
CPU计算和GPU计算
2017-06-27 08:07李旻昊
中国科技纵横 2017年9期
关键词:大数据
李旻昊
摘 要:本文先介绍了CPU和GPU的相关知识,包括他们的历史、架构、以及目前发展的现状。然后来阐述两者在使用上的区别以及使用场景的不同。最后也是本文的重点,讲述如何使用GPU来加快程序的运算速度,尤其是在大数据的处理这一方面,并且介绍NVIDIA公司所推出的CUDA运算平台。
关键词:CPU;GPU;大数据
中图分类号:TP338 文献标识码:A 文章编号:1671-2064(2017)09-0029-02
CPU与GPU是每一台电脑中都必不可少的部件。简单来说,CPU就是一台电脑中的“大脑”,能够协调电脑中各个部件的运作。相比之下,GPU就显得低调了很多。它处于显卡之中,是显卡的“心脏”,并且在以往的概念中,GPU并没有CPU那般地位重要。
CPU和GPU都遵循着摩尔定律,即当价格不变时,集成电路上可以容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将会增加一遍。我们不可否认的是,即使科技不断的进步,可以容纳的元器件的数目也会有一个上限。这时,我们会用何种方式来提高性能呢?科学家们不停的探索这一方面的内容,给出的答案的其中之一就是使用GPU编程。如何利用GPU来编程?它和CPU的区别在哪里?它适用于怎么样的程序?能提高的性能有多少?这四个问题就是本文想要阐述的。下面就让我们一起进入电子元器件的世界。
1 CPU(中央处理器)
下面先介绍一下CPU(中央处理器)相关的知识。包括指令集,物理结构,流水线架构,以及目前CPU发展的六个阶段。
1.1 指令集
我们日常使用电脑的过程中可能会思考下面的一个问题:为什么我双击了桌面上的一个图标,程序就开始运行了?你也可能已经猜到了答案:我们向电脑发出了一条命令。这条命令是什么,谁处理这条命令,这个问题就是我們这一节要弄明白的问题。
当我们双击了图标之后,就向计算机发出了一条命令。这条命令被CPU所接受,然后CPU开始解析这条命令并且向计算机其他部件发出信号,包括从硬盘取出相应的程序,放到内存中运行。这就是一条指令带给计算机的工作。如果还不能够理解,也没有关系,只需要知道我们给计算机发出的命令都可以转换成指令的形式就足够了。
当然,计算机能够接受的指令有很多很多,总体来说分成两大类:复杂指令集和精简指令集。
复杂指令集也称CISC。在CISC微处理器中,指令是按照顺序来执行的,其优点就是控制简单,但是因为只能够顺序执行,因此它的运行速度不尽如人意。我们现在使用的所有的Intel处理器都是CISC,也就是x86和x86-64架构的。
精简指令集称作RISC。John Cocke对CISC机进行研究之后发现,程序中出现频率达到80%的指令只占指令集中所有指令的20%(这也是著名的28定律)。复杂的指令系统会增加微处理器的复杂顶,导致计算机运行的速度降低。因此RISC诞生了,它的指令格式统一,种类比较少,寻址方式也简单了很多,自然处理速度也有了提高。目前在高档的服务器中都采用了RISC指令集。
1.2 物理结构
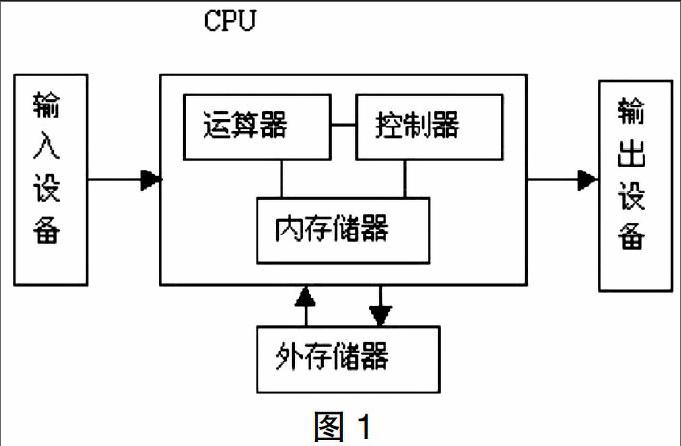
