
基于半监督聚类的数字图书推荐模型
2017-07-31 12:39黄莹
科技视界 2017年8期
黄莹
【摘 要】互联网的飞速普及使数字图书馆变成现代图书馆建设的一个重要维度,为用户供给越发优秀的图书加工和组织方法成为了数字图书馆前进的一个重要方向。数字图书推荐能够结合读者的历史阅读信息,个人的兴趣喜好等数据,为读者推荐他应该有兴趣的书籍。数字图书推荐能够增加图书资源的使用率,增多阅读书籍的读者。本文利用两种半监督聚类算法,改进了一种数字图书推荐系统模型。
【关键词】数字图书;推荐系统
0 引言
数字图书推荐系统一般分为三个基本模块:数据采集模块、数据预处理模块和数字图书推荐模块[1]。数字图书推荐系统的简要推荐过程一般可以归为五步:(1)采集图书信息,得到图书数据。(2)通过读者的个性化界面获得读者的行为日志,采集读者的信息数据。(3)将书籍数据和读者数据进行数据预处理。(4)将预处理之后的数据用于数字图书推荐模块,得到最终推荐。(5)把最终推荐结果在用户个性化界面进行显示。本文主要改进的是数字图书推荐模块。
1 数字图书推荐模块
本文主要用基于熵理论的马氏距离与高斯模型的半监督混合聚类算法(SSCMG)和基于马氏距离与主动学习成对约束的半监督模糊聚类(SSFCMAP)相结合,实现数字图书的个性化推荐。
数字图书推荐模块的基本步骤为:
Step 1:将读者行为数据采用数据预处理操作,获得读者的数据矩阵Si;
Step 2:使用SSCMG算法将读者聚类处理,得到读者类C;获得和目标读者同在一个类的其他读者阅读图书的集合矩阵;将书籍矩阵按照借阅次数进行排序,得到矩阵B;
Step 3:将B矩阵中目标读者已经阅读过的书籍进行过滤,得到矩阵R1,则该矩阵就是第一种聚类图书推荐集合;
Step 4:对读者数据矩阵Si进行分析,判断目标读者是否有借阅或点击图书的历史记录,如果有则继续Step 7,否则直接输出R1,并退出算法。
Step 5:获得目标读者借阅或点击图书的集合列表Li;通过SSCFMAP算法对Li集合中的所有图书进行聚类,得到和Li集合里图书同处一类的所有书籍b;按照一定规则(例如相似度计量)对书籍b采取排序操作;得到矩阵bk;
