
移动云数据库的协作式语义缓存设计
2017-08-08 05:42杨静丽
微型电脑应用 2017年7期
杨静丽
(南京工业职业技术学院 计算机与软件学院, 南京 210023)
移动云数据库的协作式语义缓存设计
杨静丽
(南京工业职业技术学院 计算机与软件学院, 南京 210023)
移动设备的数据访问量在不断增加,而且数据也越来越复杂,但是由于移动设备本身的约束,增加了用户的访问时间。为了解决这个问题,一方面引入了各个用户之间的协作式缓存,另一方面使用云资源。在这里,提供一个移动云数据库架构模型和协作式语义缓存算法,使用户可以根据自己对访问时间的需求,来决定采取什么样的方式来访问数据。
协作式语义缓存; 移动; 云; 数据库; 能量消耗
0 引言
移动计算的应用在日常生活中慢慢的普及化了[1-4],在任何时候、任何地点都能接入信息网获取所需的信息将成为人们的普遍需求。移动数据库的发展对移动计算的广泛应用起着重要的推动作用。但由于移动设备本身的一些约束,例如存储有限、能量消耗、计算能力,网络连接情况等,增加了用户的访问时间。为了解决这个问题,一方面引入了各个用户之间的协作式语义缓存[5-6],另一方面使用云资源[7-8]。缓存系统能够存储以前处理的数据,使用语义缓存可以大大减少在云和移动设备之间的数据传送,同时能进一步提高云服务查询的性能。
1 基于语义缓存的查询
语义缓存主要包括三个关键概念[9][10]。首先,包括对被包含在每一个缓存入口的数据的语义描述,例如,查询关系、投影属性、查询谓词。可以使用语义描述来表示包含在缓存入口的相应的数据项,同时能迅速地知道缓存入口是否能解答当前的输入查询。其次,使用值函数来实现缓存数据替换。通过值函数来选择并替换旧的缓存入口。最后,在缓存内部,每一个缓存入口被称作一个语义区域并被认为是一个替换单元,它存储了有关一个查询结果的所有信息,包括投影属性列表,查询谓词列表,这个区域的元组的数目,一个元组的最大可能大小,结果元组以及用来处理数据替换的另外数据。当处理查询时,语义缓存管理分析查询内容,同时建立两个子查询:试探查询和剩余查询。试探查询直接在缓存中得到数据,剩余查询从数据库服务器或者使用云服务得到缺少的数据。在使用云服务时,除了要考虑移动设备上的查询优化,还必须要考虑在云上的优化。不同的云供应商为他们提供的每个云服务提出了他们的定价模型。
云查询处理和RDBMS系统中的查询处理的主要区别是:由于在云中无数的配置和查询路线,所以在云上处理一个查询的可能路线也是无数的。在云上的查询优化除了要考虑时间还要考虑花费,这就形成了一个二维优化问题。为了解决这个问题,首先使用预算约束来最小化处理时间,使用时间约束最小化成本。使用贪婪算法分配每一个具体操作,并多次执行该算法,产生多个时间表。按照约束,找出最优时间表。使用语义缓存,在查询裁剪算法过程中,可能会发生这4种情况:缓存准确命中、缓存未命中、缓存扩展命中、缓存部分命中。
缓存扩展命中又包括3种类型:
(1) 输入查询的结果被包含在一个缓存区域中,例如,输入查询σjava=60,而缓存区域中存放的是σjava>50σjava<70;
(2) 输入查询的结果需要从缓存中几个缓存区域中检索得到,例如,输入查询σjava≥0,而一个缓存中存放的是σjava=60,另一个缓存中存放的是σjava>60;
(3) 输入查询和语义区域的查询是等价的,例如,输入查询σjava=60,语义区域的查询σjava>59 andσjava<61。那么,如果我们获得了语义区域的查询结果,也就得到了输入查询的查询结果。
缓存部分命中指的是,使用试探查询,一部分查询结果可以从缓存中得到,另一部分查询结果使用剩余查询,从数据库服务器中得到。在缓存中只能得到部分查询结果,所有对应于剩余查询的元组,会在数据库服务器中下载。
