
基于邻居选取策略的人群定向算法
2017-08-12 15:31朱福喜
计算机研究与发展 2017年7期
周 孟 朱福喜,2
1(武汉大学计算机学院 武汉 430072)2 (汉口学院计算机科学与技术学院 武汉 430212)
基于邻居选取策略的人群定向算法
周 孟1朱福喜1,2
1(武汉大学计算机学院 武汉 430072)2(汉口学院计算机科学与技术学院 武汉 430212)
(angel19851229@163.com)
人群定向是广告推荐系统中的一种重要技术,它是通过分析种子人群的行为数据,找出潜在的目标人群,而现有人群定向算法大多依赖于传统的协同过滤推荐算法.由于传统的协同过滤算法具有推荐精度低和抗攻击能力较弱的问题,为了解决这些问题,提出了一种基于邻居选取策略的人群定向算法.1)通过用户行为相似,动态选择出与种子人群具有相似行为的用户;2)以用户特征和用户行为作为邻居选取的依据,通过用户相似度从行为相似人群中选择出每个种子用户的邻居,并将所有的相似邻居作为候选人群;3)通过基于邻居选取策略的人群定向算法,从候选人群中择出潜在的目标用户,以完成人群定向.实验结果表明:与现有方法相比,该方法不仅提高了人群定向的精度,而且也增强了系统的抗攻击能力.
种子人群;行为相似人群;邻居选取策略;用户相似度;人群定向
目前随着互联网的发展,互联网广告的数据资源以惊人的速度增长,为了解决广告主向目标用户投放广告的需求,人群定向技术应运而生.人群定向主要通过现有用户的行为,找出未来潜在的目标人群,并选择适当的广告投放给这些目标人群.
人群定向的精度依赖于信息过滤的技术,而在现有的技术中,推荐系统已经成为解决互联网信息过滤的主要有效工具,并且应用十分广泛[1].在现有推荐技术中,基于协同过滤的推荐方法是主要常用的技术,其主要是通过协同过滤算法,找出行为相似的用户,并对目标用户进行商品推荐.但是,以往的协同过滤推荐算法,仅仅使用了用户对商品的评分来选取相似度比较高的用户作为推荐的对象,从而导致了系统的推荐精度很低.这是因为用户对商品的评分数据比较稀疏,并且在推荐系统中没有深入考虑到用户的详细信息,如性别、年龄、职业等.为了提高推荐算法的性能和用户满意度,很多学者提出了不同的推荐方法.如黄震华等人[2]将排序学习融入推荐系统中,并通过整合大量的用户和物品的特征,构建用户偏好需求模型,来提高推荐算法的性能和用户满意度;郭磊等人[3]提出了一种结合推荐对象间关联关系进行推荐的算法,该算法不仅考虑了用户间的社会关系,而且还考虑了推荐对象间的关联关系;荣辉桂等人[4]提出了基于用户相似度协同过滤推荐方法,该方法是通过用户之间的不同社交关系来计算用户间的相似度.虽然上述方法都提高了推荐系统的性能,但是这些推荐系统都没有考虑到大量的用户概貌攻击问题.
1 相关工作
对于推荐系统的研究工作,国内外学者提出了许多的推荐算法.目前,传统的主流推荐算法是基于内容过滤的推荐算法[5-6]和基于协同过滤的推荐算法[7-9].基于内容过滤的推荐算法主要不需要专门的领域知识,而且推荐的结果直观、容易理解,但是该算法无法灵活结合用户兴趣等其他多方面的有用信息;基于协同过滤的推荐算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法.基于用户的协同过滤算法充分利用了相似用户的信息,并为目标用户产生推荐集合,但是在该算法中,涉及到用户的信息量相当有限,并且数据相对稀疏,即用户对项目的评分相对较少,于是造成了严重的数据冷启动问题.在这种情况下,推荐的精确度将会受到严重影响,大大降低了推荐系统的性能;基于项目的协同过滤推荐算法则是鉴于用户已评分的项目,预测相似项目的评分.虽然该方法减少了数据稀疏性和冷启动问题对推荐系统的影响,但是用户的兴趣爱好是随着时间变化的,该方法的推荐覆盖率较低,并且用户对推荐的满意度也较低.
为解决数据稀疏和冷启动问题,Chen等人[10]提出了2阶段聚类的推荐算法,并将图摘要方法和基于内容相似度的算法结合,实现了基于用户兴趣的推荐,减少了数据稀疏和冷启动问题对推荐系统的影响.Wang等人[11]首先对用户进行分类,并对不同的行为分配不同的权重;然后计算用户间的相似度,并根据用户间的相似行为,产生相应的用户推荐集合.虽然该方法取得了一定的效果,但该方法需要用户的大量行为数据,如果在用户行为较少的情况下,不能产生良好的推荐效果.Koren[12]提出了基于矩阵分解的推荐算法,该算法解决了数据稀疏的问题,提高了系统推荐的质量;但该方法没有考虑到用户攻击概貌对推荐性能的影响.
为解决攻击概貌的问题,Mobasher等人[13]提出了基于PLSA模型的推荐算法,通过PLSA模型对用户进行聚类,从而实现对用户的推荐,与其他方法相比,该方法对攻击概貌具有较强的抗攻击能力,而且推荐的精确度较高;Mehta等人[14]提出了基于奇异值分解的推荐算法,该方法通过减弱攻击概貌对推荐的影响来提高系统的抗攻击能力,但该方法对小规模的概貌攻击具有较好的效果,对于大规模的攻击仍是显得力不从心;Sandvig等人[15]提出了基于关联规则的协同过滤算法,虽然该算法具有较强的稳定性,但是降低了推荐的精准度,并且系统推荐的覆盖面也较小.
