
近红外光谱混合模型定量分析不同物理状态样品的研究
2017-07-12 07:51李鑫宾俊范伟周冀衡陈沃若
分析化学 2017年7期
李鑫++宾俊++范伟++周冀衡++陈沃若
摘要 近红外光谱(NIR)以漫反射模式对非均质样本进行测量时,由于其光谱散射和吸收系数差异较大,建立的校正模型准确性和稳健性较低,因此,本研究提出了一种基于均质样本和模型转移方法建立混合模型的策略,解决非均质样本近红外光谱检测的问题。以烟叶样本为研究对象,分别建立了基于henk专利算法(henk′s)、分段直接标准化(PD)和基于典型相关分析的模型转移算法(CCCA)的烟粉+烟丝、烟粉+烟片混合模型,用于烟丝和烟片样本中烟碱含量的预测。结果表明,混合模型对烟丝和烟片样本的预测均方误差(RMEP)较直接建模分别降低了139%和273%,预测结果有一定的改善,稳健性提高,3种方法中CCCA表现最优。因此,采用近红外光谱均质模型和模型转移方法建立的混合模型对非均质样本的测定具有可行性,有利于在线近红外光谱分析技术的发展,可为近红外光谱模型的共享提供参考。
关键词 校正模型; 均质样本; 不同物理状态; 模型转移; 混合模型
1引 言
近红外光谱(NIR)技术是一种简单、快速、无损的分析方法,已广泛应用于石油、化工、烟草、食品、医药等领域\[1~5\]。漫反射测量是NIR最常用的测量模式,样本状态对测量过程的影响较大。研究表明,非均匀样本的物理状态将会导致光谱散射及吸收系数的变化,从而可能降低模型的准确性和鲁棒性\[6,7\]。因此,NIR校正模型多建立在粉末或均质样本的基础上。而在许多应用中,如在线生产、质量控制、原位分析等\[8~10\],样品都是非均匀状态的,所以为了保证模型长期的可靠性和准确性,可采用模型转移和混合建模的策略修正样品状态变化造成的影响。
目前,研究样品不同物理状态模型转移的文献较少\[11,12\],主要集中于采用单一均质模型预测非均质样本,没有考虑模型包容性的问题。鉴于此,本研究以烟叶为研究对象,进行了烟片、烟丝和烟粉3种物理状态样品之间的模型转移和混合建模研究,采用模型转移方法与混合建模技术相结合的方式建立了基于均质烟粉模型的混合模型,增强了模型的包容性,并成功应用于非均匀烟丝样本和烟片样本中烟碱含量的预测。通过样本不同物理状态间的模型共享研究,以期能提高模型的利用效率,为在线分析、实时检测等提供技术参考。
2实验部分
21实验材料
烟叶样本收集自云南省腾冲县,选取大小、形状较一致的完整烟叶样本85个。烟碱含量根据《YC/1602002烟草及烟草制品总植物碱的测定》行业标准\[11\]使用PULE 3000连续流动注射分析仪(意大利ystea公司)进行测定。
22光谱采集及样本划分
选用ipec BW004光栅扫描型近红外光谱仪(美国B&W ek OptoElectronics公司)进行光谱采集,采用仪器自带的标准漫反射探头垂直紧贴样品进行测量,光谱采集范围为5881~11111 cm
