
社会热点事件中评价对象分类研究
2017-06-26 12:49:24张志远杨宏敬
计算机与数字工程 2017年6期
张志远杨宏敬
(中国民航大学计算机科学与技术学院天津300300)
社会热点事件中评价对象分类研究
张志远杨宏敬
(中国民航大学计算机科学与技术学院天津300300)
随着微博等自媒体平台的迅猛发展,社会热点事件的传播速度越来越快,影响范围也越来越广。识别这些热点事件中的评论对象并对其进行分类可了解公众对事件责任主体的认定倾向,是舆情传播的重要研究内容之一。特征提取是文本分类的重要一环,传统的信息增益方法只考虑类别对特征的影响,而大量短微博中的特征很可能会被忽略,影响分类效果。论文在信息增益方法的基础上加入文本长度对特征的影响,在新浪微博上的实验表明,新方法的分类准确度较传统的信息增益方法有所提高。
微博;热点事件;评论对象;分类;信息增益
Class NumberTP391
1 引言
随着网络的普及和快速发展,其具备的强时效性和信息广泛性以及便利性等,使人们越来越倾向于在网络上表达自己对事件的看法。就目前来看,借用自然语言文字仍然是广大网民表达情感及观点的主流形式。微博作为各类新闻、事件等评论的载体,具有强大的社会舆论影响力和舆论导向作用。广大网友不仅能通过微博获取新闻时事讯息,更可以借助微博发表自己对事件的看法。在针对社会热点事件的评论中,网友对事件的看法一般都带有感情色彩,识别并确定网友的褒贬态度是舆情监控的重要内容之一。
存在这样一大类社会热点事件,由于这些事件本身和社会的基本价值观相悖,广大网友的态度容易形成一边倒的态势。如2015年11月的“南航急救门”事件中,乘客在突发疾病后相关单位人员均怕承担责任而互相推诿的事件曝光后,网络上以批评声者居多。因此在这种情况下,确定网友的评判对象是谁就显得更为重要了。一方面可以获悉广大网友认为事件到底是谁的责任,另一方面对涉事企业或个人而言,也可使其正确认识舆论倾向,并为其进一步正确引导舆论提供决策依据。
2 相关工作
一条微博评论可承载的信息形式可以是文本、图片、视频链接等,本文的主要研究对象是其中的文本内容。赵妍妍等[1]将文本情感分析分为情感信息的抽取、分类、检索与归纳三种任务。本文研究内容为从微博文本中获取网友的评价对象,属于情感信息抽取范畴。刘鸿宇等[2]使用句法分析结果获取候选评价对象,然后使用频率过滤以及名词剪枝等算法对候选评价对象进行筛选。另有部分学者使用条件随机场模型识别评论对象,如Hamdan等[3]使用CRF(Conditional Random Field)识别餐馆和笔记本电脑评论中的评价对象,林琛等[4]使用CRF识别社会热点事件中的评论对象。本文研究内容和文献[4]类似,不同之处在于本文并非识别具体出现在文本中的评论对象而是对其进行归类。例如关于“南航急救门”事件中责任相关方的红十字会,网友评论中有多种指称,如“红会”、“黑十字会”等,我们将其统一归为一类。因此,本文将评论中各涉事单位或个人看作不同类别,进而将评论对象识别转换为文本分类问题。