此外,还有学者在推荐系统中引入了用户间的信任关系,以解决攻击概貌问题.Jamali等人[16]提出了随机游走模型,通过多次随机游走算法,融合返回的多个评分,得到目标项目的预测评分,但是该模型容易受到数据稀疏的影响;Ma等人[17]提出了基于矩阵分解进行推荐的方法,通过对用户或项目特征的学习,得到目标用户的推荐,并且,他们还提出了融合社会信息的推荐方法[18];Jia等人[19]提出了一种基于双重邻居选取策略的协同过滤算法,通过用户的评分信息,计算目标用户与兴趣相似用户的信任度,并以此为选取邻居用户的依据,利用双重邻居选取策略,已完成对目标用户的推荐.虽然该方法具有较强的抗攻击能力,但在用户评分信息的稀疏性较大.
针对上述方法中存在的问题,在现有推荐技术的人群定向算法上,本文提出了一种基于邻居选取策略的人群定向算法.首先通过用户行为和用户特征,动态选择出与种子人群具有较高相似行为的候选人群;然后通过基于邻居选取策略的人群定向算法,从候选人群中选择出潜在的目标人群,以完成人群定向.本文的主要工作体现在3个方面:
1) 提出了一种兴趣指纹生成算法,根据每个用户的兴趣爱好,生成该用户的兴趣指纹.
2) 提出了一种基于用户行为和用户特征的候选人群选择算法,该算法首先以用户行为为依据,动态选择出种子人群的行为相似人群;然后以用户行为和用户特征为依据,从行为相似人群中选择出每个种子用户的邻居,并将选择出的所有邻居作为候选人群.
3) 提出了一种基于邻居选取策略的人群定向算法,通过该算法从候选人群中选择出潜在的目标用户,以完成人群定向.
2 用户相似度
互联网用户可以通过用户行为和用户特征2个方面来描述.用户行为是指用户访问的一系列的媒体(或网站)信息,可以通过该用户访问的网页直接获取;用户特征是指描述用户个人身份的属性或信息,主要包括用户的人口属性和兴趣爱好.其中,人口属性包括性别、年龄、婚姻状况、个人收入、学历、职业和行业7个子属性;兴趣爱好可分为娱乐、财经金融、运动、数码产品、旅游、汽车、文艺、时政、健康保健和军事10个兴趣爱好.为了选取种子用户的邻居,本文采用了用户相似度的方法.因此,本节着重对用户特征获取和相似度2方面进行详细介绍.
2.1 用户特征
与用户行为不同,用户特征并不能直接获取.然而可以通过用户的访问行为进行预测.由于用户特征包含人口属性和兴趣爱好2个子特征,于是,本文采用了不同的方法来进行预测用户的人口属性和兴趣爱好.
2.1.1 人口属性预测
人口属性是用户内在属性的描述.在系统中,能够直接获取用户访问了哪些网站等信息,但获得用户的人口属性往往比较困难.于是,可以通过用户访问的网站去自动预测人口属性.比如以性别为例:经常浏览汽车网、游戏网的用户绝大部分是男性,经常访问娱乐综艺的用户绝大多数用户是女性.此时,性别属性预测问题可以转化为分类问题.本文以性别为例,详细描述人口属性预测的方法.
假设某个用户访问了n个不同的媒体,分别为M1,M2,…,Mn,C1表示为男性用户,C2表示为女性用户,C1(Mi)表示访问了媒体Mi的男性用户计数,C2(Mi)表示访问了媒体Mi的女性用户计数,则该用户的性别分类概率为
(1)
同理,该方法也可扩展应用于获得人口属性的其他子属性.
2.1.2 兴趣爱好分类
与人口属性类似,用户的兴趣爱好并不能直接获取.但是,可以获取到用户浏览的所有页面,而用户经常浏览的页面通常隐含了用户的兴趣,因此,通过对访问的页面进行分类,得到每个用户的兴趣偏好.
网页的分类流程如图1所示,主要包括训练和分类2个阶段:首先通过样本训练贝叶斯分类器,然后使用训练的贝叶斯分类器对访问的页面进行兴趣分类.
1) 训练阶段:①对样本数据进行分词、过滤无用词等预处理操作,形成分词后的训练样本;②通过训练样本训练贝叶斯分类器.
2) 分类阶段:①需要对抓取页面的内容进行预处理操作;②通过贝叶斯分类器对该网页进行兴趣分类,并将网页的兴趣类别作为访问了该网页用户的兴趣爱好.

Fig. 1 Page classification图1 网页的分类流程
2.2 相似度
2.2.1 人口属性的相似度
人口属性主要包括7个子属性,可以分为2类:1)数值型属性,主要包括年龄和个人收入;2)名称型的属性,主要包括性别、婚姻状况、学历、职业和行业.由于属性的类型不同,其属性之间的距离计算也不同.对于数值型属性的相似度计算如下:首先计算2个用户在该属性上的数值绝对差,并将该属性的绝对差值的最小和最大划分为区间[vmin,vmax],然后将这个区间划分为x个等距的子区间,即[vmin,v1],[v1,v2],…,[vx-1,vmax],并且每个子区间依次给定数值型属性的距离为1,2,…,x.此时,如果数值型属性的绝对差值落在第i子区间内,那么在该属性上的距离d=i(i≤x).
