
一种基于带权无向图的中医方剂频繁项集挖掘算法
2017-06-29 12:00:34秦琦冰
计算机应用与软件 2017年5期
谭 龙 秦琦冰
(黑龙江大学计算机科学技术学院 黑龙江 哈尔滨 150080)
一种基于带权无向图的中医方剂频繁项集挖掘算法
谭 龙 秦琦冰
(黑龙江大学计算机科学技术学院 黑龙江 哈尔滨 150080)
根据中医方剂数据的特点,将频繁项集发现算法应用到中医方剂的研究中,挖掘治疗消渴病胃火炽盛症型的方剂中不同药对之间的关联规则以及核心药物组合,提出一种基于带权的无向频繁项集图的挖掘算法。该算法可以快速挖掘频繁k-items(k≥3),并随之快速回溯频繁项集所对应的方剂,从而完成了中医方剂数据特点的快速数据挖掘。通过实验表明,该算法避免产生大量候选项集,提高了中医方剂数据挖掘效率,对完成中医消渴病方剂信息的用药规律分析具有重要意义。
消渴病 频繁项集 无向图 中医方剂 数据挖掘
0 引 言
数据挖掘是数据库知识发现领域内非常热点的研究方向,主要目的是从大量的数据库中检索出用户感兴趣的信息[1]。在数据挖掘中,关联规则的挖掘是其核心任务之一,其根本意义在于从大量数据中挖掘出项集之间的相互关系。关联规则分析方面代表性案例就是“购物篮分析”,该案例是通过挖掘顾客购买商品的交易数据,来发现不同商品在交易过程中隐藏的关系,从而获得销售的增益[2]。大量研究人员已经在挖掘频繁项集的算法中作了许多工作,Agrawal等人提出的Apriori的算法是一种最经典的挖掘频繁项集的算法,在此基础上,也提出了许多基于Apriori的改进算法,如HEA[3]、MTR-FMA[4]、Modified Apriori[5]以及Improved Aprori[6]等算法,Han等于2000年提出的FP-Growth算法也在频繁项集挖掘中做出了突出贡献。
同时,针对基于图存储的频繁项集挖掘方法的研究也引起了很多学者的关注,Yen等人第一次提出了基于有向图存储的频繁项集挖掘算法,文献[7]又对上述算法进行了改进。在此基础上,Kumar等提出了一种FIG(Frequent Item Graph)的算法[8];Tiwari等在FP-Growth的基础上进行改进,提出了FP-Growth-Graph来进行频繁项集挖掘[9]。
上述频繁项集挖掘的算法中,大致可以分为两个关键思路:(1) 产生候选频繁项集以及进行剪枝。(2) 不产生候选频繁项集的方法[10]。在频繁项集挖掘的过程中,方法(1)可能会产生大量的候选项集,增加算法的时间和空间复杂度,而方法(2)避免了候选项集的产生,但是往往需要大量的额外开销,挖掘效率有待于进一步提高。本文所提出的算法主要遵循方法(2)中思路进行。
本研究团队一直从事研究中医方剂中治疗消渴病方剂的数据挖掘工作。消渴病是以多饮、多食、多尿、身体消瘦,或尿浊、尿中有甜味为主要表现的一种临床常见病、多发病,严重危害着人类的健康[11],中医对于消渴病的预防和治疗有着丰富而且独特的经验[12],因此,对《中医方剂大辞典》中收录的治疗消渴病胃火炽盛症型的方剂研究也尤为重要。在研究中发现,治疗该症型的方剂中往往存在大量的频繁的k-items(k≥3),而相比于频繁1-items、频繁2-items而言,频繁k-items(k≥3)的产生对于治疗消渴病胃火炽盛症型也更具有重要的临床参考价值。
同时,在对方剂数据库的频繁项集挖掘过程中,传统算法在找到频繁项集结果后,却不能有效发现该频繁项集所对应的方剂名称,而方剂名称和频繁项集的对应关系,对方剂规律分析具有重要意义。因此,本文提出了一种基于带权的无向频繁项集图WUFIG(WeightedUndirectedFrequentItemsGraph)挖掘算法来挖掘频繁项集。该算法不仅可以解决上述问题,还大大减少了对原始数据库的扫描次数,避免产生大量的候选项集,能够有效的挖掘出频繁k-items(k≥3),提高了对于中医方剂数据挖掘效率。
