
融合《知网》和搜索引擎的词汇语义相似度计算
2017-06-27 08:10张硕望欧阳纯萍阳小华刘永彬刘志明
计算机应用 2017年4期
张硕望,欧阳纯萍,阳小华,刘永彬,刘志明
南华大学 计算机科学与技术学院,湖南 衡阳 421001)(*通信作者电子邮箱ouyangcp@126.com)
融合《知网》和搜索引擎的词汇语义相似度计算
张硕望,欧阳纯萍*,阳小华,刘永彬,刘志明
南华大学 计算机科学与技术学院,湖南 衡阳 421001)(*通信作者电子邮箱ouyangcp@126.com)
针对当前《知网》的词语语义描述与人们对词汇的主观认知之间存在诸多不匹配的问题,在充分利用丰富的网络知识的背景下,提出了一种融合《知网》和搜索引擎的词汇语义相似度计算方法。首先,考虑了词语与词语义原之间的包含关系,利用改进的概念相似度计算方法得到初步的词语语义相似度结果;然后,利用基于搜索引擎的相关性双重检测算法和点互信息法得出进一步的语义相似度结果;最后,设计了拟合函数并利用批量梯度下降法学习权值参数,融合前两步的相似度计算结果。实验结果表明,与单纯的基于《知网》和基于搜索引擎的改进方法相比,融合方法的斯皮尔曼系数和皮尔逊系数均提升了5%,同时提升了具体词语义描述与人们对词汇的主观认知之间的匹配度,验证了将网络知识背景融入到概念相似度计算方法中能有效提高中文词汇语义相似度的计算性能。
语义相似度;知网;搜索引擎;权重;网络
0 引言
词汇语义相似度计算是自然语言处理的一项基本内容,被应用在众多重要的领域当中。词汇语义相似度计算方法可以分为两类: 一类是基于大型语料库的方法,这类方法通过统计文档中词语之间的共现情况来计算词语之间的相关性; 另一类则是基于某种世界知识与分类体系的词汇语义相似度计算方法,根据语义词典的语义层次关系和知识结构来计算词汇的相关度。《知网》(HowNet)[1]系统基于英语和汉语,是一种以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识性网状知识库,也是很多学者在词汇语义研究中的首要工具,并且帮助他们取得了很好的效果。主流的基于《知网》的词汇相似度研究方法都是根据词语的语义距离加权计算得出相似度,其中具有代表性的有刘群等[2]提出的依据义原间的距离进行计算的方法,以及王小林等[3]提出的变系数方法等;文献[4]针对《知网》中存在未登录词的问题提出了基于概念切分和语义自动生成的解决方法,该文利用逆向最大匹配法将未登录词切分成多个登录词,再将登录词的义原表达式进行组合,从而获得未登录词的义原表达式,达到对未登录词进行相似度计算的目的;文献[5]提出了基于《知网》的对概念语义相似度的改进方法,该文采用图论的二部图最大权匹配算法来计算其他基本义原描述式的相似度,提高了计算结果的精度;文献[6]综合了《知网》和《同义词词林》的相似度计算方法,依据词对在两个知识库的收录情况决定融合权值。
除了上述方法外,也有学者另辟蹊径。如文献[7]利用贝叶斯估计来计算概念语义相似度,文献[8]利用中文维基百科的结构化信息抽取来进行词语相似度计算,文献[9-13]则使用网络搜索引擎算法来计算词语相似度。
