
改进加权Slope one协同过滤推荐算法研究*
2017-08-09 01:34王潘潘
传感器与微系统 2017年7期
王潘潘, 钱 谦, 王 锋
(云南省计算机技术应用重点实验室 昆明理工大学,云南 昆明 650200)
改进加权Slope one协同过滤推荐算法研究*
王潘潘, 钱 谦, 王 锋
(云南省计算机技术应用重点实验室 昆明理工大学,云南 昆明 650200)
协同过滤推荐是最成功的推荐技术之一,但数据稀疏性问题导致推荐准确度和推荐效率不高。针对这个问题,提出了一种改进的加权Slope one协同过滤推荐算法。计算用户之间的评分相似度,找出每个用户的最近邻;根据最近邻用户评分,使用基于用户的协同过滤和改进的加权Slope one算法的加权评分预测目标用户的未评分项目;给出推荐。实验过程中采用MovieLens数据集作为测试数据。实验结果表明:与原算法相比,算法提高了预测准确度,有效提高了推荐性能。
数据稀疏; 用户相似性; 协同过滤; 最近邻用户; 加权Slope one算法
0 引 言
随着电子商务的发展,越来越多的用户喜欢网络服务,但随着商品信息的增加,引起了商品信息过载问题。为了使用户在大量商品中准确找到喜欢的商品,推荐系统应运而生。个性化推荐是目前最受欢迎的营销方式之一,推荐用户支付得起、个性化、匹配度高的商品是推荐领域的核心问题,对技术研究提出了很多挑战。现有的推荐技术正在向不同领域提供解决方案,电影,书籍,音乐电台等都使用了适合自己的推荐系统,比如国外的MovieFinder、Amazon、CDNow;国内的豆瓣、京东商城等[1]。同时,推荐系统面临着冷启动、数据稀疏性、可扩展性等问题[2]。随着研究的进步,这些问题得到了很大程度地解决,在推荐电影等方面已经产生了令人满意的推荐效果。
目前的推荐算法主要分为4类:基于内容的推荐、基于知识的推荐、协同过滤推荐和混合推荐算法。协同过滤推荐是目前最广泛的推荐技术之一,其中Slope one算法是一种简单的协同过滤算法,利用用户之间的评分偏差预测未评分项目。目前,已经有了很多类似算法:文献[1]使用Slope one算法对用户—项目评分矩阵中的空白评分进行预测填充,对填充后的评分矩阵使用基于用户的协同过滤算法进行推荐;文献[2]提出基于项目的协同过滤推荐算法并结合Slope one算法模型;文献[3]提出一种资源分配的用户相似性度量方法,增加相似用户的权重,在标准的MovieLens数据集上进行实验,结果表明改进的算法在一定程度上提高了预测精度。
上述研究根据最近邻项目集并结合Slope one算法进行推荐传统的Slope one算法没有考虑用户或项目之间的相似性,在数据稀疏时没有传统的协同过滤算法效果好。本文基于用户的协同过滤提出了一种改进算法,根据用户评分相似度计算目标用户的最近邻,在最近邻用户范围内使用用户协同过滤和加权Slope one算法改进预测评分值,提高了推荐质量。
1 基于用户的协同过滤推荐算法
协同过滤分为基于内存的协同过滤算法和基于模型的协同过滤算法。前者直接根据用户的历史评分数据寻找相似用户,分为基于用户和基于项目的协同过滤。基于用户的协同过滤的算法核心是网站给用户u作推荐,只要找出和用户u行为相似的用户,将行为推荐给用户u,算法核心步骤是:首先,找到和目标用户兴趣相似的用户集合;然后,找到这个集合中的用户喜欢且目标用户没有评过分的物品推荐给目标用户,确定邻居用户集合根据用户评分相似度,此算法和聚类算法[4]核心思想一致。基于用户相似性计算方法[5]有余弦相似性、修正余弦相似性和相关相似性。
1)余弦相似性
用户的评分可看做n维项目空间上的向量,如果用户对项目没有评分,则用户对项目的评分为0。设用户i和用户j在n维项目空间上的评分表示为向量i→和向量j→,用户i,j之间的相似性计算公式为
(1)
分子为两个用户评分向量的内积,分母为两个用户评分向量模的乘积。
2)修正的余弦相似性
设用户i和用户j共同评分过的项目集合用Ii,j表示,用户i和用户j之间的相似性计算公式为
