
基于子空间联合模型的视觉跟踪
2017-08-12 15:45杨国亮朱松伟
计算机应用与软件 2017年7期
杨国亮 唐 俊 朱松伟 王 建
(江西理工大学电气工程与自动化学院 江西 赣州 341000)
基于子空间联合模型的视觉跟踪
杨国亮 唐 俊 朱松伟 王 建
(江西理工大学电气工程与自动化学院 江西 赣州 341000)
目标跟踪是计算机视觉的重要组成部分,其鲁棒性一直受到目标遮挡,光照变化,目标姿态变化等因素的制约。针对这个问题,提出了基于子空间联合模型的视觉跟踪算法。算法为了克服遮挡对目标跟踪的影响,采用局部动态稀疏表示进行遮挡检测,根据遮挡检测结果来修正增量子空间误差。此外,在稀疏子空间基础上计算目标模板和候选模板的相似性。在粒子滤波框架下,联合候选目标增量误差和相似性实现目标跟踪。通过在多个具有挑战性的视频序列上进行实验,表明该算法具有较好的鲁棒性。
视觉跟踪 增量子空间 粒子滤波 联合模型 局部动态稀疏表示
0 引 言
视觉跟踪一直是计算机视觉领域的研究热点,它在智能控制、车辆导航、导弹制导、人机交互等领域具有大量的应用。文献[1-2]对视觉跟踪做了简要回顾。虽然现在有大量经典算法[3-5]被提出,但这个领域仍有很多问题有待解决,这个研究领域仍然充满挑战。现阶段视觉跟踪面临的技术难题是光照变化,目标遮挡,视角变化以及快速运动等环境因素对跟踪的影响。
现阶段,视觉跟踪主要分为两大类方法:鉴别式方法和生成式方法。鉴别式方法将跟踪问题转化成了一个二分类问题,其思想是通过分类器寻找与背景区分性最大的区域,从而实现目标和背景的分离。而对于生成式方法[3-8],其主要思想是在图像局部区域内进行搜索,从中寻找与目标外观最相似的区域。本文采用生成式方法实现视觉跟踪。
最近研究表明,稀疏表示模型[9]在人脸识别领域展现很强的鲁棒性。基于此,很多基于稀疏表示模型的视觉跟踪算法[6-7,10-11]被呈现。Mei等[4-5]采用全局的模板作为目标表观模型,通过L1最小化模型实现目标跟踪。在全局稀疏表示中,全局模板被当成字典,为了缓解目标遮挡对目标表观的影响,大量琐粹模板被使用。虽然对遮挡情况具有较好的鲁棒性,但是琐粹模板增加了稀疏表示的计算量。Zhong等[6]提出了稀疏合作表观模型,在这个模型中,稀疏鉴别分类器(SDC)和稀疏生成模型(SGM)通过合作的方式确定跟踪结果。通过全局模板,SDC从背景中分离跟踪目标;而对于SGM,局部块的空间信息被用来测量候选目标和目标模板相似度。基于PCA的子空间模型对目标表观变化有很强的鲁棒性。根据传统PCA,Ross等[3]提出了基于增量学习的视觉跟踪算法,其对表观变化具有很强的鲁棒性。但是,IVT算法是全局的,其对目标存在遮挡的情况鲁棒性不强。
