
融合统计学和TextRank的生物医学文献关键短语抽取
2017-07-10 10:27:26孙先朋
计算机应用与软件 2017年6期
魏 赟 孙先朋
(上海理工大学光电信息与计算机工程学院 上海 200093)
融合统计学和TextRank的生物医学文献关键短语抽取
魏 赟 孙先朋
(上海理工大学光电信息与计算机工程学院 上海 200093)
关键短语的抽取在文本聚类、分类、检索等方面有着重要的作用。利用经典的TF-IDF算法来提高文本关键短语抽取的质量。通过对TF-IDF算法的研究,发现TF-IDF可以综合利用单个文本信息和文本集合信息抽取文本关键词。在此基础上,提出一种综合TF-IDF、TextRank、统计学知识抽取关键短语的方法和利用候选关键短语逆向文档频率排序的方法。该方法在TextRank基础上,通过TF-IDF引入词的文本集合信息计算词之间权重得到词的得分。然后利用统计学知识从上一步选出词组成的短语筛选出候选关键短语。最后利用逆向文档频率的思想对候选关键短语排序。实验证明,该模型相比于经典TextRank模型准确率提高了2%,召回率提高了4.5%,F-measure提高了3.4%。
TextRank 关键短语抽取 TF-IDF 逆向文档频率
0 引 言
关键词抽取技术是信息处理领域的核心技术。对于生物医学文献,由于人工标记关键词的随机性、专业词汇较多、语言结构复杂、数据量大等原因,需要一种基于全文的自动化抽取生物医学文献关键词的方法来建立更加科学的文本分类方法。
目前常用的无监督关键词抽取方法主要是LDA[1]、TF-IDF[2]、TextRank[3]。从三者的算法原理上看,LDA和TF-IDF均没有考虑词在文本中的顺序,因此不适合直接抽取文本关键短语。而TextRank算法,Rada Mihalcea等已经证明了其抽取关键短语短语的可行性。针对TextRank算法的改进模型有很多,一种是TextRank结合主题模型的方法[4-5],但是该种方法需要事先选定高质量的训练集。一种是对TextRank加权的方法[6-7],文献[6]将窗口中共现词的频率作为二元共现词之间的权重,该方法更加偏好高频词。文献[7]将时间表达式加入到TextRank权重计算中,但该方法会增强不相连接词间的关系。在使用TextRank抽取出候选关键短语后,接下来短语紧密程度的判定和候选短语排序。目前常用的判定方法主要是频率、互信息、信息熵、边界多样性以及 统计等[8-10]方法。使用统计学方法可以去掉紧密程度不高的短语,从而增强抽取关键短语的准确率。常用的候选短语排序方法是用候选短语包含关键字的得分之和代表候选短语得分,文献[6]修正了上述方法对候选短语中包含一个分值更高而错误排序的情况,但是该排序方法更加偏好短语而降低了一元短语的重要性。
综上所述,本文基于生物医学文献全文使用TF-IDF优化的TextRank算法抽取候选关键短语,并使用频率、互信息、边界多样性对候选关键短语筛选,然后提出了将逆向文档频率引入候选关键短语排序方法,从而达到优化抽取生物医学文献短语关键词的目的。
1 基于TextRank的关键短语抽取模型
本文模型主要包括三个核心步骤:(1) 一元短语抽取,利用TF-IDF优化的TextRank算法抽取一元短语;(2) 二三元短语抽取,遍历生物医学文献全文找出相连的一元短语和一元短语中夹有停用词的短语,然后利用从统计学知识对其中二三元短语筛选;(3) 候选关键短语排序,将(2)中得到的二三元短语和其不包含的一元短语使用本文提出的排序方法排序取排名靠前作为关键短语。图1为本文模型关键短语抽取流程图。

图1 关键短语抽取流程图
1.1 一元短语抽取
TF-IDF是面向多文档的关键词抽取方法,他通过词的频率信息和词在文本集合中的信息得到词在文本中的重要性。TF-IDF公式为:
(1)

TextRank是衍生于PageRank的基于图结构的以推荐形式抽取文本关键词的算法。Rada Mihalcea等首先将TextRank算法引入到文本挖掘领域,证明了其抽取文本关键短语的可行性。TextRank将文本看作是G(V,E)的形式,V表示文本中的词,E为词语之间的边。通过设定窗口的大小,窗口内建立图结构迭代计算直至收敛后得到词的得分。TextRank公式如下:
(2)

