
基于联合聚类和C-RA组合相似度的协同过滤算法
2017-08-12 15:45赵文涛王春春成亚飞
计算机应用与软件 2017年7期
赵文涛 王春春 成亚飞
(河南理工大学计算机科学与技术学院 河南 焦作 454000)
基于联合聚类和C-RA组合相似度的协同过滤算法
赵文涛 王春春 成亚飞
(河南理工大学计算机科学与技术学院 河南 焦作 454000)
针对传统协同过滤算法由于数据稀疏和冷启动而造成的推荐精度下降的问题,提出一种基于联合聚类和C-RA组合相似度的协同过滤算法。首先,通过联合聚类对原始评分矩阵进行用户和物品两个维度的聚类;其次,利用联合聚类结果填充原始评分矩阵;最后,利用C-RA组合相似度计算用户相似度并进行推荐。实验结果表明,该方法有效地提高了推荐结果的精确度,缓解了数据稀疏和冷启动问题。
协同过滤 冷启动 数据稀疏性 联合聚类 C-RA
0 引 言
推荐系统作为一种软件工具和技术方法,通过为用户过滤无关信息,以满足用户的个性化需求,同时解决了因“信息过载”造成的资源浪费问题。推荐系统现已在新闻、视频、社交网络、电子商务等领域广泛应用。推荐系统可分为六种不同的推荐方法[1]:基于内容的方法、协同过滤方法、基于人口统计学的方法、基于知识的方法、基于社区的方法和混合推荐系统。其中,协同过滤推荐技术通过用户对商品的评分或者其他行为模式为用户提供个性化的推荐,而且不需要了解用户或者商品的大量信息,因此其被广泛应用。
协同过滤技术主要包括基于领域的模型和隐语义模型,其中基于领域的模型由于其简单、直观、高效的特点而十分流行。然而协同过滤技术在实际运用中存在数据稀疏和冷启动等问题,因此造成推荐误差较大。针对上述问题,国内外的研究者对协同过滤算法进行了相关改进。Mobasher B[2]等提出基于用户的事务和浏览量进行聚类,从而找出用户共同的特征并有效地提高推荐效果。吴杰等[3]利用奇异值分解将具有相似兴趣的用户分成不同的簇,在簇内提取用户评价过的物品的特征向量,同时运用了神经网络进行训练,并最终对较高满意度的物品进行推荐。
本文的贡献主要包括三个方面:1) 在原始评分矩阵中对用户维度和物品维度进行联合聚类,利用联合聚类预测填充原始评分矩阵,不仅充分利用了用户与物品之间的联系,同时也有效地改善了数据稀疏性和冷启动问题。2) 提出一种新的相似度计算方法C-RA,使RA相似性和修正余弦相似性共同作用于用户之间的相似度计算上,提高了用户相似度的准确性,同时弥补了以上两种相似性各自的缺陷。3)通过联合聚类对原始矩阵的填充缓解了原始矩阵数据的稀疏性,然后计算用户的相似度,找出目标用户的K近邻来进行推荐。
1 相关研究
1.1 协同过滤算法
为了建立推荐信息,推荐系统通常需要把两种有本质区别的实体(即用户和物品)联系起来,为方便比较这两种实体产生了两种主要的协同过滤技术:基于邻域的算法和隐语义模型[4]。其中,基于邻域的算法重点关注用户之间的关系或者物品之间的关系。因此,基于邻域的算法又可分为基于用户的协同过滤算法和基于物品的协同过滤算法[5]。
基于用户的协同过滤算法主要包括两个步骤:
1) 通过用户之间的相似度计算出和目标用户u相似的用户集合。计算用户之间的相似度方法主要包括三种:皮尔逊相关相似性、余弦相似性、修正余弦相似性。其中修正余弦相似性具有实现简单、计算速度快以及考虑到用户评分尺度的问题等优点。修正余弦相似性由式(1)所示:
(1)
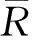