基于网络搜索引擎的语义相似度算法普遍采用基于查询返回页面数和基于查询结果片段的方法来进行语义相似度的计算。文献[9]使用基于搜索结果片段的相关性双重检测(Co-Ocurrence Double Check, CODC)算法进行语义相似度计算,该算法对相关性较高的词对能得出较好的计算结果,但是对相关度较低的词对的计算结果为0,单独依靠语义搜索片段计算相似度得出的结果存在片面性。文献[10] 使用基于词汇搜索页面数的点互信息(Pointwise Mutual Information, PMI)法计算语义相似度,该方法无法避免噪声和冗余数据对计算结果的影响,同样具有片面性。文献[11]同时分析了CODC和PMI两种方法,提出根据不同情况,使用不同的算法。如果两个词的语义相关性较强则使用CODC算法,否则使用PMI算法,这在一定程度上减轻了CODC和PMI两种算法各自的局限性,增加了结果的可信度,相比单一的方法,相似度计算效果有了一定的提升,但是相关系数依旧不及《知网》的结果。文献[12]利用Google搜索引擎独有的去除冗余的办法修改PMI算法,效果提升比较显著,但是该方法主要针对英文词汇语义相似度计算,中英文之间的差异和搜索引擎算法之间的差异使得该方法不适用于汉语词汇语义相似度计算。
基于搜索引擎的算法采用了大量的背景知识库,召回率较高,但是由于网络中的信息杂乱而繁多,噪声信息对实验结果产生影响难以避免。本文在分析和总结了传统方法的基础下,提出了融合《知网》和搜索引擎的词汇语义相似度算法,通过利用知网系统的层级结构和搜索引擎的搜索库,使词汇语义相似度结果相比传统方法更加符合人们的主观判断。
1 《知网》词汇语义相似度计算方法
基于《知网》的语义相似度计算方法主要包括了三个步骤。
步骤1 义原相似度计算。义原的相似度计算主要是利用《知网》中的词语的义原层次的语义距离来计算相似度,李峰等[14]在刘群等[2]提出的依据义原间的距离进行计算的方法的基础上,提出了一种即考虑义原距离又考虑义原层次深度的改进算法,是目前普遍认为的改进算法中效果较好的。
步骤2 概念相似度计算。文献[2]提出实词概念按义项表达式细分为第一独立义原表达式、其他独立义原表达式、关系义原表达式和符号义原表达式,并且使用固定大小的参数来定义4种表达式的权重,最后其概念语义相似度的计算公式为:

β1+β2+β3+β4=1,β1≥β2≥β3≥β4
其中:βi为可调节参数。该公式确保主要部分概念重要度大于次要部分概念,参数确定后不再变化,适用于所有类型的词汇概念相似度计算。文献[3]在前文的算法基础上提出了变系数的概念相似度计算方法,该文认为第一义原表达式的概括性太强,不适合给定较大的权值,并且《知网》对于第一义原的选取有主观性因素,然后该文提出将各类型义原集合中所包含的个数作为参数权值的选取标准,其具体公式如下:
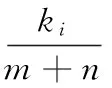