Textrank强调两个词之间的联系,而且传统TextRank算法人为设定词之间都赋予相同的初始权重,并仅利用了文本本身的信息。经过以上考虑,本文提出了一种新的TF-IDF对TextRank加权的方法,该方法将词的推荐能力和文本集合的信息加入到TextRank算法中。例如,图2由{A,B,C,D,E}五个词组成的候选关键词图,圆圈上部分为词,下部分为词的TF-IDF值。
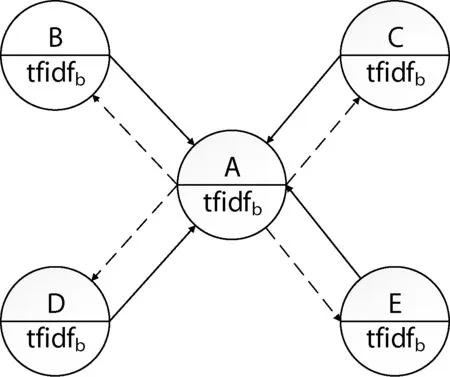
图2 候选关键词图示例
在图2中,传统TextRank算法会赋给与相连的词之间相同的权重,默认为1。而本文方法则考虑到词的推荐能力不同,如A、B之间,计算词A的得分时和计算词B的得分时它们之间的权重是不同的。计算A指向B的权重时,首先计算与A相连的词(包含B)的TF-IDF值之和,然后计算B的TF-IDF值占与A相连词的TF-IDF值之和的比例值,将该值作为A指向B的权重,同理可得B指向A的权重。权重计算公式如下:
(3)
式中:wij表示词j指向词i的权重,tfidfi表示词i的TF-IDF值,Inj表示与词j相连的词集合。
1.2 二三元短语抽取
抽取出候选关键词后,在全文找出相连的候选关键词组成候选短语。但是此时的候选短语存在许多问题,比如紧密程度不够、重要性低等,需要相应的方法对此时的候选短语筛选。本文使用短语频率、互信息和边界多样性判定短语。公式分别如下:
tfp≥times
(4)
式中:其中tfp是短语p出现的次数,times是人工设定的短语出现最低次数。
(5)
式中:MIxy为短语xy的互信息,p(xy)为短语xy出现的概率,p(x)、p(y)分别为词x、y出现的概率。
(6)

为了使选出的关键短语更能体现文本的内容,需要对短语频率、互信息、边界多样性设定相应的阈值,去掉频率低和紧密程度不高的短语,判断条件如下:
MIxy≥MI
(7)
式中:MI为短语的互信息阈值。
Ap≥A
(8)
式中:A为短语的边界多样性阈值。
1.3 候选关键短语排序
生物医学文献中的关键词主要是短语和单个词,本文的目标是抽取出包含一元短语的文本关键短语。对候选关键词排序是非常重要的部分,因为选择出来的候选关键词往往数量比较多,而我们必须从其中选择10~15个[11]作为文本的关键词。而使用Abdelghani Bellaachia提出的排序方法不能满足本文的要求。生物医学文献中关键短语的长度一般小于四个词(四元以上的短语一般会以简写表示),因此本文只统计三元之内(包含三元)的短语。TF-IDF算法中,IDF的思想是若一个词在一篇文本中出现的次数多但在文本集合中其他文本中出现的次数少则证明此词对该文本越重要,同理本文将该思想用于短语排序。但是由于短语越长频率越低,本文对短语频率取对数降低频率的影响力,然后对不同长度的短语赋予不同的权重的方法对短语排序。公式如下:
scorep=α×logtfp×idfp
(9)
式中:scorep为短语p的得分,tfp为短语p的频率,idfp为短语的逆向文档频率,α∈(0,1)为短语权重,α参数经过实验得来。
2 仿真实验
2.1 实验数据和相关工具
本文所用的数据为英文生物医学文献,从PubMed数据库中随机下载574篇文献。开发语言Java,分词工具Lucene 5.5.0,句法分析工具Opennlp。
2.2 评价标准
本文使用常用的准确率(P)、召回率(R)、F-measure作为判定标准。公式分别如下:
(10)
(11)
(12)

2.3 实验结果及分析
本文通过研究100篇生物医学文献数据在参数α取不同的值时P、R、F-measure的变化,得出不同长度的短语的参数取值,如表1所示。

表1 短语参数取值
本文将传统TextRank算法和TF-IDF加权的TextRank算法对比分析,同样适用P、R、F-measure作为判定标准。对两种方法选择同样的参数,分别如下:一元短语数量N1=60,短语频率times=3,互信息阈值MI=7,边界多样性阈值A=0。对比两种方法取不同数量的关键短语时的P、R、F-measure图像,如图3-图5所示。

