
并行LDA主题模型在电力客服工单文本挖掘中的应用
2017-06-30 09:25陈亮王刚王震
科技创新导报 2017年12期
陈亮+王刚+王震

摘 要:为提升电力客户服务质量,在进行电力客服工单文本挖掘时,对工单文本首先进行切词,然后应用分布式内存计算框架构建并行LDA主题模型,对工单进行文本主题分析。使用国网公司某网省电力客服工单进行了主题分析,结合业务专家经验确定主体数k=10较合适,结果表明分布式内存计算框架下的并行LDA主题模型可以应用于客服工单的文本挖掘。
关键词:工单文本挖掘 并行LDA 分布式内存计算
中图分类号:F407.61 文献标识码:A 文章编号:1674-098X(2017)04(c)-0245-05
Abstract:Applicate distributed computing framework to construct parallel theme LDA model, then modeling power customer service work order text theme. Use SGC a net province electric power customer service work order are analyzed in the text theme, calculation results show that the distributed memory parallel theme LDA model under the framework of text mining can be applied to customer service work order.
Key Words:Worksheet semantic analysis; Parallel LDA; Distributed memory computing
優质服务是一切企业生存与发展的基础和前提。国家电网公司将电力的优质服务定位成“国家电网的生命线”,足见其对于电力企业的重要作用。国网某省公司为充分发挥电力客户服务中心“对客户服务的窗口作用、对市公司的桥梁作用、对业务部门的决策支撑作用、对供电服务质量的监督作用”,基于国网南中心办结与转派的海量工单数据,对分散在95598日常业务工单中的用户诉求与供电服务质量的关系进行全方位、多维度、多层次的统计分析。依托现有国网95598系统、营销业务系统等数据,通过95598模块优化提升,对营业普遍和专题性问题、客户服务效率问题、客户服务满意度提升方面进行深入分析,探究客户用电服务中的共性问题以及分布、趋势和原因,挖掘用户用电的普遍性规律,找出用户用电过程中敏感的、重点关注的,受行为习惯、外界因素影响的深层次原因。进一步挖掘分析业务处理各流程环节的短板、问题和原因所在,将加强各类业务督办和服务协同,提升95598业务服务能力,提高客户服务质量。
该文的方法首先将电力客服工单文本根据自建的电力关联词库及非关联词库进行文本切词,然后在分布式内存计算框架下构建并行LDA主题模型,最后利用该模型进行文本主题挖掘,得到电力客服工单的主题描述。该方法结合国家电网某省公司实际电力工单文本数据,进行文本主题分析,结果表明可以有效描述电力客服工单主题。
1 并行LDA主题模型
隐含狄利克雷分布(Latent Dirichlet allocation,LDA)是一种主题模型(Topic Model),也是一种词袋模型,采用无监督学习算法,由Blei等于2003年提出。LDA主题模型可以以概率分布的形式给出文档集中每篇文档主题,并且在训练时不需要带标注的训练集。目前,LDA主题模型在文本挖掘领域中的文本主题识别、文本分类及相似度计算等方面都有广泛应用。
1.1 LDA主题模型