2 使用协作式语义缓存
2.1 协作式缓存的架构
Padmanabhan and Sripanidkulchai[11][12]提出了一种称为协作式对等网络架构。本文采用分布式协作式网络,每一个客户使用一个分布式哈希表来缓存自己的查询基本信息和以往的查询结果。在移动网络中,客户会经常从一个地方移动到另一个地方,所以会受到电池能量和资源的限制。为了节约能量,我们不能在一些移动客户之间来选择缓存管理器,也不能让每一个客户都变成一个分布式主机[13],这样当为其他客户服务时,会有一个复杂的搜索过程。在这里,我们提供一个新的协作式语义缓存的方法,缓存架构,如图1所示。

图1 移动云数据库架构
h是移动主机,MSS是移动支持站,它提供到主机h的无线连接。MSS有无线通讯接口,通过它,主机h就可以连接到有线主干网络。MSS在移动客户端和服务器之间起到了网关的作用。F表示对应的移动主机的缓存备份,各个客户之间以协作的方式,共享他们的缓存。
2.2 云服务移动计算环境下的协作式语义缓存
在移动云数据库架构中,MSS不是一个移动客户端,而是作为一个缓存管理器。MSS主要包含3个独立部分:缓存内容管理器、缓存替换管理器、缓存解析管理器。缓存内容管理器用于管理缓存内的结果,经常用于插入,删除和查找。缓存替换管理器使用一些相关的项来处理缓存数据替换。缓存解析管理器用来恢复缓存中的数据同时调用一些外部工具来加载丢失的数据项。还使用3种其他类型的管理器,包括:移动估计计算管理器、云估计计算管理、优化管理器,主要用来处理每一次评估的计算以及制定更好的解决方案。当在移动设备上执行一个查询时,移动估计计算管理器计算执行时间和能量消耗。云估计计算管理器用来在云上处理一个查询时的计算时间,移动能量消耗以及必要的成本。当考虑到用户的一些约束时,比如,剩余电池情况,最大查询响应时间以及支付给云供应商的费用等等,优化管理器负责在移动查询处理估计和云查询处理估计之间进行选择。
举例:假设h1和h2是两个移动客户。
开始时,h1,h2和 MSS的缓存都是空的。
第一步:h1在时刻T1发送查询请求Q1(select num, name from student where math<80 and 50 第二步:客户端h2在时刻T2发送查询请求Q2(select num, name from student where math<80 and 60 第三步:h1在时刻T3发送查询请求Q3(select num , name from student where math<90 and 65 2.3 协作式语义缓存算法 上面的例子是一个典型的无线数据访问情况,说明了怎样使用协作式语义缓存来满足客户端的查询。算法主要包含下面几步:查询缓存分析、估计计算、决策过程、查询计算。首先,查询缓存调用内容管理器返回三种结果:缓存命中或未命中的类型、试探查询、剩余查询。其次,根据查询分析结果进行估计计算。在查询命中的情况下,查询直接在移动设备上执行,并得到结果,因此,可以忽略在移动设备上的查询处理成本。在查询部分命中的情况下,要估计在移动设备上的试探查询处理时间和在云上处理剩余查询的成本。另外,还要计算在云上处理整个输入查询的估计成本,在这里我们使用acquiredEstimation函数[14][15]来得到。函数在云估计缓存或者移动估计缓存中查找那些估计值。估计缓存调用替换管理器将新的估计插入到缓存中保存起来。在扩展命中的情况下,在移动设备上处理查询要花费一定的成本。所以,在这种情况下,执行之前来计算估计值是非常重要的。同时,依据在云上执行查询的预估成本来决定是应当在移动设备上查询还是在云上查询。最后,在查询未命中时,算法计算在云上处理查询的成本,以满足用户的一些需求。一旦计算好了估计值,就可以决定应该在哪处理查询并建立查询计划。