk-{b}(x)=∂Ck(x)不成立,则称Bk是Ck关于对象x的广义局部相对约简. 4.3 广义规则提取与实现算法 在不协调的不完备多粒度决策系统S=(U,C∪{d})中,基于广义局部最优粒度的规则可以分别获取,具体算法如算法2所示: 算法2. 不协调系统的广义局部最优粒度规则挖掘算法. 输入: 不协调的不完备多粒度决策系统S=(U,C∪{d}); 输出: 广义局部最优粒度下的规则. Setgopti_level[1,2,…,n]←1; Fork=2 toIdo Fori=1 tondo If ∂Ck(xi)=∂C1(xi) then gopti_level[i]←k; EndIf EndFor EndFor Fork=Ito 1 do Setno←0; Fori=1 tondo Ifgopti_level[i]==kthen no++; B←Ck; Forj=1 tomdo If ∂B-{aj}(xi)=∂Ck(xi) then B←(B-{aj}); EndIf EndFor t←∅; For eachaj∈Bdo t←t∧(aj,aj(xi)); EndFor For eachdj∈∂Ck(xi) do EndFor gopti_level[i]←0; EndIf EndFor EndFor 算法2首先计算了每个对象的广义最优粒度层次,两重循环的时间复杂度为O(nI).但是每次计算涉及广义决策的计算,计算需要时间复杂度为O(nm),所以时间复杂度为O(n2mI).接着根据每个对象的广义最优粒度层次,计算局部相对约简,3层循环嵌套的时间复杂度为O(nmI),同样内循环涉及广义决策的计算,时间复杂度为O(n2m2I).所以总的时间复杂度为O(n2m2I). 例8. 对于例6中不协调的不完备多粒度决策系统S=(U,C∪{d}),根据算法2,可以得到广义局部最优粒度下的规则: 我们对上述算法用UCI公开数据集进行实验验证,对于协调的和不协调的不完备决策系统的实验情况分别介绍如下: 实验1. 协调的不完备决策系统. 选用的数据集是乳腺癌数据集,共有699条记录,除了编号外有10个属性,其中缺省值有16个.我们用映射的方法构造了3层粒度,经过验算系统是协调的,而且全局最优粒度是第2层粒度.经过程序运行后删除重复的规则,我们在第3层粒度上得到109条确定性规则,在第2层粒度上得到21条确定性规则. 实验2. 不协调的不完备决策系统. 选用的数据集是乳房X片数据集,共有961条记录,除了编号外有6个属性,其中缺省值有162个.我们删除了年龄属性后用映射的方法构造了3层粒度,经过验算系统是不协调的.所以引入广义决策,并且广义全局最优粒度是第1层粒度.经过程序运行后删除重复的规则,我们在第3层粒度上得到10条确定性规则、34条可能性规则,在第2层粒度上得到5条确定性规则、6条可能性规则,在第1层粒度上得到3条确定性规则、4条可能性规则. 在经典的粗糙集方法中,每个对象在某个属性上只能取一个值.但是人们在实际处理问题时,可能需要在不同的粒度层次上用不同值来表示.本文介绍不完备多粒度决策系统的概念,对协调的系统通过局部最优粒度和局部约简来挖掘基于局部最优粒度的规则;对于不协调的系统通过广义局部最优粒度和广义局部约简来挖掘基于广义局部最优粒度的规则;同时结合例子分别给出了规则提取的算法.这种属性约简与规则提取尽可能在合适的粒度上进行,这对于多粒度决策系统的知识获取具有重要意义.在后续的研究中,将讨论多粒度序信息系统中最优粒度的选择问题. [1]Zadeh L A. Fuzzy sets and information granularity[G]Advances in Fuzzy Set Theory and Applications. Amsterdam: North-Holland, 1979: 3-18 [2]Hobbs J R. Granularity[C]Proc of the 9th Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1985: 432-435 [3]Lin T Y. Granular computing on binary relations I: Data mining and neighborhood systems[G]Rough Sets in Knowledge Discovery. Heidelberg: Physica-Verlag, 1998: 107-121 [4]Lin T Y. Granular computing: Structures, representations, and applications[G]LNAI 2639: Proc of the 9th Int Conf on Rough Sets, Fuzzy Sets, Data Mining, and Granular Computing. Berlin: Springer, 2003: 16-24 [5]Yao Yiyu. Granular computing: Basic issues and possible solutions[C]Proc of the 5th Joint Conf on Computing and Information. Durham, NC: Duke University Press, 2000: 186-189 [6]Zhang Ling, Zhang Bo. Quotient Space Based Problem Solving: A Theoretical foundation of Granular Computing[M]. Beijing: Tsinghua University Press, 2014 (in Chinese)(张铃, 张钹. 基于商空间的问题求解: 粒度计算的理论基础[M]. 北京: 清华大学出版社, 2014) [7]Liang Jiye, Qian Yuhua, Li Deyu, et al. Theory and method of granular computing for big data mining[J]. Scientia Sinica: Informationis, 2015, 45(11): 1355-1369 (in Chinese)(梁吉业, 钱宇华, 李德玉, 等. 大数据挖掘的粒计算理论与方法[J]. 中国科学: 信息科学, 2015, 45(11): 1355-1369) [8]Yao J T, Vasilakos A V, Pedrycz W. Granular computing: Perspectives and challenges[J]. IEEE Trans on Cybernetics, 2013, 43(6): 1977-1989 [9]Liu Qing, Qiu Taorong, Liu Lan. The research of granular computing based on nonstandard analysis[J]. Chinese Journal of Computers, 2015, 38(8): 1618-1627 (in Chinese)(刘清, 邱桃荣, 刘斓. 基于非标准分析的粒计算研究[J]. 