
基于半监督学习的客户信用评估集成模型研究
2017-07-08 09:31黄静薛书田肖进
软科学 2017年7期
黄静 薛书田 肖进
摘要:将半监督学习技术与多分类器集成模型Bagging相结合,构建类别分布不平衡环境下基于Bagging的半监督集成模型(SSEBI),综合利用有、无类别标签的样本来提高模型的性能。该模型主要包括三个阶段:(1)从无类别标签数据集中选择性标记一部分样本并训练若干个基本分类器;(2)使用训练好的基本分类器对测试集样本进行分类;(3)对分类结果进行集成得到最终分类结果。在五个客户信用评估数据集上进行实证分析,结果表明本研究提出的SSEBI模型的有效性。
关键词:信用评估;类别分布不平衡;半监督学习;Bagging;半监督集成
DOI:10.13956/j.ss.1001-8409.2017.07.28
中图分类号:F83046;TP18 文献标识码:A 文章编号:1001-8409(2017)07-0131-04
Semisupervised Learning Based Multiple Classifiers
Ensemble Model for Customer Credit Scoring
HUANG jinga, XUE Shutianb, XIAO Jinb
(a. Public Administration School; b.Business School,Sichuan University, Chengdu 610064)
Abstract:This paper combines semisupervised learning with multiple classifiers ensemble model Bagging, and proposes a semisupervised ensemble model based on Bagging for imbalanced data (SSEBI), which is expected to improve the model performance by comprehensively using samples with and without class labels. This model includes the following three phases: (1) Selectively label some samples from the data set without class labels and train several base classifiers; (2) Classify samples in test set by the trained base classifiers respectively; (3) Obtain the final classification results with integrating the classification results of all the base classifiers. Empirical analyses are conducted in five customer credit scoring data sets, and the results show the effectiveness of the SSEBI model.
Key words:credit scoring; imbalanced class distribution; semisupervised learning; Bagging; semisupervisedensemble
引言
随着我国经济的快速发展,人们的消费方式也在发生改变,住房按揭、汽车贷款、信用卡等信用消费规模不断扩大,信用交易已经成为市场经济条件下重要的交易方式。但是信用交易迅速发展的同时也带来了越来越多的信用欺诈行为,给商业银行带来巨大的损失。如何准确而有效地预测客户可能发生的恶意信用欺诈行为,必须依赖已有的数据对客户进行信用评估。
客户信用评估是依据客户信用欺诈风险的大小来划分客户的信用等级[1]。传统的信用评估模型有神经网络、logistic回归、贝叶斯、进化计算、k-近邻、遗传规划和支持向量机(support vector machine,SVM)等,为客户信用评估建模的研究做出很大贡献。但由于客户信用评估数据集通常是薄靶、类别分布不平衡的,即信用好的客户样本数要远高于信用差的客户样本数;如果继续采用上述传统信用评估模型来对客户进行分类,就会造成信用差的少数类客户较高的错误分类率[2]。就给企业带来的损失而言,错误分类一个少数類客户会高于错误分类一个多数类客户。
目前用于处理信用评估数据集中类别分布不平衡问题的方法主要有两类:数据层次方法,即重抽样技术[2];算法层次方法,主要是代价敏感学习[3]。即使使用这些技术,单一客户信用评估模型也很难准确分类整个样本空间。但是如果采用多分类器集成,即将多个单一分类模型的分类结果集成,客户信用评估模型的有效性将有望提升[4,5]。如Paleologo等在多分类器集成模型Bagging的基础上提出Subagging信用评估模型,取得较好效果[6]。