2) 找到和目标用户u相似的用户集合中用户所感兴趣的,但目标用户u没有评价过的物品集合,选择相似性最高的前N个物品,推荐给目标用户u。推荐过程由式(2)所示:
(2)
式(2)中Ru,i表示用户u对未评分物品i的预测评分。Su为用户u的最近邻集合。
1.2 联合聚类
聚类算法是数据挖掘中重要的算法之一,也是无监督学习中的典型案例。聚类的基本思想:通过对象之间的相似度,利用分类的方法将对象分成不同的簇或者子集,使同一个子集中的成员对象都有相似的一些属性。联合聚类作为聚类的重要方法之一,在基因表达、协同过滤以及数据文本分析等领域被广泛使用。
联合聚类的基本原理是在数据矩阵中通过在行聚类和列聚类两个维度上进行循环迭代直至收敛,发现隐藏在数据空间中的簇集。Cheng等[6]首次在基因表达上提出并使用联合聚类,提出同时在基因和条件两维度上进行聚类,并以最小均方残差作为评价标准。韦素云等[7]提出基于联合聚类平滑的协同过滤学算法,首先使用联合聚类对原始矩阵中用户和物品两个维度进行评分预测,然后从用户聚类、物品聚类和联合聚类这三方面对空缺项进行平滑填充,最终结合基于物品的协同过滤算法进行推荐。
2 基于联合聚类和组合相似度的协同过滤算法
图1为本文算法的流程图。本文的算法主要分为两个步骤:首先,利用联合聚类对原始数据矩阵进行填充。然后,在填充后的矩阵中利用C-RA计算用户相似度对未评分项进行预测。通过联合聚类填充后的矩阵在预测过程中缓解了由于数据稀疏性而造成的推荐质量下降等问题。
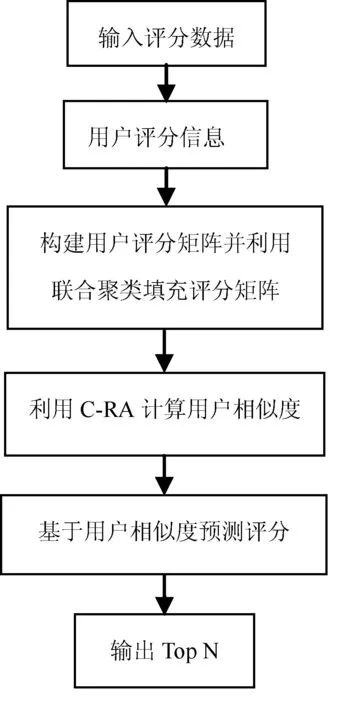
图1 算法流程图
2.1 联合聚类填充
传统的聚类算法中,数据矩阵中的某一行或者某一列只能属于一个类别,然而在实际的推荐过程中,无论是用户还是物品,同属于且只属于一个类别的可能性很小。而联合聚类能同时考虑行聚类和列聚类,与传统的只是基于用户的聚类或者基于物品的聚类相比,推荐结果更加精确。为了降低原始矩阵的维度,本文采用矩阵降秩逼近方法。在使用联合聚类的基础上,利用矩阵加权降秩逼近方法预测原始矩阵中的未评分项[8]。
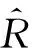
(3)
(4)
(5)
(1≤u≤m)
(6)
(1≤i≤n)
(7)
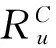
2.2 C-RA组合相似度
在计算用户之间的相似性时,为了使用户间相似度更加的稳定和准确,本文引入节点相似性指标。节点相似性指标广泛应用在图聚类、链路预测、个性化推荐等方面。一个好的指标,一定要有相应的稳定性。Liu等[9]经过大量的实验发现相似性指标的稳定性有很大差异,而RA相似性指标的稳定性很好。
本文将RA相似性引入并进行扩展:
(8)
式(8)中,RAuv表示RA相似性方法中用户u和用户v的相似度。Γ(u)表示用户u评分的物品集合,Γ(v)表示用户v评分的物品集合,f表示用户u和用户v共同评分的物品。K(f)表示对f物品进行评分的用户个数。
由于利用RA相似性计算出的相似度值并非在[0,1]之间,并且RA相似性只考虑到用户之间共同评分的物品,而忽略了用户对物品的评分。同时,修正余弦相似性仅通过用户之间共同评分的物品集合计算相似度。因此,本文提出一种新的组合相似度衡量指标Su,v,通过利用同趋化函数(如式(9)所示)对RAu,v和Cu,v同时进行处理,使得Su,v正确反映RA相似性和修正余弦相似性在不同的作用力上的综合结果,使组合相似度充分利用RA相似性和修正余弦相似性的优势,更加准确地综合衡量用户间的相似度。
