
基于NOSQL的微博图数据管理存储平台设计与实现∗
2017-08-01 13:49包从开黄永峰廖旺坚余辉
计算机与数字工程 2017年7期
包从开 黄永峰 廖旺坚 余辉
(1.清华大学电子工程系信息认知与智能系统研究所北京100084)(2.清华大学信息科学与技术国家实验室北京100084)(3.中国科学院大学北京100084)
基于NOSQL的微博图数据管理存储平台设计与实现∗
包从开1,2黄永峰1,2廖旺坚1,2余辉3
(1.清华大学电子工程系信息认知与智能系统研究所北京100084)(2.清华大学信息科学与技术国家实验室北京100084)(3.中国科学院大学北京100084)
近年来,以微博为代表的在线社交网络得到迅速普及和发展。这些规模庞大,内部关联复杂的图结构数据给传统数据库的存储管理带来了挑战。论文详细分析微博社交网络数据结构特点,结合上层应用需求对数据存储模型进行设计,实现了一套基于NoSQL的微博数据管理存储平台。该平台设计为RAW数据存储、图模型映射、NewSQL转换三层,较好地解决海量微博图数据存储的可扩展性和实时、易用性问题。通过实验对平台入库、查询性能进行了评估,验证了其在实际中的有效可行性。
NoSQL;微博;大图数据;存储管理平台
Class NumberTP311
1 引言
近年来,以微博为代表的在线社交网络得到迅速普及和发展。作为当下最流行的社会信息传播平台,微博对突发事件的发生发展产生着重要影响,面向微博数据的分析挖掘等显得十分有意义[1]。
然而,微博社交网络规模庞大,内部关联复杂,是典型的大图关系数据。据报道,2015年6月新浪微博月活跃用户数为2.12亿,单月微博产生总量达30亿以上。假设以微博用户作为顶点,用户间互相的关注、好友等关系作为边来构建图数据结构,则仅用户间关注边超过十亿,如果进一步考虑用户与微博间关系以及历史数据,则微博数据量可达上百TB。目前传统的关系型数据库并不能适应这一需求,对其存储检索的时间空间开销都远远超出了当前传统数据库的承受能力。如何对海量微博社交网络数据进行稳定、高效的存储管理成为一件亟需解决并且具有挑战的任务[2]。
本文重点分析微博社交网络数据结构特点,对存储模型进行设计,实现了一套基于NoSQL的微博数据管理存储平台,该平台设计为RAW数据存储、图模型映射、NewSQL转换三层,分层地解决了海量微博图数据存储的可扩展性和实时、易用性等问题。为进一步研发热点人物多维关联关系分析[3],意见领袖挖掘追踪[4]等典型应用提供了数据存储与管理支撑。
2 相关研究
传统数据库借助于集合代数等数学概念和方法来处理数据库中的数据,是建立在关系模型基础上的数据库。关系模型[5]由IBM研究员Codd于1970年首先提出,在之后几十年中以其容易理解的模型、容易掌握的查询语言、成熟的技术和产品,逐渐成为数据库架构的主流模型。
然而面对海量微博的复杂关系图[6],关系数据库系统并未做好准备[7]。首先,过于严格的建模模型不容易组织和管理所有类型多样的数据,对于新浪微博这些复杂的内部关联数据,强行使用关系模型进行建模,会引入大量的JOIN操作和额外的空间开销,效果并不能令人满意。其次,如何实现大规模数据的高速查询,是一个巨大的挑战。现有的关系型数据库解决方案通常不可伸缩[8],当数据量增大时性能会遇到瓶颈,已经无法从根本上解决这一问题。面对上述需求和挑战,NoSQL数据库不断涌现和发展,为大规模图关系数据存储提供了一种可行的解决方案。
目前NoSQL数据管理数据库按数据模型分目前有代表性的主要有四类[9]。键值数据模型是NoSQL中结构最简单的数据存储模型,通过哈希表维护Key到具体数据(value)的映射,易于存储大量数据,如Redis、Berkeley DB等。但是对于处理图关系数据,经常需要批量的对节点进行数据查询、更新时效率上较低,难以达到实时要求。列族存储[10]模型在存储数据时,围绕着“列”,而不是传统关系数据库的“行”进行,主要有BigTable,Cassandra等。对于同一列操作时,具有查询速度快、数据缩率高的特点。但此类数据库只适用于按Rowkey的简单查询,不具备二级索引功能且需学习一套其本身私有的API,易用性较差。文档存储模型比较适合存储系统日志等非结构化数据,但并不适合微博这样以邻接矩阵或邻接表组织的图数据。图存储模型[11]的相关研究目前还不完善,neo4j是当前最成熟的开源图数据库,但由于是单机系统存储规模有限,难以扩展。
综上,现有的各类数据库系统在可扩展性,实时性,易用性等方面不能完全满足微博社交网络数据存储查询的具体需求。本文将详细分析微博大规模社交网络数据的特点,设计多种存储模型,基于分层思想实现一个同时满足可扩展、实时、易用的存储管理平台。
3 微博数据关系模型分析