上述研究为客户信用评估做出了重要贡献,但分析发现,都属于监督式的分类建模范式,即仅使用原始有类别标记的训练集来训练分类模型,但在现实中很多信用评估问题,有类别标记的样本数是远少于无类别标记的客户样本数的。如果仅使用少量有类别标记的样本而舍弃大量无类别标记的样本来建模,即监督式建模范式,会造成大量有用信息的浪费,使模型性能得不到大的提升。
在机器学习领域新兴的半监督学习(semi-supervised learning,SSL)有效地解决了这个问题[7]。其中比较有代表性的方法是由Blum和Mitchell[8]提出的协同训练模型(Co-training);Zhou和Li[9]提出的半监督集成模型:Tri-training;王娇等[10]构建的基于随机子空间的半监督协同训练模型(Random SubspacebasedCO-training,RASCO);Hady和Schwenker[11]提出的基于投票的协同训练算法(Co-training by committee,CoBC);苏艳等[12]提出的基于动态随机子空间的协同训练模型(Dynamic Random Subspace based CO-training,DRSCO)。深入研究这些半监督式学习模型,发现除了tri-training和CoBC,其他模型没有考虑数据集的类别分布不平衡性对其性能的影响,在选择性标记样本后还是构建单一分类模型作为最终分类模型。因此已有的半监督式学习模型在现实信用评估问题中难以取得广泛应用。
综上所述,本文将集成学习中应用广泛的Bagging算法[13]跟半监督学习相结合,构建了类别分布不平衡环境下基于Bagging的半监督集成模型(Semi-Supervised Ensemble model based on Bagging for Imbalanced data,SSEBI)。实证分析结果表明本文所提出的SSEBI模型不仅具有良好的选择性标记样本机制,同时也具有优异的信用评估性能。
1SSEBI模型
11模型构建的基本思路
本文提出的SSEBI模型的建模过程主要包括以下3个阶段:(1)构建N个基本分类器;(2)使用训练好的N个基本分类器对测试集中的样本进行分类;(3)对分类结果集成得到最终的分类结果。
12平衡数据集类别分布
本文采用数据层次方法即重抽样技术来平衡数据集的类别分布。随机向下抽样技术和随机向上抽样技术均是常用的重抽样技术,但是这两种重抽样方法均有不足之处,随机向下抽样则是最终的训练集样本数目很少,随机向上抽样会导致少数类中重复样本太多。所以本研究采用随机向上抽样和随机向下抽样相结合,提出一种混合抽样方法来平衡数据集类别分布,假设数据集中有n1个多数类客户样本,有n2个少数类客户样本,将其中的多数类客户样本随机向下抽样至ceiln1+n22个,将少数类客户样本随机向上抽样至ceiln1+n22个,其中ceil( )是向上取整函数。
13详细建模步骤
输入:N:基本分类器个数,K:计算被标记样本的标记置信度时从原始有类别标记的训练集L中为样本选取的近邻样本个数(标记置信度=k/K,k为与样本预测类别标记相同的近邻样本个数),Theta:标记置信度阈值,p:U中被选择性标记的样本的比例。
输出:测试集Test的分类结果。
初始化:L′=L,Q=Φ,i=1。
阶段1:构建N个基本分类器
(1)计算U中被选择性标记样本集Q中样本个数占U中全部样本的百分比b=size(Q)/size(U),若b>p,转到步骤(5);
(2)混合抽样L′平衡其类别分布,并训练SVM、logistic回归和朴素贝叶斯3个分类模型;
(3)使用训练好的3个分类模型来预测U中样本类别标签,并将预测类别一致的样本放置于候选集Uj中,同时计算Uj中每个样本的标记置信度;
(4)从Uj中选用标记置信度大于Theta的样本添加到L'中,同时也将它们添加到Q中;
(5)使用Bootstrap抽样技术从L′中抽取一个训练子集,并使用混合抽样平衡其类别分布;
(6)训练一个BP神经网络作为基本分类器Ci,若i 阶段2:对测试集中的样本进行分类 (7)使用分类器池中的N个基本分类器C1,C2,…,CN分别对测试集Test中的样本进行分类得到分类结果R1,R2,…,RN。 阶段3:对分类结果集成得到最终的分类结果 (8)采用多数投票法将R1,R2,…,RN进行集成得到最终的分类结果。 2实证分析 为了分析本研究SSEBI模型的性能,本文选取5个信用评估数据集进行实验。同时,比较分析SSEBI模型和已有的监督式(Subagging和RSS[14])和半监督式分类模型(CoBag,TritrainingCoBag,Tritraining,RASCO和DRSCO)的信用评估性能。 21数据集介绍 本文在5个信用评估数据集上进行实验(见表1)。根据5个数据集均包含的类别标签,将全部的样本划分为少数类样本(信用差的样本)和多数类样本(信用好的样本)。