
RFID不确定数据的隐匿方法
2017-07-18 11:57:28王亚男
河北软件职业技术学院学报 2017年2期
王亚男,张 磊
(1.四平农业工程学校,吉林 四平 136100;2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007)
RFID不确定数据的隐匿方法
王亚男1,张 磊2
(1.四平农业工程学校,吉林 四平 136100;2.佳木斯大学 信息电子技术学院,黑龙江 佳木斯 154007)
RFID不确定性数据可通过查询概率值等方式获取或优化,进而达到识别不确定性数据的目的。然而,通过使用RFID不确定性处理方法,管理人员或者查询者很容易得到不确定性数据的真实情况,不确定性数据被识别以后,原有的针对RFID数据所使用的RFID安全协议将不再起作用,攻击者可以很轻松地获取当前标签的隐私数据。针对这一问题,从数据位置、隐匿范围、数据路径等三个方面提出RFID不确定数据的隐匿方法,以此保护潜在的隐私数据。
不确定数据;隐私;隐藏;保护
0 引言
在当前的RFID技术研究中,针对不确定性数据管理的研究逐渐成为热门研究方向。读写器本身以及查询方法等一系列问题,造成RFID数据中存在大量的不确定性数据,这些数据给RFID正常运行带来很多不便,目前的研究主要是使用诸如概率法等方法获取这些不确定性数据,若要查询或者优化这些不确定性数据首先需将数据进行解密,而这势必会对RFID数据隐私带来影响。
本文从RFID不确定性数据的查询优化角度出发,分析当前不确定性数据处理方法的不足之处,针对查询优化后产生的隐私泄漏问题,提出了针对RFID数据位置和数据路径的隐私保护方案,为RFID不确定性数据以及RFID数据安全提出了一个新的研究方向,具有很强的理论意义和实践价值。
1 国内外研究现状
可以通过使用密码学技术制定安全协议来解决RFID数据安全问题[1],而经过RFID解密之后的数据将不再被安全协议所保护,因此对于解密后的RFID数据隐私的保护逐渐被研究者关注,成为一个新的研究方向。当前对于数据库中存储的数据,尤其是经过数据挖掘方法获取的整理后的数据进行隐私保护的研究相对较少,多数研究主要是基于路由保护协议[2]和节点协议[3]展开的。在路由保护协议方面Ying Jian等[3]人提出了追踪数据包定位汇聚节点的模型。在这个模型中,可利用概率路由方法为传输路径提供随机性。每当节点接收到数据包后,就以一定的概率随机选择一个远邻居接点作为下一跳节点,远邻居节点具有随机性,攻击者很难确定数据包的下一条走向是否趋近于汇聚节点。
由于单纯的概率路由算法并不能有效地抵抗追踪数据包攻击,何康[4]在LPR协议中加入了垃圾包策略,就是节点在发送数据包给下一跳节点的同时,随机选择一个远邻居节点并把垃圾包发送给这个节点,接收到垃圾包的节点再用同样的方法将其发送给自己的任意一个远邻居节点。垃圾包的加入会让攻击者在分析数据包流向时追踪到错误的方向,这样LPR协议与垃圾包策略相结合就可以有效地防御追踪数据包定位汇聚节点的攻击。
Mehta K等人[5]也介绍了一种伪造汇聚节点协议。在这个协议中,挑选一些普通传感器被作为假的汇聚节点,并且要求每一个真的汇聚节点的通信范围内有一个假的汇聚节点,传感器只向假的汇聚节点发送数据,并且让所有假汇聚节点发送一条广播消息,确保隐藏真的汇聚节点能收到正确的数据包。
2 RFID不确定数据隐匿所面临的问题
2.1 RFID不确定性数据位置隐匿
对RFID不确定性数据的位置信息进行隐私保护,主要是对产生不确定性数据的RFID标签数据所放置的具体位置进行隐匿。这里与基于位置的服务LBS(Location Based Service)中的位置隐匿有一定的区别,由于当前技术水平的进步,LBS中移动位置服务载体的运行能力具有很大的提高,能够进行较复杂的算法运算。而作为RFID中不确定性数据的载体——标签,在处理能力上还有待进一步提高,当前标签Tag主要分为被动式、半被动式、主动式三大类,其中仅有主动式Tag具有能量来源,也就是说,采用LBS中的位置隐匿方法仅有主动式Tag具有提出位置隐匿的可能。因此需从无能量来源的Tag位置隐匿方向入手,在被读写器(read-write device)读写之后获取隐匿要求,并进行位置混淆的隐匿方式,完成对于RFID不确定性数据的位置隐匿,实现对RFID不确定性数据的隐私保护。
2.2 RFID不确定性数据隐匿范围
2.3 RFID不确定性数据路径隐匿
在对RFID不确定性数据进行位置隐匿的情况下,攻击者可以对获取的RFID不确定性数据所通过的路径信息进行数据挖掘,由此获得RFID不确定性数据位置信息,因此,在进行位置隐匿的同时需要对RFID标签所经过的路径信息进行隐匿。由于RFID标签数据经过的路径具有很强的可追踪性,对于该不确定性数据单纯的采用混淆的方法是不能够满足需求的,需要在有效路径选择的基础上进行混淆,并且当出现当前不存在可混淆路径情况时,能够采用回溯上一位置的方式进行路径隐匿。
3 RFID不确定数据的隐匿方法
3.1 数据位置隐匿
在位置隐匿问题的研究中,最为著名的就是k-匿名模型,它的基本思想是在发布位置的时候,用一个覆盖其它k-1个用户的匿名区域代替用户的真实位置,从而使得位置服务无法从k个用户中鉴别出某个用户。其具体模型如图1所示。