文本分类的步骤大致为:获取原始文本后,首先进行分词,并以某停用词表作为基准去除停用词,将文本表示为向量空间模型,进行特征选择,然后训练分类模型并进行测试。选取好的特征对训练分类器至关重要。TF-IDF(Term Freqency-Inverse Document Frequency)作为经典的特征提取算法,多次被前人进行过研究。王美芳等[5]在原始TF-IDF算法上提出了一种新的改进后的评价函数,此评价函数将类别信息引入到特征项中,使其提取出的特征项与类别相关,弥补了传统型TF-IDF的不足,提高了分类精度。贺飞艳等[6]等结合TF-IDF方法与方差统计方法,并将其应用于微博短文本的细粒度情感特征词提取,在NLP&CC2013的评测任务中取得了较好的成绩。
一些研究者尝试将TF-IDF和信息熵结合进行特征提取。周炎涛等[7]考虑词条文档在分类中的分布情况,在TF-IDF的基础上添加了信息熵因素,利用向量空间模型进行文本分类并取得较好的实验结果。郭红钰[8]也将信息熵与TF-IDF结合,提出了新的特征权重计算方法ETF-IDF。该方法综合考虑了特征项在文档中出现的频率和在训练集中的集中度以及其在各个类别中的分散度,可以更准确地表示文本,进而提高分类的精确程度。
Yang等[9]针对文本分类问题,分析和比较了多种特征提取方法,认为信息增益(Information Gain,IG)和卡方统计(chi-square statistic,CHI)效果较好。传统的信息增益方法只考虑类别对特征的影响,而短微博中的词汇在特征选择后很可能会被忽略,从而导致其无法被正确分类。本文在信息增益算法的基础上,考虑了微博短文本中的词汇对特征提取的影响,并将其应用于社会热点事件中的评价对象分类研究。
3 信息增益
信息增益是依据某特征项ti为整个分类所能提供的信息量多少来衡量该特征项的重要程度,从而决定对该特征项的取舍。信息增益由信息熵与条件熵的差值决定,其中信息熵表示随机变量的不确定性,熵越大,不确定性越大,则做出正确估计的可能性就越小。实际上,均匀分布时熵最大,最不具有区分意义。条件熵是指在给定条件下随机变量的不确定性。因此信息增益表示的是在给定条件下信息不确定性减少的程度。具体到文本分类,就是以某特征存在与否为条件。如果考虑进该特征后,后者的不确定性小了,则二者之差表示该特征带给我们的信息量大了,因此考虑将这个特征加入特征集。Yang等[9]定义了用于文本分类中特征选择的信息增益公式:
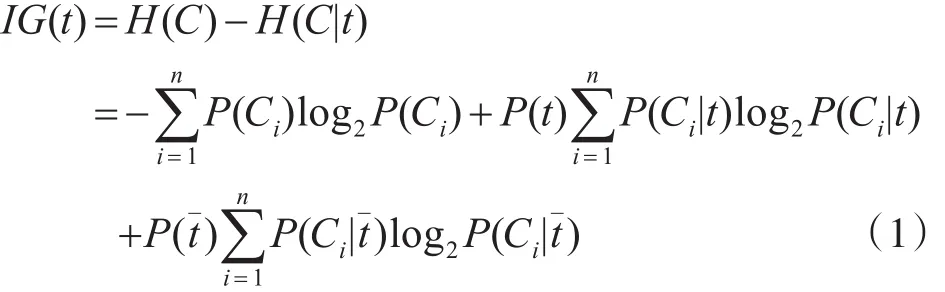
其中,t为单词,Ci表示第i个类别,n为类别总数。根据概率论知识,公式中其他部分也很容易得到。P(Ci)是第i类出现的概率,若每类平均出现,则P(Ci)=1/n。P(t)是单词t出现的概率,可用出现词语t的文档数与总文档数的比值估算。P(t)是单词t不出现的概率,可用1-P(t)估算。P(Ci|t)即t出现时,Ci出现的概率,可用出现t且属于Ci的文档数与所有出现t的文档总数的比值估算。P(Ci|t)即t不出现但属于Ci的概率,可用未出现t但属于Ci的文档总数与未出现t的所有文档数的比值估算。
4 算法设计
与前人不同的是,本方法考虑短文本中的特征词对分类的影响。为避免短文本中的特征词被忽略,增加了文本长度系数来提高短文本中特征词的权重,从而增加短文本的分类准确性。该系数由单词在所有微博条目中出现的比率加和得到,公式为