LDA主题模型是一种词袋模型,将语料库看作文档集合,将文档看作单词集合。文档就像一个装单词的袋子,袋子中的单词独立并可交换(即没有单词顺序和语法结构),基于此可将文档文本转换成对应的词频向量,完成文档数字化抽象。LDA主题模型将文档视为“文档—主题—词”的三层贝叶斯结构,每篇文档是若干主题的概率分布,每个主题是若干词的概率分布[1]。LDA主题模型的概率图模型见图1。
图1中,是文档—主题的Dirichlet分布的超参数;是主题—词的Dirichlet分布的超参数;是第i篇文档中主题的多项式分布的超参数;是第k个主题中词的多项式分布超参数;是第i篇文档中第j个词的主题;Wi,j是第i篇文档中第j个词;M是预料库中的文档数;Ni是第i篇文档中词数。
根据LDA主题模型的文档生成方式,模型中可见变量和隐变量的联合概率分布:
公式(1)中各变量含义与图1中一致。
根据极大似然估计,可以由对公式(1)得到一篇文档中单词的分布:
公式(2)中各变量含义与图1中一致。
通过的极大似然估计,最终可以使用吉布斯采样(Gibbs Sampling)方法估计模型中的参数。
1.2 LDA主题模型的并行化
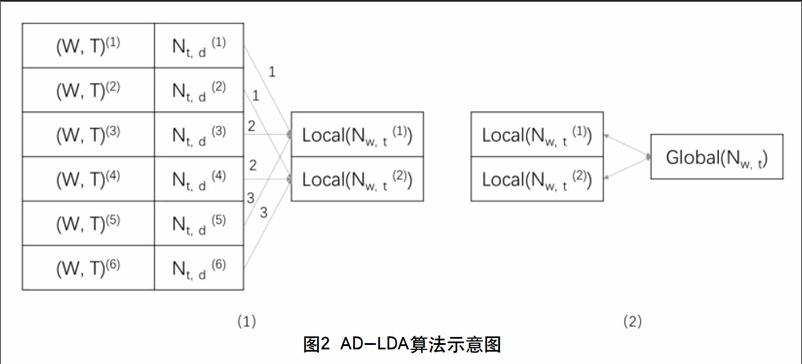
应用吉布斯采样方法可以估计模型中的参数,但是必须获取到除当前参数外其他全部参数的状态。所以,标准的LDA主题模型是一个串行学习的过程。近似分布LDA(AD-LDA)是一种分布式并行化的LDA算法。AD-LDA基于吉布斯采样,采用数据并行方式及参数全局融合思想,可以构建近似的并行化LDA主题模型。首先初始化LDA主题模型的全局参数,优化各分布的主题模型,然后采用同步或异步方式融合的到全局LDA主题模型参数[2]。AD-LDA算法见图2。
图2中,(W, T)(1)是并行处理的预料数据块,W是文本,T是主题,上标是数据块标号;Nt,d(1)是文档—主题频率计数矩阵,上标是与数据块对应的矩阵标号;Nw,t(1)是主题—单词频率计数矩阵,上标是任务标号;Local(Nw,t(1))是并行的本地模型;Global(Nw,t)是全局模型。
AD-LDA算法简述为:
(1)将语料数据分块为(W,T)(i),构建对应的文档—主题频率计数矩阵Nt,d(i);
(2)构建并行采样任务,使用分块语料数据训练本地模型Local(Nw,t(i));
(3)并行任务之间采用同步或异步方式借助全局参数服务器融合Global(Nw,t)全局模型。
近似分布LDA是标准LDA主题模型的近似,会使得训练收敛速度变慢,在几轮迭代后可以收敛到与串行吉布斯采样相同的超参数。可以在大规模分布式计算框架下加速收敛速度。
2 分布式内存计算框架
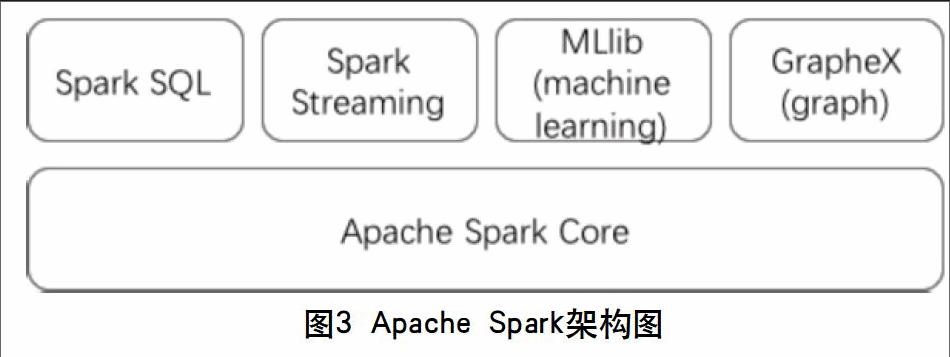
Apache Spark是UC Berkeley大学AMPLab实验室于2009年创建的分布式内存计算框架项目,并于2010年将其作为开源项目贡献给Apache基金会。截止到Spark 2.0版本,该项目由核心模块(Apache Spark Core)、类SQL查询模块(Spark SQL)、机器学习模块(MLlib)和图计算模块(GrapheX)组成,其架构见图3。
Apache Spark是一种与Apache Hadoop类似的基于MapReduce并行计算范式的分布式计算框架。Apache Spark与ApacheHadoop的关键不同在于,Apache Spark是基于内存的分布式计算框架,即计算作业的中间结果保存在内存中,在非必要时不需要频繁的读写外部存储介质,从而减少大量的I/O操作。而Apache Hadoop在Map阶段之后与Reduce阶段之前的中间结果硬性要求进行I/O操作。Apache Spark的这种内存计算特性使得在进行大规模迭代式机器学习与数据挖掘时效率很高。