5个数据集的正负样本比例见表1最后一列,可知5个数据集均属于类别分布不平衡数据集。 22实验设置 對于本研究中所使用的数据集,均按照3:3:4的比例将其随机划分为训练集L、无类别标记的数据集U和测试集Test3个子集。 在本文中,为了保证比较的公平性,SSEBI模型和其他参与比较的模型均采用BPerrorbackpropagation神经网络作为基本分类器。进一步地,在SSEBI模型中当p=06,Theta=055,N=40,K=9时模型的信用评估性能达到最佳,因此,除非特别说明,p,Theta,N和K这4个参数均保持在该数值。 最后,所有实验均是在MATLABR2014a软件平台上编程实现,每一种模型的分类结果均是5次实验结果的平均值。 23评价准则 本文采用ACCaccuracyrate和AUC(areaunderthe ROCcurve)准则对模型性能进行评估。 (1)ACC准则 ACC是指每一种半监督式模型对无类别标记数据集U中样本类别标记的准确率,即U中被正确标记的样本在全部被标记样本中所占的比率,其定义如下: ACC=f1f2(1) 其中,f1表示无类别标记数据集U中被类别标记正确的样本个数,f2表示U中被选择性标记的全部样本个数。 (2)AUC准则 由于现实的信用评估数据集的类别分布都是高度不平衡的,此时通过计算模型在测试集上的总体分类精度来评价模型信用评估性能的方法已不太实用,而ROC(receiver operating characteristic curve)曲线恰好能够解决这个问题。但直接采用ROC曲线来比较不同模型的性能会带来诸多不便,因此使用AUC(area under the ROC curve)值来比较模型的分类性能优劣是一个更好的选择。
24模型性能比较分析
241模型的ACC值比较分析
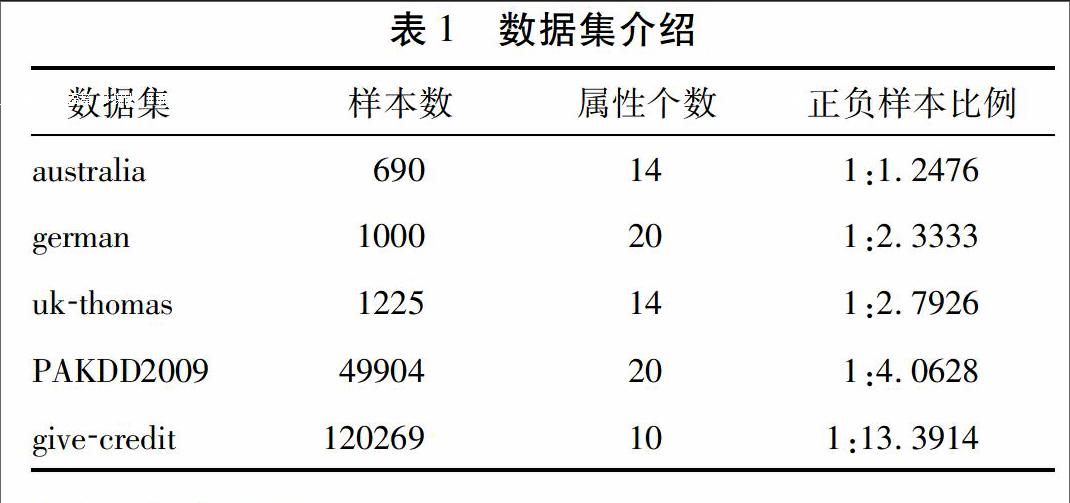
在本文中ACC是指分类模型对无类别标记数据集U中样本类别标记的准确率,因此参与比较的模型必须为半监督式分类模型。表2给出了本文提出的SSEBI模型与其他4種半监督式分类模型的标记准确率,即ACC值。在各个数据集上取得的最大标记准确率均已加粗表示。括号内为在相应数据集上取得的ACC值排名,排名越小,模型的选择性标记样本机制越好,表的最后一行表示5个模型在5个信用评估数据集上的平均排名。
分析实验结果,可以得到以下结论:
(1)从表2可以看出,本文提出的SSEBI模型在ukthomas信用评估数据集上取得了最大的ACC值,在german、PAKDD2009和givecredit信用评估数据集上取得的ACC值仅低于RASCO模型或Tritraining模型。从表2最后一行可知,SSEBI模型平均排名为20,仅低于Tritraining模型,表明SSEBI模型具有良好的选择性标记样本机制。
(2)从表2中5个数据集上的平均排名来看,SSEBI模型和RASCO模型的选择性标记样本机制要优于CoBag和DRSCO模型。其原因可能是因为初始有类别标记训练集L中的样本个数较少,难以训练出分类性能很高的基本分类器,此时即使采用协同训练的方法也会错误标记U中的样本,从而人为地引入了更多的噪声,降低了模型的分类性能。而SSEBI和RASCO模型在对U中样本选择性标记过程中,都对被标记样本进行了剪辑操作,剔除一部分噪声样本,从而提高其选择性标记样本的正确率。
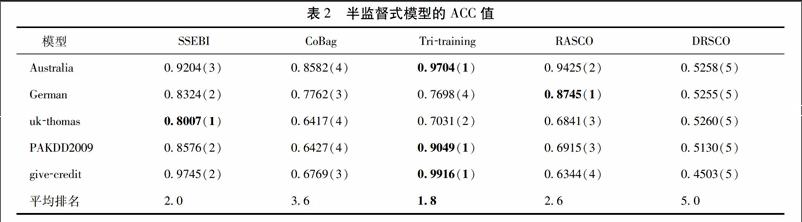
242模型的AUC值比较分析
本文提出的SSEBI模型与参与比较的其他6种分类模型在5个信用评估数据集上得到的AUC值如表3所示。根据表3,可以得到以下3个结论:
(1)SSEBI模型在australia、ukthomas、PAKDD2009 3个信用评估数据集上取得了最大的AUC值,在german和givecredit两个信用评估数据集上取得的AUC值仅低于CoBag模型或RSS模型。同时,从平均排名上来看,SSEBI模型的AUC值平均排名为14,是最小的。因此,SSEBI模型的整体分类性能要优于其他6种模型。
(2)从5个信用评估数据集上的平均排名来看,本文所提出的SSEBI模型以及CoBag模型的平均排名都要小于两种监督式模型Subagging和RSS模型,且SSEBI、CoBag、Subagging和RSS模型均属于集成模型。这表明半监督学习,即综合使用有无类别标记的样本来增强模型的学习,确实可以提升模型的信用评估性能。
(3)从表3中还可以看出,SSEBI和CoBag模型在5个信用评估数据集上取得的AUC值均要大于RASCO和DRSCO模型的AUC值,且Tritraining模型在5个信用评估数据集上的平均排名也要低于DRSCO模型。这可能是因为SSEBI、CoBag和Tritraining模型都属于半监督式集成分类模型。本文提出的SSEBI模型在迭代选择性标记样本的同时构建了多个基本分类器,CoBag模型在选择性标记样本后根据最终得到的训练集分别训练了多个基本分类器,Tritraining模型也训练了3个基本分类器来迭代选择性标记样本,然后再对测试集中的样本进行集成分类。而RASCO和DRSCO模型在选择性标记样本后只构建了单个分类器对测试集中的样本进行分类。这一结果表明,在一般情况下半监督式集成分类模型的信用评估性能优于半监督式单一分类模型。