图3 准确率对比

图4 召回率对比
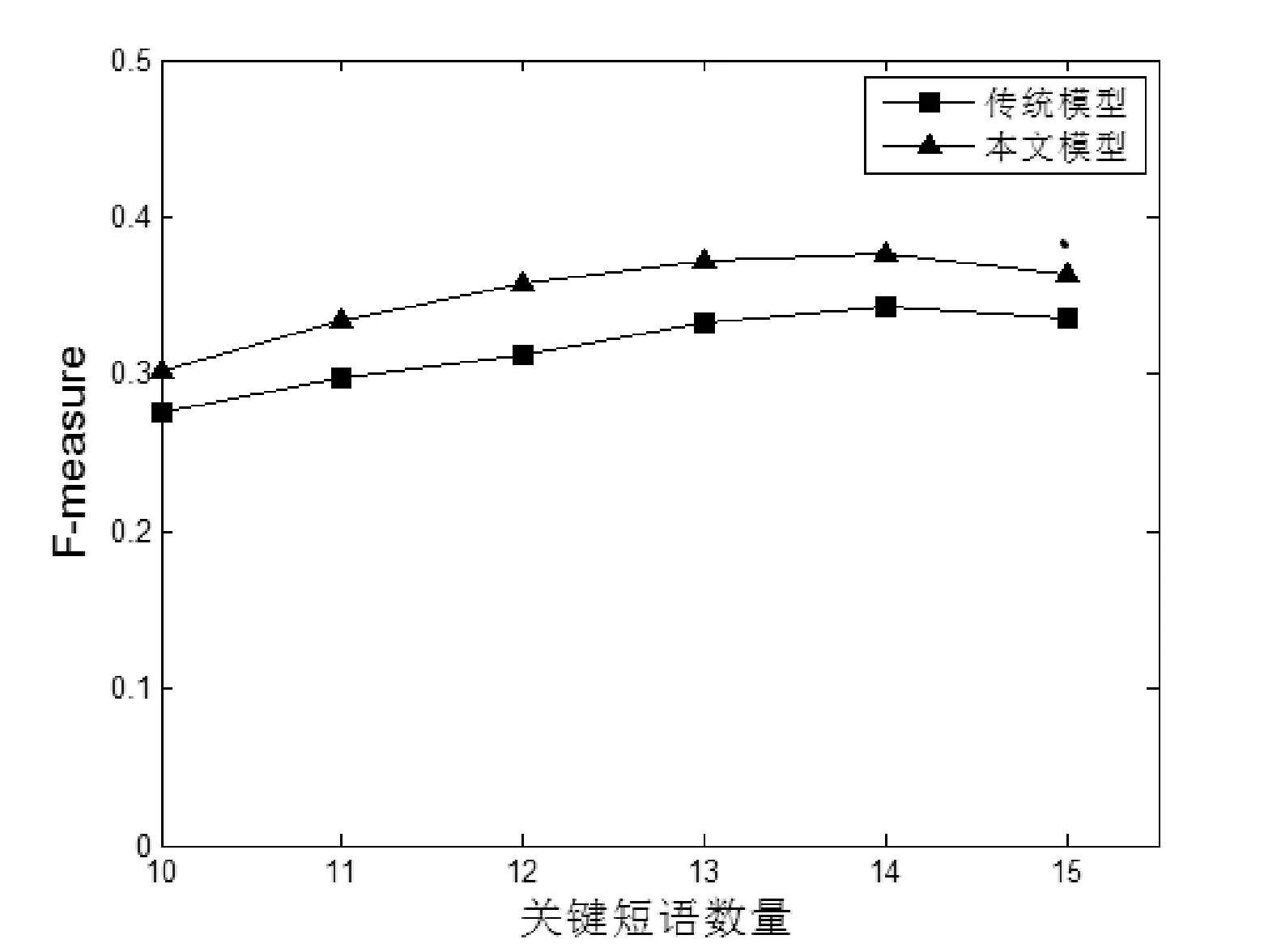
图5 F-measure对比
通过观察图3-图5可以发现,在取相同数量的关键词时,本文方法相比于传统的Textrank算法在准确率、召回率、F-measure上均有提高。而且可以发现当候选关键短语数量N2=14时,P、R、F-measure值最大,因此本文选择候选关键短语数量为N2=14。候选关键短语数量确定后,两种方法在P、R、F-measure的结果如表2所示。

