
基于线性判别分析的室内声源定位方法
2017-06-27 08:14:13顾晓瑜
计算机技术与发展 2017年6期
杨 悦,顾晓瑜
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
基于线性判别分析的室内声源定位方法
杨 悦,顾晓瑜
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
在小信噪比和混响时间较长的恶劣环境下,基于模式分类的手段能够有效克服传统的声源定位算法鲁棒能力不足的缺点,其中朴素贝叶斯分类器定位的准确率高,计算量小,鲁棒能力强。在此基础上,为了获得更好的定位性能,提出使用线性判别分析(LDA)分类器进行声源定位。使用Matlab进行仿真,截取声源信号的相位变换加权广义互相关函数(PHAT-GCC)作为特征向量,通过投影变换,找到最佳的特征空间来区分特征数据,从而训练得到线性判别分析分类器。然后在不同的混响时间和信噪比的条件下,进行定位测试,比较了线性判别分析分类器和朴素贝叶斯分类器的性能。仿真结果表明,在环境恶劣场合更宜使用线性判别分析分类器,特别是混响严重时,线性判别分析分类器的定位准确率比朴素贝叶斯分类器高1%~2%。
声源定位;相位变换加权广义互相关函数;LDA分类器;朴素贝叶斯分类器
0 引 言
基于麦克风阵列的声源定位技术一直是国内外研究的一项热点。它的主要原理是:通过具有一定几何拓扑结构的麦克风阵列采集声源信号,通过阵列信号处理技术对语音信号进行处理和分析,从而确定声源位置。基于麦克风阵列的声源定位技术已广泛应用于许多领域,如视频会议、声音检测、语音增强、语音识别、说话人识别、智能机器人、监控监听系统、助听装置等。传统的声源定位技术研究大体上分为三类:基于最大输出功率可控波束形成技术、基于高分辨率谱估计技术、基于时延估计技术。其中,基于广义互相关时延估计算法(Generalized Cross-Correlation,GCC)由于其计算量小、方法简单、容易实现,得到了广泛应用[1-3]。
由于房间墙壁的吸收,声源发出的声波在各方向来回反射,又逐渐衰减的现象,称为室内混响。当声源停止后,从初始的声压降到60 dB所需的时间称为混响时间,在这里用T60表示室内声音的混响时间[1-2]。室内混响的存在,对时延估计影响很大。因此,对于声源定位算法来说,如何提高抗噪声和抗混响能力是长久以来的研究重心,很多改进方法的提出对克服糟糕的环境影响有一定的作用,如对GCC进行加权处理[4-5],但是在信噪比很小,混响很严重的情况下,基于传统算法的改进措施很难有明显的效果;此外当麦克风无法接收到声源的直达声时,也难以定位。
近年来,随着统计机器学习的发展,很多传统的问题有了新兴的解决方式[6],声源定位领域也是如此。文献[7-8]提出了针对头相关函数(HRTF)特征提取并通过K-Means聚类和神经网络进行声源定位的方法;文献[9-10]使用朴素贝叶斯分类器,通过鉴别互相关函数的方法进行声源定位。这类方法能有效解决传统声源定位算法的缺点,不仅有很好的鲁棒性,而且计算效率高。
在此基础上,为了能够进一步提高在恶劣条件下声源定位的效果,提出采用LDA(线性判别分析)分类器鉴别相位变换加权广义互相关函数来进行声源定位的方法,并对其进行了实验。
1 PHAT-GCC
PHAT-GCC(PHAse Transform Generalized Cross -Correlation)方法是经典的基于时延的声源定位技术之一。轻量级的计算复杂度和易于实现的特点使其应用广泛。
由于来自同一声源的信号具有一定的相关性,通过计算不同麦克风接收到的信号的相关函数,由相关函数的峰值可以确定时延差,从而计算出声源的位置。相关函数的计算如式(1):
(1)