计算机学报, 2015, 38(8): 1618-1627) [10]Hu Jie, Li Tianrui, Wang Hongjun, et al. Hierarchical cluster ensemble model based on knowledge granulation[J]. Knowledge-Based Systems, 2016, 91: 179-188 [11]Yang Xibei, Qian Yuhua, Yang Jingyu. Hierarchical structures on multigranulation spaces[J]. Journal of Computer Science and Technology, 2012, 27(6): 1169-1183 [12]Xu Ji, Wang Guoyin, Yu Hong. Review of big data processing based on granular computing[J]. Chinese Journal of Computers, 2015, 38(8): 1497-1517 (in Chinese)(徐计, 王国胤, 于洪. 基于粒计算的大数据处理[J]. 计算机学报, 2015, 38(8): 1497-1517) [13]Liu Qing, Liu Qun. Granules and applications of granular computing in logical reasoning[J]. Journal of Computer Research and Development, 2004, 41(4): 546-551 (in Chinese)(刘清, 刘群. 粒及粒计算在逻辑推理中的应用[J]. 计算机研究与发展, 2004, 41(4): 546-551) [14]Hu Qinghua, Yu Daren, Xie Zongxia, et al. Fuzzy probabilistic approximation spaces and their information measures[J]. IEEE Trans on Fuzzy Systems, 2006, 14 (2): 191-201 [15]Zhao Suyun, Wang Xizhao, Chen Degang, et al. Nested structure in parameterized rough reduction[J]. Information Sciences, 2013, 248(6): 130-150 [16]Shao Mingwen, Leung Y, Wu Weizhi. Rule acquisition and complexity reduction in formal decision contexts[J]. International Journal of Approximate Reasoning, 2014, 55(1): 259-274 [17]Zhang Qinghua, Xue Yubin, Wang Guoyin. Optimal approximation sets of rough sets[J]. Journal of Software, 2016, 27(2): 295-308 (in Chinese)(张清华, 薛玉斌, 王国胤. 粗糙集的最优近似集[J]. 软件学报, 2016, 27(2): 295-308) [18]Duan Jie, Hu Qinghua, Zhang Lingjun, et al. Feature selection for multi-label classification based on neighborhood rough sets[J]. Journal of Computer Research and Development, 2015, 52(1): 56-65 (in Chinese)(段洁, 胡清华, 张灵均, 等. 基于邻域粗糙集的多标记分类特征选择算法[J]. 计算机研究与发展, 2015, 52(1): 56-65) [19]Pawlak Z. Rough sets[J]. International Journal of Computer and Information Science, 1982, 11(5): 341-356 [20]Deng Dayong, Xu Xiaoyu, Huang Houkuan. Concept drifting detection for categorical evolving data based on parallel reducts[J]. Journal of Computer Research and Development, 2015, 52(5): 1071-1079 (in Chinese)(邓大勇, 徐小玉, 黄厚宽. 基于并行约简的概念漂移探测[J]. 计算机研究与发展, 2015, 52(5): 1071-1079) [21]Fu Zhiyao, Gao Ling, Sun Qian, et al. Evaluation of vulnerability severity based on rough sets and attributes reduction[J]. Journal of Computer Research and Development, 2016, 53(5): 1009-1017 (in Chinese)(付志耀, 高岭, 孙骞, 等. 基于粗糙集的漏洞属性约简及严重性评估[J]. 计算机研究与发展, 2016, 53(5): 1009-1017) [22]Zhang Wenxiu, Mi Jusheng, Wu Weizhi. Knowledge reductions in inconsistent information systems[J]. Chinese Journal of Computers, 2003, 26(1): 12-18 (in Chinese)(张文修, 米据生, 吴伟志. 不协调目标信息系统的知识约简[J]. 计算机学报, 2003, 26(1): 12-18) [23]Wang Guoyin, Yu Hong, Yang Dachun. Decision table reduction based on conditional information entropy[J]. Chinese Journal of Computers, 2002, 25(7): 759-766 (in Chinese)(王国胤, 于洪, 杨大春. 基于条件信息熵的决策表约简[J]. 计算机学报, 2002, 25(7): 759-766) [24]Mi Jusheng, Wu Weizhi, Zhang Wenxiu. Approaches to knowledge reduction based on variable precision rough set model[J]. Information Sciences, 2004, 159(34): 255-272 [25]Miao Duoqian, Hu Guirong. A Heuristic algorithm for reduction of knowledge[J]. Journal of Computer Research and Development, 1999, 36(6): 681-684 (in Chinese)(苗夺谦, 胡桂荣. 