其中:ki代表两个概念划分后第i类义原描述式集合的元素个数之和;m和n为两个概念表达式的表达式个数;权重系数βi经过计算,其值与义项表达式数量有关。对比文献[2]和文献[3]的两种方法可看出,文献[3]方法更加灵活,对不同的词汇相似度也更加准确,适用于大部分的词汇语义相似度比较;但是该方法对于某类字面和现实意义都很相关的词汇来说,其计算结果不够准确,例如“阿拉伯”和“阿拉伯人”的相似度结果就不够合理。
步骤3 词语相似度计算。Lin[15]认为任何事物的相似度取决于它们之间的共性与个性,文献[2]认为词语之间的相似度即是两个词汇在不同的上下文环境中可以互相替换而不改变其句法结构的程度;文献[2]还认为实词与虚词之间得到相似度为0,实词与实词的相似度则取义项所有组合中相似度的最大值,考虑到所用对比词汇并非从具体的语境中提取,所以使用该方法计算词语的相似度是合理的。
2 本文算法
本文方法分为两个步骤:首先计算基于《知网》的词汇语义相似度,且沿用传统的三个步骤并采用文献[4]方法计算未登录词的相似度,由于《知网》在计算某类特定词汇的概念相似度时与人们的主观看法之间存在偏差,所以在此部分中对概念语义相似度进行了改进;然后,在基于《知网》的词汇语义相似度结果的基础上,引入搜索引擎算法,对词汇语义相似度计算结果进行修正。
2.1 基于《知网》的词汇语义相似度算法改进
目前对词汇语义相似度结果的评价没有公认的标准,主要依赖人工评测。《知网》目前主要由人工编写,部分词语的相似度计算结果与人们的主观判断偏差较大。其中,本文发现词语“阿拉伯人”和“阿拉伯”,“玻利维亚”和“玻利维亚诺”的相似度结果偏低,原因在于两对词语的第一义原表达式相似度较低,阿拉伯人是人,阿拉伯是地名,玻利维亚是国家地名,玻利维亚诺是当地通用的货币,所以传统《知网》的方法得出的相似度很低,其中“阿拉伯人”与“阿拉伯”的相似度为0.270,“玻利维亚”和“玻利维亚诺”的相似度为0.275,这是不合理的;2016年NLPCC评测会议给出了一组测试用例,它选择20位研究生对词对的相似度进行主观判断并给出一个1~10的分数,最终结果取他们的平均值,其中他们对词对“阿拉伯人”和“阿拉伯”的相似度判断为7.2,转换成0~1的数值就是0.72,远高于《知网》给出的0.27。通过分析发现,计算词语间的相似度时,如果词对中的一个词完整地出现在另一个词的义原解释当中,那么两个词应该具有较高的相似度,所以,本文在计算概念相似度时添加一条规则。
规则1 如果词对中某词完整地出现在另一个词的义原解释中,则二词的概念义原相似度结果提高;如果词对中某词只是字面上出现在另一个词语的组成结构中,则概念语义相似度结果不产生变化,如词对“阿拉伯”和“阿拉伯人”,“太平”和“太平洋”,它们在《知网》中的义原解释如表1所示。
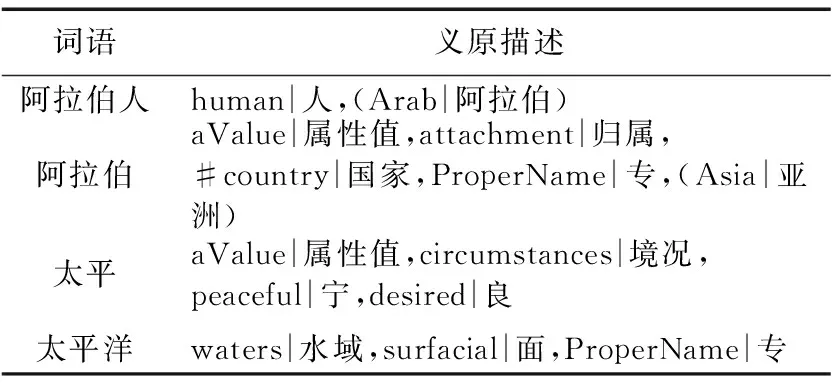
表1 词对义原描述