针对视觉跟踪存在的难点问题以及增量子空间和稀疏子空间的现有优势,本文提出了基于子空间联合模型的视觉跟踪算法。首先,算法利用增量子空间模型求得候选目标的增量误差,并采用局部动态稀疏表示模型检测候选目标的遮挡情况来减少目标遮挡对增量子空间模型的影响。此外,为了更加准确选择候选目标,算法在局部动态稀疏表示的基础上计算目标模板局部块和候选模板局部块之间相似性。最后,在粒子滤波框架下,利用联合模型实现目标跟踪。通过在多个具有挑战性的视频序列上进行实验,算法对光照变化,目标遮挡,视角变化,目标姿态变化以及运动模糊有较好的鲁棒性。
1 粒子滤波
基于粒子滤波的视觉跟踪方法可以分为预测和更新两个部分。假设在视频序列的第t帧,y1:t-1={y1,y2,…,yt-1}表示第一帧到第t-1帧的目标观测,xt表示目标的真实状态,则粒子滤波的预测过程如式(1)所示:
p(xt|y1:t-1)=∫p(xt|xt-1)p(xt-1|y1:t-1)dxt-1
(1)
其中,p(xt|x1:t-1)为状态转移模型。状态转移模型p(xt|x1:t-1)描述了目标状态和连续帧之间的关系。本文利用仿射变换建立目标状态与连续两帧图像之间的转移模型,模型如式(2)所示:
p(xt|xt-1)=N(xt,xt-1,Σ)
(2)
其中Σ为对角矩阵,其对角元素表示相应元素的方差。在t时刻,当观测状态yt可用时,则根据式(3)执行更新过程:
(3)
其中,p(yt|xt)是状态xt的观测似然。在得到所有候选目标的观测似然后,利用最大后验概率准则估计跟踪目标的最优状态,如式(4)所示:
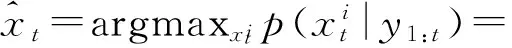
(4)
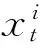
2 增量子空间学习和局部动态稀疏表示
为了充分利用增量子空间和稀疏表示模型的各自优势,本文提出了二者的联合模型。首先根据增量子空间模型求得候选目标的增量误差,因为增量子空间没有遮挡检测机制,所以采用局部动态稀疏表示实现遮挡检测,用检测结果修正增量误差。此外,在局部动态稀疏表示基础上计算候选目标和目标表观的相似性。在以理论的基础上利用联合模型实现了本文的视觉跟踪算法。
2.1 增量子空间学习
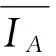
通过以上分析,t时刻的候选目标yt的增量学习误差ePCA可以通过式(5)求得:
(5)
其中,q为特征向量系数。
在跟踪过程中,需要实时更新训练集,这样就降低了原训练集的贡献度,因此引入遗忘因子f,f∈[0,1],则原有效样本数变为f×n。通过这种更新方式,增量子空间获取了新的表观变化,同时又保证了初始表观在子空间中的重要地位。
2.2 局部动态稀疏表示
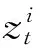
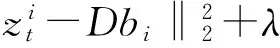
(6)
其中,bi是局部块的稀疏系数,λ是稀疏表示模型的权值参数,字典D∈RG×J通过M个局部块k均值聚类生成(J为聚类中心数量),η为相邻帧跟踪目标之间相关性的控制参数,Ht是相邻帧之间的状态转移矩阵。本文局部块的生成过程和局部块稀疏系数柱状如图1所示。
