
基于Lenet-5的空间结构光编码符号识别研究
2017-06-12 12:01宋丽芳罗兵
五邑大学学报(自然科学版) 2017年2期
宋丽芳,罗兵
(五邑大学 信息工程学院,广东 江门 529020)
基于Lenet-5的空间结构光编码符号识别研究
宋丽芳,罗兵
(五邑大学 信息工程学院,广东 江门 529020)
针对传统解码方法在空间结构光编码的三维重建时易受投影对象表面颜色、纹理、曲率的影响而出现解码错误,本文提出一种在解码阶段利用微调后的卷积网络Lenet-5对编码符号分类识别的解码算法,实验结果表明基于卷积网络的解码方法其识别率可达96.67%,样本的识别速度可达0.552 ms/个,对于表面具有颜色、扭曲等物体具有较好的实验效果.本文所提出的解码方法对提升动态三维测量的精度具有重要意义.
Lenet-5;解码;识别;三维重建
基于空间结构光编码的三维重建技术仅需要投影一幅图像就可以获得视场中的全部数据,具有实时性,尤其适合动态场景的三维重建[1].凭借突出的优点和性能,基于空间结构光编码的三维重建技术已经在医学、考古、娱乐、工业检测等方面得到广泛应用.
基于空间结构光编码的编码方法可分为非正式编码、De Bruijn序列图案编码和M-arrays图案编码[2],依据编码符号又可以分为彩色编码[3]和二值编码[4-5],而彩色编码极易受到物体表面颜色的干扰,相比较而言二值编码受物体表面颜色的干扰相对较小.基于空间结构光的二值编码采用等符号编码空间结构光.由于编码符号的特征提取和分类识别是解码阶段的重要组成部分,这两步效果的优劣直接影响到最后的重建效果.目前,用于编码符号识别的方法有基于符号特征的方法[4-5]、基于符号密度谱方法[7]、基于特征点角度变化的方法[8],而这些方法需要显性的提取编码符号的特征,凭借符号本身的特征进行分类识别,对于表面较复杂、扭曲程度较大的物体,鲁棒性不强.事实上,目标对象的表面颜色、纹理、曲率、材质等都会对投影模板图像实现不同的调制效果,使得投影到目标对象表面的编码符号出现灰度深浅不一、不连续、畸变、遮挡等现象,给解码造成很大的难度.
为了增强基于空间结构光三维重建解码阶段的鲁棒性.本文提出一种新的解码方法,在解码阶段利用微调后的卷积网络Lenet-5对编码符号分类识别.首先,为了训练得到一个鲁棒性强的网络,本文建立了一个含有91 840个样本的样本库来训练卷积网络;其次,在卷积网络Lenet-5网络的基础上进行微调,将网络的输出单元个数由10调整为8,并且研究了C5层特征图数目对识别性能的影响;最后,利用实物的三维重建效果来检验此方法的性能.
1 建立大样本数据库
1.1 编码
目标对象表面的颜色往往会对重建效果产生一定的影响,为了尽可能的降低这种影响,本文采用二值几何图形对空间结构光进行编码.编码方式采用文献[9]中的方法生成一个大小为、窗口尺寸为的伪随机阵列,用图1中的八类几何图形替代伪随机阵列中的码字,将这八类几何元素镶嵌在黑色背景的栅格中,从而获得一个二值投影模板.两条白色栅格线的交叉点定义为特征点,特征点由其周围的四个几何图形唯一编码标识.编码符号和局部投影模板如图1所示.

图1 左图为投影模板中采用的几何元素,右图为投影模板的局部部分
1.2 采集样本
将投影模板投射到目标对象,保存被目标对象表面调制的模板图案,将保存的图像转换成灰度图像,通过公式(1)检测出候选特征点.
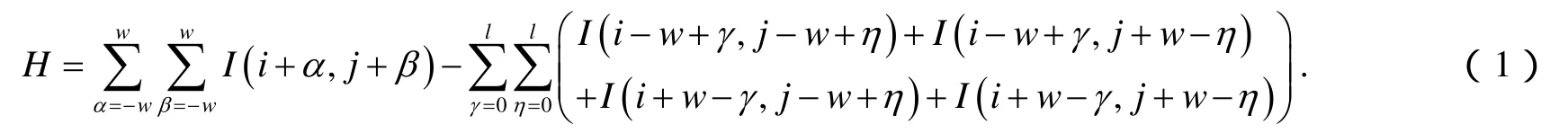
其中I表示图像灰度,w表示一个十字模板的半径,l被设置为w/3,H表示沿i、j方向图像灰度的累加值.给定H合适的值选出候选特征点,利用旋转对称性[10],可以排除大部分错误的候选特征点.
通过特征点的检测,可以获得所有栅格点的拓扑结构,由拓扑结构可以提取到模板的几何元素.借助栅格的四个特征点,利用如下公式和双线性插值法可以将模板元素规范化成大小均为的样本图像,并将样本保存为jpg格式.