1 系统模型
本文系统模型为,存在项集I={I1,I2,…,Im},事务数据库D={〈TID,T〉|T⊆I},TID为代表每一条事务的标识符;T为项的集合。事务数据库D,将进一步产生带权的无向频繁项集图(如图1所示),无向频繁项集图的节点为项集I中的项组成,节点项之间如果是频繁项集,则有一条边,边的权值用边的两个节点项之间的权重表示。
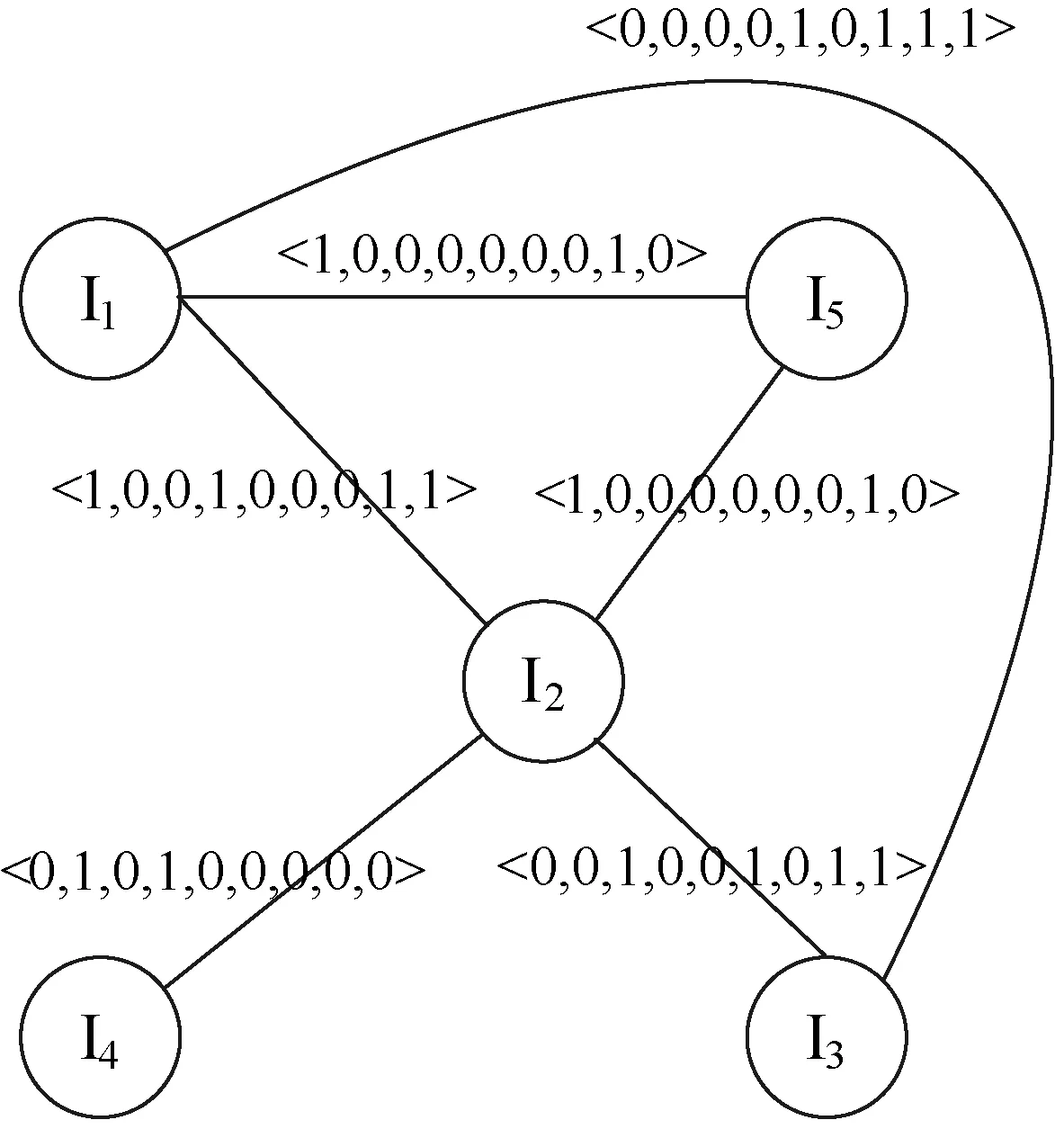
图1 带权无向频繁项集图
定义1 对于项X,包含所有的X的TID的集合称之为项X的事务集合,简称Tidset,用Tidset(X)表示。
假设TID的个数为n,则Tidset(X)为n位二进制位组成的元组,该元组可存储在整型Long数据类型(4个字节)中。通常,《中医方剂大辞典》中收录的治疗常见症型的方剂约为300首左右,因此,最多需要申请10个Long类型空间存储事务数据库中的n位二进制元组,满足算法的存储要求。例如,在表1中,n=9,需申请2个Long类型存储空间(16位),按照从低位到高位的按位存储,项I1存在的TID为1,4,7,8,9,则:
Tidset(I1)=<(0,0,0,0,0,0,0,1),(1,1,0,0,1,0,0,1)>
为描述方便,针对表1所示,n=9情况,本文将Tidset(I1)表示为:
Tidset(I1) = <1,0,0,1,0,0,1,1,1>
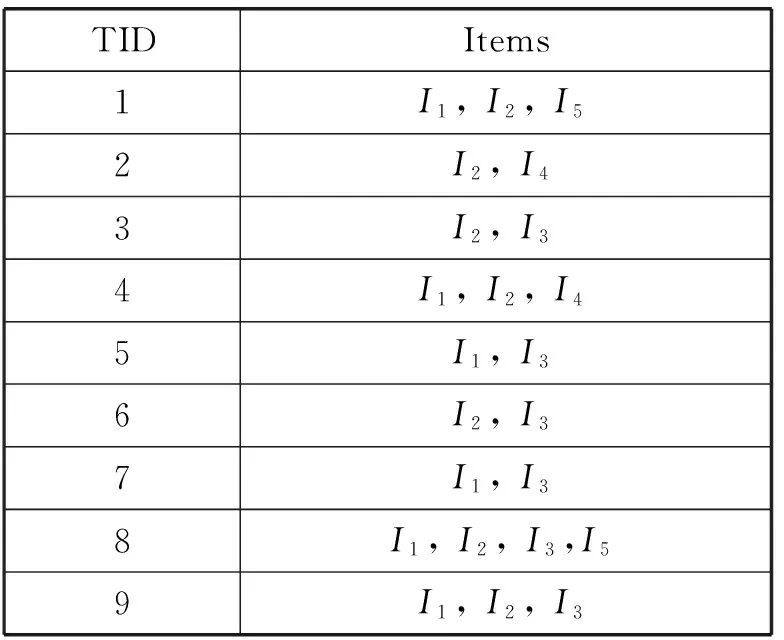
表1 事务数据库表
定义2 两个项X和Y之间的Tidset可以进行按位与(&)操作,记为Tidset(X)&Tidset(Y),其结果与元组
例如,由定义1可知表1中:
Tidset(I1) = <1,0,0,1,0,0,1,1,1>
Tidset(I2) = <1,1,1,1,0,1,0,1,1>
则:
Tidset(I1)&Tidset(I2)) = <1,0,0,1,0,0,0,1,1>
在带权的无向频繁项集图中,设频繁1-items为点集V,E为边集,E(Vx,Vy)表示为点Vx和Vy的边,minsup为最小支持度阈值,count(Tidset(Vx)&Tidset(Vy))表示Vx和Vy同时出现的次数。由上述定义1和定义2,可得边权重weight(Vj,Vk)的计算方法为:
∀Vi∈L1(1≤i≤m)
∃count(Tidset(Vj)&Tidset(Vk))≥minsup则:
E=E∪E(Vj,Vk)
weight(Vj,Vk)=Tidset(Vj)&Tidset(Vk)
在基于带权的无向频繁项集图(WUFIG)中,对于任意两个频繁1-items, 如果count(Tidset(X)&Tidset(Y))不小于最小支持阈值,那么X与Y之间存在边E(X,Y),该边加入到E中,同时weight(E(X,Y))为Tidset(X)&Tidset(Y)的结果。
在基于带权的无向频繁项集图(WUFIG)中,对于某个点集合V′中任意两点Vi和Vk,如果都存在一条边E(Vi,Vk)E,则V′中所有的点构成一条频繁项集环,即为频繁项集。因此,∀Vi∈L1(1≤i≤m),∃V′=
2 基于带权的无向频繁项集图挖掘算法
本文中提出的算法是基于带权的无向频繁项集图基础上搜索频繁k-items环,算法命名为WUFIG(WeightedUndirectedFrequentItemsGraph)。
图4中,V1、V3、V5分别表示阀1、3、5收到脉冲触发信号,发生不对称故障后,由于a相幅值降低,ab换相线电压过零点超前于对称故障时的过零点,此时导致实际的触发角增大,在换相线电压变为正向时换相结束,因此导致换相失败。
2.1 算法原理