计算机之父冯·诺依曼曾经提出过存储程序原理,把程序本身当作数据来对待,程序和该程序处理的数据用同样的方式存储。大致的思想如图1所示。
可以看到,运算器、控制器和内存储器是被放在CPU之中的,这也是目前CPU的物理结构。运算器也称做运算逻辑部件,可以执行各种算术运算操作和逻辑操作。内存储器包括寄存器和CPU缓存,用来保存指令执行过程中临时存放的寄存器操作数和中间操作结果。控制部件主要是对指令进行翻译,并且发出为完成每条指令所要执行的各个操作的控制信号。
在CPU中,上述三个部件是必不可少的。当然随着技术的发展,目前CPU还有很多其他的部件,感兴趣的读者可以自行搜索相关资料。
1.3 流水线架构
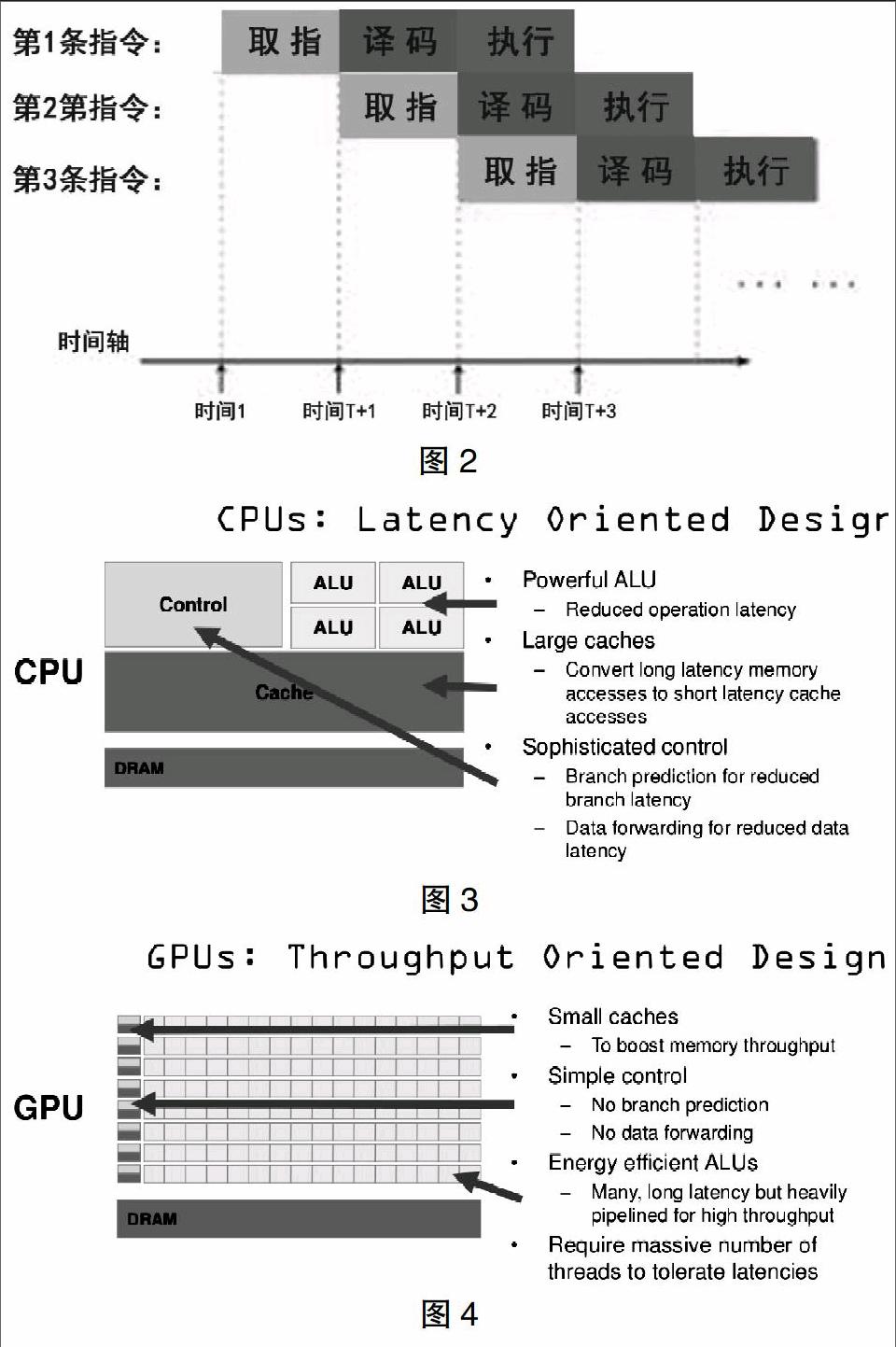
在说流水线架构之前,我们需要先弄清楚CPU的工作流程。CPU从存储器中取出指令,放入指令寄存器,并且进行译码。然后发出各种控制命令,执行微操作,从而完成一条指令的执行。详细来说,主要分成下述四个步骤:
(1)提取。用程序计数器来指定存储器的位置,然后从存储器中检索指令。
(2)解码。根据我们提取到的指令来决定其执行行为。根据CPU的指令集,指令会被拆解成有意义的片段。
(3)执行。我们根据相应的指令片段,来链接到各种CPU运算部件,进行相应的操作。
(4)写回。最终,我们将在执行阶段得到的结果简单的写回。通常他会被写进CPU内部的寄存器中,也有可能会被写进速度较慢但是容量较大的内存中。这时,一条指令已经完成,程序计数器值会递增,来提取下一条指令并且重复上述的过程。
这就是CPU的工作流程。在流水线架构诞生之前,我们的指令都是一条完成后再接着另一条的,这样做效率就会很低,因为并不是所有部件都无时无刻的在工作。比如,在执行阶段,指令存储器就没有办法很好的利用起来。为了解决这样的问题,流水线架构诞生了。简单来说,就是能够充分利用每一个部件。在第n条指令解码的时候,我们可以提前提取第n+1条指令。然后在第n条指令执行之时,CPU会去对第n+1条指令进行解码。详细的流程如图2所示。
有了流水线架构,CPU的工作效率大大提高。
1.4 发展的六个阶段
CPU发展已经有40多年的历史了。我们通常将其分成六个阶段。
(1)第一阶段(1971年-1973年)。这是4位和8位低档微处理器时代,代表产品是Intel4004处理器。
(2)第二阶段(1974年-1977年)。这是8位中高档微处理器时代,代表产品是Intel8080。此时指令系统已经比较完善了。
(3)第三阶段(1978年-1984年)。这是16位微处理器的时代,代表产品是Intel8086。相对而言已经比较成熟了。
(4)第四阶段(1985年-1992年)。这是32位微处理器时代,代表产品是Intel80386。已经可以胜任多任务、多用户的作业。
(5)第五阶段(1993年-2005年)。这是奔腾系列微处理器的时代。
(6)第六阶段(2005年至今)。是酷睿系列微处理器的时代,这是一款领先节能的新型微架构,设计的出发点是提供卓然出众的性能和能效。
2 GPU(图像处理器)
读完了CPU的介绍,现在我们来简单介绍一下GPU。因为CPU和GPU的工作流程和物理结构大致是类似的,因此这里不再重复了。我们仅仅介绍一下GPU的功能和目前主流的供应商。