Apache Spark的核心组件是弹性分布式数据集(Resilient Distributed Dataset, RDD),是一个分布式内存的抽象。RDD提供了以操作本地数据集合的方式来操作分布式数据集合的抽象。将频繁使用的RDD缓存到内存,这样对该RDD的计算可以直接在内存中进行,避免了大量I/O操作。但是,在内存消耗较大时RDD仍需要存储到外存中,这时需要要求其中的数据集是可序列化的(serializable)。RDD内部实现由5部分组成:
(1)数据块列表,即数据集分区列表。
(2)由父RDD生成子RDD时执行的数据块函数。
(3)对父RDD的依赖关系列表。
(4)用于分割数据,确定所在分区的partitioner()函数。
(5)数据块预定义存储地址列表。
Apache Spark RDD有两类计算方式,Transformation计算和Action计算。Transformation计算是懒执行的,即一个RDD通过执行Transformation计算生成新RDD时,该计算并不执行,而仅仅是记录该计算,当遇到Action计算时才执行计算。Transformation计算主要包括:map\filter\flatMap\mapPartitions\groupByKey\join\cogroup\repartition等。Action计算是立即执行的,执行完毕后将结果写入外部存储系统。Action计算主要包括:reduce\collect\count\countByKey\foreach\saveAsTextFile等。图4说明了计算的执行过程。
Apache Spark RDD提供了审计容错机制,是通过在RDD的计算过程中设置Checkpoint完成的。在RDD的计算过程中对RDD的转换过程进行记录,记录RDD之间的准换过程和关系,设置Checkpoint,轉换记录被称为Lineage。当系统需要回滚时,Apache Spark根据这些Lineage转换记录重新计算,完成作业操作。
3 应用分析
应用上述方法,选取国网公司某网省公司某年1~6月份95598客服工单数据(约204万条)进行分析。结合电力行业词库与非电力行业词库,对工单文本数据进行切词处理,表1为部分工单文本切词结果数据。
应用并行LDA主题模型,在分布式内存计算框架下,以主题数为10(k=10)进行文本分析,各主题包括的主题词见表2。
4 结语
结合电力工单文本数据的非结构化数据特点,使用某网省电力客户文本工单数据,首先对工单文本结合电力词典进行分词,然后应用分布式内存计算框架,构建并行LDA主题模型对其进行文本挖掘。结合客户业务专家经验进一步进行语义分析,提高了工单文本分析的效率。通过仿真计算表明能够较好的提取工单文本语义信息,满足实际应用需求。
参考文献
[1] Blei, David M, Ng A Y, Jordan M I. Latent dirichlet allocation[C]. Neural Information Processing System, 2001:601-608.
[2] Newman D. Asuncion A U, Smyth P, et al. Distributed inference for latent dirichlet allocation[C]. Neural Information Processing Systems, 2008:81-88.
[3] 刘兴平,章晓明,沈然,等.电力企业投诉工单文本挖掘模型[J].电力需求侧管理,2016,18(2):57-60.
[4] 王震,代岩岩,陈亮,等.基于LDA模型的95598热点业务工单挖掘分析[J].电子技术与软件工程,2016(22):190-192.
[5] 高阳,严建峰,刘晓升.朴素并行LDA[J].计算机科学,2015,42(6):243-246.
[6] 王旭仁,姚叶鹏,冉春风,等.一种并行LDA主题模型建立方法研究[J].北京理工大学学报,2013,33(6):590-593.