3结论
本文针对信用评估中的实际问题,在类别不平衡环境下,结合半监督学习和集成方法中应用较为广泛的Bagging算法,构建了基于Bagging半监督集成分类模型SSEBI,并将模型用于客户信用评估。在5个客户信用评估数据集上与两种常用的监督式集成模型和4种已有的半监督式模型进行的比较显示,SSEBI模型具有良好的选择性标记样本机制,具有优异的信用评估性能。
参考文献:
[1]Orgler Y E. A Credit Scoring Model for Commercial Loans[J]. Journal of Money, Credit and Banking,1970,2(4):435-445.
[2]Marqués A, García V, Sánchez J. On the Suitability of Resampling Techniques for the Class Imbalance Problem in Credit Scoring[J]. Journal of the Operational Research Society,2013,64(7):1060-1070.
[3]邹鹏, 李一军, 郝媛媛. 基于代价敏感性学习的客户价值细分[J]. 管理科学学报,2009,12(001):48-56.
[4]Xiao J, He C Z, Jiang X Y, et al. A Dynamic Classifier Ensemble Selection Approach for Noise Data[J]. Information Sciences,2010,180(18):3402-3421.
[5]肖进, 刘敦虎, 顾新, 等. 银行客户信用评估动态分类器集成选择模型[J]. 管理科学学报,2015,3:10.
[6]Paleologo G, Elisseeff A, Antonini G. Subagging for Credit Scoring Models[J]. European Journal of Operational Research, 2010,201(2): 490-499.
[7]Zhu X. Semi-supervised Learning Literature Survey[A]. Technical Report 1530[R/OL]. Department of Computer Sciences, University of Wisconsin at Madison, Madison, WI, 2006. http://www.cs.wisc.edu/?jerryzhu/pub/ssl survey.pdf.,2006.
[8]Blum A, Mitchell T. In Combining Labeled and Unlabeled Data with Co-training[C]. Proceedings of the Eleventh Annual Conference on Computational Learning Theory, ACM: 1998.92-100.
[9]Zhou Z H, Li M. Tri-training: Exploiting Unlabeled Data Using Three Classifiers[J]. Knowledge and Data Engineering, IEEE Transactions on,2005,17(11):1529-1541.
[10] 王娇, 罗四维, 曾宪华. 基于随机子空间的半监督协同训练算法[J]. 电子学报,2008,36(12): 60-65.
[11]Hady M, Schwenker F. In Co-training by Committee: A New Semi-supervised Learning Framework[C]. Data Mining Workshops, ICDMW'08. IEEE International Conference on, IEEE: 2008.563-572.
[12]苏艳, 居胜峰, 王中卿, 等. 基于随机特征子空间的半监督情感分类方法研究[J]. 中文信息学报,2012,26(4):85-90.
[13]Breiman L. Bagging Predictors[J]. Machine Learning,1996,24(2):123-140.
[14]Ho TK. The Random Subspace Method for Constructing Decision Forests[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on,1998,20(8):832-844.
(責任编辑:石琳娜)