词语“阿拉伯人”不仅在字面上包含了词语“阿拉伯”,而且在其义原解释项中也包含了词语“阿拉伯”;而词对“太平洋”和“太平”中,词语“太平洋”仅在字面上包含了词语“太平”,在义原解释项中并没有包含完整的词语“太平”,因此在计算相似度时不予以添加相似度。基于上述考虑,在原有概念相似度公式基础上,加入词语义原数量与被包含词之间的比例关系,用于揭示被包含词在相似度计算中的重要度。例如,一个词有8个义原解释,其中包含了一个计算对象词,那么可见这个计算对象词对基于义原的相似度计算结果影响不大;反之,如果一个词只有1个义原解释,而这个义原又恰好是计算对象词,那么两者之间的相似度必然很高。
因此改进的概念相似度计算公式如下:
(1)
其中:sj表示s1和s2中义原里包含了另一词的词(j取1或2),Num(sj)为词sj所包含的义原数。改进后对于某些词对得出的相似度结果如表2。
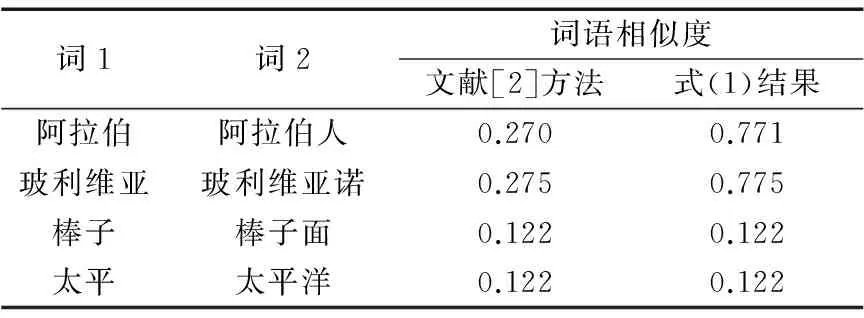
表2 两种方法词语相似度结果
从结果上看,第1、2组词的相似度有一定提高,而第3、4组词的相似度没有提高,原因在于两个词对都只在字面上相似,不满足规则1的条件,相似度没有增加,证明了规则1的合理性。
2.2 基于搜索引擎的词汇语义相似度算法改进
在网络文化发展过程中,很多词汇有了新含义,如“神马”表示“什么”的意思。传统《知网》知识库的更新速度无法赶上网络知识增长的速度,而网络搜索引擎则可以实时反映网络中新增的知识,所以利用搜索引擎修正《知网》的计算结果是合理的。
本文基于查询页数和页面片段信息结合的搜索引擎方法进行词汇语义相似度计算,查询页数指查询包含词汇或词对的网页数目。文献[12]使用Google搜索引擎,而本文所研究的是中文词汇语义相似度计算,所以选择最大的中文搜索引擎百度搜索引擎。
常用的基于查询页面的语义相似度计算方法有Jaccard、Overlap、Dice、PMI四种算法,且PMI的算法相对效果最好,PMI算法如下:
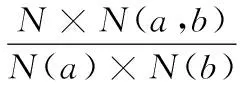
其中:N=1011,为Google的索引页面数。本文尝试了PMI算法计算中文语义相似度,效果不理想,究其原因,Google搜索引擎与百度搜索引擎在搜索结果上存在一定的差异,如Google搜索引擎的搜索页面数没有上限,百度查询页面数上限为108条,在Google上搜索“dog”有14.3亿条页面记录,搜索“狗”则有5亿条,而百度上搜索“狗”结果为上限1亿条。所以本文对该算法进行修改,使得该公式更适合于中文词汇相似度计算,修改如下:

谷歌搜索页面数没有上限,则变相的其页面上限数就是索引页面数N,所以公式中使用参数Nb等于百度查询页面上限数108来代替N,由于查询“a和b”与查询“b和a”的页面结果数有一个比较小的差异,这和搜索关键字算法有关,为了计算结果准确性,Nb(a,b)取查询“a和b”和查询“b和a”的结果数的平均值。
文献[9]提出了基于页面片段信息的双重检测算法CODC,其对于语义相关性比较强的词预测准确度比较高,计算公式如下:

2.3 融合《知网》与搜索引擎的词汇语义相似度计算