例1. 假设年龄的最小值和最大值区间为[vmin,vmax],并将该区间划分为3个子区间,即[vmin,v1],[v1,v2],[v2,vmax],则用户uA和uB在年龄上的差值为|l|=|uA-vB|,其中vA为用户uA的年龄,vB为用户uB的年龄,并且|l|∈[v1,v2],则用户uA和uB在年龄上的距离为2.
针对所有的数值属性a1,a2,…,an,假设用户uA和uB在所有数值属性上的距离为
(2)
其中,dj表示2个用户在属性aj上的距离,若所有的dj都为0,则Dnumber的默认值为1.
对于名称型属性的距离计算,本文采用了方法:假设名称型属性的取值数目为N,则对所有取值按顺序进行人工评级,即所有的评级为r1,r2,…,rN,若2个用户在该属性上的评级分别为ri和rj,则2个用户在该属性上的距离为|ri-rj|.
例2. 以学历为例,学历分为本科以下、本科、硕士和博士,其对应的人工评级为1,2,3,4,若2个用户uA和uB的学历分别为本科和博士,则2个用户在“学历”属性上的距离为2.
针对所有的名称型属性b1,b2,…,bn,假设用户uA和uB在所有名称型属性上的距离为
(3)
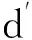
如果2个用户的距离越小,则他们之间的相似度就越大.于是本文中采用了距离的调和均值的倒数作为2个用户的人口属性相似度,即:
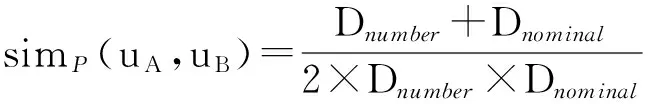
(4)
2.2.2 兴趣相似度
由于每个用户是个独立的个体,并且不同用户的兴趣爱好或许不同.因此,每个用户都会拥有属于自己的兴趣指纹,如果2个用户的兴趣指纹越相似,那么这2个用户的兴趣相似度就越大.本文提出了一种兴趣指纹算法来生成用户的兴趣指纹.
兴趣指纹算法的主要思想是将每个用户的多个兴趣映射到1个K位的指纹中,该算法主要经过4个阶段:
1) 对所有的兴趣进行Hash,得到n个K位的Hash值.
2) 抽取用户的所有兴趣爱好,以及每个兴趣的概率权重.
3) 计算用户的第i(1≤i≤K)位的兴趣数字指纹.首先设置该位的初始累加数为0,依次循环每个散列的第i位,如果该位为1,则累加数加上该兴趣的权重;如果该位为0,则累加数减去该兴趣的权重.最后,如果累加数为正,则第i的兴趣数字指纹为1,否则为0.
4) 对K个数字指纹进行连接,生成用户的兴趣指纹.该算法的具体实现如下.
算法1. 兴趣指纹生成算法.
输入:用户的兴趣概率矩阵P=(pij)、P是m×n矩阵、用户ux的兴趣概率向量Px=(px1,px2,…,pxn)、n个兴趣;
输出: 用户的兴趣指纹F.
①H←∅,F′←∅;
② fori←1 tondo*本文中K的取值为所有兴趣标签的计数*
③ 对于兴趣i,生成1个K位Hashhi;
④H←H∪hi;
⑤ end for
⑥ fori←1 toKdo
⑦sum←0;
⑧ forj←1 tondo
⑨q←hj的第i位;
⑩ ifq=1 do














兴趣指纹反映了用户的兴趣爱好,因此,2个用户之间的兴趣相似度可以通过他们的兴趣指纹来计算.假设用户uA和uB的兴趣指纹分别为FA=fA1fA2…fAK和FB=fB1fB2…fBK,则2个用户的兴趣相似度计算为
(5)
如果2个用户兴趣指纹相同,那么兴趣相似度为1;如果兴趣指纹完全不同,兴趣相似度为0.
2.2.3 用户特征相似度
用户特征是用户的内在属性,并且用户特征包含了人口属性和兴趣2个方面,因此用户特征相似度包含人口属性的相似度和兴趣的相似度2部分.由于人口属性和用户兴趣是从不同方面来描述用户特征,属于不同的维度空间,用户之间的人口属性相似度和兴趣相似度不同,都会影响用户特征的相似度.
例3. 假设有3个用户uA,uB,uC,uA与uB的人口属性相似度和兴趣相似度分别为0.8和0.2,而uA与uC的人口属性相似度和兴趣相似度分别为0.6和0.4.若采用算术平均值的方法计算用户特征相似度,则uA与uB的用户特征相似度为0.5,uA与uC的用户特征相似度为0.5,此时,uB和uC都与uA具有相同的用户特征相似度;若采用调和均值的方法计算用户特征相似度,则uA与uB的用户特征相似度为0.32,uA与uC的用户特征相似度为0.48,此时,uA与uC的用户特征相似度高于uA与uB.