本算法使用带权无向图的方式进行存储,图中顶点集合即为频繁1-items,顶点之间边的权值即为Tidset(Vi) &Tidset(Vj),在基于带权的无向频繁项集图(WUFIG)中,如果存在频繁k-items环,则环上面的顶点即为频繁k-items。频繁k-items环路的每条边的权值,进行与(&)操作,其结果即为频繁k-items所在的TID。该TID在具体中医方剂数据处理中,即为频繁药物组合所对应的方剂名称。
无向频繁项集图的生成算法见WUFIG_GEN算法,在此无向频繁项集图基础上,搜索频繁k-items环的操作见Mining_Frequent_K_Items算法,该算法调用Searchfrequentk-itmesloop来完成对频繁k-items环的搜索。
WUFIG_GEN算法描述如下:
Input:Transactional Database D, minsup
Output: WUFIG
procedure WUFIG_GEN (D, minsup)
1) For each Vj∈L1
2) For each Vi∈L1(i≠j)
3) If (vj∩vi)≠∅ and count(Tidset(Vj)&Tidset(Vi)) ≥minsup;
4) Add E(Vi,Vi)to Edge set E;
5) Weight(Vi, Vj) = Tidset(Vi)& Tidset(Vj);
6) End if;
7) End for;
8) End for;
End procedure;
Mining_Frequent_K_Items算法描述如下:
Input:WUFIG
Output: frequent k-items,TID
//(k≥3)
Procedure Mining_Frequent_K_Items
//(k≥3)
1) While V≠∅ do
2) For each Vi, Vj(i≠j) of V
3) If E(Vi, Vj)∈E then
//Vi, Vj之间有边相连
4) L = Vi∪Vj,V′ = V-{ Vi, Vj}
5) Search frequent k-itmes loop(L,V′);
6) End if;
7) End for;
8) End while;
End procedure;
procedure Search frequent k-itmes loop(L,V′)
1) While V′≠∅ do
2) For unvisited Vkof V′
3) If E(Vk, ∀Vj∈V′)∈E then;
4) L=L∪Vk, V′ = V′-{ Vk};
5) Output L and weight_&;
//输出频繁k-items和对应的TID
6) End if;
7) End for;
8) End while;
End procedure;
根据WUFIG_GEN算法,在最小支持度minsup为2的基础上,首先对事务数据库D中频繁1-items的计算Tidset,同时计算任意两个频繁1-items的Tidset的交集。
例如,从表1得到:
Tidset(I1) = <1,0,0,1,1,0,1,1,1>
Tidset(I2) = <1,1,1,1,0,1,0,1,1 >