其中IG(t)由传统信息增益计算,Lit表示第i条微博中单词t出现的次数,Li表示第i条微博中的单词总数,N表示数据集中微博条目总数。为避免IG(t)和单词的文本长度系数之间大小差距悬殊的情况,对两者分别进行了归一化处理,即式(2)中的Normal函数。
短文本中的词汇由于Li值较小容易获得比较大的比值,反之长本文中的词汇要想获得比较大的比值,要么在同一篇微博中出现的次数比较多,要么出现在不同微博中的次数比较多一些。为分析该算法的有效性,我们比较了“南航急救门”事件中网民对于红十字会的多种表述方式在传统信息增益算法和本文改进算法中的排序位置,如表1所示。从表中可以看出,主流的表述方式如“红十字会”、“红会”由于出现次数较多,在两种算法中均占据了比较靠前的位置。而一些不太常见的表述方式如“红十字”、“红十会”、“黑十字会”、“黑十字”等的排序位置均比较靠后,但这些单词在本文算法中的排序位置均比传统的信息增益算法靠前,也就更容易被选择为特征词语。“中国红十字会”作为一个单位名称,并未被切分为“中国”和“红十字会”两个词语,由于这个词只在以下两篇短微博中出现过:

表1 “南航急救门”事件特征词排序示例
1)又是中国红十字会,厚颜无耻。
2)中国红十字会真是神一般的存在~999急救看来是999要人命啊!
因此获得了较高的文本长度系数,从而将排序位置由原来的126位提高到了24位。
5 实验与结果分析
5.1 实验数据集
实验数据使用八爪鱼采集器从Sina微博抓取。抓取的微博主要来自两个主题:南航急救门和维珍事件,分别获取了170条和319条微博。对于每条微博,都对其进行了手工情感标注,分为正向、负向、中立和无情感倾向四种。如引言所述,对于“南航急救门”事件,负面评论居多(负向111条,无情感48条,中立7条,正向4条)。我们仅研究其中的负向评论,并根据其中的评论对象对微博进行分类。由于某些评价对象在数据集中仅出现一两次,对这类微博条目予以删除。经过这些处理后,南航急救门事件剩余104条微博,维珍事件剩余197条微博。
手工标注了每条微博的评论对象以训练分类器,标注示例如表2和表3所示。由于微博中有很多口语用语或者名词简称,比如“红十字会”和“红会”其实指的是同一个机构,我们就把这类词都归为“红十字会”类。维珍事件中,出现很多“白人”“老外”“欧美”等,其实对象指向均为“外国人”,于是将其分类为“外国人”。这些有明显评价对象的,可以进行具体分类,但诸如“人命关天,有什么比生命更重要?”“烂尾的事情还少么”,这类文本并没有明确的评价对象指向,所以将它们分为“不明确”类。其中单条微博可能包含多个评价对象,本文将不同评价对象的组合作为单独的类别予以对待,如表3中的第4类“急救中心和民航”。

表2 “南航记者门”事件分类示例

表3 维珍事件分类示例
5.2 数据预处理
微博中经常出现一些http链接、@××等,这些信息对评价对象识别和分类没有什么用处,将其去掉。另外微博中经常会出现一些标题引用,如“道歉有什么用?该反思检讨改变了『南航机场急救门:真正恶劣的是后来的事…』”,后面的标题引用对于最后的评价对象分类易造成干扰,因此也将其去掉。
去除无用信息后进行分词,此处选择中科院张华平教授开发的自然语言分词系统NLPIR[10]进行分词,并采用哈工大停用词表作为基准,将文本中出现的停用词去掉。
5.3 基于规则的评价对象分类
给定评价对象,一般比较容易想到一些代表性的词汇。当微博中出现这些代表性词汇时,可以使用简单的规则对其进行分类,并将其结果作为测试基准。两类事件的分类规则如表4所示。若同时出现两种类别,则按5.1节所述作为一个新类别对待;若一种类别也没有出现,则将其分到“不明确”中。对两个数据集分别进行测试,所得准确率分别为67.27%和41.9%。由于维珍事件中关于中国人和外国人的描述具有很大的不确定性,很难找到合适的代表性词汇,因此准确率比较低。

表4 评价对象分类规则
5.4 实验结果与分析
对两个数据集以按类别分层抽样的方式平均分成三份,其中两份作为训练集,一份作为测试集,使用支持向量机作为分类器进行交叉验证,所得结果如表5所示。由于网络词汇极为丰富,表4中的规则很难覆盖到所有情况,因此当采用基于规则的方法将微博分到“不明确”类中时很可能会出现偏差。因此,本文还考虑了“规则+本文算法”的方法,如表5最后一行所示。本方法仅针对基于规则方法中分出的“不明确”类微博使用本文算法,而其他微博则使用原基于规则分类方法所得结果。

表5 实验结果汇总
在两个数据集的实验中,本文算法所得准确率分别为70.21%和55.78%,均高于基于规则的分类方法和传统的信息增益方法。而“南航急救门”事件中信息增益算法的准确率为63.4%,低于基于规则方法的67.27%,说明当评价对象的代表性词汇较为集中时,基于规则的方法虽简单,却也能收到不错的效果。采用“规则+本文算法”时“南航急救门”事件的正确率在四种方法中效果最好,达到了73.93%,但在“维珍事件”中该方法只有46.8%的准确率,仅略高于基于规则的方法。
从表5可以看出,本文算法在“南航急救门”事件的数据集上具有明显优势,而对于维珍事件来说,改进后的算法较原始的信息增益算法,虽然准确率略有提高,但并未达到预期效果。甚至在结合语义规则后,准确率反倒低了。为此,我们对实验数据进行了分析。由于本文中提出的算法是加入了短文本为考虑因素,于是我们从两个数据集的文本长短入手,假设我们规定文本短于30个字的为短文本,30字~50字之间的为中长度文本,多于50字的为长文本。分别计算出短、中、长文本在整个数据集中所占的比例,如图1所示。