ymbolm@@ 1,平均分辨率为35 nm,扫描次数为32次。进行光谱采集前,先对烟叶进行手工撕叶处理去除烟梗,然后将烟叶剪成500~800 mm2的烟片,用于光谱采集;将烟片用微型切丝机制成宽1 mm的烟丝,待烟丝样测量完毕后将其用旋风粉碎机粉碎,并过60目筛,得到烟叶的粉末状样,烟片、烟丝和烟粉样品均测量6次取平均值,3种不同物理形态的烟叶样品在光谱采集前均置于相对湿度16%、温度25℃的恒温恒湿箱中平衡含水率48 h,所有的光谱采集操作均在室温25℃下进行。
利用Kennardtone法\[14\]对光谱数据进行样本划分:65个样本作为训练集,20个样本作为测试集,由于一般标样都取自训练集,故使用Kennardtone方法从训练集中选择15个样本作为备选标样集。
23模型转移方法
模型转移\[15\]是指通过数学方法建立源机光谱与目标机光谱之间的函数关系,由确定的函数关系对光谱或预测结果进行转换,实现模型的共享和有效利用,常见的光谱模型转移方法有斜率截距算法(BC)\[16\]、专利算法(henk′s)\[17\]、直接标准化(D)\[18\]、分段直接标准化(PD)\[19,20\]和基于典型相关分析的模型转移法(CCCA)\[21\]等。本研究采用henk′s、PD和CCCA对烟叶NIR模型进行转移研究。
231henk′s算法henk′s是一种对光谱波长和吸光度都进行校正的方法。首先进行波长校正,对应于源机所测的标样光谱矩阵的第i个波长点mj,在目标机标样光谱上选择窗口为(k+j+1)大小的光谱段s,k+j+1,分别计算mj与该光谱段每个波长点的相关系数,得到目标机上波长l与源机光谱波长i相关系数ri最大,为使结果更加精确,选取波长l-1、l、l+1与对应的相关系数rl-1、 rl\, rl+1建立一元二次抛物线模型:
由该模型得到目标机上与源机波长i对应的波长i′,待求出所有对应的i′后,用求得的i和i′建立一元二次抛物线波长校正模型:
波長校正后进行吸光度的校正,用插值方法计算目标波长i′的吸光度矩阵s,j,
然后可由最小二乘法计算出saj和sbj。对于未知光谱Ps,un,先用波长校正公式(2)对其波长校正,然后用插值计算s,un, 最后由式(3)得到转移的结果。
232PD算法PD方法是基于D的改进算法,在光谱的模型转移中有广泛的应用,在目标机光谱中取宽度为2k+1窗口的吸光度矩阵Zi:
然后将源机光谱的第i个波长点的吸光度矢量am,j与Zi建立数学模型关系:
用PCR或PL对上式进行求解,将回归系数bi置于矩阵的对角线上,同时将其他元素设为0,则转换矩阵F为:
待转换矩阵F求出后,则目标机上的未知光谱Ps转换成匹配源机上的光谱Pm。
233CCCA算法CCCA是基于典型相关分析(CCA)原理而研发的模型转移算法,由于两组光谱之间反映被测物信息的部分是一致的,且相互之间具有一定的线性相关性,而噪声和干扰信息则是随机的,不具有相关性,因此,通过CCA可以提取两组光谱之间的线性相互依赖关系,并滤除噪声和干扰信息。