目标对象表面的颜色、纹理、反射、曲率、材质等对投影模板产生不同的调制效果,为了增强解码阶段分类识别的鲁棒性,建立的样本数据库需要尽可能的丰富.样本采集过程中选用的目标对象(如黄色的塑料球、人脸、白纸、广告彩页等)颜色、纹理由简单到复杂,表面扭曲程度、反射率各不相同.采集过程主要分为建立基础样本数据库和扩展样本数据库.具体步骤如下:
1)将每一个只含有单一元素的投影模板分别投影到目标物体上,这样做的目的是一次性可以获得大量样本,方便简单快捷;
2)扩展样本数据库到91 840.在原有样本基础上进行扩展:①在样本中添加高斯噪声;②在样本中添加随机黑白线以获得具有遮挡的样本;③对样本执行仿射变换以获得具有局部误差的样本;④对样本进行不同程度的高斯滤波以获得不同模糊程度的样本.

图2 采集设备及样本图像
2 Lenet-5及改进
Lenet-5卷积网络是由Yann LeCun[11]提出的一种卷积网络,主要应用于手写数字的识别.输入图像为归一化到大小为322的图像,除去输入层,Lenet-5网络由7层组成:卷积层C1、C3、C5和下采样层S2、S4,以及全连层F6和输出层.其中C表示卷积层,S代表下采样层,F表示全连层.
每层由多个特征图组成,每个特征图通过一种卷积滤波器提取前一层的特征得到,每个特征图有多个神经元,每一层都有可训练的参数,即连接权重.卷积层通过一个的卷积滤波器与前一层图像做卷积,通过卷积运算可以使原信号特征增强,并且降低噪音.C1层有6个特征图;C3有16个特征图,C5有120个特征图.下采样层可以利用局部相关性的原理对图像进行子抽样,以减少数据处理并保留有用信息,S2有6个14´ 14的特征图,S4有16个特征图.全连层有84神经元,输出层为8,代表识别8个类别.卷积层C的每4个神经元加权后相加,然后再加上一个可训练的偏置,最后通过一个sigmoid激活函数(S形生长曲线函数),最终产生一个缩小四倍的特征映射图,即下采样层.将得到的下采样层与的卷积滤波器做卷积就得到了卷积层.这样就出现了如图3所示的卷积层和下采样层交互相连的情形.全连层的每个特征图只有一个神经元,与C5层全相连.输出层由欧式径向基函数神经元组成,每个类分别对应一个神经元,输出有10个类.局部感受野和权值共享特性减少了卷积网络的训练参数,这在一定程度上降低了对机器内存的要求.此外,卷积网络的特征提取和模式分类同时进行,并不需要显示的提取特征.
本文所采用的编码符号有8类,因此将Lenet-5的输出层由10调整为8.此外对C5层特征图数目进行调整,研究其特征图数目对识别分类的影响.调整后的卷积网络如图3所示.