表2 传统模型和本文模型的结果对比
从表2可以看出,本文优化的Textrank方法在准确率上提高了2%,召回率提高了4.5%,F-measure提高了3.4%
3 结 语
本文针对生物医学文献数据的特点,提出了使用TextRank算法抽取生物医学文献关键词的方法。并针对TextRank算法只依靠文档自身信息和词之间的推荐能力没有差异性的特点,提出了使用TF-IDF对TextRank优化的方法。并结合统计学方法达到抽取生物医学文献关键词目的。但是本文对短语权重的赋值还存在缺点。下一步的主要工作修正短语权重和进一步对文本聚类研究。
[1] Blei D M,Ng A Y,Jordan M.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[2] Gerard Salton.Developments in automatic text tretrieval[J].Science,1991,253:974-980.
[3] Mihalcea R,Tarau P.TextRank:Bringing Order into Texts[C]//Conference on Empirical Methods in Natural Language Processing,EMNLP 2004,A Meeting of Sigdat,A Special Interest Group of the Acl,Held in Conjunction with ACL 2004,25-26 July 2004,Barcelona,Spain.DBLP,2004:404-411.
[4] 田长波,林民,斯日古楞.融合PAM和主题偏好TextRank 的历史沿革信息抽取[J].计算机应用研究,2017(1):129-133.
[5] Bellaachia A,Aldhelaan M.NE-Rank:A Novel Graph-Based Keyphrase Extraction in Twitter[C]//IEEE/WIC/ACM International Joint Conferences on Web Intelligence.ACM,2012:372-379.
[6] Zhu Z,Li M,Chen L,et al.Combination of Unsupervised Keyphrase Extraction Algorithms[C]//International Conference on Asian Language Processing,2013:33-36.
[7] 赵佳鹏,林民.基于维基百科的领域历史沿革信息抽取[J].计算机应用,2015,35(4):1021-1025.
[8] 刘海峰,姚泽清,苏展.基于词频的优化互信息文本特征选择方法[J].计算机工程,2014,40(7):179-182.
[9] Magerman D M,Marcus M P.Parsing a natural language using mutual information statistics[C]//Eighth National Conference on Artificial Intelligence.AAAI Press,1990:984-989.
[10] 刘荣,王奕凯.利用统计量和语言学规则抽取多字词表达[J].太原理工大学学报,2011,42(2):133-137.
[11] Popova S,Danilova V.Keyphrase Extraction Abstracts Instead of Full Papers[C]//International Workshop on Database and Expert Systems Applications.IEEE,2014:241-245.
FUSION OF STATISTICS AND TEXTRANK FOR KEYPHRASE EXTRACTION IN BIOMEDICAL LITERATURE
Wei Yun Sun Xianpeng
(SchoolofOptical-electricalandComputerEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)
Keyphrase extraction plays a significant role in text clustering, classification, retrieval and so on. This paper uses the classic TF-IDF algorithm to improve the quality of text keyphrase extraction. By studying the TF-IDF algorithm, it is found that the TF-IDF can extract the text keywords by using the single text information and the text collection information. On this basis, this paper proposes a keyphrase extraction method by combining TF-IDF, TextRank, statistical knowledge and inverse document frequency sorting by candidate keyphrase. Based on the TextRank, this method calculates the weight of the words by TF-IDF to get the word score. And then use the statistical knowledge from the previous step to select the phrases of the phrase selected candidate keyphrases. Finally, the candidate keyphrases are sorted by the idea of inverse document frequency. Experiments show that the accuracy of this model is 2% higher than that of classical TextRank model, and the recall rate increased by 4.5% and F-measure increased by 3.4%.
TextRank Keyphrase extraction TF-IDF Inverse document frequency
2016-06-30。国家自然科学基金项目(61170277);上海市教委科研创新基金项目(12YZ094)。魏赟,副教授,主研领域:智能交通,对等网络,分布式系统。孙先朋,硕士生。
TP311
A
10.3969/j.issn.1000-386x.2017.06.006
猜你喜欢
科学与社会(2022年4期)2023-01-17 01:20:04
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科学与社会(2021年4期)2022-01-19 03:29:50
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
图书馆建设(2018年5期)2018-07-10 09:46:44
儿童绘本(2018年5期)2018-04-12 16:45:32
照明工程学报(2016年3期)2016-06-01 12:17:54