对于上述实例,若从人口属性和用户兴趣2个角度去考虑,uA与uC的用户特征相似度应高于uA与uB.基于此,本文没有采用算术平均的方法来计算用户特征相似度,而是采用了调和平均的方法来计算2个用户的特征相似度,即:

(6)
其中,simP(uA,uB)是2个用户的人口属性相似度,simI(uA,uB)是2个用户的兴趣相似度.
2.2.4 用户行为相似度
用户行为相似度是从用户访问的媒体角度来衡量2个用户之间的相似度,该相似度是从动态角度考虑2个用户的相似程度,这是由于用户行为是随着时间不断发生变化的,并且用户访问的媒体反映了用户的行为轨迹,因此,在人群定向分析算法中,用户访问行为也是必须考虑的因素.于是,本文通过用户访问的不同媒体来计算2个用户之间的行为相似度.
假设有m个用户组成的集合U={u1,u2,…,um}和n个媒体组成的集合M={M1,M2,…,Mn},则用户-媒体访问矩阵可以用m×n矩阵C来表示,Cij(1≤i≤m,1≤j≤n)表示用户ui访问媒体Mj的计数,并且用户uA和用户uB的共同访问的媒体集合为T,则2个用户的行为相似度为
(7)

2.2.5 用户相似度
每个用户不仅具有内在的用户特征,而且还包含动态的用户行为.于是在本文中,用户相似度是从用户特征和用户行为2个角度来衡量用户间的相似程度,由于用户特征和用户行为是用户的2个不同的维度,并且算术平均数方法容易受到极端数值的影响,计算出的平均数的代表性较差(参见例3),于是,采用了调和平均方法来计算用户uA和用户uB的相似度,即:

(8)
其中,simF(uA,uB)是2个用户的特征相似度,simB(uA,uB)是2个用户的行为相似度.
3 基于邻居选取策略的人群定向算法
人群定向是通过种子人群的行为特征,找出潜在的目标人群.由于推荐系统的开放性,导致基于推荐算法的人群定向的抗攻击能力差.为此,本文提出了一种基于邻居选取策略的人群定向算法,该算法首先根据用户行为找出种子人群的行为相似人群;然后以用户行为和用户特征为依据,找出每个种子用户的邻居,并将所有邻居作为种子人群的候选人群;最后通过基于邻居选取策略的人群定向算法,从候选人群中选择出相似度较高的用户作为潜在的目标人群.在人群定向算法中,为了选择出种子人群的行为相似人群和候选人群,本文提出了一种基于用户行为和用户特征的候选人群选取算法.
3.1 基于用户行为和用户特征的候选人群选取算法
由于人群定向是找出与种子人群具有相同行为的目标人群,因此,该目标人群应是与种子人群具有较高行为相似度的用户集合.然而仅仅通过用户行为相似寻找候选人群,具有一定的片面性,这是因为人群定向系统容易受到用户概貌攻击的影响,当系统遇到大规模的用户攻击时,人群定向的精度明显降低.本文提出了一种基于用户行为和用户特征的候选人群选取算法.该算法通过用户行为,寻找出较高的行为相似人群,根据用户特征和用户行为为选择邻居的依据,从行为相似人群中,找出每个种子用户的邻居集合,并将所有的种子用户的邻居集合作为人群定向的候选人群.这样从局部角度增强系统的抗攻击能力,有助于提高人群定向的质量.
候选人群选取算法的目标主要是以用户行为和用户特征为依据,找出相似度较高的种子用户的邻居.该算法主要包括3个阶段:1)选取种子人群的中心用户.在该阶段,为了减少每个用户与种子人群的比较次数,本文从种子人群中选择出中心用户,并计算中心用户的媒体向量.2)寻找种子人群的行为相似人群.计算每个用户与中心用户的行为相似度,并计算所有行为相似度的平均值作为行为相似度的阈值,选出行为相似度不低于阈值的那些用户作为种子人群的行为相似人群.3)选取出种子人群的候选人群.计算行为相似人群中每个用户与种子用户的相似度,并根据相似度的大小,选择出每个种子用户的前k个邻居,并将选择出的所有邻居集合作为种子人群的候选人群.
算法2. 基于用户行为和用户特征的候选人群选取算法.
输出: 候选人群Pcand.
①Sbeh←∅,uc←u,Mc←0,Pcand←∅;*u为中心用户,Mc为中心用户u的访问的媒体向量*
② fori←1 tondo
③num←0,sum←0;
④ forj←1 tordo
⑤ ifCji≠0 do
⑥sum←sum+Cji;
⑦num←num+1;
⑧ end if
⑩Mc(i)←sumnum;









3.2 基于邻居选取策略的人群定向算法
由于候选人群Pcand中的用户是针对每个种子用户而选择出的邻居集合,但并不是每个用户都与所有的种子用户具有较高的相似性,因此,本文从种子人群的整体角度出发,提出了基于邻居选取策略的人群定向算法(audience targeting based on neighbor choosing strategy, ATNCS),该算法以用户特征和用户行为为选取依据,计算候选人群Pcand中的每个用户与种子人群的相似度,动态选择相似度较高的用户作为潜在的目标人群.
人群定向算法的思想主要是从候选人群中选择出潜在的目标人群,该算法主要包括3个阶段:1)计算候选人群中的每个用户与种子用户的相似度,根据该用户与所有种子用户的相似度,计算相似度的平均值,并将其作为该用户与种子人群的相似度;2)根据所有用户与种子人群的相似度,计算种子人群的相似度阈值;3)从候选人群中选择出用户与种子人群相似度不低于阈值的用户集合,并将这些用户作为潜在的目标人群.