(9)
(10)
式(10)中Su,v表示用户u和v的C-RA相似度。RAu,v表示RA相似性,Cu,v表示修正的余弦相似性。
2.3 基于联合聚类和C-RA组合相似度的推荐
通过联合聚类将原始评分矩阵进行填充,然后利用C-RA相似度计算用户之间的相似度,最后利用式(2)预测未评分项的值。本文对于新用户或者新物品没有可供参考的评分的情况,通过联合聚类各类中的用户和物品均值,预测新用户和新物品的评分,缓解了冷启动问题,最终进行Top N推荐。
算法:
输入:用户-物品评分矩阵R、评分标准标识矩阵W、用户聚类数目h、物品聚类数目j、目标用户u′、待评分物品i′、Top N个数。
输出:目标用户u对待评分物品i的预测评分、Top N推荐集。
过程:
Step1 随机初始化用户-物品联合聚类(μ,λ);
Step2 计算联合聚类中各类的均值RCOC、用户聚类中各类的均值RCC、物品聚类中各类的均值RDC;
Step3 利用式(6)更新用户聚类,利用式(7)更新物品聚类;

Step6 根据式(10)计算用户之间的相似度;
Step7 找到用户u′的最近邻居集Nu′;
Step8 通过最近邻居集和式(2)计算出目标用户u′对物品i的评分,产生Top N推荐。
3 实验分析与结果
3.1 数据集
本文所采用的MovieLens数据集源于美国明尼苏达大学的GroupLens项目组创办的MovieLens推荐系统。本文使用的MovieLens数据集包含943位用户对1 682部电影的评分信息。评分总数为100 000。评分标准为1~5分,某用户对某部电影所打的分值越高,表明该用户对该部电影越感兴趣。利用数据稀疏度公式可计算出该数据集的稀疏度。
(11)
式中S表示数据稀疏度,m表示用户数,n表示物品数,N为总的评分数。计算得出MovieLens数据集的稀疏度为:93.69%。
3.2 度量标准
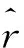
(12)
平均绝对误差(MAE)也常被用来度量预测评分的准确性。当RMSE和MAE的值越小,说明预测的准确度越高。
(13)
3.3 实验结果
本文采用五折交叉验证的方法。将数据集随机分成五份,每次选取其中的4份作为训练集,剩余的一份作为测试集。通过五次实验后,计算五次实验结果的平均值作为最终的实验结果。在交叉验证之前,需要确定联合聚类中用户聚类的个数和物品聚类的个数,聚类个数的选取对算法最终的性能有直接的影响。
如图2所示,当最近邻居的值分别取10、30、50,将用户和物品的聚类个数同时设为5、6、7、8、9、10时MAE值的变化趋势。随着用户与物品聚类个数的增加,MAE值也在不断变化,由于联合聚类算法对于聚类结果中每一类元素的个数存在随机性。因此,如果选择较大的聚类个数或者较高的最近邻居数,都可能会出现最近邻的个数比类内元素总个数还要多的情况。经实验证明:当用户和物品的聚类个数为5时,MAE值达到最优,并且在合理范围之内。

图2 用户和物品聚类数目的确定
将本文算法与传统的协同过滤算法、文献[10]的算法作对比。本文中的用户和物品聚类个数为5,将最近邻居个数从10递增至60,每次增加10,实验结果如图3所示。
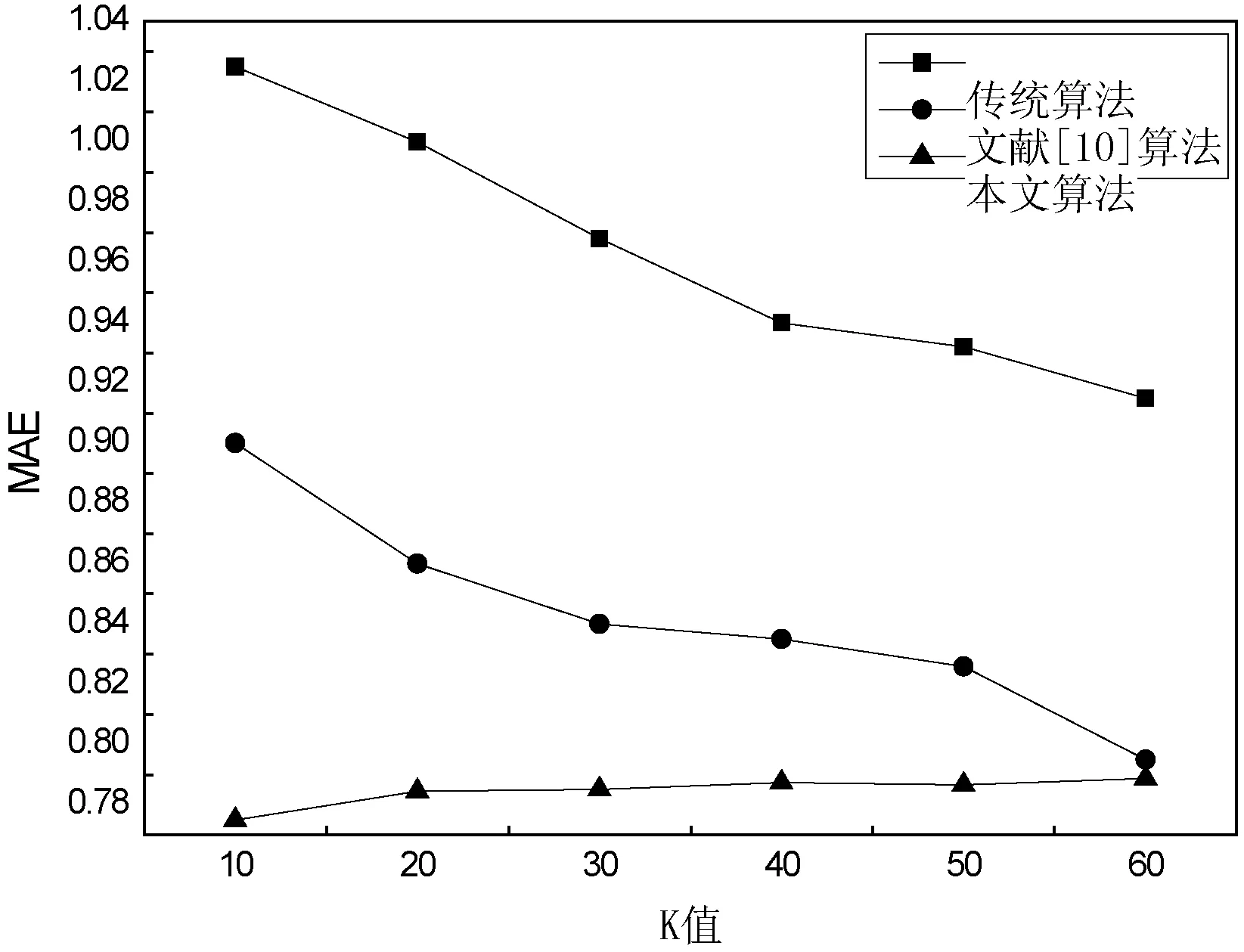
图3 不同算法的MAE值的比较