知识约简的一种启发式算法[J]. 计算机研究与发展, 1999, 36(6): 681-684) [26]Skowron A, Rauszer C. The discernibility matrices and functions in information systems[G]Intelligent Decision Support—Handbook of Applications and Advances of the Rough Sets Theory. Amsterdam: Kluwer Academic Publishers, 1992: 331-362 [27]Qian Yuhua, Liang Jiye, Yao Yiyu, et al. MGRS: A multi-granulation rough set[J]. Information Sciences, 2010, 180 (6): 949-970 [28]Wu Weizhi, Leung Yee. Theory and applications of granular labelled partitions in multi-scale decision tables[J]. Information Sciences, 2011, 181(18): 3878-3897 [29]Wu Weizhi, Leung Yee. Optimal scale selection for multi-scale decision tables[J]. International Journal of Approximate Reasoning, 2013, 54(8): 1107-1129 [30]Wu Weizhi, Chen Ying, Xu Youhong, et al. Optimal granularity selections in consistent incomplete multi-granular labeled decision systems[J]. Pattern Recognition and Artificial Intelligence, 2016, 29(2): 108-115 (in Chinese)(吴伟志, 陈颖, 徐优红, 等. 协调的不完备多粒度标记决策系统的最优粒度选择[J]. 模式识别与人工智能, 2016, 29(2): 108-115) [31]Wu Weizhi, Gao Cangjian, Li Tongjun. Ordered granular labeled structures and rough approximations[J]. Journal of Computer Research and Development, 2014, 51(12): 2623-2632 (in Chinese)(吴伟志, 高仓健, 李同军. 序粒度标记结构及其粗糙近似[J]. 计算机研究与发展, 2014, 51(12): 2623-2632) [32]Gu Shenming, Wu Weizhi. On knowledge acquisition in multi-scale decision systems[J]. International Journal of Machine Learning and Cybernetics, 2013, 4(5): 477-486 [33]Gu Shenming, Wu Weizhi. Knowledge acquisition in inconsistent multi-scale decision systems[G]LNCS 6954: Proc of the 6th Int Conf on Rough Sets and Knowledge Technology. Berlin: Springer, 2011: 669-678 [34]Wu Weizhi. Attribute reduction based on evidence theory in incomplete decision systems[J]. Information Sciences, 2008, 178(5): 1355-1371 [35]Kryszkiewicz M. Rough set approach to incomplete information systems[J]. Information Sciences, 1998, 112(1234): 39-49 [36]Yang Xibei, Song Xiaoning, Chen Zehua, et al. On multigranulation rough sets in incomplete information system[J]. International Journal of Machine Learning and Cybernetics, 2012, 3(3): 223-232 Gu Shenming, born in 1970. Professor. Senior member of CCF. His main research interests include rough set theory, granular computing, concept lattice, machine learning, etc. Gu Jinyan, born in 1993. Master. Her main research interests include rough set theory, granular computing, artificial intelligence, etc (974795816@qq.com). Wu Weizhi, born in 1964. Professor and PhD supervisor. Senior member of CCF. His main research interests include rough set theory, granular computing, random set theory, concept lattice, approxing reasoning, etc (wuwz@zjou.edu.cn). Li Tongjun, born in 1966. PhD and professor. His main research interests include rough set theory, granular computing, concept lattice, etc (litj@zjou.edu.cn). Chen Chaojun, born in 1992. Master. Her main research interests include rough set theory, granular computing, artificial intelligence, etc (972237554@qq.com) Local Optimal Granularity Selections in Incomplete Multi-Granular Decision Systems