然而在实际环境中,由于噪声和混响的影响,相关函数的最大峰会被弱化,有时还会出现多个峰值,给实际峰值检测带来了困难。因此,对于互相关函数法,常使用加权函数突出时延峰值来减小混响和噪声的影响,其中PHAT(相位加权)能在噪声较小时有效地抗混响。相位加权广义互相关函数的计算如式(2):
(2)
(3)
其中,ψ1,2(ω)为相位加权,相当于白化滤波,改进后的互功率谱是一个纯相位函数,它的幅值为1,因此PHAT加权是用相位的信息来求时延。
但当噪声增大时,信噪比较低的频率逐渐增多,PHAT-GCC的性能逐渐下降,这种方法就不管用了。对于PHAT-GCC来说,当噪声和混响严重时,可能会出现多个虚假谱峰,但是在相同的室内环境下,同一位置声源引起的混响对谱峰的干扰是类似的,如果使用模式识别的方法,将带有混响的信号的PHAT-GCC作为特征,而非峰值检测的方法。由混响产生的虚假谱峰也能看成是一种特征,可以一定程度上减小混响的影响,在小信噪比的情况下定位性能不至于迅速下降,比传统的时延定位算法有更强的鲁棒性。
2 线性判别分析
LDA是一种经典的线性学习方法,也称“Fisher判别分析”,常常作为特征提取和降维算法用于人脸识别、人脸检测中[11-13],也可直接作为分类器使用[14-16]。其思想是将高维的样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,使投影后的样本在新的子空间有最大的类间距离和最小的类内距离,从而能更好地分辨模式类别[17]。LDA投影示例如图1所示[18]。

图1 LDA投影示例
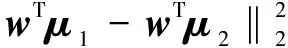
则引入目标函数J:
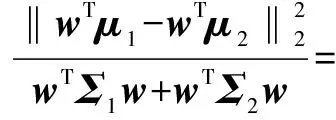
(4)
定义“类内散度矩阵”为:
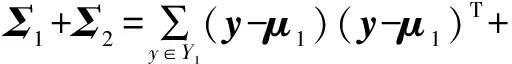
(5)
定义“类间散度矩阵”为:
Sb=(μ1-μ2)(μ1-μ2)T
(6)
则式(3)可重写为:
(7)

计算出LDA模型参数后,即可将测试样本数据y投影到w上,得到投影结果Z=wTy。再由判决式(8)决定类别:
(8)
(9)
其中,N1和N2分别是第一类训练样本和第二类训练样本的个数。
3 基于LDA分类器的声源定位方法
3.1 PHAT-GCC特征提取
在房间中放置2个麦克风的麦克风阵,位于ls的声源S到第i个麦克风的房间脉冲响应为hi(ls,t)(i=1,2)。设声源S发出的信号为s(t),则麦克风接收到的信号为xi(t)=hi(ls,t)*s(t),其离散傅里叶变换为Xi(k)。由式(2)可以求得长度为K帧的PHAT-GCC:Rj(τ),j=1,2,…,K。
对于任意一帧Rj(τ),截取特征数据:

(10)
(11)
其中,round为取整函数;D为麦克风间距;fs为采样频率;c为声速;因子α设为1.67。
即截取PHAT-GCC谱线上所有可能取得谱峰的时延点的数据,转化为特征数据集,最终可以得到:Y=[y1,y2,…,yK]。
3.2 训练LDA分类器模型
声源位于L个不同的方位角,即分类目标有多种类别,因此需要训练多分类LDA模型。对于LDA的多分类问题,可以直接从二分类问题的求解方式推广出来,也可以使用“One vs Rest”或“One vs All”方法[17]将多分类任务拆分成若干个二分类任务来实现。这里通过直接多分类的方式求解模型。
对于L个类别的训练数据Yi(i=1,2,…,L),使用D个投影向量W=[w1,w2,…,wD],对K帧训练数据进行投影,结果为Z=WTYi。此时类内散度矩阵由式(5)推广到:
(12)
(13)
类间散度矩阵由式(6)推广到:
(14)
其中,μ为全体样本均值。
此时目标函数可选择:
(15)
其中,tr(·)表示矩阵的迹。

3.3 定位测试
对于K'帧的测试数据,可以使用单帧PHAT-GCC数据测试一个方位,测试K'次;也可以同时使用多帧数据进行定位。
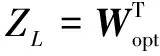
LDA分类器的声源定位流程见图2。

图2 LDA分类器的声源定位流程
4 仿真实验
实验使用Matlab R2014A进行仿真。使用RoomSim工具包[19]模拟室内环境,使用LDA分类器在小信噪比和较严重的混响环境下进行定位,并将结果和朴素贝叶斯分类器的定位结果进行对比。
4.1 实验数据
仿真的房间尺寸为8 m×6 m×3 m,使用2个麦克风组成麦克风阵,麦克风阵位于(4,2.5,1.5)处,麦克风间距0.3 m;对接收到的信号分帧加汉宁窗,每帧512点,帧移256点,即每帧信号长度32 ms,使用100帧训练数据Ytrain=[y1,y2,…,y100]和400帧测试数据Ytest=[y101,y102,…,y500];声源信号采用麻省理工学院TIMIT语音库的语音。声源位于以麦克风阵中点为圆心,半径为2 m的圆弧上,方向角为10°、30°、50°、70°、90°、110°、130°、150°、170°共9个位置,如图3所示。