从图3可以看出,本文算法与传统的协同过滤算法和文献[10]中的算法在最优情况下对比,MAE值明显较小,说明本文的算法推荐效果更好。随着最近邻个数的增加,在传统算法和文献[10]算法中,MAE值越来越小,而在本文的算法中,通过C-RA相似度能够更加准确衡量用户之间的相似性,使确定的最近邻更加相似。所以,刚开始呈现出较大幅度的增长。随着最近邻个数的增长,邻居之间相似度变化幅度更大,导致算法推荐性能的提高逐渐变缓。随着最近邻个数的增加,MAE值逐渐增长,且MAE值均比前两种算法小。
如图4所示,当用户和物品的聚类个数同时为5时,本文算法的RMSE值在最近邻个数为10的时候取得最小值,表示更加接近真实值,具有较好的推荐结果。而在最近邻个数为20的时候取得最大值,使预测值和真实值之间出现更大的偏差。产生这种现象的原因可能是联合聚类的随机性导致最近邻个数超过了某个类中元素个数或者由于实验中较大误差样本值的影响导致RMSE值比较大。
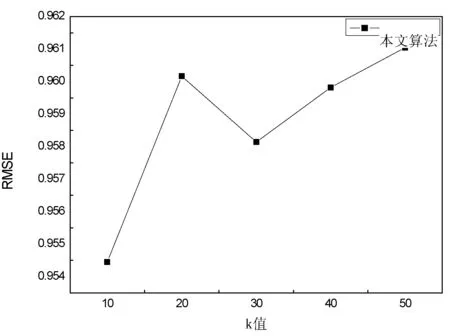
图4 本文算法的RMSE值
4 结 语
本文提出一种基于联合聚类和C-RA组合相似度的协同过滤算法。通过联合聚类对原始评分矩阵进行填充,有效地解决了数据稀疏和冷启动问题。并提出一种新的相似度计算方法,即C-RA组合相似度更加精确地计算用户之间的相似度,同时也提高了推荐质量。本文中联合聚类的个数是通过大量实验验证所得,如何快速精确地划分聚类将是下一步的研究工作重点。
[1] Burke R. Hybrid Web Recommender Systems[C]//The Adaptive Web: Methods and Strategies of Web Personalization, Lecture Notes in Computer Science,2007:377-408.
[2] Mobasher B, Dai H, Luo T, et al. Discovery of Aggregate Usage Profiles for Web Personalization[C]//Proceedings of the WebKDD Workshop at the ACM SIGKDD,Boston,August 2000.
[3] 吴杰,冯锋.综合用户偏好和优先新品推荐的协同过滤算法[J].计算机应用与软件,2014,31(10):285-287.
[4] 弗朗西斯科·里奇. 推荐系统:技术、评估及高效算法[M]. 机械工业出版社, 2015.
[5] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:44-45.
[6] Cheng Y,Church G M. Biclustering of expression data[C]//Proc of the 8th Int Conf on Intelligent Systems for Molecular Biology.Menlo Park,CA:AAAI,2000:93-103.
[7] 韦素云,静静,业宁.基于联合聚类平滑的协同过滤算法[J].计算机研究与发展,2013(50):163-169.
[8] George T, Merugu S. A scalable collaborative filtering framework based on co-clustering[C]//IEEE International Conference on Data Mining. IEEE Xplore,2005:625-628.