算法3. 基于邻居选取策略的人群定向算法.
输入: 种子用户集合S、候选人群Pcand、种子用户-媒体访问矩阵、种子用户-兴趣概率矩阵、候选人群-媒体访问矩阵、候选人群-兴趣概率矩阵、种子用户及候选人群的人口属性;
输出: 目标人群集合At.
①At←∅,sum←0,Q←∅;
② for eachui∈Pcanddo
③simi←0,sumSimi←0;
④ for eachuj∈Sdo
⑤ 计算sim(ui,uj);
⑥sumSimi←sumSimi+sim(ui,uj);
⑦ end for
⑧simi←sumSimi|S|;*simi为用户ui与种子人群的相似度*
⑨sum←sum+simi;
⑩Q←Q∪{〈simi,ui〉};





4 实验验证与分析
4.1 数据集
为了验证算法的有效性,本文使用了1家互联网广告公司的在线广告用户作为实验数据,该实验数据包括4组数据:组1(G1)包含1 882 146个用户、2 912个媒体和14 415 499个网页;组2(G2)包含1 854 321个用户、2 736个媒体和13 959 907个网页;组3(G3)包含2 561 384个用户、2 987个媒体和18 746 897个网页;组4(G4)包含2 118 465个用户、2 896个媒体和16 081 431个网页.此外,除上述数据集之外,还包含人口属性的分类样本数据集和页面兴趣分类的样本数据集.
在实验时,我们随机选择10%的用户作为种子人群,剩下90%的用户作为测试数据.
4.2 对比算法
为了验证人群定向算法的性能,本文选择作为对比算法的2种算法:
1) 基于用户协同过滤的人群定向(audience targeting based on user collaborative filtering, ATUCF)算法.该算法主要通过用户访问的媒体,找出相似用户集合进行人群定向.
2) 不确定近邻的协同过滤的人群定向(audience targeting based on uncertain neighbors’ collaborative filtering, ATUNCF)算法[20].基于用户访问的媒体,计算用户之间的相似性,并自适应地选择每个种子的近邻对象作为潜在的目标人群.
4.3 人群定向的效果对比
为了验证新方法在人群定向中的效果,本文在4.1节中4组数据集上,对ATNCS,ATUCF,ATUNCF进行了对比实验.此外,还进行了仅采用用户行为的人群定向算法(ATNCS-B)和仅采用用户特征的人群定向算法(ATNCS-F)的实验,具体实验结果如表1所示.
从表1中可以看出,在ATUCF,ATUNCF,ATNCS方法中,ATUNCF方法在准确率Precision上比ATUCF方法平均提高了3%~5%,而ATNCS方法比ATUNCF方法平均提高了1%~3%;在召回率Recall上,ATUNCF方法比ATUCF方法平均提高了将近3%,而ATNCS方法比ATUNCF方法平均提高了1%~2%.显然,ATUCF方法的推荐精度最低,其次是ATUNCF方法,ATNCS的推荐性能是最优的.这是因为在人群定向时,ATUCF方法仅仅考虑了用户的访问媒体信息,并且没有考虑用户特征信息,即在人群定向时,仅仅通过用户之间是否存在共同的访问媒体,如果共同访问媒体的越多,2个用户就越相似.而ATUNCF方法则不同,该方法在寻找种子用户的邻域时,不仅考虑用户之间的相似性,而且还考虑了媒体之间的相似性,因此ATUNCF的方法的性能优于ATUCF方法.ATNCS方法与ATUNCF方法类似,也是通过寻找种子用户邻域来进行人群定向,但是在寻找用户的邻域时,ATUNCF方法只考虑了用户访问的媒体信息,并没有考虑用户特征信息,而ATNCS方法在邻居选取策略中考虑了用户行为和用户特征为信息.即在寻找种子用户的邻居时,首先通过用户之间的行为相似度动态选择出种子人群的行为相似人群;然后通过用户相似度选择出种子人群的候选人群;最后通过用户相似度的方法从候选人群中动态选择出潜在的目标人群.并且在选择候选人群和目标人群时,均使用了用户相似度方法,该相似度方法不仅考虑行为相似度,而且还考虑了用户特征相似度.因此ATNCS方法的性能优于ATUNCF方法.

Table 1 Comparison of Different Methods表1 不同方法的性能比较
此外,在ATNCS-B,ATNCS-F,ATNCS方法中,在准确率Precision上,ATNCS方法比ATNCS-B方法平均提高了5%~6%,比ATNCS-F方法平均提高了3%~5%;在召回率Recall上,ATNCS方法比ATNCS-B方法平均提高了3%~4%,比ATNCS-F方法平均提高了2%~3%.显然,ATNCS方法人群定向的性能是最优的.这是因为ATNCS-B只考虑用户行为信息,忽视了用户的特征信息,即在选择种子用户的邻居时只考虑了用户行为相似度,并没有考虑用户特征相似度;ATNCS-F方法则与之相反,只考虑了用户特征信息,并没考虑用户的行为信息,即在计算用户的相似度时,只使用了用户特征相似度,并没有考虑用户的行为相似度;而新方法在选择种子用户的邻居时,用户相似度方法中不仅使用了用户的行为相似度,而且还考虑了用户特征相似度.因此,这2种方法的人群定向效果低于新方法.从另一方面,也说明了用户特征和用户行为邻居选取策略中具有重要的作用,不能被忽视.