如果在执行时间、能量消耗以及花费上,都能满足用户需求,那么查询缓存就会调用解析管理器来处理已经产生的查询计划并返回查询结果。同时,要更新估计缓存中的执行时间,能量消耗,花费等值,再使用查询缓存的替换管理器替换查询缓存中的数据。如果有些部分需要从查询缓存中移除,那么与其对应的移动估计缓存中的内容也应该移除。如果这个部分被一个只需要很少花费就能获得查询结果的替换了,那么这个估计也就不正确了。最后,所有的替换完成以后,用户得到查询结果。 算法定义的类和acquiredEstimation函数的实现以及整个算法的流程图,如图2所示。 图2 协作式语义缓存算法流程图 类的定义:查询Query、查询缓存QueryCache、移动估计缓存MobileEstimationCache、云估计缓存CloundEstimationCache、移动估计计算管理器、云估计计算管理器、优化管理器。 acquiredEstimation函数: 输入:Query query, EstimationCache estimationCache, EstimationComputationManager estimationCo- mpManager 输出:Estimation estiResult 1. estiLookup=estiCache.lookup(query) 2. if estiLookup=CACHE_HIT then 3. estiResult=estiCache.process() 4.else 5.estiResult=estimationCompManager.compute(que ry) 6.estiCache.replace(query,estiResult) 7.end if 8.return estiResult 使用Java进行模拟实验,首先建立一个模拟实验环境:一个数据库服务器,一台模拟MSS的计算机,多个移动客户端,1.728 GHz CPU,2 GB of RAM,2300 mAh的电池容量,使用阿里私有云服务。实验中使用Hadoop框架以及数据仓库Hive。通过运行在tomcat服务器上的RESTful Web服务来访问云架构基础设施。Web服务使用云来评估查询的成本,同时使用HiveQL在云上处理查询,HiveQL使用MySQL数据库存储数据。为了研究本算法的性能,在下面3种情况下完成实验:(1)不使用缓存(2)使用语义缓存(3)使用协作式语义缓存。在每一种情况下,记录算法的平均查询时间、查询成本、能量消耗以及缓存命中率。对于每一种情况,模拟执行100次迭代,并记录平均结果,如图3所示。 图3 在不同的查询请求情况下的缓存命中率 从图3可以看出随着请求数量的增加,在使用语义缓存和协作式语义缓存两种情况下,缓存命中率都在不断地提高。在没有使用缓存的情况下,命中率均为零。使用协作式语义缓存不仅可以利用移动主机的本地缓存,还可以使用备份存储在MSS中的其他移动主机的缓存,所以缓存命中率迅速提高,如图4所示。 图4 在不同缓存扩展命中率的情况下进行100 从图4可以看出,使用语义缓存和使用协作式语义缓存在处理时间,能量消耗,费用等方面是相似的,这也说明了,估计缓存阻止了由于估计计算所引起的一些开销。当使用协作式语义缓存时,由于使用了云服务,查询处理时间明显减少,如图5所示。 图5 在不同缓存扩展命中率的情况下进行100次查询的费用 但是从图5可以看出,由于使用云服务,产生了一些费用。当用户在费用上有一定限制时,本文算法可以阻止一些对于个别用户来讲花费费用比较高的查询,因此,与不考虑任何用户约束的语义缓存相比,使用本文算法减少了不满足用户约束的查询的数量,保证用户和云服务之间能互相协作的工作。当缓存部分命中时,本算法和语义缓存算法的处理查询时间是类似的,因而在缓存部分命中的情况下,查询效率没有提高。 