count(Tidset(I1)&Tidset(I2))=count(<1,0,0,1,0,0,0,1,1>)由于count(Tidset(I1)&Tidset(I2))=4>minsup,则I1,I2之间存在一条边E(V1,V2)。 因此weight(I1,I2) = <1,0,0,1,0,0,0,1,1>,Tidset(I4) = <0,1,0,1,0,0,0,0,0>,count(Tidset(I1)&Tidset(I4) ) =count(<0,1,0,0,0,0,0,0,0>)。由于count(<0,1,0,0,0,0,0,0,0>)=1 根据Mining_Frequent_K_Items算法:对于WUFIG(V,E,W)中∀E(Vi,Vj)∈E,例如:图1中点I1和点I2,从V′=V-{I1,I2}={I3,I4,I5}中选取点I3,则E(I3,I1)∈E,E(I2,I1)∈E,则点I1、点I2和点I3之间存在一条频繁3-items环,则I1I2I3为频繁3-items,weight(I1,I2)&weight(I1,I3)&weight(I2,I3) = <0,0,0,0,0,0,0,1,1>,即I1I2I3出现的TID为8,9,同理可以由图1可以生成频繁3-itemsI1I2I5,I1I2I5出现的TID为1,8。 2.2 算法复杂性分析 本文提出的基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法,在空间上的耗费主要在于存储WUFIG中的N个顶点、K条边以及边的权重,而存储WUFIG的复杂度主要取决于事务数据库的长度。随着中医方剂数据库长度的增大,WUFIG的空间复杂度也会相应的增加,因此,通常的方法是在原始中医方剂数据的基础上采用聚类方法,将治疗同一症型的方剂分簇,然后在同一簇内采用该算法进行频繁项集的挖掘,这样就可以有效地降低其空间复杂度。 该算法的时间代价主要在于扫描事务数据库以及搜索频繁k-items环的过程。扫描事务数据库所需要的时间取决于事务数据库的长度,因此这一过程的平均时间复杂度为O(n);搜索频繁项集环所需的时间取决于WUFIG中点的个数,V′中点的个数以及频繁项集的长度,因此这一过程的平均时间复杂度为O(N×K×L),其中N为V中点的个数,K为V′中点的个数,L为所求频繁项集的长度。因此总的时间复杂度为O(n)+O(N×K×L)。 本文的实验算法使用VC++6.0环境来实现。实验数据是从《中医方剂大辞典》中收录的治疗消渴病胃火炽盛方剂中筛选出来的382首方剂,包含218味中药药材。 本文中针对于数据的前期准备处理主要是针对药物组成的规范,该规范包括:药材的重名和异名处理;同名异方的处理;药材的计量单位的统一标准。在此规范数据基础上,构建方剂数据库。通过对《中医方剂大辞典》中收录的方剂进行分析,初步按照编号、方剂名、组成、别名、性、味、归经、功效等8个属性进行描述,完成对原始数据库的构建。从而,利用基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法对数据源存储的方剂进行分析研究。 3.1 实验结果 根据本次治疗胃火炽盛方剂数量和用到的中药个数,结合经验判断以及不同参数提取数据的预读,选择组方中3味药物核心组合支持度≥20,提取出96个组合,根据提出结果结合经验判断,筛选出部分有价值的频繁3-items以及所对应的方剂名见表2所示。由实验结果中选择4味药物核心组合支持度≥15,提取出67个组合,根据提出结果结合经验判断,筛选出部分有价值的频繁4-items以及对应的方剂名见表3所示。 表2 治疗胃火炽盛组方中3个药物核心组合 表3 治疗胃火炽盛组方中4个药物核心组合 根据对于消渴病胃火炽盛症型的经验,药物关联规则结果中选择支持度≥15,置信度≥0.6,去掉相互包含的规则后,同时针对胃火炽盛方剂对得到的结果进行关联规则分析后得到20条有价值的规则,见表4所示。 表4 胃火炽盛方剂中部分药物关联规则 《中医方剂大辞典》中收载的治疗胃火炽盛型消渴病的方剂,分析得到治疗胃火炽盛型消渴病的方剂中药物的使用频次,选取适合的支持度,提取出治疗胃火炽盛型消渴病3 味药物的核心组合96组、4 味药物的核心组合67 组,并且进一步揭示了胃火炽盛型消渴病组方中药物的关联规则,可以得出以下结论: (1) 从表2、表3可知,治疗胃火炽盛型消渴病方剂中药物频次最高的四味药为黄连、麦冬、天花粉、知母,为医家基本用药组合,可作为临床组方用药时的重要参考与借鉴。 (2) 通过核心药对所在的方剂名,可以得到治疗胃火炽盛型消渴病的方剂治疗时以清胃火为主,同时兼补心、肺、胃、肾等相关脏腑之阴。 (3) 通过以上数据中的用药频次与药物关联规则可以看出,黄连、麦冬、天花粉、知母四味药物与石膏、黄芩、黄柏、大黄等药物的配伍运用亦为治疗胃火炽盛型消渴病的常见药物组合。 3.2 实验对比分析 本文主要针对FP-Growth、FIG、FP-Graph算法,选择了minsupthreshold为0.3%、0.25%、0.2%、0.15%、0.1%进行对比实验。实验数据通过采用《中医方剂大辞典》中收录的治疗消渴病胃火炽盛方剂作为基础数据,采用常用药材随机分布的方式,构建了10 000条实验数据,进行算法性能对比分析。实验结果如图2所示。从图中可以看出,随着最小支持度阈值的降低,运行时间都在增加,但是基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法的时间增加率要远低于其他算法。从实验结果可以得知:基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法的复杂度要优于其他算法。 图2 基于不同支持度算法对比分析图 假设minsupthreshold为0.25%,实验方剂数据量从2 000增加到10 000,进行算法性能的对比实验。随着实验方剂数据量的增加,算法产生的中间候选项集会不断增大,时间代价也会越来越大。由图3可知,基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法性能方面优于其他算法。 图3 基于不同事务数量算法对比分析图 在对《中医方剂大辞典》中收载的治疗胃火炽盛型消渴病方剂进行研究分析时,针对研究分析数据的特点,提出了一种基于带权的无向频繁项集图(WUFIG)的频繁项集挖掘算法。该算法能够有效快速地产生频繁k-items(k≥3),并随之快速回溯频繁项集所对应的方剂,对于分析该症型中医用药规律的研究有着重要意义。由于该算法只需扫描一次原始数据库,而且在频繁项集挖掘过程中,避免产生大量候选项集,降低了时间复杂度,大大提高了算法的效率。同时,随着事务数据库的增大,带权的无向频繁项集图边的权重元组的存储空间会增加,接下来,我们将针对如何有效地压缩其存储空间作进一步研究。 本文算法通过对消渴病方剂数据分析所得到的核心药物组合以及方剂名称,在一定程度上反映消渴病胃火炽盛型的用药规律,可作为在临床针对消渴病胃火炽盛型的组方用药时的重要参考与借鉴。在诊疗疾病的过程中对于临床医生的判读与分析,提供了有效的保证,具有重要的临床应用价值。 [1] Solanki S K,Patel J T.A survey on association rule mining[C]//Advanced Computing & Communication Technologies (ACCT),2015 Fifth International Conference on.IEEE,2015:212-216. [2] Girotra M,Nagpal K,Minocha S,et al.Comparative survey on association rule mining algorithms[J].International Journal of Computer Applications,2013,84(10):18-22. [3] Li Z C,He P L,Lei M.A high efficient AprioriTid algorithm for mining association