相比于CPU而言,GPU的工作更为单一。在大多数的个人计算机中,GPU仅仅是用来绘制图像的。如果CPU想画一个二维图形,只需要发个指令给GPU,GPU就可以迅速计算出该图形的所有像素,并且在显示器上指定位置画出相应的图形。
由于GPU会产生大量的热量,所以通常显卡上都会有独立的散热装置。
除此之外,GPU的供应商比CPU供应商更多一些。主流的供应商有:
(1)Intel,基本都为集成显卡。
(2)Nvidia,也就是我们常说的N卡,在运算速度上有较大的优势。
(3)AMD(ATI),我们常说的A卡,通常在图形渲染上做的比N卡好。
(4)其他厂商,包括3dfx,Matrox,SiS和VIA。这些都是相对比较小众的公司。
3 CPU和GPU的比较
现在,我们来比较一下CPU和GPU。看看他们各自在哪些领域能够发挥出自己的作用。我们从两个角度入手:设计结构和使用场景。
3.1 设计结构
我们先从CPU开始说起。CPU有强大的算术运算单元,可以在很少的时钟周期内完成算术计算。同时,有很大的缓存可以保存很多数据在里面。此外,还有复杂的逻辑控制单元,当程序有多个分支的时候,通过提供分支预测的能力来降低延时。具体的结构如图3所示。
下面我们来讨论GPU的设计结构。GPU是基于大的吞吐量设计,有很多的算术运算单元和很少的缓存。同时GPU支持大量的线程同时运行,如果他们需要访问同一个数据,缓存会合并这些访问,自然会带来延时的问题。尽管有延时,但是因为其算术运算单元的数量庞大,因此能够达到一个非常大的吞吐量的效果。如图4所示。
3.2 使用场景
显然,因为CPU有大量的缓存和复杂的逻辑控制单元,因此它非常擅长逻辑控制、串行的运算。相比较而言,GPU因为有大量的算术运算单元,因此可以同时执行大量的计算工作,它所擅长的是大规模的并发计算,计算量大但是没有什么技术含量,而且要重复很多次。
这样一说,我们利用GPU来提高程序运算速度的方法就显而易见了。我们使用CPU来做复杂的逻辑控制,用GPU来做简单但是量大的算术运算,就能够大大地提高程序的运行速度。下面我们来介绍一下Nvidia所推出的CUDA运算平台。
4 CUDA
CPU程序员的挑战不只是在GPU上获得出色的性能,还要协调系统处理器与GPU上的计算调度、系统存储器和GPU存储器之间的数据传输。为了解决这样的问题,Nvidia决定开发一种与C类似的语言和编程环境,通过克服多种并行带来的挑战来提高GPU程序员的生产效率。这个系统的名称为CUDA,表示“计算统一设备体系结构”。
在CUDA中,这些并行形式的统一主题就是CUDA线程。CUDA线程是最低级别的并行,可以执行一次操作。例如,如果我们有200个CUDA线程,那我们就可以同时进行200个算术运算,这样一来程序的吞吐率就有了提高。
就目前来看,CUDA的应用场景是非常广泛的。在消费级市场上,几乎每一款重要的视频程序都已经使用CUDA加速。除此之外,在科研界和金融市场,CUDA都有相应的使用场景。不可否认的是,在未来,GPU计算必将成为主流。
参考文献
[1]John L. Hennessy, David A. Patterson. Computer Architecture: A Quantitative Approach[M].人民郵电出版社,2013.
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