基于《知网》的词汇语义相似度计算方法考虑词对的语义信息,忽略了词对之间的关联关系;基于搜索引擎的词汇语义相似度计算算法考虑词对之间的关联关系,忽略了词对之间的底层语义;而融合两者的词汇语义相似度计算结果可以提高最终结果的精度。本文研究发现搜索关键字后查询返回的页面结果数越多,则该关键字的义原描述越接近义原层次体系树的根节点,如:“时间”“空间”等,该类词在搜索引擎中的搜索页面结果数为上限108条,其在《知网》中的义原定义稳定,语义不会偏移,《知网》计算该类词的语义相似度的准确度较高。为证明以上猜想,遂构造回归模型求取融合权值,具体如下:
Sim(a,b)=(1-w1)×SimZ(a,b)+w1×SimS(a,b);w1=sigmod(w2×lgn1+w3×lgn2)
SimS(a,b)=sigmod(w4)×CODCB(a,b)+ (1-sigmod(w4))×PMIB(a,b)
其中:w1表示搜索引擎计算结果的权重参数,它由词对的页面结果数和其相关系数w2与w3决定;sigmod函数保证了权值结果的值域在0~1;L(y,w)是均方误差(Mean Squared Error, MSE),表示相似度结果的损失函数;m代表样例数。本次实验使用批量梯度下降算法学习权值参数,实验中设定步长为0.05。本文选取了2016NLPCC会议提供的中文词汇语义相似度样本数据40条,以及实验数据10 000条中NLPCC会议提取并标注人工评测结果的500条作为本次实验数据,从中随机选取了270条作为训练数据进行实验。
训练结果显示,均方误差为1.46时收敛,此时CODC方法权重参数w4为0.37,搜索引擎权重的参数w2为-0.15,w3为-0.14。实验结果表明搜索引擎相似度计算结果的权值与搜索返回页面数呈负相关,验证了本文观点。
3 实验与分析
本次实验采用基于《知网》的中文词汇语义相似度计算方法,以及基于搜索引擎的中文词汇语义相似度算法修正算法。为验证方法的有效性,实验选取了NLPCC会议提供的540条数据。该样本数据和实验数据的标准语义相似度由20名会议人员人工标注并取其平均值得出,可靠性较高。随机抽取了270条作为权值训练数据,将剩下的270条作为测试数据。一共选取了三种相似度算法,分别是文献[5]的改进《知网》算法、文献[13]的利用搜索引擎的算法以及本文算法,分别对270条测试数据进行词汇语义相似度计算,然后使用斯皮尔曼(Spearman)系数和皮尔逊(Pearson)系数评价其准确性,结果如表3,可以看出本文方法得出的结果相对其他算法更好。

表3 相关系数
由于篇幅有限,本文选取了样本数据40条中的前20条进行具体分析,结果如表4所示。
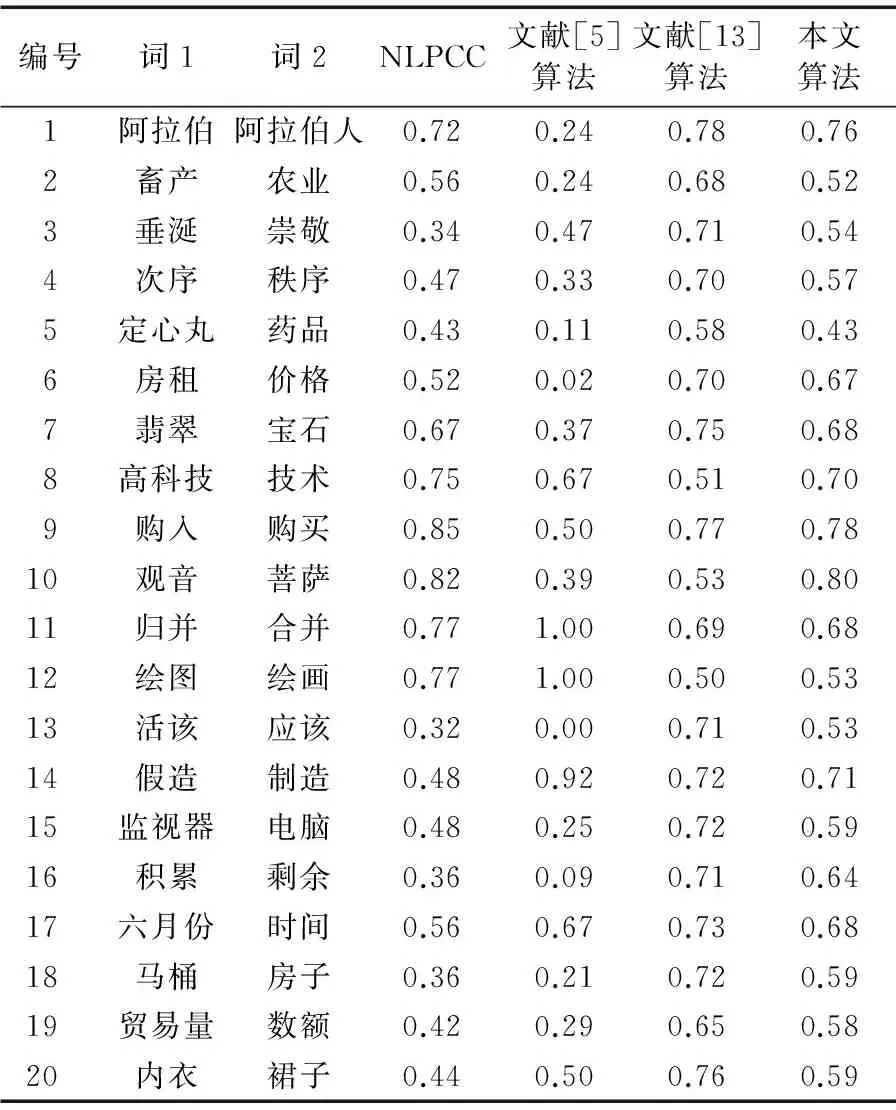
表4 抽样词语的相似度结果
实验结果分析:
比较NLPCC评测的人工评测结果和文献[5]对《知网》的改进计算,在很多词对上二者的相似度结果差异依旧较大,文献[5]的算法中第11行,第12行结果为1,偏大,第13行结果为0,偏小,本文认为原因是《知网》中对11,12行的二词义原解释定义完全相同,以及其对于实词和虚词的相似度结果直接判定为0,文献[5]对概念语义相似度的计算作出了改进,但是依然无法保证该类词对的相似度的准确度。