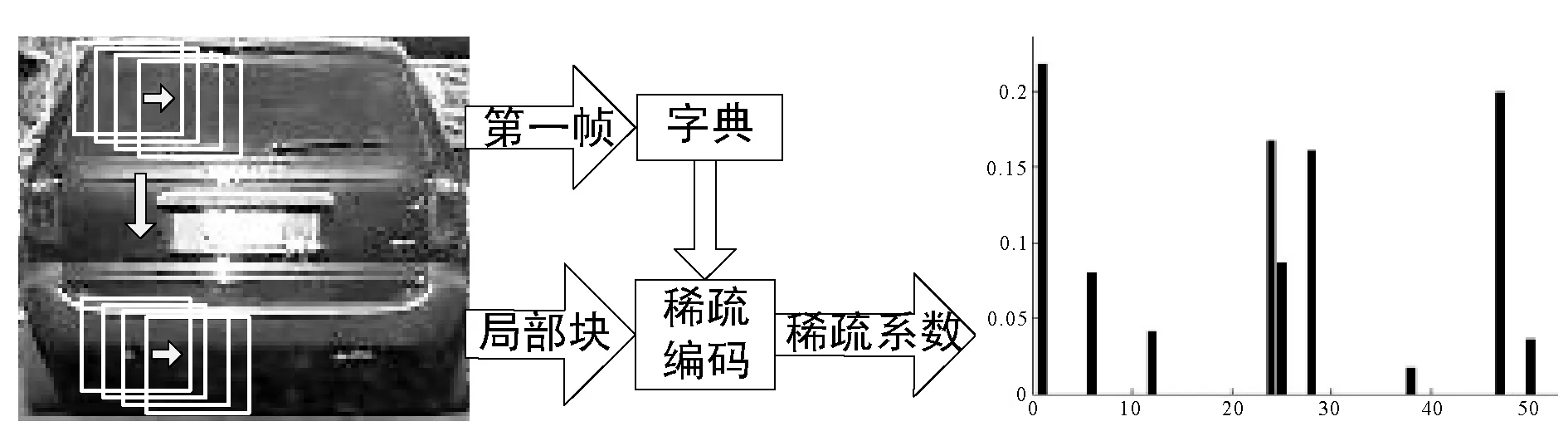
图1 局部块和稀疏系数柱状图
通过局部动态稀疏表示模型求解候选目标局部块的稀疏系数bi∈RJ×1,将所有稀疏系数连接起来形成一个向量,如式(7)所示:
(7)
其中,β∈R(J×M)×1表示一个候选目标的稀疏系数向量。
2.3 遮挡检测
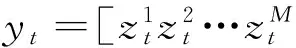

(8)
在稀疏编码中,候选目标的局部块能够由字典稀疏表示。如图1所示,局部块的表示系数是稀疏的。然而,遮挡块不属于目标模板,其用字典表示时将会有很大的稀疏误差。因此局部块的遮挡情况可以通过稀疏误差确定。定义遮挡指示器如式(9)所示:
(9)
其中,ξ是自定义阈值,用来确定局部块是否被遮挡。定义候选目标的遮挡检测矩阵为O∈Rm×n,则根据遮挡指示器可以求得:
(10)
其中,p和q是第j个局部块在候选目标中的坐标向量。Λ和Ω分别表示1矩阵和0矩阵。利用式(10)对所有局部块进行遮挡检测,对检测结果进行阈值处理可以求得遮挡检测矩阵O。从而利用遮挡检测矩阵修正增量学习误差。
在利用遮挡检测矩阵对增量误差进行修正后,可以得到修正误差,如式(11)所示:
Ej=ej⊕O
(11)
其中,ej为第j候选目标的增量误差,Ej为对应修正误差,⊕表示元素之间的点乘。则可以求得所有候选目标的修正误差为:
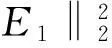
对于局部动态稀疏表示模型,当候选目标存在遮挡时,根据遮挡指示器生成加权系数向量:
φ=β⊕g
(12)
其中,g为遮挡指示器。
通过以上的遮挡检测方式,本文不仅考虑了两个模型的各自特点,也充分利用了局部块的空间信息,增强了算法对遮挡的鲁棒性。
2.4 联合模型
对于局部动态稀疏表示模型,本文参考文献[6]选择向量求交来计算候选目标和目标模板相似度,公式如下所示:
(13)
其中,φc和ω分别表示第c个候选目标和目标模板的系数向量。所有候选目标和目标模板的相似度可以表示为L=[L1,L2,…,LN]T。
对于增量子空间模型和局部动态稀疏表示模型,其相似性根据各自模型特点分开计算。但在最后的决策环节采用联合模型确定最优候选目标。因为增量学习模型采用增量误差衡量候选目标,其值应该越小越好;而局部动态稀疏表示模型采用目标模板和候选目标的相似度衡量候选目标,其值应该越大越好。所以本文定义联合模型如式(14)所示:
(14)
其中,α是控制高斯核函数的参数,Γ为归一下常量。
3 模板更新
在跟踪过程中,目标的表观是经常改变的,所以实时更新目标模板显得至关重要。对于增量子空间模型,当目标不存在遮挡时,算法选择间隔5帧更新一次训练集;当目标存在遮挡时,算法利用遮挡检测结果修正增量学习误差,同时跟踪结果不会更新到训练集。而对于局部动态稀疏表示模型,字典D在此后的跟踪结果中不会更新,但为了利用新的表观信息,本文选择更新模板系数向量的方式来跟踪目标,更新过程如式(15)所示:
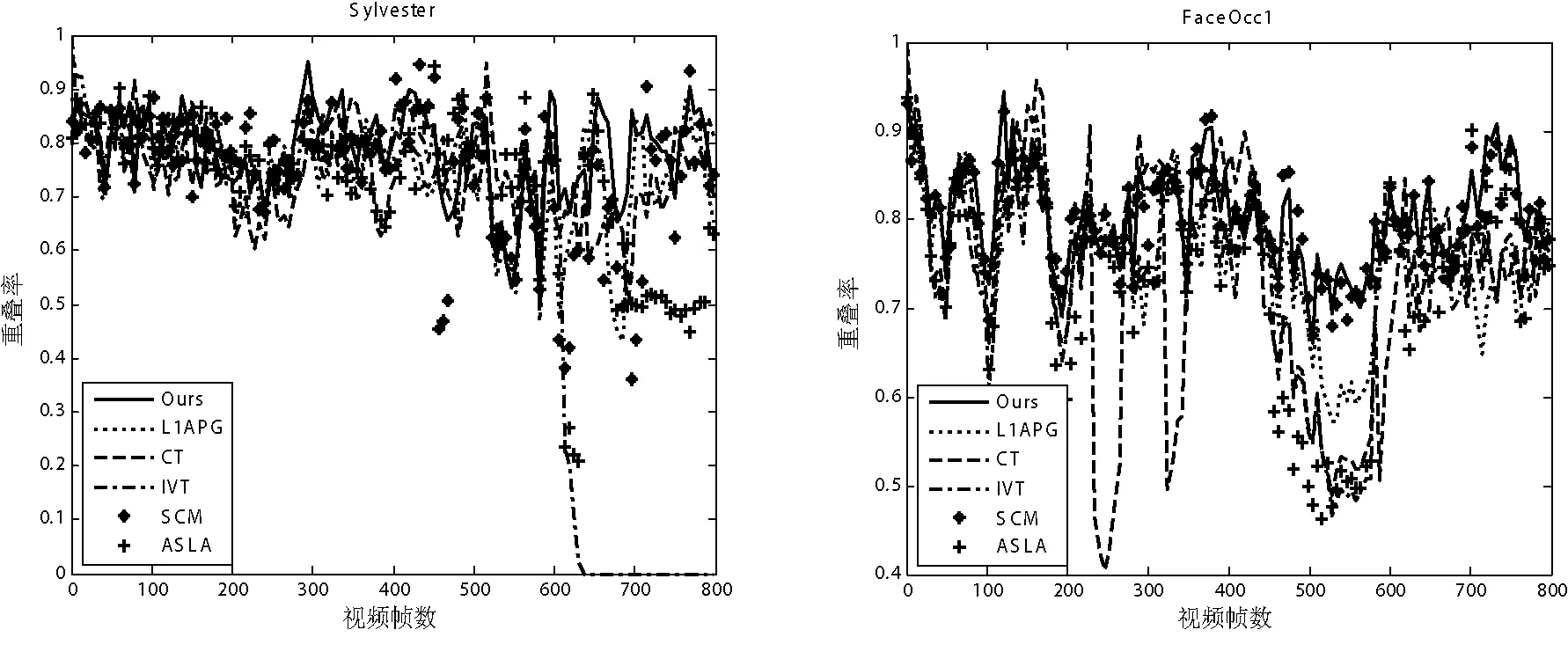
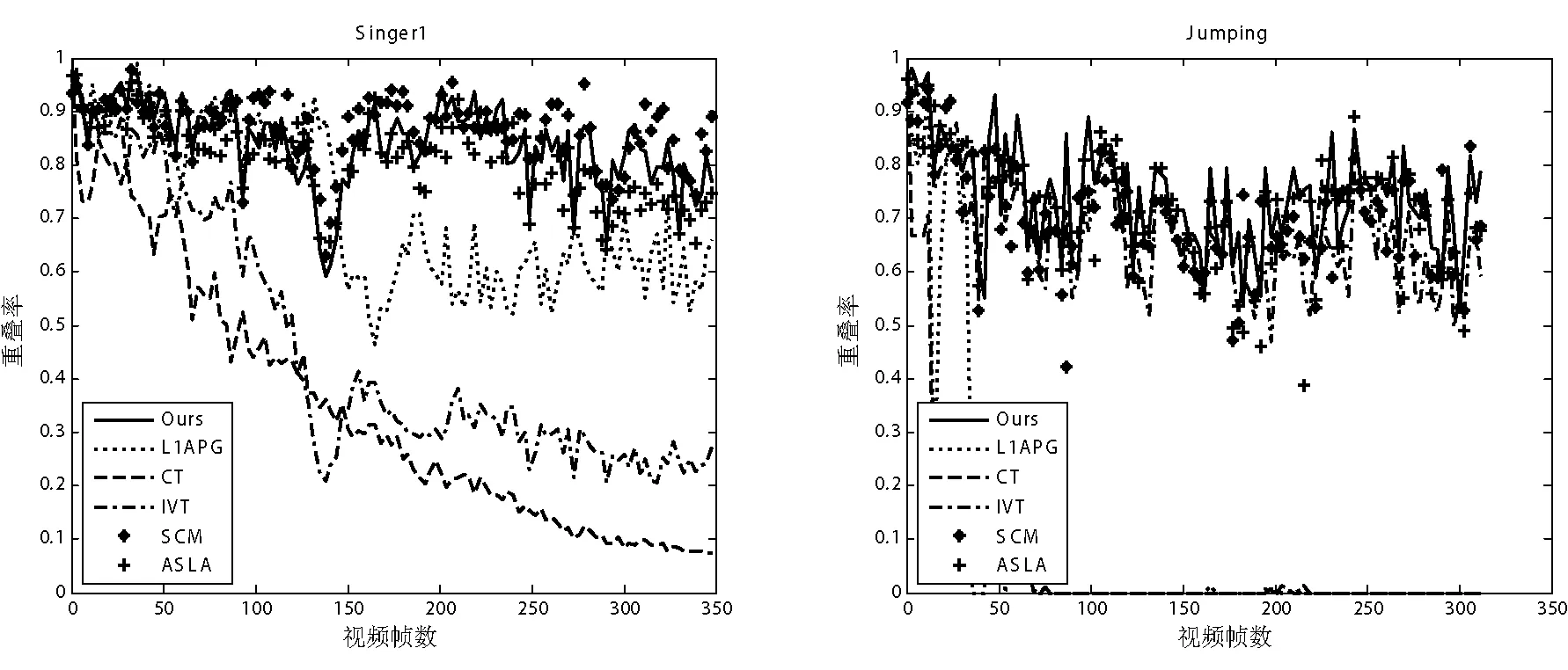
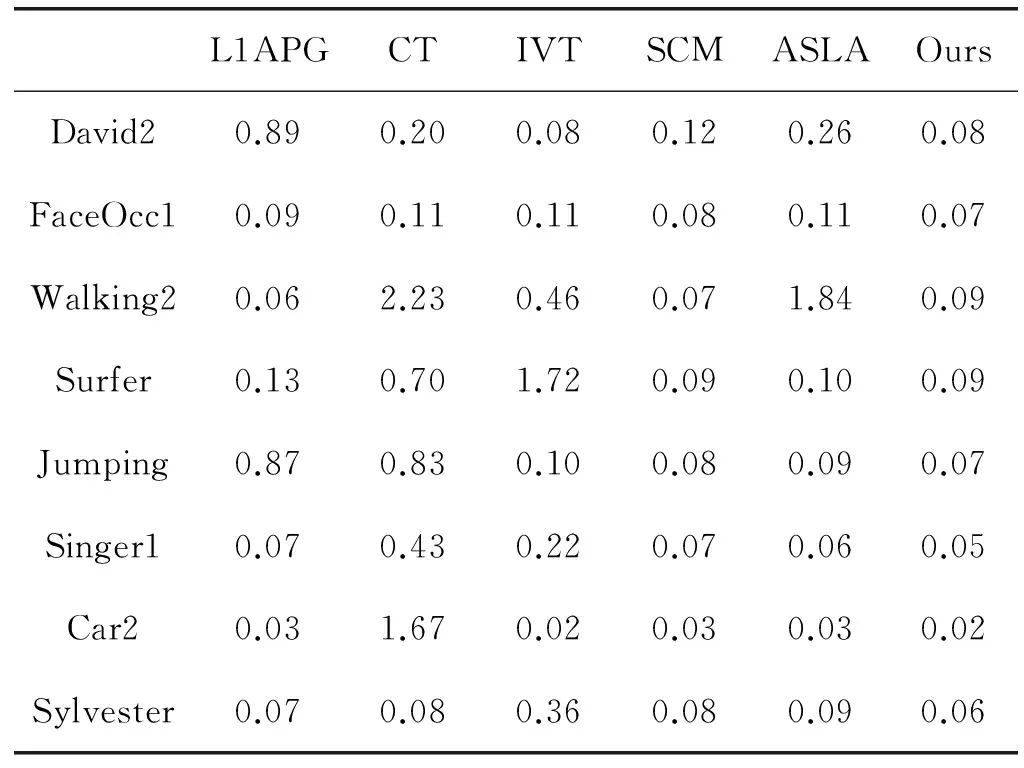
ωn=μωf+(1-μ)ωlifGn (15) 其中,ωn是新的系数向量,ωf是根据第一帧图像生成的系数向量,而ωl是上一次存储的系数向量,μ为平衡系数,Gn表示跟踪结果的遮挡情况,G0为自定义阈值。选择这种模板更新方式一方面保证了第一个模板的重要性,另一方面也充分考虑了新的表观变化,增强了算法的鲁棒性。 本文算法以粒子滤波为整体框架,通过将增量误差和稀疏相似度作为候选目标的观测似然,在特定的遮挡检测和模板更新方式下实现了目标跟踪。算法流程如算法1所示。 算法1 基于子空间联合模型的视觉跟踪 输入:手工标定目标x1,字典D,前五帧通过模板匹配进行跟踪 1.For t=6 ;t<= FrameNum ;t++ 8.end for 本文算法实验平台为Intel Duo e7500双核处理器,主频为2.93 GHz,内存为2 GB,Windows XP操作系统,软件环境为Matlab R2010b。实验之前,需要对参数进行基本的设置,其中包括:样本所投影的局部块大小为32×32,训练集更新间隔为5,遗忘因子设为0.95。为了评估我们算法的性能,从标准测试库[13]选择了“Car2”,“Singer1”,“FaceOcc1”,“Walking2”,“Surfer”,“Jumping”,“David2”,“Sylvester”8个测试序列进行实验,测试序列总共包括4 390张视频帧图像,同时8个测试序列分别涵盖光照变化,严重遮挡,运动模糊,姿态变化,尺度变化等挑战。并与IVT跟踪[3]、L1APG跟踪[5]、CT跟踪[8]、SCM跟踪[6]、ASLA跟踪[7]五个经典算法进行比较。为了确保实验的合理性,所有初始位置都根据目标真实位置确定。 4.1 定性比较 这部分,在各种场景下将我们的算法和著名算法作对比,因为标准测试序列帧数过多,不可能在跟踪结果中全部展示,所以选择关键位置作结果展示,结果如下: 光照变化 “Car2”序列显示一辆小车在剧烈光照变化下行驶,其中包括从下面通过一座桥,受阴影的影响很大。而在“Singer1”序列中,跟踪除了受到演唱会现场强烈光照影响,还受到歌手自身姿态和尺度变化的影响。实验结果显示,“Car2”序列中CT跟踪跟丢目标,L1APG跟踪精度不足,其他四个算法都能准确跟踪目标。而对于“Singer1”序列,在图像序列第120帧到第325帧之间存在剧烈的强光照射,这对IVT,L1APG和CT算法都有一定影响,三个算法都存在一定的跟踪误差。本文算法能够准确跟踪目标。表明本文算法对阴影和强光照射具有较好的鲁棒性。 严重遮挡 大面积遮挡对于目标跟踪很常见,它在算法性能评估中占有重要的地位。