图1 k-匿名模型位置隐匿示意图
图1中A为真实位置,其它点为获取的其他用户位置,方框内其它各点为可代替用户真实位置的混淆位置结点。
在针对数据位置的隐匿中,与位置服务相类似,但是由于数据本身的特殊性要求,所获得的查询数据可以采用两种方式进行位置隐匿。第一种,查询后返回隐匿区域中包括真实结点在内的所有结点中任意一个随机结点作为查询结果;第二种,查询后返回隐匿区域中的所有结点,通过多个类似数据结点达到隐匿目的。
若设定固定的隐匿区域,在实现算法时需要达到满足隐匿要求的结点个数,因此在计算时采用一种聚类的方法将混淆结点收敛到隐匿区域内,这里采用粒子群优化算法来完成收敛操作,其速度和位置更新方程如下:
本文涉及的超声波流量计要求精度等级为1级,管径为50 mm,量程范围为2.0 m3/h~160 m3/h,将比例阈值法和自适应阈值法应用在同一个流量计上进行流量测试,根据超声流量计检定规程《JJG 1030-2007超声流量计》要求在检定过程中每次实际检定流量与设定流量不能超过设定流量的±5%,每个流量点检定次数不应少于3次,因此流量实验中每个流量点稳定时间30 s,测试时间60 s,每个流量点测试3次,利用比例阈值法和利用自适应阈值法的流量实验结果分为表1和表2。
速度方程为:
位置更新方程为:

压缩因子表示为:

其中,φ=c1+c2,φ>4。
在该算法中,pbest为局部极值点,gbest为全局极值点,压缩因子λ的取值范围为:
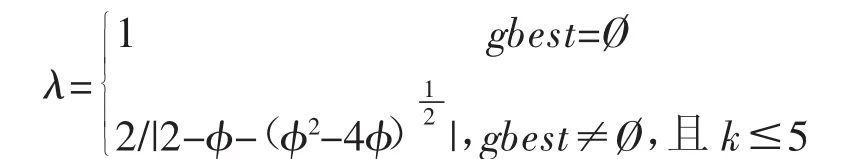
参数r1=r2=(0,1),c1=c2=2.5,初始速度v0=1。
3.2 隐匿范围
数据信息隐匿具有特殊性,其隐匿范围受到当前数据规模以及数据类型等多方面的影响。首先,若整体范围内数据粒子数量无法满足隐匿粒子数量要求,则采用一种生成隐匿粒子的方式,即在当前整体范围内数据粒子数量无法满足隐匿需求时,生成满足隐匿要求数量的混淆数据粒子,通过生成粒子达到隐匿要求;其次,若整体数据范围能够提供满足要求的数据粒子,则根据粒子数量要求,扩大隐匿区域。隐匿区域如图2所示。