(2)
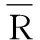
3)相关相似性(Pearson相关系数)
设用户i和用户j共同评分过的项目集合用Ii,j表示,Ii,j=Ii∩Ij,用户i和用户j之间的相似性计算公式
(3)
本文使用相似度计算方法来确定目标用户的最近邻居,计算用户与用户之间的相似度,通过实验确定用户与用户之间的相似度计算方法,空白评分的预测公式为
(4)
2 加权Slope one算法
Slope one算法是由Daniel Lemire 和Anna Maclachlan在2005年提出的一种协同过滤算法[6]。Slope one是一种容易理解的推荐算法,因其简单、易于实现和维护而备受关注。每对物品根据一个物品的评分预测另一个物品的评分,可以解决新用户问题和部分冷启动问题,及时获取新用户评分并对用户推荐结果产生影响,且算法运行速度快,可即时响应用户需求,在数据稠密的情况下,Slope one算法优于传统算法。基本Slope one算法思想来自简单的一元线性模型[3]为y=mx+b,x为评分差值,b为一个常量,m=1为基本的Slope one算法。如表1为一组用户评分值,计算user3对item 3的评分。

表1 三个项目的评分
首先找到user1,user2和user3共同评分的项目item1,计算user1和user2对item1和item3的评分偏差为((5-3)+(4-2))/2=2,user3对item3的预测评分为4-2=2。Slope one算法的基本步骤:1)定义itemi相对于itemj的平均偏差
(5)
式中 uj为用户u对itemj的评分;ui为用户u对itemi的评分;Sj,i(χ)为同时对itemi和itemj给予了评分的用户集合;card()为集合包含的元素数量。2)计算出每对项目之间的平均评分差值:首先,获取所有评过分的用户id,然后计算每个用户评分过的产品间的平均评分差值。计算评分偏差后,为某个用户推荐时,取出该用户评分过的项目,使用devj,i+ui获得用户u对itemj的预测值。将所有这种可能的预测平均起来,可以得到
(6)
式中 P(u)j为项目j的预测评分;card(Rj)为所有用户已经给予评分且满足条件 (i≠j且S(u)非空) 的项目集合。
但是Slopeone算法在计算itemi相对于itemj的平均偏差devj,i时没有考虑不同的用户数量,可信度不一样。假设有1 000个用户同时评分了itemj和k,而只有10个用户同时评分了itemj和l,显然devj,k比devj,l更具有说服力,而且推荐系统的应用中,用户评分数一般大于2,使用加权Slopeone更符合实际应用,本文使用加权Slopeone算法,预测评分公式为
(7)
式中 cj,i为加权值cj,i=card(Sj,i(χ));预测评分值用PwSl(u)j表示。
3 改进加权Slope one协同过滤推荐算法
加权Slopeone算法的缺点是没有考虑用户之间和项目之间的相似度问题,改进算法根据用户的协同过滤,选出目标用户的前k个最近邻,最近邻集合用S(k)表示,根据最近邻用户集合S(k)使用加权Slopeone算法预测未评分值。计算目标用户和其他邻居用户的相似度,对共同评分的项目可以得到一个评分相似度权值Weight为
(8)
式中 Ri,t≠0,Ri,t为用户i对目标项目t的评分;card(Ri,t)为评分总数。通过改进的加权Slopeone算法,给出推荐结果,改进的预测评分公式为
(9)
每个用户评分的项目数量有限,某些项目可能没有被评过分,所以影响算法推荐效果。为了克服这个问题,引入用户相似度,在邻居范围内,项目预测评分通过基于用户的协同过滤和改进加权Slopeone算法进行加权平均求得,改进的评分公式如下
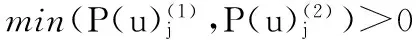

输入:用户—项目评分数据集,目标用户为u,目标项目为itemj。
输出:目标用户对项目的预测评分值P(u)j。