图1微博图数据模型
为了给微博数据的存储管理奠定基础,对微博社交网络数据进行具体模型分析,将抽取到的各类节点和关系边集中在示意图1中进行表示。如图所示,图结构中包括了用户、微博等三种节点及关注、转发等五种边关系。其中用户节点,包括用户的ID、注册时间、姓名、昵称、性别、省份城市、邮箱地址、博客地址、个性化域名地址和个人描述等属性信息。微博节点包括微博的ID、发表时间、来源、内容、转发数、回复数和情感值等信息。评论节点包括时间、内容等信息。对于五种边关系表示如下:
1)关注、好友关系。关注关系建立在用户与用户之间,包括两种类型:单向的关注关系和双向的好友关系。如图所示,用户B和C之间,C关注了B,而B没有关注C,这就是一种单向的关注关系;A关注了B,同时B也关注了A,那么AB双方则是一种双向的好友关系。其中关注关系边中包含权重强度等信息。
2)发文关系。发文关系建立在用户和微博之间,如图所示,用户A发表了微博A和B,则在用户A和微博A、B之间就产生了发文关系。
3)转发关系。转发关系建立在用户和其他用户发表的微博之间。图中所示,用户B和C分别转发了微博B。对于每一个转发关系,都存在一个转发路径。例如用户B转发路径为用户B→用户A→微博B,对于用户C的转发路径则为用户C→用户B→用户A→微博B。
4)艾特关系。艾特关系建立在微博与用户之间,是某个用户发文或转发其他人的微博之后,想提醒其他用户而建立在微博和其他用户之间的一种关系。用户发文后可以艾特其他用户,如用户A发表微博B并艾特用户E;用户转发其他人的微博后也可以艾特其他用户,如用户C转发微博B并艾特用户D。
5)评论关系。回复关系建立在用户与微博之间,用户可以对其他用户发表的微博,或者是转发的微博进行回复,从而在用户和他人的微博之间建立回复关系。图中用户E和微博A建立了评论关系。
4 微博数据存储模型设计
将用户、微博信息数据,各类关系数据(好友关系,转发关系等)全部成功加载进NOSQL数据库。由于微博数据规模庞大,在具体实现中采用Hbase数据库,Hbase是一种Key Value存储、面向列族的分布式NoSQL数据库,对于主键查询可以做到毫秒级效率。根据上述微博关系模型分析,结合上层应用要求实现任意节点属性及关系毫秒级查询的实时性需求,通过图分割方法建立多表,基于访问模式建立主键索引,微博图数据映射存储表如下:
1)用户节点表
用户表存储用户结点的基本信息。考虑到基于用户名的访问模式较多,将用户名UserName做为Rowkey。该表分为Userinfo和Count两个列族,列族userinfo下存放性别、昵称、邮箱等相应个人信息。由于HBASE的无模式可扩展特性,以后需要添加任何属性字段时可以直接进行添加。这些信息不经常变动且经常会同时读取,将其放于同一列族下,可以大大减少读写IO延迟。列族Count存储了用户的关注数、粉丝数、发文数等数量信息。每当往用户关系表插入数据时,利用Hbase Increment功能对此数值进行自动递增。这样就可以通过主键直接查询,避免了Hbase数据库在统计查询时中需要全表scan时延大的缺陷。