4.4 抗攻击能力比较
为了评价ATNCS方法的抗攻击能力,在原有的4组数据集中,分别注入了不同规模的用户概貌攻击数据.实验中注入的用户攻击规模有:2%,5%,7%,10%.并且还进行了ATUTC方法和ATUNCF方法进的实验,3种不同方法在4组数据集中的平均结果分别如图2所示:
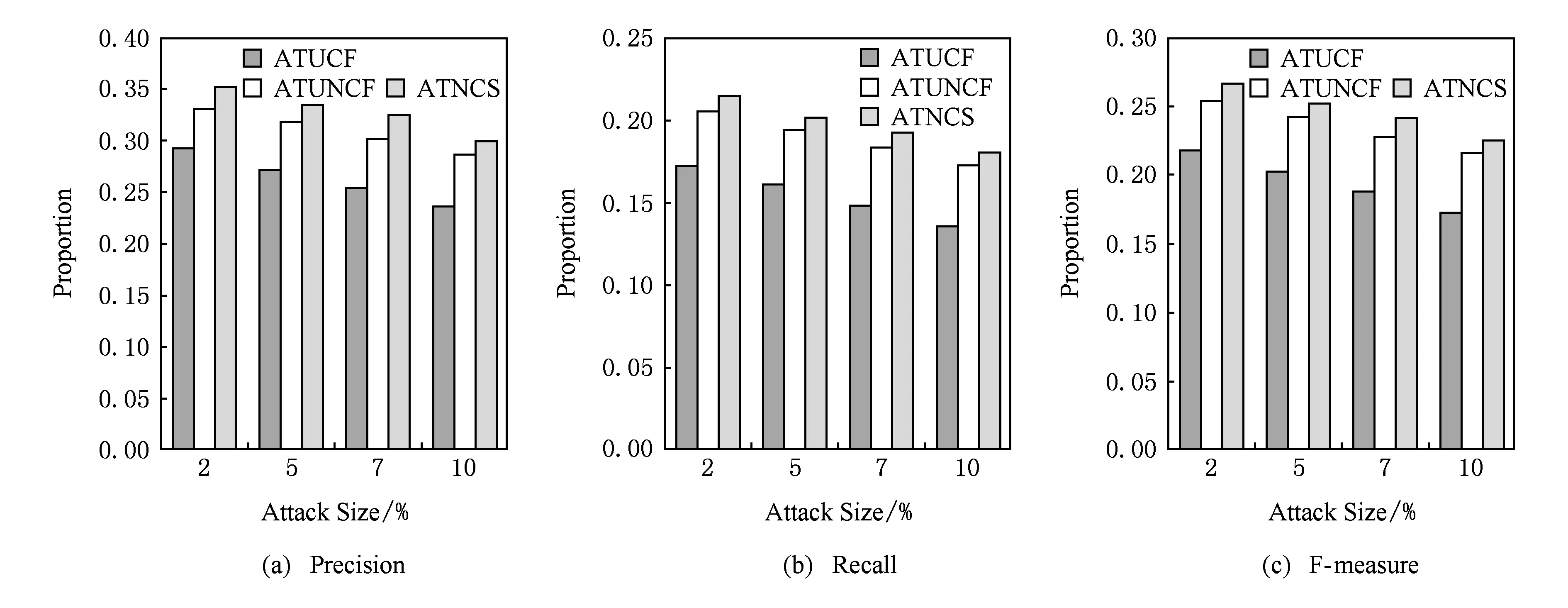
Fig. 2 Comparison of anti-attack capability图2 抗攻击能力的比较
从图2中可以看出,无论是在准确率Precision上,还是召回率Recall和F-measure上,随着用户攻击规模的增大,人群定向的效果逐渐降低.从而可知,攻击的用户越多,人群定向的性能受到的影响就越大.除此之外,从图2中还可以看出,ATUCF下降幅度较大,说明ATUCF方法受到的影响较明显,这是由于ATUCF方法在人群定向中只考虑较少的用户行为信息,并没有考虑用户特征信息,从而导致该方法具有较弱的抗攻击能力.而ATUNCF方法和ATNCS方法下降幅度较小,ATUNCF方法和ATNCS方法受到的影响较小.这是因为ATUNCF方法不仅通过访问的媒体来计算用户之间的相似度,而且能够通过相似度的动态阈值来自适应地选择用户的近邻.而ATNCS方法具有较高的抗攻击能力,主要有2个原因:1)在选择种子用户的邻居时,使用了用户相似度方法,该方法不仅考虑了用户特征相似度,而且还考虑了行为相似度.2)ATNCS方法经历了3个阶段,即选取种子人群的行为相似人群、选取种子人群的候选人群和选取潜在目标人群,在每个阶段中都会过滤一些用户集合,进而会过滤掉一些攻击用户,这样从局部角度增强了用户的抗攻击能力.因此,随着攻击规模的增大,ATNCS方法的效果仍优于ATUNCF方法.与其他2种方法相比,ATNCS方法具有较强的抗攻击能力.