图2 隐匿区域示意图
在图2中斜线区域为当前粒子数无法满足隐匿要求情况下增大的隐匿区域。这里需要说明的是,之所以在使用聚类方式增加隐匿粒子数量的同时还需要扩大隐匿区域,是因为在使用聚类方式进行粒子收敛时,依然存在粒子数量无法满足混淆要求的情况。针对这种情况以及数据整体范围无法满足的情况提出该方法。
3.3 路径隐匿
在LBS中的路径隐匿是针对如图3所示的路径情况下提出的,本文针对不确定性数据经过的不同读写、传递路径进行隐匿。
图3 可隐匿路径
在路径隐匿中可以通过不同路径进行混淆,在RFID中受读写器数量、传输通道等的限制,路径可能会是单一的,这就需要采用一种能够按段进行隐匿并产生虚拟路径的运算方式进行隐匿,文中使用了一种旋转虚拟生殖的方式。

图4 路径偏差示意图

图4(a)中的T为数据真实路径,D为产生的虚拟路径,(b)中为经过路径偏差计算后获取的具有偏差值的真实路径和虚拟路径。
4 结论
本文针对RFID不确定数据被优化后可能会造成隐私数据泄露的情况,提出了针对RFID不确定数据隐私保护的隐匿方法。该方法从数据位置、隐匿范围和隐匿路径等方面入手,完善了对RFID不确定数据的隐匿处理,实现了对RFID不确定数据的隐私保护。
[1]黄刘生,田苗苗,黄河.大数据隐私保护密码技术研究综述[J].软件学报,2015,26(4):945-959.
[2]Chun-Ta Li,Chi-Yao Weng,Cheng-Chi Lee.A Secure RFID Tag Authentication Protocol with Privacy Preserving in Telecare Medicine Information System[J].Journal of Medical Systems,2015,39(8):77.
[3]Mohammad Saiful Islam Mamun,Atsuko Miyaji.A privacy-preserving efficient RFID authentication protocol from SLPN assumption[J].International Journal of Computational Science&Engineering,2015,10(3):234-243.
[4]何康.基于物联网的个性化k-匿名位置隐私保护技术的研究和实现[D].南京:南京邮电大学,2012.
[5]Saiyu Qi,Li Lu,Zhenjiang Li,et al.BEST:a bidirectional efficiency-privacy transferable authentication protocol forRFID-enabled supply chain[J].International Journal of Ad Hoc&Ubiquitous Computing,2015,18(4):234-244.
The Anonymous Method of RFID Uncertain Data
WANG Ya-nan1,ZHANG Lei2
(1.Siping Agricultural Engineering School,Jilin Siping 136100,China;2.College of Information and Electronic Technology,Jiamusi University,Heilongjiang Jiamusi 154007,China)
The uncertain data of RFID can be obtained or optimized by the probability of query,and then to achieve the purpose of identifying uncertain data.However,through this type of method to process the RFID data,the management of query users can get the actual circumstances of the uncertain data easily;after the uncertain data are identified, the security protocol used originally in protecting RFID data will be invalid,and the adversary can get the private data of current RFID labels easily.In order to solve this problem, this article puts forward the hiding methods of RFID uncertain data from the data location,hiding scope,data path to protect the potential private data.
uncertain data;privacy;hiding;protecting
TP391.7
A
1673-2022(2017)02-0054-04
2016-12-26
佳木斯大学教育科研课题(2016jw2003)
王亚男(1963-),男,吉林公主岭人,助理工程师,研究方向为信息安全;张磊(1982-),男,黑龙江绥化人,讲师,研究方向为数据安全、隐私保护。
猜你喜欢
法律方法(2022年2期)2022-10-20 06:41:56
中国外汇(2019年7期)2019-07-13 05:45:04
网络安全和信息化(2018年4期)2018-11-09 12:01:54
数学物理学报(2018年1期)2018-03-26 08:16:42
系统工程与电子技术(2016年4期)2016-08-24 07:46:22
中国新通信(2014年11期)2014-09-11 19:27:52
电子设计工程(2014年12期)2014-02-27 11:58:23
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
电子设计工程(2011年24期)2011-06-09 10:15:02
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