本文一方面引入了各个用户之间相互合作的缓存,另一方面给出了一个应用于移动云数据库的协作式语义缓存的算法。算法能够预先估计在移动设备上处理查询和在云上处理查询所花费的时间,消耗的能量以及使用云服务所花费的费用,所以算法能够根据用户的要求来执行查询,用户和数据库系统之间能够相互协作地工作。从仿真实验结果可以看出,由于算法能够在移动云环境下运行,减少了查询处理时间。 [1] 徐小龙,刘笑笑. 面向移动计算环境的混合式数据同步机制[J].通信学报,2016,37(8):1-12. [2] 薛彦俊. 移动图书馆APP 应用的探讨[J].网络与信息工程,2016,55-56. [3] 胡金萍.新时期云数据库研究[J].网络技术,2016,43-45. [4] 刘琰,郭斌,吴文乐等.移动群智感知多任务参与者优选方法研究[J].计算机学报,2016,39(3):1-16. [5] 龚玉利,冷文浩. 移动计算中语义缓存的改进研究[J].计算机应用与软件,2014,31(2):37-40. [6] 梁茹冰,刘琼.移动环境中语义缓存一致性维护的Agent 方法[J].北京邮电大学学报,2014,37(3):67-72. [7] 林子雨,赖永炫,林琛,谢怡,邹权.数据库研究[J].软件学报,2012,23(5):1148-1166. [8] 卿宸,钟勇,向柳明. 云数据库中基于极大熵差分进化的负载评估算法[J].计算机应用,2014,34(S2):123-125. [9] Dar, S., Franklin, M.J., Jonsson, B.T., Srivastava. Semantic data caching and replacement:Very Large Data Bases VLDB[J]. 1996: 330-341. [10] Ren, Q., Dunham, M.H., Kumar, V. Semantic caching and query processing[J]. IEEE Trans. Knowl. Data Eng.2003,15(1): 192-210. [11] Padmanabhan V N, Sripanidkulchai K. The case for cooperative networking[C]∥Proceedings of the 1st International Workshop on Peer-to-Peer Systems (IPTPS’02), Mar 7-8, 2002. Berlin,Germany: Springer-Verlag, 2002: 178-190. [12] Liang Ru-bing, Liu Qiong. Answering queries using cooperative semantic cache in mobile computing environments[J]. The Journal of China Universities of Posts and Telecommunications, 2012, 19(3): 54-59. [13] Bruno, N., Jain, S., Zhou, J.Continuous cloud-scale query optimization and processing[C]∥Proceedings of the VLDB Endowment, 2013, 6(11): 961-972. [14] Mikael Perrin, Jonathan Mullen, Florian Helff, LeGruenwald, and Laurent d’Orazio. Time-, Energy-, and Monetary