rule[C]//Machine Learning and Cybernetics,2005 International Conference on.IEEE,2005:1812-1815. [4] Thevar R E,Krishnamoorthy R.A new approach of modified transaction reduction algorithm for mining frequent itemset[C]//Computer and Information Technology,2008 11th International Conference on.IEEE,2008:1-6. [5] Abaya S A.Association rule mining based on Apriori algorithm in minimizing candidate generation[J].International Journal of Scientific & Engineering Research,2012,3(7):1-4. [6] Sunil K S,Shyam K S,Akshay K C,et al.Improved Aprori algorithm based on bottom up approach using probability and matrix[J].International Journal of Computer Science Issues,2012,9(2):242-246. [7] Yen S J,Chen A L P.A graph-based approach for discovering various types of association rules[J].IEEE Transactions on Knowledge and Data Engineering,2001,13(5):839-845. [8] Kumar A V S,Wahidabanu R S D.A frequent item graph approach for discovering frequent itemsets[C]//Advanced Computer Theory and Engineering,2008 International Conference on.IEEE,2008:952-956. [9] Tiwari V,Tiwari V,Gupta S,et al.Association rule mining:a graph based approach for mining frequent itemsets[C]//Networking and Information Technology (ICNIT),2010 International Conference on.IEEE,2010:309-313. [10] Mohamed M H,Darwieesh M M.Efficient mining frequent itemsets algorithms[J].International Journal of Machine Learning and Cybernetics,2014,5(6):823-833. [11] 王芳芳.消渴病古代文献研究及近30年用柴胡类方治疗资料的分析[D].广州:广州中医药大学,2011. [12] 荣开明.复兴中医药学的几点思考[J].