1)构建用户项目—评分矩阵,首先确定用户共同评分的项目,建立用户—项目评分矩阵R(m×n),根据式(3)计算用户之间的相似性,目标用户和其他用户没有共同评分项目,则用户之间相似度值置为-1。
2)产生邻居,计算用户之间的相似度,确定邻居个数k值,取前k个最大的相似度值用户,形成最近邻用户集合S(k),并使用式(8)计算评分相似度权值Weight。
3)在最近邻用户集合S(k)条件下,获取邻居用户id值,计算每个用户评分过的项目之间的评分差值,使用式(10)计算目标用户的未评分值。如果目标用户的邻居用户没有对当前项目评分,则项目预测评分值由当前用户对所有项目的评分均值代替。
4)输出预测值,产生TopN推荐,计算平均绝对偏差(Mean Absolute Error,MAE)值。根据用户对项目评分的预测值高低向用户做出推荐。
4 实验结果与分析
4.1 实验数据集
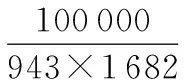
实验数据集分为训练集和测试集,采用5折交叉验证法。首先将数据集分成5个不相交的子集,将其中4份作为训练集,其余1份作为测试集,用训练集得到预测模型,然后用测试集对预测结果进行评价。
4.2 度量标准
衡量推荐质量的度量标准包括决策支持精度度量和统计精度度量[7~10]。本文使用MAE作为度量标准,计算公式如下
(10)
式中Pi为预测评分值;Ri为用户的实际评分值。MAE值越小,预测精确度越高。
4.3 实验结果
1)相似度计算方法
首先,对相似度计算方法进行了对比,在基于用户的协同过滤下,相似度计算分别采用修正余弦相似性、余弦相似性、相关相似性,在测试集和训练集上进行了5次对比实验,实验结果如表2所示,实验表明,相关相似性的MAE值最低,准确率最高,所以,本文相似度计算采用相关相似性。
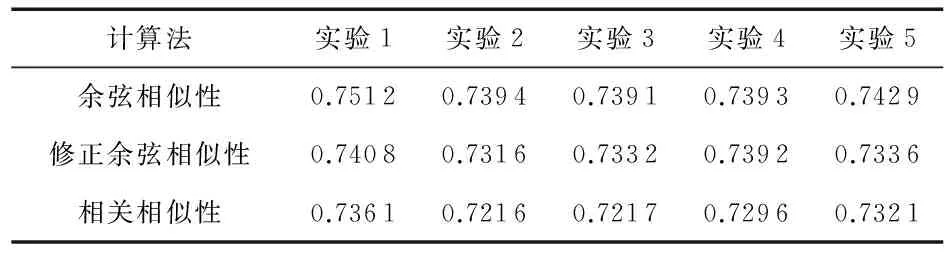
表2 不同相似度计算方法下的MAE
2)最近邻居集
按照相似度值形成用户的邻居用户集,然后通过实验确定邻居数目k的大小。邻居数目过少或过多均会影响推荐结果选取合适的k值可以使推荐结果更加准确。实验中,分别取k=2,5,10,15,20,25,30,35,40,45,50,每个k值对应采用5个不同的数据集,并将5次实验的MAE均值作为衡量算法优劣的指标。如表3所示,随着邻居数目的增大,MAE值逐渐增大,k=10时推荐质量最好,也可看出用户邻居的数量影响很大。

表3 不同邻居数下的MAE
3)不同算法下的MAE值
本文改进算法与基于用户的协同过滤和加权Slope one算法做了比较。如图1所示,在邻居数k=10的条件下,每个算法在测试集和训练集上分别做了5次实验,由实验可知:改进加权Slope one算法的预测效果明显比基于用户的协同过滤算法和加权Slope one算法的MAE值低,表明改进算法的推荐准确率高,算法的改进有很大的进步。
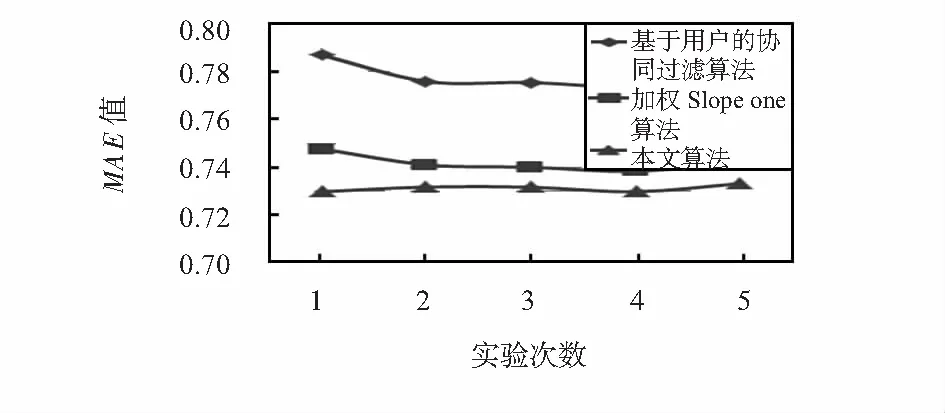
图1 不同算法下的MAE
5 结束语
本文针对传统Slope one算法在数据稀疏状况下推荐准确度不高的影响,提出了改进加权Slope one协同过滤算法。算法首先根据用户之间的相似性找出目标用户的邻居用户,预测目标用户的未评分项目的评分,通过对空白评分的填充,降低了数据的稀疏性,提高了推荐质量。而且本文考虑了用户之间的相似性,提高了推荐算法的推荐精度。实验结果表明:改进的加权Slope one算法的准确率较高,并在数据稀疏下达到满意的推荐效果。
[1] Wang P,Ye H W.A personlized recommendation algorithm combining slope one scheme and user based collaborative filtering[C]∥International Conference on Industrial and Information Systems,2009:152-154.