比较《知网》和PMI算法结果与NLPCC评测最佳结果之间的差异,传统的PMI算法对于中文的词语计算语义相似度整体结果较高,其算法原理与《知网》不同,二者结果分歧较大,例如第1行的词对,《知网》从底层语义的角度考虑,给出了一个较低的相似度,搜索引擎则从二词的相关度和联系性考虑,给出的相似度结果较高;PMI算法在某些词汇上的结果不合理,如第3行,第13行的结果过大,本文认为,其原因主要是:“垂涎”和“尊敬”的网页结果多出自一篇新闻的两个分标题,属于噪声信息,“活该”和“应该”在网上经常出现在一句话里,并出现在各种微博和短文中,因此PMI给计算结果很高。最后从整体上看,知网给出的部分结果偏低,PMI算法给出的部分结果偏高。
综合3种方法结果进行比较,本文总体上结果比《知网》和搜索引擎算法结果更加符合NLPCC给出的人工评测结果。第11行的结果从知网给出的1.0降到0.8,与NLPCC给出的0.68更为接近;第5行的结果升高到0.43与会议给出的结果一致;第16行的相似度从0.06提高到了0.64,与会议给出的0.36还是有部分差距;第14行,第18行的结果相比过高,本文认为原因在于二词虽然相似度不高,但存在较强的联系性使得人们经常将二词放在一起使用或搜索,从而提高了搜索引擎对二词的相似度的判断。作者将在下一个阶段对该类问题进行研究。
4 结语
本文充分考虑《知网》的算法特点,提出一种利用搜索引擎搜索词汇结果片段和网页数修正《知网》计算结果的算法,提出了利用回归函数训练融合权值的方法,并对某词的义原中包含另一个词的词对的《知网》概念相似度算法进行改进。从实验数据来看,本文提出的改进算法计算结果相对《知网》和搜索引擎的算法得到的准确性更高,更加符合人们的直观感受。接下来,将深入研究搜索引擎对词汇相似度的计算机制,并利用搜索引擎完善知网的未登录词问题,从而进一步改善词汇语义相似度的计算合理性。
)
[1] 董强, 董振东.知网简介[EB/OL]. [2013- 01- 29].http://www.keenage.com/zhiwang/c_zhiwang.html.(DONGQ,DONGZD.HowNetknowledgedatabase[EB/OL]. [2013- 01- 29].http://www.keenage.com/zhiwang/c_zhiwang.html.)
[2] 刘群, 李素建.基于《知网》的词汇语义相似度的计算[EB/OL]. [2015- 01- 12].http://www.nlp.org.cn/Admin/kindeditor/attached/file/20130508/20130508094157_16839.pdf.(LIUQ,LISJ.WordsimilaritycomputingbasedonHowNet[EB/OL]. [2015- 01- 12].http://www.nlp.org.cn/Admin/kindeditor/attached/file/20130508/20130508094157_16839.pdf.)