因此,本文选择了2个存在遮挡的序列进行实验。结果表明,在“FaceOcc1”序列中,六个算法都能正确跟踪目标,但CT和IVT存在精度不足的缺点,如图2(c)所示。而对于“Walking2”序列,因为存在大面积遮挡和很大尺度变化,IVT、CT以及ASLA跟踪失败,如图2(d)所示。通过在2个遮挡视频序列上进行实验,表明本文算法对遮挡情况具有较好的鲁棒性。 图2 测试序列跟踪结果1 运动模糊 为了验证算法对运动模糊的跟踪性能,本文选择“Surfer”和“Jumping”视频序列进行实验。对于“Surfer”序列,其主要的挑战是目标快速运动和目标姿态变化,实验表明SCM和本文算法展现了相当的跟踪精度,另外三个跟踪算法跟踪失败。而对于“Jumping”序列,其不仅存在运动模糊,还存在背景杂斑,结果显示CT和L1APG算法跟踪失败。通过在两个运动模糊视频序列上进行实验,结果表明本文算法对运动模糊和快速运动的目标具有较好的跟踪精度。 姿态变化 “David2”序列存剧烈姿态变化,如图3(c)所示。在此图像序列上进行实验,结果表明本文算法对本图像序列有较好的鲁棒性。为了进一步验证本文算法对姿态变化的跟踪性能,选择“Sylvester”视频序列做进一步性能分析。实验表明,本文算法能正确跟踪目标,其他算法跟踪精度不足。 由以上实验可知,本文算法在光照变化,姿态变化,严重遮挡,运动模糊,尺度变化等各种复杂场景下,均能有效跟踪目标,并且跟踪窗口可以随着跟踪目标自适应尺度变化和姿态变化。 图3 测试序列跟踪结果2 4.2 定量分析 由标准测试库[13]可以得到目标的真实状态。所以为了进一步对本文算法性能进行评估,利用目标真实边界框和跟踪结果边界框的重叠率进行定量分析。假设目标的边界框为RT,准确的边界框为RG,则跟踪结果的重叠率为S=|RT∩RG|/|RT∪RG|,其中∩和∪分别表示两个区域的交集和并集,|·|表示区域内像素点的个数。由于篇幅所限,本文选择4个测试序列绘制重叠率曲线如图4所示,其横坐标为视频序列的序号,单位为帧,纵坐标为目标真实边界框和跟踪结果边界框的重叠率。 图4 重叠率曲线 此外,进一步利用跟踪结果与真实状态之间的相对位置误差对本文算法作进一步的性能评估。其中,相对位置误差e=ξ/d,ξ为跟踪结果的中心位置与真实状态的中心位置的偏移量,d为真实状态的目标矩形对角线长度。6个跟踪算法对应8个测试序列的平均相对位置误差如表1所示,其中最好的两个算法平均相对位置误差采用加粗方式表示。 表1 平均相对位置误差 针对单目标跟踪易受环境因素的影响,提出了基于子空间联合模型的视觉跟踪算法。算法利用增量子空间模型求解候选目标的增量误差。为了克服环境因素对目标跟踪的影响,采用局部动态稀疏表示进行遮挡检测,根据候选目标的遮挡情况来修正增量学习误差。因为局部动态稀疏表示也能够求得候选目标和目标模板的相似度,所以结合修正的增量误差和局部动态稀疏表示求得的相似度共同决定候选目标。