4.5 调和均值方法的影响
在人群定向算法中,计算用户特征相似度和用户相似度时都采用了调和均值的方法.而不同的均值计算方法都会影响最终的人群定向效果.为了验证调和均值方法对人群定向的影响,本文在4组数据集上进行了简单调和均值法(harmonic mean,HM)与算术平均法(arithmetic mean, AM)的对比实验,具体的实验结果如图3所示:
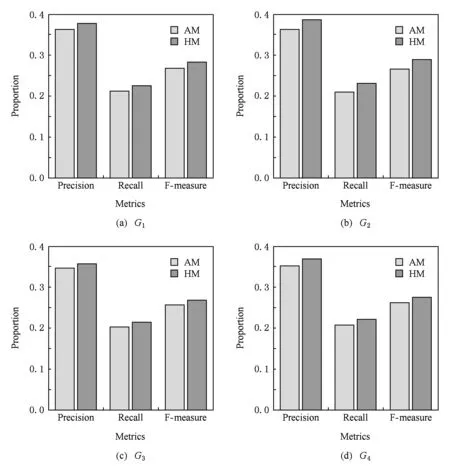
Fig. 3 Comparison of different parameters图3 不同参数的比较
从图3中可以看出,无论是在准确率Precision上,还是召回率Recall和F-measure上,AM方法都没有HM方法的人群定向的效果较好.在4组数据集中,2种方法在第2组数据集上的影响最大,HM方法的准确率Precision比AM方法高2.4%,在召回率Recall上,HM方法比AM方法高2.2%;而在第3组数据集上的影响最小,在准确率Precision上,HM方法比AM方法高0.9%,HM方法的召回率Recall比AM方法高1.1%.由此可知,不同的均值方法都会影响最终的人群定向效果.
4.6 参数的影响
在基于用户行为和用户特征的候选人群选取算法中设置了参数k,参数k的不同影响着人群定向的效果.为了验证参数k的影响,本文在4组数据集上进行了不同参数k的实验,具体实验结果如图4所示.
从图4中可以发现,k的取值对人群定向的结果具有显著影响.随着k的取值的不同,无论哪组数据集,ATNCS方法的3个评价指标Precision,Recall,F-measure也都发生了显著变化.当参数k从0开始增加时,3个评价指标的值会逐渐升高;当参数k=6时,3个评价指标达到了最大值,此时,人群定向的效果是最佳的;当参数k>6后,3个评价指标便会随着k的增加而逐渐减小.由此可知,参数k的取值影响着人群定向的质量.于是在人群定向中,选择合适的参数k是不容忽视的.

Fig. 4 Comparison of different parameters图4 不同参数的比较
5 结论与进一步工作
本文以用户行为和用户特征为邻居选取的重要依据,提出了基于邻居选取策略的人群定向算法.首先从行为相似人群中找出种子的候选人群,并通过基于邻居选取策略的人群定向算法找出潜在的目标人群.实验结果表明:用户行为和用户特征不仅在人群定向中起了重要作用,而且在增强人群定向系统的抗攻击能力方面也十分重要.
此外,该算法虽然取得了一定效果,但是忽略了系统中的时间属性,如用户访问的媒体和用户特征都是具有一定时间属性的.在未来的工作,将进一步研究如何将时间属性与用户媒体、用户特征结合在一起,以进一步改善人群定向的效果.
[1]Xu Hailing, Wu Xiao, Li Xiaodong, et al. Comparison study of internet recommendation system[J]. Journal of Software, 2009, 20(2): 350-362 (in Chinese)(许海玲, 吴潇, 李晓东, 等. 互联网推荐系统比较研究[J]. 软件学报, 2009, 20(2): 350-362)
[2]Huang Zhenhua, Zhang Jiawen, Tian Chunqi, et al. Survey on learning-to-rank based recommendation algorithms[J]. Journal of Software, 2016, 27(3): 691-713 (in Chinese)(黄震华, 张佳雯, 田春岐, 等. 基于排序学习的推荐算法研究综述[J]. 软件学报, 2016, 27(3): 691-713)
[3]Guo Lei, Ma Jun, Chen Zhumin, et al. Incorporating item relations for social recommendation[J]. Chinese Journal of Computers, 2014, 37(1): 219-228 (in Chinese)(郭磊, 马军, 陈竹敏, 等. 一种结合推荐对象间关联关系的社会化推荐算法[J]. 计算机学报, 2014, 37(1): 219-228)
[4]Rong Huigui, Huo Shengxu, Hu Chunhua, et al. User similarity-based collaborative filtering recommendation algorithm[J]. Journal of Communications, 2014, 35(2): 16-24 (in Chinese)(荣辉桂, 火生旭, 胡春华, 等. 基于用户相似度的协同过滤推荐算法[J]. 通信学报, 2014, 35(2): 16-24)
[5]Popescul A, Ungar L H, Pennock D M, et al. Probabilistic models for unified collaborative and content-based recommen-dation in sparse-data environments[C]Proc of the 7th Conf on Uncertainty in Artificial Intelligence. New York: ACM, 2001: 437-444
[6]Arora G, Kumar A, Devre G S, et al. Movie recommendation system based on users’ similarity[J]. International Journal of Computer Science and Mobile Computing, 2014, 3(4): 765-770
[7]Ekstrand M D, Riedl J T, Konstan J A. Collaborative filtering recommender systems[J]. Foundations and Trends in Human-Computer Interaction, 2011, 4(2): 81-173
[8]Linden G, Smith B, York J. Amazon. com recommen-dations: Item-to-item collaborative filtering[J]. IEEE Internet Computing, 2003, 7(1): 76-80
[9]Cai Yi, Leung H, Li Qing, et al. Tyco: Towards typicality-based collaborative filtering recommendation[C]Proc of the 22nd IEEE Int Conf on Tools with Artificial Intelligence. Piscataway, NJ: IEEE, 2010: 97-104
[10]Chen Kehan, Han Panpan, Wu Jian. User cluster based social network recommendation[J]. Chinese Journal of Computers, 2013, 36(2): 349-359 (in Chinese)(陈克寒, 韩盼盼, 吴健. 基于用户聚类的异构社交网络推荐算法[J]. 计算机学报, 2013, 36(2): 349-359)
[11]Wang Tingting, Liu Hongyan, He Jun, et al. Predicting new user’s behavior in online dating systems[G]LNAI 7121: Proc of the 7th Int Conf on Advanced Data Mining and Applications. Berlin: Springer, 2011: 266-277
[12]Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model[C]Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2008: 426-434
[13]Mobasher B, Burke R, Sandvig J J. Model-based collaborative filtering as a defense against profile injection attacks[C]Proc of the 21st AAAI Conf on Artificial Intelligence(AAAI’06). Menlo Park, CA: AAAI Press, 2006: 1388-1393