[3] 王小林, 王义.改进的基于知网的词语相似度算法[J]. 计算机应用, 2011, 31(11):3075-3077.(WANGXL,WANGY.ImprovedwordsimilarityalgorithmbasedonHowNet[J].JournalofComputerApplications, 2011, 31(11): 3075-3077.)
滤波是将信号中特定波段频率滤出的操作,是抑制和防止干扰的一项重要措施。在计算机视觉中,常常利用滤波如高斯滤波来对图像进行处理,当然,为了提升运算速度,也会直接使用奇数阶的方阵以用于对图像进行卷积运算。具体的操作就是对于图像的每一个像素点,计算他的邻域像素和滤波器矩阵的对应元素的乘积,之后加起来即可,作为该像素点的值。通过这一操作,将灰度图像执行了平滑在操作,如图1所示。
[4] 夏天.汉语词语语义相似度计算研究[J]. 计算机工程, 2007, 33(6):191-194.(XIAT.StudyonChinesewordssemanticsimilaritycomputation[J].ComputerEngineering, 2007, 33(6): 191-194.)
[5] 朱征宇, 孙俊华.改进的基于《知网》的词汇语义相似度计算[J]. 计算机应用, 2013, 33(8):2276-2279.(ZHUZY,SUNJH.ImprovedvocabularysemanticsimilaritycalculationbasedonHowNet[J].JournalofComputerApplications, 2013, 33(8): 2276-2279.)
[6] 朱新华, 马润聪, 孙柳, 等.基于知网与词林的词语语义相似度计算[J]. 中文信息学报, 2016, 30(4):29-36.(ZHUXH,MARC,SUNL,etal.WordsemanticsimilaritycomputationbasedonHowNetandCiLin[J].JournalofChineseInformationProcessing, 2016, 30(4): 29-36.)
[7] 吴奎, 周献中, 王建宇, 等.基于贝叶斯估计的概念语义相似度算法[J]. 中文信息学报, 2010, 24(2):52-57.(WUK,ZHOUXZ,WANGJY,etal.AconceptsemanticsimilarityalgorithmbasedonBayesianestimation[J].JournalofChineseInformationProcessing, 2010, 24(2): 52-57.)
[8] 张春红.中文维基百科的结构化信息抽取及词语相关度计算[D]. 武汉:华中师范大学, 2011.(ZHANGCH.ExtractingstructuredinformationfromtheChineseWikipediaandmeasuringrelatednessbetweenwords[D].Wuhan:CentralChinaNormalUniversity, 2011.)
[9]CHENHH,LINMS,WEIYC.NovelassociationmeasuresusingWebsearchwithdoublechecking[C]//Proceedingsofthe21stInternationalConferenceonComputationalLinguisticsandthe44thAnnualMeetingoftheAssociationforComputationalLinguistics.Stroudsburg,PA:AssociationforComputationalLinguistics, 2006: 1009-1016.
[10]CILIBRASIRL,VITANYIPMB.TheGooglesimilaritydistance[J].IEEETransactionsonKnowledgeandDataEngineering, 2007, 19(3): 370-383.
[12] 陈海燕.基于搜索引擎的词汇语义相似度计算方法[J]. 计算机科学, 2015, 42(1):261-267.(CHENHY.MeasuringsemanticsimilaritybetweenwordsusingWebsearchengines[J].ComputerScience, 2015, 42(1):261-267.)
[13]BOLLEGALAD,MATSUOY,ISHIZUKAM.AWebsearchengine-basedapproachtomeasuresemanticsimilaritybetweenwords[J].IEEETransactionsonKnowledgeandDataEngineering, 2011, 23(7): 977-990.
[14] 李峰, 李芳.中文词语语义相似度计算——基于《知网》2000[J]. 中文信息学报, 2007, 21(3):99-105.(LIF,LIF.AnnewapproachmeasuringsemanticsimilarityinHowNet2000 [J].JournalofChineseInformationProcessing, 2007, 21(3): 99-105.)