在上述理论的基础上,以粒子滤波为框架实现了基于子空间联合模型的视觉跟踪算法。在多个具有挑战性的视频序列上进行实验,并与多个现有的跟踪算法作对比,实验结果表明本文算法具有较好的鲁棒性。 [1] Yilmaz A, Javed O, Shah M. Object tracking:A survey[J]. Acm Computing Surveys,2006,38(4):13. [2] Smeulders A W, Chu D M, Cucchiara R, et al. Visual Tracking: An Experimental Survey[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,36(7):1442-1468. [3] Jing L. Incremental Learning for Robust Visual Tracking[J]. International Journal of Computer Vision, 2008,77(1-3):125-141. [4] Mei X, Ling H, Wu Y, et al. Minimum Error Bounded Efficient L1 Tracker with Occlusion Detection (PREPRINT)[C]//The 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, Colorado Springs, CO, USA, 20-25 June 2011:1257-1264. [5] Bao C. Real time robust L1 tracker using accelerated proximal gradient approach[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2012:1830-1837. [6] Zhong W, Lu H, Yang M H. Robust object tracking via sparse collaborative appearance model[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 2014,23(5):2356-68. [7] Jia X. Visual tracking via adaptive structural local sparse appearance model[C]//IEEE Conference on Computer Vision & Pattern Recognition,2012:1822-1829. [8] Zhang K, Zhang L, Yang M H. Real-Time Compressive Tracking[C]//European Conference