Step 6:将bk矩阵中目标读者已然阅览过的图书进行过滤,得到矩阵R2;则该矩阵就是第二种聚类图书推荐集合;
Step 7:将矩阵R1和矩阵R2进行线性叠加,然后进行处理,包括去除重复书籍和按照阅读量进行排序。最后得到最终推荐结果矩阵R。
2 推荐系统评估方法
推荐系统的评估指标主要有:准确率(Precision)、召回率(Recall)、F值(F-Measure)、E值和覆盖率[2-3]。
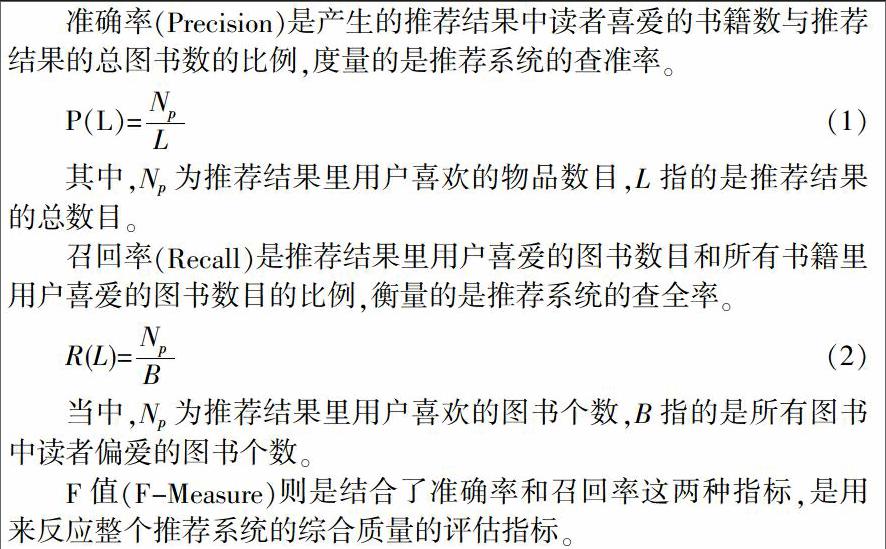
准确率(Precision)是产生的推荐结果中读者喜爱的书籍数与推荐结果的总图书数的比例,度量的是推荐系统的查准率。
其中,Np为推荐结果里用户喜欢的物品数目,L指的是推荐结果的总数目。
召回率(Recall)是推荐结果里用户喜爱的图书数目和所有书籍里用户喜爱的图书数目的比例,衡量的是推荐系统的查全率。
当中,Np为推荐结果里用户喜欢的图书个数,B指的是所有图书中读者偏爱的图书个数。
F值(F-Measure)则是结合了准确率和召回率这两种指标,是用来反应整个推荐系统的综合质量的评估指标。
其中,P指的是准确率,R指的是召回率,α是加权值。
E值表示的是准确率和召回率的加权平均值,也是推荐系统的一个综合指标。
其中,P指的是准确率,R指的是召回率,b是加权值。当b越大的时候,表示查准率占的比重越大。当P和R中有一个为0时,E值等于1。
覆盖率是用于衡量是不是所有的商品都有被推荐的机会。
当F1值越高的时候,产生的推荐结果越准确,推荐系统的机能越高。所以本节采用F1值这一个评估指标对数字图书推荐模型进行测试,评估推荐模型的准确性以及有效性。
3 实验结果
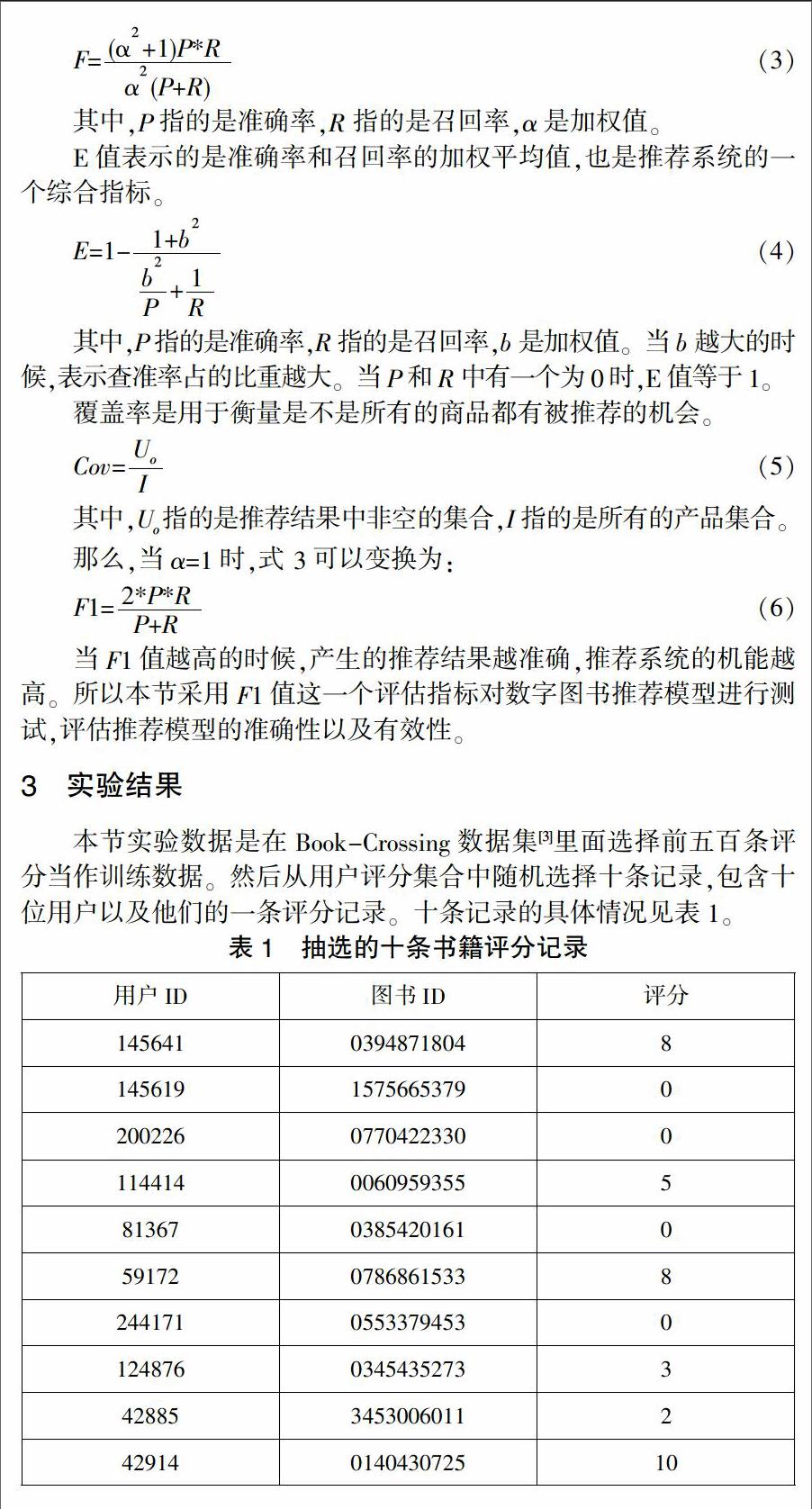
本节实验数据是在Book-Crossing数据集[3]里面选择前五百条评分当作训练数据。然后从用户评分集合中随机选择十条记录,包含十位用户以及他们的一条评分记录。十条记录的具体情况见表1。
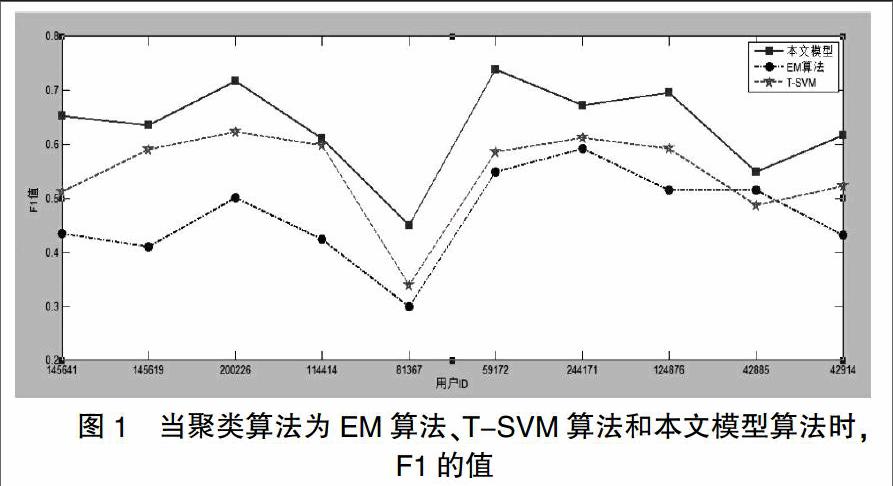