表1 用户节点表
2)微博节点表
微博表存储微博结点的基本信息。该表同样分为Weiboinfo和Count两个列族。列族Weiboinfo下存放作者、创建时间、微博内容等相应不经常变动的信息以减少IO。列族Count存储了用户的转发数、收藏数等数量信息。

表2 微博节点表
3)用户关系表
用户间关系表存储用户之间的关注、好友等关系信息。存储时需要容纳下上亿甚至数十亿用户间的相互联系,采用用户ID、关注者ID的字符串拼接来建立复合Rowkey,因为用户名长度为变长字符串,对两者进行散列运算,使其生成固定长度的值,且使得数据能够随rowkey均匀分布,因此能避免REGION热点问题。本表只设一个列族,列族内存放用户关注时间,用户关系权重等信息。在查询用户关注关系时只要对复合Rowkey进行查找,例如存在记录便存有UserID1对UserID2的关注关系。利用Hbase Filter以及正则表达式,通过前缀匹配可以快速查找UserID1的关注列表,而通过后缀拼配能得到用户所有的粉丝列表。要获得用户的好友关系,则只需对用户的关注列表及粉丝列表取交集。
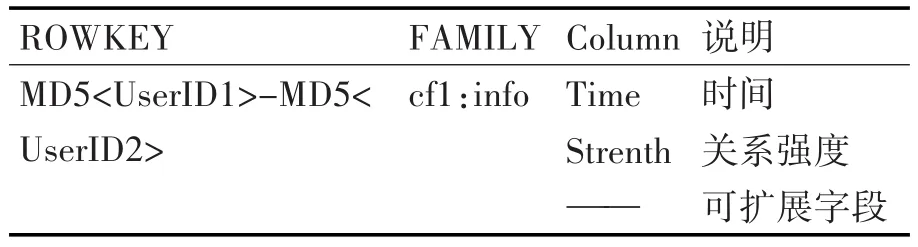
表3 用户关系表
4)用户微博关系表
用户微博关系表存储用户微博间发文,转发,艾特,评论等关系信息。采用用户ID、关系类型、时间戳、微博ID的字符串拼接来建立复合Row⁃key。其中首字段用户名长度为变长字符串,对其进行散列运算,使其生成固定长度的值。二字段添加关系类型冗余字段,例如采用二位编码00表示发文,01表示转发,10表示艾特,11表示回复。要查询用户的微博数据时,只需要给出用户ID-关系类型,便可以通过前缀查询快速取出这个用户的所有微博记录。三字段添加时间维度信息,通过对时间戳字段进行反转,在进行查询时,数据将以时间的降序进行排列,即会优先显示其最近发表的所有微博。在列族中,设置了评论内容、评论情感倾向,转发来源等字段,如若微博经过多次转发,可以通过多次查询repostFrom字段追溯微博转发路径。

表4 用户微博关系表
5 管理存储平台框架设计
微博图数据管理存储平台分为三层,包括RAW存储层、图数据映射层以及NewSQL转换层。通过分层的思想实现平台的可扩展,实时,易用性目标。每部分的功能如下。
RAW存储层。RAW层存储通过网络爬虫等技术从新浪、腾讯等主流微博获取原始数据,包括用户、微博信息以及用相互的边关系等。微博数据更新量较大,每天需采用实时数据获取工具向RAW层每天自动更新前一天的增量数据。由于RAW层使用HDFS分布式文件系统用来存储,HDFS本身能够基于普通硬件集群提供高吞吐的数据批量读写能力,因此能够提供高可靠的可扩展能力。