图1 两个数据集的文本长短分布情况
其中,“南航急救门”事件中短、中、长文本占比分别为60.5%、13.5%、26%,而“维珍事件”中短、中、长文本对应的比例分别为5.6%、22.3%、72.1%。能够明显地看出“南航急救门”事件的数据集中,短文本占有相当大的比例,而“维珍事件”数据集则与此相反,长文本占了很大比例。这也表明了本文算法更适用于短文本较多的数据集,在长文本较多时,优势不甚明显。
6 结语
本文研究了从评价对象的角度对反应社会热点事件的微博进行分类的问题。针对微博中存在大量短文本,其中的特征词语易被忽略的问题,本文提出了在传统信息增益算法的基础上增添文本长度系数进行特征选择的方法,在新浪微博上的实验表明,新方法的分类准确度较传统的信息增益方法有所提高。
[1]赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,8:1834-1848.
ZHAO Yanyan,QIN bing,LIU ting.Sentiment Analysis[J].Journal of Software,2010,8:1834-1848.
[2]刘鸿宇,赵妍妍,秦兵,等.评价对象抽取及其倾向性分析[J].中文信息学报,2010,24(1):84-88.
LIU Hongyu,ZHAO Yanyan,QIN Bing,et al.Comment Target Extraction and Sentiment Classification[J].Journal of Chinese Information Processing,2010,24(1):84-88.
[3]Hamdan H,Bellot P,Béchet F.Supervised Methods for Aspect-Based Sentiment Analysis[C]//Proceedings of the 8thInternationalWorkshoponSemanticEvaluation(SemEval 2014),Dublin,Ireland,Aug.2014,596-600.
[4]林琛,王兰成.基于条件随机场的网民评论对象识别研究[J].现代图书情报技术,2013(6):63-67.
LIN Chen,WANG Lancheng.Object Recognition of Network Comments Based on Conditional Random Fields[J]. New Technology of Library and Information Service,2013(6):63-67.
[5]王美方,刘培玉,朱振方.基于TFIDF的特征选择方法[J].计算机工程与设计,2007,28(23):5795-5799.
WANG Meifang,LIU Peiyu,ZHU Zzhenfang.Feature selection method based on TFIDF[J].Computer Engineering and Design,2007,28(23):5795-5799.
[6]贺飞艳,何炎祥,刘楠,等.面向微博短文本的细粒度情感特征抽取方法[J].北京大学学报(自然科学版),2014,50(1):48-54.
HE Feiyan,HE Yanxiang,LIU Nan.A Microblog Short Text Oriented Multi-class Feature Extraction Method of Fine-Grained Sentiment Analysis[J].Acta Scientiarum Naturalium Universitatis Pekinensis,2014,50(1):48-54.
[7]周炎涛,唐剑波,王家琴.基于信息熵的改进TFIDF特征选择算法[J].计算机工程与应用,2007,43(35):156-171.
ZHOU Yantao,TANG Jianbo,WANG Jiaqin.An Improved TFIDF Feature Selection Algorithm Based On Information Entropy[J].Computer Engineering and Applications,2007,43(35):156-171.
[8]郭红钰.基于信息熵理论的特征权重算法研究[J].计算机工程与应用,2013,49(10):140-146.
GUO Hongyu.Research on term weighting algorithm based on information entropy theory[J].Computer Engineering and Applications,2013,49(10):140-146.
[9]Yang Y,Pedersen JO.A Comparative Study on Feature Selection in Text Categorization[C]//Fourteenth International Conference on Machine Learning.Morgan Kaufmann Publishers Inc.1997:412-420.
[10]NLPIR汉语分词系统[EB/OL].http://ctclas.nlpir.org/ downloads.(ICTCLAS2013)
Opinion Target Classification in Hot Social Events
ZHANG ZhiyuanYANG Hongjing
(School of Computer Science&Technology,Civil Aviation University of China,Tianjin300300)
With the rapid development of microblog from the media platform,the propagation velocity of the hot social events gets faster and faster,and the scope of influence becomes more widely as well.To recognize the target of these hot events reviews and classify them can identify the attitude of public for the tendency of the main responsibility of the events,and it is important for the research of the spread of public opinion.Feature extraction is an important part of text classification,and the traditional information gain only considers the impact on the characteristics of the category,large number of features in short microblog are potentially to be ignored,thus affecting the classification effect.This paper proposes a method based on the information gain that considers the length of text influence on feature.Experiments on Weibo shows that the classification accuracy of the new method is better than the traditional information gain.
microblog,hot events,opinion target,classification,information gain
TP391
10.3969/j.issn.1672-9722.2017.06.031
2016年12月3日,
2017年1月24日
张志远,男,副教授,研究方向:文本挖掘,数据仓库,复杂网络。杨宏敬,女,硕士,研究方向:情感分析。
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
电子制作(2019年19期)2019-11-23 08:41:36
时代英语·高二(2018年7期)2018-12-03 09:23:06
电子制作(2018年19期)2018-11-14 02:37:02
时代英语·高二(2018年3期)2018-06-06 05:24:36
意林(2018年3期)2018-03-02 15:17:24
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
电子设计工程(2014年18期)2014-02-27 12:00:19