假设选择N个光谱作为模型转移的标准光谱,令源机和目标机的标准光谱矩阵分别为m和s,执行CCA后得到的典型向量分别为Wm和Ws,则典型变量Lm和Ls可以分别表示为:
则转换矩阵F1可通过最小二乘法计算得到:
同理,转换矩阵F2为:
将目标机的预测集Ps与典型变量Ws相乘可得到典型变量Ks:
最后利用转换矩阵F1和F2可将Ks转换为能直接在源机模型上进行预测的数据集Pm:
从而实现基于典型相关分析的光谱转移。
24模型评价和软件
文章采用偏最小二乘法(PL)建立回归模型,通过10折交互检验选择最佳潜变量数,将训练均方误差(RMEC)和预测均方误差(RMEP)作为模型性能评价的标准。所有数据处理和计算都采用MALAB 2015a(美国Mathwork公司)完成。
3结果与讨论
31光谱差异分析
在建模前,需对光谱进行相关预处理以消除仪器噪声和其它背景的影响,提高光谱分辨率和灵敏度。经试算,选择avitskyGolay二阶导数与光谱平滑组合预处理的方式,可有效扣除不同仪器间的光谱差异,求导窗口设置为15,平滑窗口为13。
从图1A可知,3种物理状态的样本光谱均发生了漂移,烟粉和烟丝光谱差异较小,三者吸光度的总体变化趋势一致,但是光谱差异不明显。从图1B可知,虽然适当的预处理方法可以减少光谱基线漂移的影响,但不能消除样品状态造成的光谱偏差,经过预处理后,三者光谱之间的差异更加明显,如在8300 cm
ymbolm@@ 1附近,烟片样光谱波谷变宽、高度变小,而在7100和6900 cm
ymbolm@@ 1处,三者波峰波谷高度都不一致。因此,不同物理状态样本的光谱存在一定的偏差和变化,且不能通过预处理消除。
图2为烟草3种物理状态光谱的主成分分析(PCA)得分图,尽管三者主成分得分有一定交集,但不同物理状态之间的差异非常明显,烟粉样的波动范围最小、烟丝样次之、烟片样最大,说明样本物理状态的改变会导致光谱的变化,不同物理状态的样品光谱建模可能会导致模型根本无法使用或预测结果偏差较大。
32PL建模
通过PL建立的烟叶不同物理状态的烟碱预测模型的性能见表1,烟粉模型的整体性能优于烟丝和烟片模型,烟粉模型烟碱的RMEP仅为01490,表明烟粉模型性能较优。烟粉校正模型分别预测烟丝和烟片样中烟碱的RMEP较烟丝和烟片模型的自身预测结果分别增大了3294%和2887%,这主要是由于烟丝和烟片光谱与烟粉光谱差异较大所致。因此,在简单的模型套用效果不佳的情况下, 可以使用模型转移技术对不同物理状态的光谱进行校正,提高烟丝和烟片样本的预测效果。
33模型转移分析
由于henk′s、PD和CCCA都是有标算法,故而在进行模型转移分析时需先对标样数进行优化。标样数太少,会导致校正系数中包含的转换信息不充分;标样数太多,则不方便实际应用,且会增加计算量,甚至还会出现过校正。图3为3种模型转移方法执行光谱转移时最佳标样数的选择。从图3可知,标样数量并非越多越好,随着样本量增加,RMEP值呈先降低后升高的趋势,综合考虑,3个模型的标样数选择14较好。