图2微博图数据存储系统
图模型映射层。在此层中主要实现平台的实时性要求。在第3节中对Hbase进行图分割,图索引等方法对微博数据进行了映射载入。Hbase通过维护-Root-和.Meta.两张特殊位置信息表,采用类B+树的结构来获取数据的Region信息,能够实现高效的实时查询。对于基于主键的增删改查操作,该层可以做到TB数据毫秒级的随机查询速度。
NewSQL转换层。NewSQL层是构建在HBase之上的SQL引擎层,在此层我们实现微博HBase图数据模型到SQL引擎层的映射与转换工作。具体来讲在此层实现了两种功能:一是增加SQL解析功能实现类标准化的SQL语言来访问HBase数据库,用户可以直接通过客户端JDBC驱动用以对HBase中的数据进行实时访问。通过此层对外提供各类包括用户、微博节点查询,用户间转发回复评论等关系在内的图查询接口,实现数据查询的易用性目标。二是提供基于非主键查询的支持。由于当前HBASE系统并没有提供二级索引功能,当用户基于非主键査询数据的时候,只能通过全表扫描获取满足条件的数据,不能满足实时化需求。通过建立倒排索引,以数据的冗余换取时间上的实时。
6 微博数据管理存储平台的系统性能测试与评估
本节根据上述框架搭建实际存储管理平台,对系统读写性能进行测试和验证。
6.1 实验环境及软件配置:
采用5个服务器部署分布式集群,其中一台服务器作为主节点,其余4台作为平台的数据节点,系统软硬件配置如下。

表5 服务器集群环境及软件配置表
6.2 写入性能

图3导入性能测试
采用的负载为用户模拟数据,其中单条记录大小1KB,包含10字段。使用JAVA客户端,多线程方式进行入库。由图可见,入库速度随着随着线程增多、数据规模增大而不断增长,且随着节点增加呈线性增长,具有较好的可扩展性。当在4台节点,数据为100万条,100线程时,入库速率达到14.7MB/S,能满足项目需求。

表6 导入性能测试
6.3 查询性能
查询测试采用的是通过爬虫技术从新浪、腾讯等主流微博获取的真实图数据。通过去噪清洗,将采集过程中出现的错误和不一致性数据过滤并进行结构化处理后,获得用户节点数7489707,用户关系边数21105470,微博节点数4067183,用户微博关系数边32958308。

表7 项目常用API查询实时性测试(ms)