图3 仿真的房间平面图
实验参数如下:中等的混响时间T60=300 ms和严重的混响时间T60=600 ms;加性白噪声信噪比为clean(无噪)、25 dB、20 dB、15 dB、10 dB和5 dB;特征属性使用单帧PHAT-GCC。
4.2 结果与分析
在混响时间T60=300 ms和T60=600 ms这两种情况下,分别比较了LDA算法和朴素贝叶斯算法在6种信噪比情况下的定位准确率,如图4和图5所示。
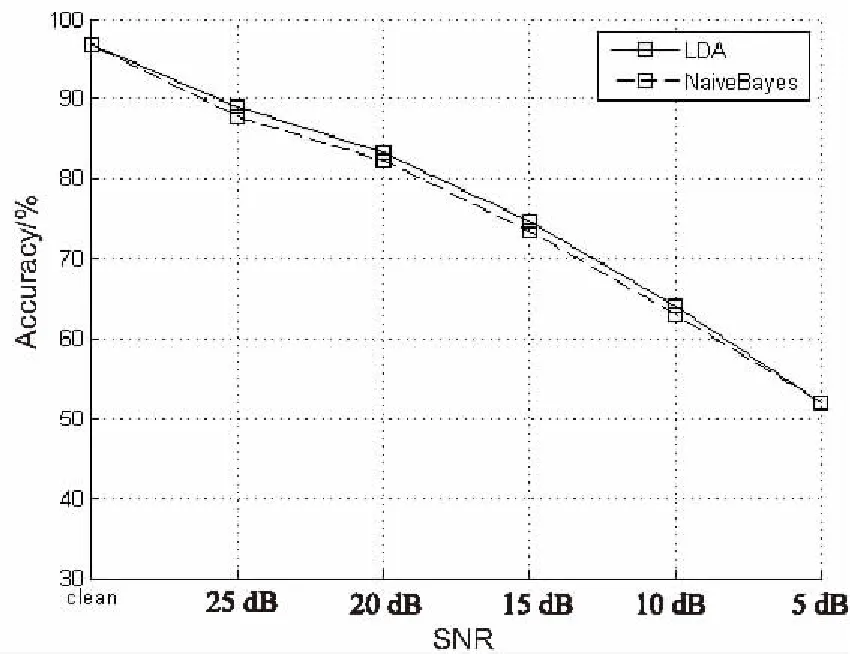
图4 T60=300 ms时的定位准确率比较
从实验结果中可以看出,定位准确率随着信噪比的降低而降低,随着混响的加强而降低。在T60=300 ms时,信噪比为25 dB,20 dB,15 dB,10 dB的情况下,使用LDA算法定位的准确率相比朴素贝叶斯算法有1%左右的小幅提升。当T60=600 ms时,6种信噪比的情况下,使用LDA算法定位的准确率相比朴素贝叶斯算法都有明显提升,能提高2%左右的准确率。显然,混响严重的情况下更宜使用LDA分类器进行定位。
5 结束语
为了提高恶劣环境下声源定位的性能,提出了一种基于LDA分类器的声源定位方法,使用PHAT-GCC作为特征。实验中仅使用了单帧(32 ms)PHAT-GCC作为特征属性,实际环境下可以使用多帧PHAT-GCC数据,能得到更高的准确率。实验结果表明,LDA分类器在声源定位的性能上优于朴素贝叶斯分类器,特别是在混响严重的情况下有明显优势,显著改善了在恶劣环境下声源定位的效果。
[1] 万新旺.基于阵列信号处理与空间听觉的声源定位算法研究[D].南京:东南大学,2011.
[2] 周 峰.室内麦克风阵列声源定位算法研究和实现[D].上海:复旦大学,2009.
[3] 刘 超.基于麦克风阵列的声源定位算法研究[D].南京:南京大学,2015.
[4] 崔玮玮,曹志刚,魏建强.声源定位中的时延估计技术[J].数据采集与处理,2007,22(1):90-99.
[5] 夏 阳,张元元.基于矩形麦克风阵列的改进的GCC-PHAT语音定位算法[J].山东科学,2011,24(6):75-79.
[6] 檀何凤,刘政怡.模式分类方法比较研究[J].计算机技术与发展,2015,25(2):99-102.
[7] 马 浩,吴镇扬,张 杰,等.与头相关传递函数的双耳特征提取与分类[J].电路与系统学报,2007,12(5):58-64.
[8] 马 浩,周 琳,胡红梅,等.基于与头相关传递函数的神经网络声源定位方法研究[J].电子与信息学报,2007,29(9):2058-2062.
[9] Wan Xinwang,Wu Zhenyang.Sound source localization based on discrimination of cross-correlation functions[J].AppliedAcoustics,2013,74(1):28-37.
[10] Wan Xinwang,Liang Juan.Improved sound source localization using classifier in reverberant noisy environment[J].Journal of Applied Science,2013,13(21):4897-4901.
[11] 李道红.线性判别分析新方法研究及其应用[D].南京:南京航空航天大学,2004.
[12] 王建国,杨万扣,郑宇杰,等.一种基于ICA和模糊LDA的特征提取方法[J].模式识别与人工智能,2008,21(6):819-823.
[13] 谢永林.LDA算法及其在人脸识别中的应用[J].计算机工程与应用,2010,46(19):189-192.
[14] Mansor M N,Rejab M N,Syam S,et al.Automatically infant pain recognition based on LDA classifier[C]//International symposium on instrumentation & measurement,sensor network and automation.[s.l.]:[s.n.],2012:380-382.
[15] Zhang Y,Zhou X,Witt R M,et al.Automated spine detection using curvilinear structure detector and LDA classifier[J].Neuroimage,2007,36(2):346-360.
[16] 陈惠勤,骆德汉.基于扩散映射和LDA的辛味中药材鉴别研究[J].计算机技术与发展,2015,25(5):192-195.
[17] 周志华.机器学习[M].北京:清华大学出版社,2016.
[18] Bishop C.Pattern recognition and machine learning[M].[s.l.]:Springer,2007.