[15]LIND.AninformationtheoreticdefinitionofsimilaritysemanticdistanceinWordNet[C]//ICML1998:Proceedingsofthe15thInternationalConferenceonMachineLearning.SanFrancisco,CA:MorganKaufmann, 1998: 296-304.
[16]FIRTHJR.Asynopsisoflinguistictheory1930—1955 [J].StudiesinLinguisticAnalysis(SpecialVolumeofthePhilologicalSociety), 1957, 41(4): 1-32.
ThisworkispartiallysupportedbyNationalNaturalScienceFoundationofChina(61402220, 61502221),theScientificResearchProjectofHunanProvincialEducationDepartment(16C1378, 14B153, 15C1186),thePhilosophyandSocialScienceFoundationofHunanProvince(14YBA335).
ZHANG Shuowang, born in 1993, M. S. candidate. His research interests include natural language processing.
OUYANG Chunping, born in 1979, Ph. D., associate professor. Her research interests include semantic Web, emotion analysis.
YANG Xiaohua, born in 1963, Ph. D., professor. His research interests include information retrieval, public opinion analysis.
LIU Yongbin, born in 1978, Ph. D., lecturer. His research interests include knowledge graph, natural language processing.
LIU Zhiming, born in 1972, Ph. D., professor. His research interests include information retrieval, big data analysis.
Word semantic similarity computation based on integrating HowNet and search engines
ZHANG Shuowang, OUYANG Chunping*, YANG Xiaohua, LIU Yongbin, LIU Zhiming
(College of Computer Science and Technology, University of South China, Hengyang Hunan 421001, China)
According to mismatch between word semantic description of “HowNet” and subjective cognition of vocabulary, in the context of making full use of rich network knowledge, a word semantic similarity calculation method combining “HowNet” and search engine was proposed. Firstly, considering the inclusion relation between word and word sememes, the preliminary semantic similarity results were obtained by using improved concept similarity calculation method. Then the further semantic similarity results were obtained by using double correlation detection algorithm and point mutual information method based on search engines. Finally, the fitting function was designed and the weights were calculated by using batch gradient descent method, and the similarity calculation results of the first two steps were fused. The experimental results show that compared with the method simply based on “HowNet” or search engines, the Spearman coefficient and Pearson coefficient of the fusion method are both improved by 5%. Meanwhile, the match degree of the semantic description of the specific word and subjective cognition of vocabulary is improved. It is proved that it is effective to integrate network knowledge background into concept similarity calculation for computing Chinese word semantic similarity.
semantic similarity; HowNet; search engine; weight; network
2016- 09- 23;
2016- 10- 26。 基金项目:国家自然科学基金资助项目(61402220,61502221);湖南省教育厅科研项目(16C1378,14B153,15C1186);湖南省哲学社会科学基金资助项目(14YBA335)。
张硕望(1993—),男,湖南湘潭人,硕士研究生,主要研究方向:自然语言处理; 欧阳纯萍(1979—),女,湖南衡阳人,副教授,博士,CCF会员,主要研究方向:语义Web、情感分析; 阳小华(1963—),男,湖南衡阳人,教授,博士,CCF会员,主要研究方向:信息检索、舆情分析; 刘永彬(1978—),男,河北邯郸人,讲师,博士,CCF会员,主要研究方向:知识图谱、自然语言处理; 刘志明(1972—),男,湖南浏阳人,教授,博士,CCF会员,主要研究方向:信息检索、大数据分析。
1001- 9081(2017)04- 1056- 05
10.11772/j.issn.1001- 9081.2017.04.1056
TP391.1
A
猜你喜欢
疯狂英语·新阅版(2020年11期)2020-12-21
北方文学(2017年9期)2017-07-31
现代交际(2017年13期)2017-07-18
小天使·三年级语数英综合(2017年6期)2017-06-07
小天使·三年级语数英综合(2017年6期)2017-06-07
北方文学·下旬(2017年3期)2017-04-20
科技视界(2016年5期)2016-02-22
中国卫生(2015年12期)2015-11-10
火炸药学报(2014年3期)2014-03-20
科学导报·学术论坛(2013年5期)2013-06-26