on Computer Vision. Springer-Verlag,2012:864-877. [9] Jie C, Zhang Y. Sparse Representation for Face Recognition by Discriminative Low-Rank Matrix Recovery[J].Journal of Visual Communication & Image Representation, 2014,25(5):763-773. [10] Chen F, Wang Q, Wang S, et al. Object tracking via appearance modeling and sparse representation[J].Image & Vision Computing,2011,29(11):787-796. [11] Wang D, Lu H, Yang M H. Online object tracking with sparse prototypes[J].IEEE Transactions on Image Processing, 2013, 22(1):314-25. [12] Ji Z, Wang W. Object tracking based on local dynamic sparse model[J].Journal of Visual Communication & Image Representation, 2015,28:44-52. [13] Wu Y, Lim J, Yang M H. Online Object Tracking: A Benchmark[C]//IEEE Conference on Computer Vision & Pattern Recognition,2013:2411-2418. VISUAL TRACKING BASED ON SUBSPACE COLLABORATIVE MODEL Yang Guoliang Tang Jun Zhu Songwei Wang Jian (SchoolofElectricalEngineeringandAutomation,JiangxiUniversityofScienceandTechnology,Ganzhou341000,Jiangxi,China) Target tracking is an important part of computer vision, and its robustness is always restricted to target occlusion, illumination variation and target pose change and so on. To this end, this paper proposes a visual tracking algorithm based