[9] Liu J G, Lei H, Xue P, et al. Stability of similarity measurements for bipartite networks[J].Scientific Reports, 2015, 6:18653.
[10] 喻金平,张勇,廖列法,等.基于混合蛙跳联合聚类的协同过滤算法[J].微电子学与计算机,2016,1(33):65-71.
COLLABORATIVE FILTERING ALGORITHM BASED ON CO-CLUSTERING AND C-RA COMBINED SIMILARITY
Zhao Wentao Wang Chunchun Cheng Yafei
(CollegeofComputerScienceandTechnology,HenanPolytechnicUniversity,Jiaozuo454000,Henan,China)
In order to overcome the sparse data and cold start of traditional collaborative filtering recommendation algorithm, a collaborative filtering algorithm based on co-clustering and C-RA combined similarity is proposed. First, co-clustering algorithm is used to simultaneously obtain user and item neighborhoods. Secondly, the result of co-clustering is used on rating matrix. Finally, C-RA combined similarity is used to calculate the similarity of users and recommend. Experimental results show that the proposed method not only effectively improves the accuracy of the recommended results, but also solves problems of user cold start and data sparsity.
Collaborative filtering Cold start Data sparsity Co-clustering C-RA
2016-08-14。河南省科技攻关项目(142402210435);河南省高等学校矿山信息化重点学科开放基金项目(ky2012-02)。赵文涛,教授,主研领域:信息系统,大数据,数据挖掘。王春春,硕士生。成亚飞,硕士生。
TP393
A
10.3969/j.issn.1000-386x.2017.07.047
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
河北画报(2020年8期)2020-10-27
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
小学生学习指导(低年级)(2018年9期)2018-09-26
舰船电子对抗(2017年6期)2018-01-11
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