本文使用式6作为推荐系统的测试指标,记为F1。那么表1中的十位用户的F1值如图1所示。
当B值越大的时候,F1值也相应的比较高。B值越大说明读者的信息越多,F1值越大表示推荐系统的推荐质量越好,精度越好。由图1可以看出,相较于EM算法及T-SVM算法,本文构建的推荐系统模型的质量较好。从图1中我们还可以发现当用户有少量的信息之后,的值基本超过百分之六十。其他传统算法的F1值基本不超过百分之六十。说明本章所提出的数字图书推荐模型的推荐效果以及精度相较于其他算法,已经得到了一定的提高。综上所述,本节提出的數字图书推荐模型经过仿真实验,验证了模型的有效性,该模型是切实(下转第132页)(上接第152页)可行的方案。
4 结语
本章提出了基于半监督聚类的数字图书推荐系统模型,而且采取了仿真实验。该模型主要包括三个模块:数据采集模块、数据预处理模块与数字图书推荐模块,主要介绍了数字图书推荐模块,它是核心模块。针对数字图书推荐模块,使用Book-Crossing数据集进行了仿真实验,验证该模块的可行性以及有效性。
【参考文献】
[1]刘莹.数字图书馆应用模型设计[J].商情,2010(23):42-45.
[2]王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,2012,23(1):1-20.
[3]孟祥武,胡勋,王立才,等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[4]徐敏.高校图书馆采访管理系统的设计与实现[D].重庆:重庆大学,2009.
[责任编辑:朱丽娜]
猜你喜欢
今传媒(2022年12期)2022-12-22
南风(2020年22期)2020-09-15
小学生优秀作文(低年级)(2019年5期)2019-04-25
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
办公室业务(2015年6期)2015-11-26
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