on subspace collaborative model. In order to overcome the influence of occlusion on target tracking, this algorithm rectifies incremental subspace error by result of occlusion detection using local dynamic sparse representation. Besides, the similarity between target template and candidate template is computed based on local dynamic sparse representation. In the framework of particle filter, this algorithm is achieved based on combining incremental error with similarity. The experimental results on several sequences show that this algorithm has better performance of tracking. Visual tracking Incremental subspace Particle filter Collaborative model Local dynamic sparse representation 2016-08-11。国家自然科学基金项目(51365017,61305019);江西省科技厅青年科学基金项目(20132bab211032)。杨国亮,教授,主研领域:模式识别与图像处理,智能控制。唐俊,硕士生。朱松伟,硕士生。王建,硕士生。 TP391.41 A 10.3969/j.issn.1000-386x.2017.07.029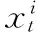
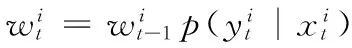
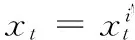
4 实验及结果分析


5 结 语
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
中华书画家(2021年12期)2022-01-06
当代水产(2021年8期)2021-11-04
科技研究·理论版(2021年22期)2021-04-18
散文诗(2020年1期)2020-07-20
农业机械学报(2020年2期)2020-03-09
妇女生活(2019年1期)2019-01-17
东方艺术·国画(2016年3期)2017-02-08
电脑知识与技术(2016年28期)2016-12-21