图4数据平台可扩展性测试(ms)
鉴于微博中存在大量的僵尸用户,根据需求选取5000个重点人物在平台上对项目常用的API进行SQL查询用时测试,由于数据需多次测试,block⁃cache命中率对读性能影响十分大。对此,将分开启和关闭缓存两组进行测试。
由表7可知,在已有数据下,项目常用API的利用SQL语句平均查询用时皆在20ms以内,99%分位值也均在100ms以内,能够很好地满足平台的实时性要求。由图4数据可知,随着数据规模的增大,存储平台的数据查询用时并不出现线性增长。即使在用户节点数达到5000万的规模下,也能保持属性查询平均用时在15ms以内。特别是对指定重点人物的多次查询,在缓存命中的情况下能保持用时在5ms。由于本存储系统基于HDFS文件系统搭建,其分布式架构本身具有良好扩展与可靠性。故本存储平台能够成功满足实时,可扩展性和易用性等要求。
7 结语
本文建立了一个面向海量微博数据的管理存储平台,着重对微博社交网络数据的内在关系进行深入分析及NoSQL数据存储设计,并成功将此平台应用于项目组重点人物多维关联关系分析,意见领袖挖掘追踪等典型应用中,有效地解决了传统关系型数据库在存储微博大图数据中遇到的各类挑战。
[1]廉捷,周欣,曹伟,等.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011(10):1300-1305. LIAN Jie,ZHOU Xin,CAO Wei,et ak.SINA microblog data retrieval[J].Tsinghua Univ(Sci&Tech),2011(10):1300-1305.
[2]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013(1):146-169. MENG Xiaofen,CI Xiang.Big Data Management:Con⁃cepts,Techniques and Challenges,2013(1):146-169.
[3]孟聪,黄永峰,应励志.基于认知度的用户好友社团关系挖掘方法[J].计算机应用研究,2012(8):2833-2836. MENG Cong,HUANG Yongfeng,YING Lizhi.Community relationship mining method based on users'cognition de⁃gree[J].Application Research of Computers,2012(8):2833-2836.
[4]樊兴华,赵静,方滨兴,等.影响力扩散概率模型及其用于意见领袖发现研究[J].计算机学报,2013(2):360-367. FAN Xinhua,ZHAO Jing,FANG Bingxing,et al.Influ⁃ence Diffusion Probability Model and Utilizing It to Identi⁃fy Network Opinnion Leader[J].Chinese Journal of Com⁃puters,2013(2):360-367.
[5]Codd E F.A relational model of data for large shared data banks[J].Communications of the ACM,1970,13(6):377-387.
[6]丁悦,张阳,李战怀,等.图数据挖掘技术的研究与进展[J].计算机应用,2012(1):182-190. DING Yue,ZHANG Yang,LI Zhanhuai,et al.Research advances on graph data mining[J].Journal of Computer Applications,2012(1):182-190.
[7]龚卫华.数据库集群系统的关键技术研究[D].武汉:华中科技大学,2006. GONG Weihua.Study On the Key Issues of Database Clus⁃ter System[D].Wuhan:Huazhong University of Science and Technology,2006.
[8]覃雄派,王会举,李芙蓉,等.数据管理技术的新格局[J].软件学报,2013(2):175-197. QIN Xiongpai,WANG Huiju,LI Furong,et al.New Land⁃scape of Data Management Technologies[J].Journal of Software,2013(2):175-197.
[9]申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013(8):1786-1803. SHEN Derong,YU Ge,WANG Xite,et al.Survey on NoSQL for Management of Big Data[J].Journal of Soft⁃ware,2013(8):1786-1803.
[10]李超,张明博,邢春晓,等.列存储数据库关键技术综述[J].计算机科学,2010(12):1-7,17. LI Chao,ZHANG Mingbo,XING Chunxiao,et al.Survey and Review on Key Technologies of Column Oriented Da⁃tabase Systems[J].Computer Science,2010(12):1-7,17.
[11]Chang F,Dean J,Ghemawat S,Hsieh WC,Wallach DA,Burrows M,Chandra T,Fikes A,Gruber RE.Bigtable:A distributedstorage system for structured data[C]//Ber⁃shad BN,Mogul JC,eds.Proc.of the OSDI 2006.Seat⁃tle:USENIX Association,2006:15-22.
Design and Implementation of Microblog Graph data Management and Storage Platform Based on NoSQL
BAO Congkai1,2HUANG Yongfeng1,2LIAO Wangjian1,2YU Hui3
(1.Institute of Information Cognition and Intelligence System,Department of Electronic Engineering,Tsinghua University,Beijing100084)(2.National Laboratory for Information Science and Technology,Tsinghua Univerisity,Beijing100084)(3.University of Chinese Academy of Sciences,Beijing100084)
In recent years,online social networks are rapid popularization and development,especially in the microblog sys⁃tem.These large-scale,inter-related complex graph data brought enormous challenges to the traditional database storage manage⁃ment.This paper thorough analyzes the structural features and the relationship between the type of microblog data,designs and Im⁃plementationsthedata storage platform based on NoSQL.The platform is divided into threelayers of information extraction,distribut⁃ed storageandNewSQLconverted.Itsuccessfullymeetsthe requirements of scalable,real-time,and ease of use.Experiment show its good performance in practise.
NoSQL,mcriblog,big graph data,storage platform
TP311
10.3969/j.issn.1672-9722.2017.07.025
2017年1月10日,
2017年2月27日
国家自然科学基金项目(编号:U1536201);科技部支撑技术项目(编号:2014BAH41B00);科技部863项目(编号:2015AA020101)资助。
包从开,男,硕士,研究方向:网络大数据存储与计算。黄永峰,男,博士,教授,研究方向:网络WEB信息挖掘及应用及网络隐蔽通信与监测。廖旺坚,男,硕士,研究方向:网络大数据并行计算。余辉,男,硕士,研究方向:舆情分析与监测。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
智能制造(2021年4期)2021-11-04
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
World Journal of Diabetes(2019年3期)2019-04-16
智富时代(2018年10期)2018-01-30
智富时代(2018年10期)2018-01-30
财经(2017年2期)2017-03-10