湖北中医药大学学报,2015,17(2):59-62. A TRADITIONAL CHINESE MEDICINE PRESCRIPTION FREQUENT ITEM SETS MINING ALGORITHM BASED ON WEIGHTED UNDIRECTED GRAPH Tan Long Qin Qibing (CollegeofComputerScienceandTechnology,HeilongjiangUniversity,Harbin150080,Heilongjiang,China) According to the characteristics of traditional Chinese medicine prescription data, the frequent item sets discovery algorithm is used to the study of TCM prescriptions, and mine the association rule and core drug combination of the different drugs in the prescriptions for the treatment of Emaciation-Thirst disease with stomach fire flaming. In this paper, frequent item sets mining algorithm based on weighted undirected graph is proposed. The proposed algorithm can rapidly mine frequent k-items, and quickly backtrack to the prescription corresponding to frequent item sets, thus accomplishing the rapid data mining of TCM prescription data. Experiments show that this algorithm avoids generating a large number of candidate items and improves the data mining efficiency of TCM prescription, which is of great significance to analyze the law of drug use in the prescriptions of Emaciation-Thirst disease. Emaciation-Thirst disease Frequent item sets Undirected graph Chinese medicine prescription Data mining 2016-04-05。国家自然科学基金面上项目(81273649);黑龙江省自然科学基金面上项目(F201434)。谭龙,副教授,主研领域:传感器网络,数据挖掘。秦琦冰,硕士生。 TP ADOI:10.3969/j.issn.1000-386x.2017.05.0073 实 验





4 结 语
猜你喜欢
中国民间疗法(2021年1期)2021-04-20 02:30:58
中国民间疗法(2020年22期)2021-01-07 07:40:06
爱你(2019年5期)2019-11-14 22:09:12
养生阅刊(2019年9期)2019-09-10 07:22:44
饮食保健(2018年17期)2018-09-18 09:20:56
中成药(2018年6期)2018-07-11 03:01:24
长春中医药大学学报(2017年1期)2017-04-16 05:56:45
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
中国民间疗法(2014年10期)2014-01-24 14:39:12