[14]Mehta B, Hofmann T, Nejdl W. Robust collaborative filtering[C]Proc of the 1st ACM Int Conf on Recommender Systems. New York: ACM, 2007: 49-56
[15]Sandvig J J, Mobasher B, Burke R. Robustness of collaborative recommendation based on association rule mining[C]Proc of the 1st ACM Int Conf on Recommender Systems. New York: ACM, 2007: 105-112
[16]Jamali M, Ester M. TrustWalker: A random walk model for combining trust-based and item-based recommendation[C]
[17]Ma H, King I, Lyu M R. Learning to recommend with social trust ensemble[C]Proc of the 32nd ACM SIGIR Int Conf on Research and Development in Information Retrieval. New York: ACM, 2009: 203-210
[18]Ma H, Zhou T C, Lyu M R, et al. Improving recommender systems by incorporating social contextual information[J]. ACM Trans on Information Systems, 2011, 29(2): 219-230
[19]Jia Dongyan, Zhang Fuzhi. A collaborative filtering recommendation algorithm based on double neighbor choosing strategy[J]. Journal of Computer Research and Development, 2013, 50(5): 1076-1084 (in Chinese)(贾冬艳, 张付志. 基于双重邻居选取策略的协同过滤推荐算法[J]. 计算机研究与发展, 2013, 50(5): 1076-1084)
[20]Huang Chuangguang, Yin Jian, Wang Jing, et al. Uncertain neighbors’ collaborative filtering recommendation algorithm[J]. Chinese Journal of Computers, 2010, 33(8): 1369-1377 (in Chinese)(黄创光, 印鉴, 汪静, 等. 不确定近邻的协同过滤推荐算法[J]. 计算机学报, 2010, 33(8): 1369-1377)

Zhou Meng, born in 1986. PhD candidate. Student member of CCF. His main research interests include data mining and natural language processing.

Zhu Fuxi, born in 1957. Professor and PhD supervisor. His main research interests include artificial intelligence, knowledge mining and distributed computing.
An Audience Targeting Algorithm Based on Neighbor Choosing Strategy
Zhou Meng1and Zhu Fuxi1,2
1(SchoolofComputerScience,WuhanUniversity,Wuhan430072)2(SchoolofComputerScienceandTechnology,HankouUniversity,Wuhan430212)
Audience targeting which is designed to discover the prospective target users by analyzing the these seed users’ behavior is an important technology in the online advertising recommendation systems, and the existing audience targeting technologies mostly rely on collaborative filtering algorithms. However, the traditional collaborative filtering algorithms have the disadvantages of lower precision and weaker anti-attack capability. In order to solve the problems, an audience targeting algorithm based on neighbor choosing strategy is proposed. Firstly, the users which have the similar behavior with the seed audiences are chosen dynamically by means of the user behavior similarity. Then, on the basis of the users’ feature and behavior, the neighbors of each seed user are chosen from the behavior similar audiences by the user similarity, and all the neighbors are considered to be the candidate audiences. Finally, the prospective audiences are chosen from the candidate users by the audience targeting algorithm based on neighbor choosing strategy, so as to complete the task of audience targeting. Compared with the existing methods, the experimental results on real-world advertisement datasets show that the audience targeting algorithm not only improves the precision, but enhances the anti-attack capability as well.
seed audiences; behavior similar audiences; neighbor choosing strategy; user similarity; audience targeting
2016-05-20;
2016-11-04
国家自然科学基金项目(61272277) This work was supported by the National Natural Science Foundation of China (61272277).
朱福喜(fxzhu@whu.edu.cn)
TP391; TP18
猜你喜欢
当代陕西(2020年23期)2021-01-07
幼儿教育·教育教学版(2020年8期)2020-12-23
幼儿教育·教育教学版(2020年8期)2020-12-23
恋爱婚姻家庭(2020年27期)2020-10-09
大学生(2020年9期)2020-09-12
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
制造技术与机床(2017年3期)2017-06-23
中国教师(2015年17期)2015-09-10
浙江人大(2014年6期)2014-03-20