Gu Shenming, Gu Jinyan, Wu Weizhi, Li Tongjun, and Chen Chaojun (SchoolofMathematics,PhysicsandInformationScience,ZhejiangOceanUniversity,Zhoushan,Zhejiang316022) (KeyLaboratoryofOceanographicBigDataMining&ApplicationofZhejiangProvince(ZhejiangOceanUniversity),Zhoushan,Zhejiang316022) Granular computing is an approach for knowledge representing and data mining. With the view point of granular computing, the notion of a granule is interpreted as one of the numerous small particles forming a larger unit. In many real-life applications, there are different granules at different levels of scale in data sets having hierarchical scale structures. Many people apply granular computing for problem solving by considering multiple levels of granularity. This allows us to focus on solving a problem at the most appropriate level of granularity by ignoring unimportant and irrelevant details. In this paper, rule extraction based on the local optimal granularities in incomplete multi-granular decision systems is explored. Firstly, the concept of incomplete multi-granular decision systems is introduced. Then the notions of the optimal granularity and the local optimal granularity in consistent incomplete multi-granular decision system are defined, and the approaches to attribute reduction and rule extraction based on the local optimal granularities are illustrated; the generalized decisions in inconsistent incomplete multi-granular decision systems are further introduced, the generalized optimal granularity and the generalized local optimal granularity are also defined, and the approaches to attribute reduction and rule extraction based on the generalized local optimal granularities are investigated. Finally, the experimental results on the public datasets are discussed. decision system; granular computing; local optimal granularity; multi-granularity; rule extraction 2016-05-24; 2016-10-10 国家自然科学基金项目(61602415,61573321,61272021,41631179);浙江省自然科学基金项目(LY14F030001);浙江省海洋科学重中之重学科开放基金项目(20160102) This work was supported by the National Natural Science Foundation of China (61602415, 61573321, 61272021, 41631179), the Natural Science Foundation of Zhejiang Province of China (LY14F030001), and the Open Foundation from Marine Sciences in the Most Important Subjects of Zhejiang Province (20160102). TP18




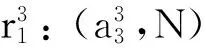
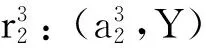
4 不协调的不完备多粒度决策系统





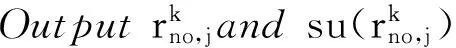
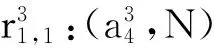

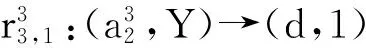


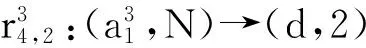

5 实验验证
6 结束语




 猜你喜欢
舰船科学技术(2022年20期)2022-11-28数学物理学报(2022年3期)2022-05-25科教导刊·电子版(2021年6期)2021-05-06中国中医急症(2019年10期)2019-05-21汉字汉语研究(2018年1期)2018-05-26华东师范大学学报(自然科学版)(2018年3期)2018-05-14自动化学报(2018年2期)2018-04-12智能系统学报(2017年3期)2017-08-01中国工程咨询(2017年10期)2017-01-31现代计算机(2016年17期)2016-02-28
猜你喜欢
舰船科学技术(2022年20期)2022-11-28数学物理学报(2022年3期)2022-05-25科教导刊·电子版(2021年6期)2021-05-06中国中医急症(2019年10期)2019-05-21汉字汉语研究(2018年1期)2018-05-26华东师范大学学报(自然科学版)(2018年3期)2018-05-14自动化学报(2018年2期)2018-04-12智能系统学报(2017年3期)2017-08-01中国工程咨询(2017年10期)2017-01-31现代计算机(2016年17期)2016-02-28