Cost-Aware Cache Design for a Mobile-Cloud Database System[C]∥Biomedical Data Management and Graph Online Querying. VLDB. 2015,71-85. [15] Li D W, Huang W J, Hu J H, et al. A distributed redundant real-time data storage mechanism[J]. Journal of Shanghai Jiaotong University,2014, 48(7): 948- 952. Cooperative Semantic Cache Design for Mobile-Cloud Database Systems Yang Jingli (School of Computer and Software, Nanjing Institute of Industry Technology, Nanjing 210023, China) Growing demand for mobile access to data is only outpaced by the growth of large and complex data, accentuating the constrained nature of mobile devices. On the one hand, we introduce the cooperative semantic cache among different users, on the other hand, we use cloud resources to solve this problem. We present a mobile cloud database architecture model and a cooperative semantic cache algorithm by which the users can decide the manner to use to access data according to their demand of accessing time. Cooperative semantic cache; Mobile; Cloud; Energy consumption 国家自然科学基金(61671253),南京工业职业技术学院2015年院级科技创新团队项目(TK15-04-01) 杨静丽(1971-),女, 辽宁绥中人,教授,硕士,研究方向:软件技术,云计算等。 1007-757X(2017)07-0007-04 TP393 A 2017.03.06)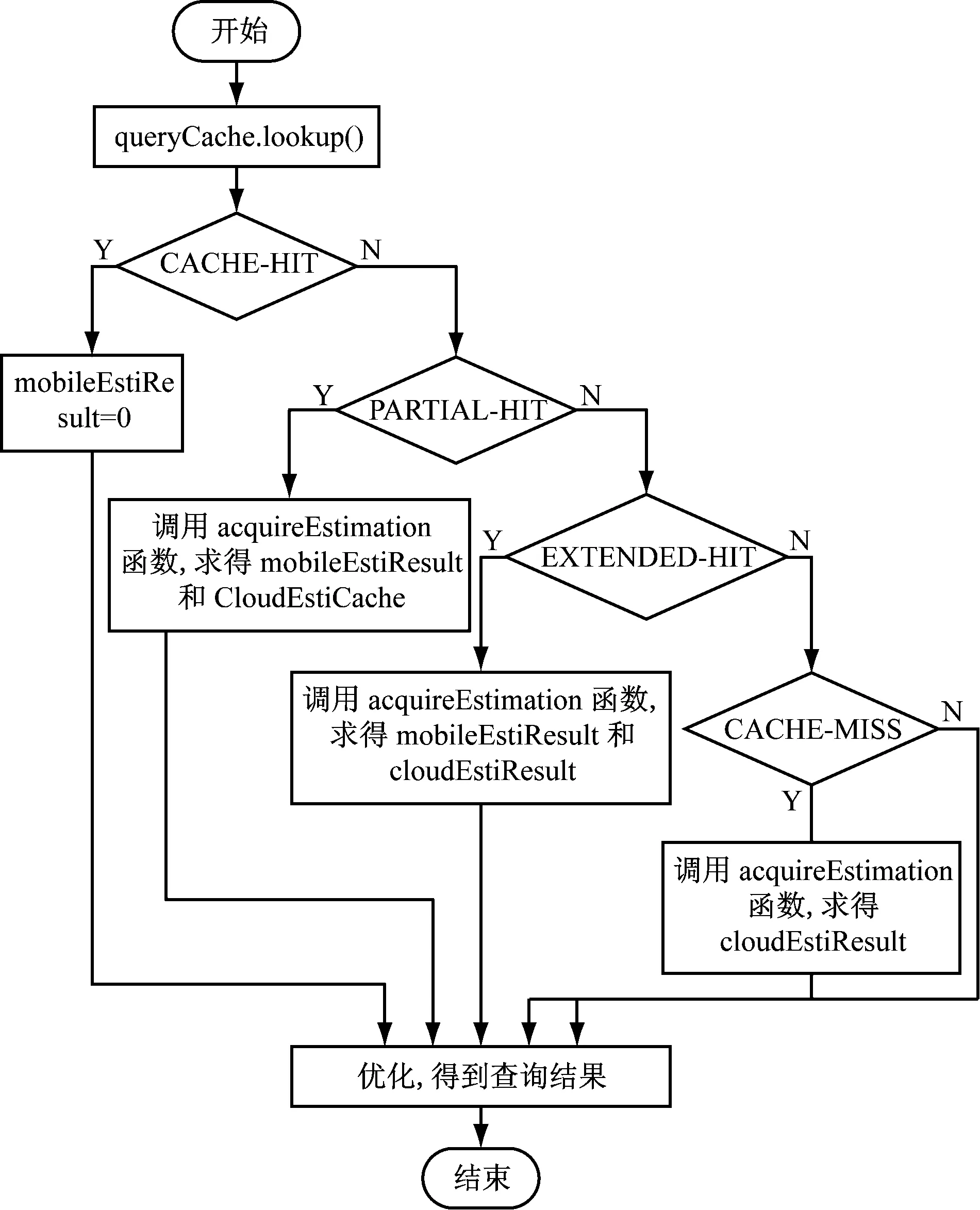
3 仿真实验

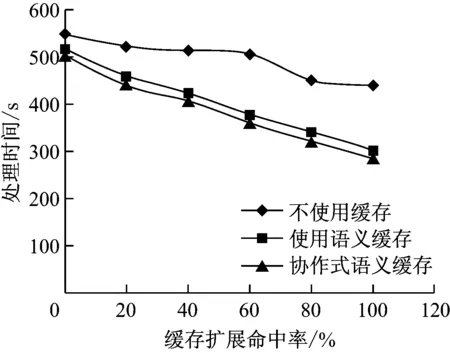
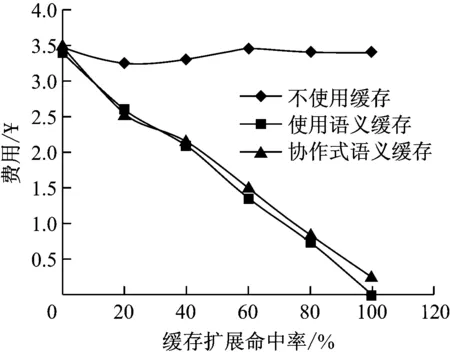
3 总结
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21体育科技文献通报(2022年3期)2022-05-23计算机与网络(2021年22期)2021-01-13作文中学版(2020年1期)2020-11-25电脑爱好者(2020年10期)2020-07-28作文成功之路·小学版(2019年8期)2019-09-18人大建设(2019年4期)2019-07-13小学生学习指导(低年级)(2019年4期)2019-04-22数码世界(2018年2期)2018-12-21读者(2017年14期)2017-06-27