[19] Campbell D.ROOMSIMtoolbox[EB/OL].2012-08-08.http://media.paisley.ac.uk/~campbell/Roomsim/.
Indoor Acoustic Source Localization Method with LDA
YANG Yue,GU Xiao-yu
(College of Telecommunications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
The method based on pattern classification can overcome the deficiency of traditional acoustic source localization algorithms which has an insufficient robust ability in the harsh environment of small SNR and severe reverberation.Among them,Naive Bayes classifier has high location accuracy with a small amount of calculation and strong robustness.In order to achieve better localization performance,Linear Discriminant Analysis (LDA) classifier is adopted to locate acoustic source on the basis of former research.It has been tested by Matlab,while the Phase Transform Generalized Cross-Correlation (PHAT-GCC) function would be used as feature vector.LDA classifier has been trained through projection transformation which could help to find a better feature space to discriminate the feature data.Subsequently,the source would be located in different reverberation and noisy conditions to compare the performance with LDA classifier and Naive Bayes classifier.The simulation results have demonstrated that LDA classifier is a better choice in harsh environment and that the location accuracy of LDA classifier is higher than that of Naive Bayes classifier by 1% to 2%,especially in severe reverberation environment.
acoustic localization;PHAT-GCC;LDA classifier;Naive Bayes classifier
2016-07-07
2016-10-13 网络出版时间:2017-04-28
江苏省自然科学基金(BK20140891);声纳技术国防科技重点实验室开放研究基金(KF201503)
杨 悦(1989-),男,硕士研究生,研究方向为语音处理、声源定位、机器学习。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1703.058.html
TP301
A
1673-629X(2017)06-0187-04
10.3969/j.issn.1673-629X.2017.06.039
猜你喜欢
舰船科学技术(2022年11期)2022-07-15 07:54:30
复旦学报(自然科学版)(2019年3期)2019-07-19 09:48:04
电子制作(2019年23期)2019-02-23 13:21:12
电子测试(2018年23期)2018-12-29 11:11:24
舰船电子工程(2018年11期)2018-11-26 07:55:08
剧作家(2018年2期)2018-09-10 01:47:18
小学科学(2016年12期)2017-01-06 19:36:17
噪声与振动控制(2016年5期)2016-11-09 09:09:47
西北工业大学学报(2015年3期)2015-12-14 13:08:44
做人与处世(2015年19期)2015-09-10 07:22:44