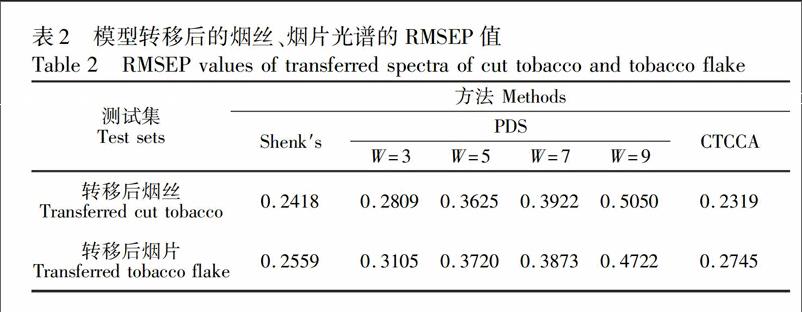
选择最佳标样数后,利用henk′s、PD和CCCA将烟片和烟丝光谱分别转移到烟粉模型上,并对其中的烟碱含量进行预测,从表2可知,经henk′s、CCCA转移后的烟丝、烟片光谱预测结果分别优于其它方法转移后的光谱预测结果,PD的效果最差,且随着窗口增大,效果越差,窗口选择3较好。对表1和表2的结果进行对比可知,将烟丝光谱转移到烟粉模型的预测精度优于将烟片光谱转移到烟粉模型与使用烟粉模型对烟片、烟丝样本直接进行预测的结果相比较,烟片和烟丝的烟碱RMEP最大分别降低了657%和476%,预测结果有所改善,但是较实际应用还有一定差距。因此,单纯采用模型转移方法无法实现烟粉模型对非均质烟丝、烟片样本的准确预测,需要综合考虑样本、模型和模型转移技术的有机结合,以提高非均质样本的预测精度。
34混合模型的建立
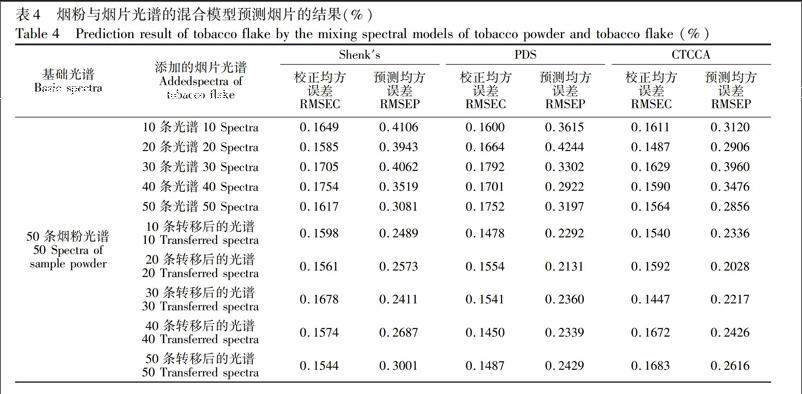
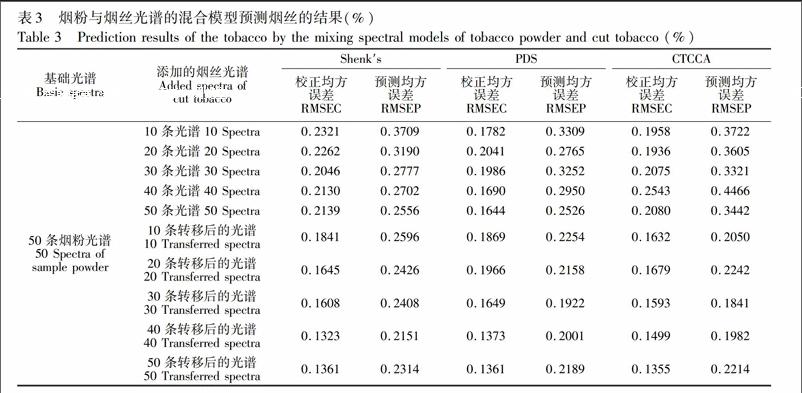
混合建模的策略是指通过在基础模型中增加变异样本的信息建立一个精确和健壮的模型,获得更好的预测能力和更广的预测范围。本实验将烟粉模型作为基础模型,以烟叶样本的不同物理状态为变异,分别添加一定数量的烟丝和烟片样本到烟粉模型中,建立混合模型,表3和表4分别为烟粉+烟丝、烟粉+烟片的混合模型分别对烟丝和烟片样本的预测结果。从表3可知,直接添加预处理的烟丝样本到烟粉样本中,建立的混合模型,其预测能力没有明显提高,与直接使用烟粉模型预测经转移的烟丝样本的预测误差接近。而通过对烟粉模型添加一定数量的经模型转移后的烟丝样品建立的混合模型, 可使模型的稳定性和预测能力提高,其中添加30条CCCA转移后的烟丝样本光谱比直接使用烟粉模型预测烟丝样本的RMEP降低了139%,模型的稳健性增强\[22\]。3种方法预测效果的对比中,CCCA的结果优于henk′s和PD方法。
由表4可知,3种方法的对比分析中,增加20个CCCA转移的烟丝样品建立的混合模型能得到最佳的预测结果。与烟粉模型预测转移后的烟片样本结果相比,混合模型预测性能明显提升,RMEP从02559降低到02028,添加20个CCCA转移的烟丝样品的混合模型预测烟片样本的RMEP较烟片模型预测烟片样本的RMEP降低了273%。因此,增加约20%的烟片样本可以较好地提高混合模型对烟片的预测能力,同时也进一步证明了混合模型的有效性,在基礎模型中添加经模型转移后的样本基本可实现无信息的丢失,达到了良好的预测效果。综上所述,通过向烟粉模型中增加一定量的经转移后的烟丝和烟片样本作为建模集,可以提高模型的稳健性,进而提高对烟丝和烟片样本中烟碱的预测精度。