[2] Zhang D J.An item-based collaborative filtering recommendation algorithm using Slope one scheme smoothing[C]∥2009 the 2nd International Symposium on Electronic Commerce and Security,Nanchang,China: IEEE Computer Society,2009:215-217.
[3] 柴 华,刘建毅.一种改进的Slope one推荐算法研究[J].信息网络安全,2015(2):77-81.
[4] 惠周利,杨 明,潘晋孝.基于遗传算法与FCSS相结合的模糊球壳聚类算法[J].传感器与微系统,2008,27(12):109-111.
[5] 安计勇,高贵阁,史志强,等.一种改进的k均值文本聚类算法[J].传感器与微系统,2015,34(5):130-133.
[6] 贺怀清,李图波,李铁军.资源分配的改进Slope One算法[J].小型微型计算机系统,2015,36(5):1056-1058.
[7] Lemire D,Maclachlan A.Slope one predictors for online rating based collaborative filtering[C]∥Proceedings of the 2005 SIAM Data Mining Conference,2005:471-480.
[8] Zhao J L,Ma J B.An improved slope one algorithm based on tag frequency[C]∥2013 the 3rd International Conference on Computer Science and Network Technology,IEEE,2013:369-372.
[9] Sarwar B.Item-based collaborative filtering recommendation algorithms[C]∥Proceedings of the 10th International Conference on World Wide Web,Hong Kong,China,2001:285-295.
[10] Wang Y,Lou H Y.Improved slope one algorithm for collaborative filtering[J].Computer Science,2011,38(A1):192-194.
Study on improved weighted Slope one collaborative filtering algorithm*
WANG Pan-pan, QIAN Qian, WANG Feng
(Yunnan Key Laboratory of Computer Technology Applications,Kunming University of Science and Technology,Kunming 650200,China)
Collaborative filtering is one of the most successful recommendation technologies,but the data sparsity results in low recommendation accuracy and poor efficiency.So an improved weighted Slope one and collaborative filtering algorithm is proposed.Based on users’ ratings,it calculates the similarity between users,so that to find user’s the nearest neighbors.Based on the score of user’s nearest neighbors,user-based collaborative filtering and weighted Slope one algorithm is used to predict the unknown rating of the target users and to present recommendation results.In the experiment,MovieLens data set is used as test data.The experimental results suggest that the improved algorithm improves prediction accuracy and recommendation performance.
data sparsity; user similarity; collaborative filtering; nearest neighbors; weighted Slope one algorithm
10.13873/J.1000—9787(2017)07—0138—04
2016—07—13
国家自然科学基金资助项目(61462053, 31300938)
TP 311
A
1000—9787(2017)07—0138—04
王潘潘(1992-),女,硕士研究生,主要研究方向为推荐算法和人工智能。
钱 谦(1981-),男,通讯作者,博士,副教授,硕士研究生导师,从事视觉认知与计算智能研究工作,E—mail:qianqian_yn@126.com。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
河北画报(2020年8期)2020-10-27
汽车观察(2019年2期)2019-03-15
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国卫生(2016年5期)2016-11-12