图3 更改后的Lenet-5卷积网络模型
3 实验及对比分析
3.1 改变C5层特征图数目对识别率的影响
改变C5层特征图的数目,测试对测试样本的识别率和识别时间,其中训练样本数为78 720,测试样本数是13120,二者无重复,均来自前面建立的样本库.实验结果如表1所示.
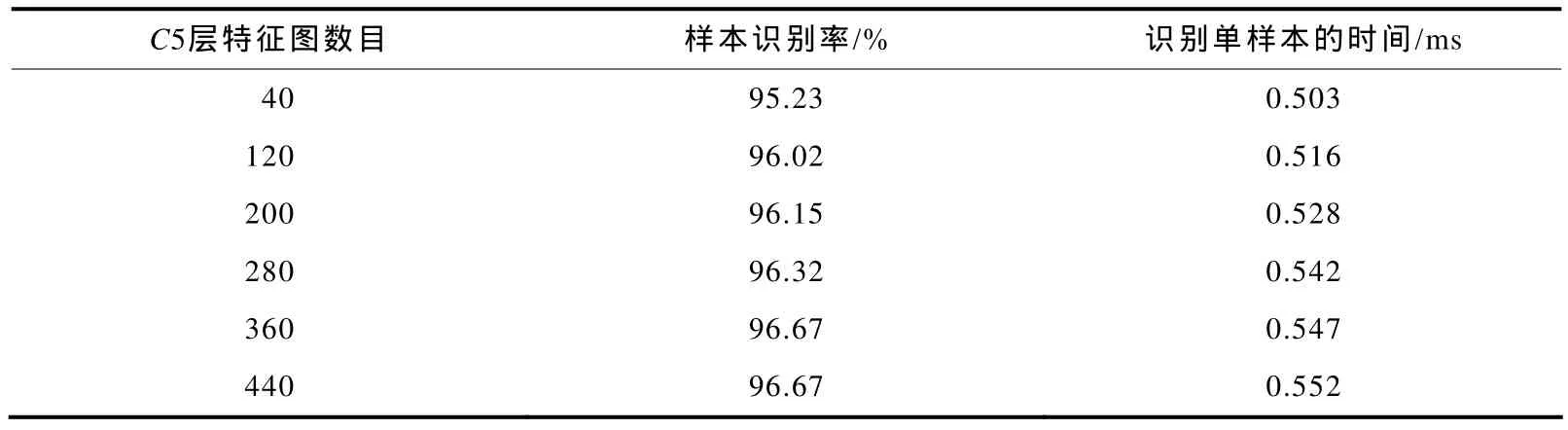
表1 C5层特征图数目不同的Lenet-5的性能
由表1可见,随着C5层特征图数目的不断增加,测试样本的识别率不断增大并且增大到一定程度后将不再改变,同时识别时间也不断增大.这是因为,C5层特征图数目越多,网络越复杂,而网络的分类能力越强,但是识别速度会受到影响.
3.2 与BP神经网络的对比
将调整后的Lenet-5网络与三层BP神经网络对比,BP神经网络隐含层采用360个节点,学习率为0.01.将样本库按照: 6:1的比例分成训练集合测试集,训练集有78 720个样本,测试集有13120个样本.由表2可以看出Lenet-5的识别率高于BP神经网络的识别率.对于一些较为复杂的测试样本,尤其是编码符号扭曲、被遮挡、背景复杂的,BP神经网络难以正确识别.

表2 Lenet-5与BP网络识别性能比较
3.3 三维重建效果
为了验证训练好的卷积网络的分类识别性能在基于空间结构光编码的三维重建中的效果,选用彩色纸张和陶瓷水杯分别进行重建实验.彩色纸张和陶瓷水杯的原图以及重建三维图如图4所示.图4-a、c分别为目标对象彩色纸张和陶瓷水杯的原图,图4-b、d分别为将投影模板投射到目标对象表面后采集到的图像,图4-e、f分别为三维重建的空间效果图.彩色纸张具有较为复杂的颜色变化以及轻微的扭曲变形,由于花朵及叶子处纹理及颜色都发生了变化,这就导致投影到这些地方的编码符号会出现灰度不一、不连续等情况,对于这些情况神经网络会将编码图案识别错误,从而导致重建过程中会出现空洞.陶瓷水杯是颜色单一的物体但是本身具有较大的弯曲度,投影到陶瓷水杯表面的编码符号会出现较大的扭曲形变,当编码符号形变较大的时候同样会给识别带来困难.而在解码阶段用本文方法训练得到的卷积网络对编码符号进行识别可以很好的克服这些问题,由图4可以看到,在彩色纸张的花朵及叶子处都能很好的实现重建效果,同时纸张在空间中的轻微变形也在重建的效果图中充分表现了出来;陶瓷水杯的的下面有部分凸起,这部分和水杯边缘的曲率变化较大,进行重建的过程中这两部分同样得到很好的重建.
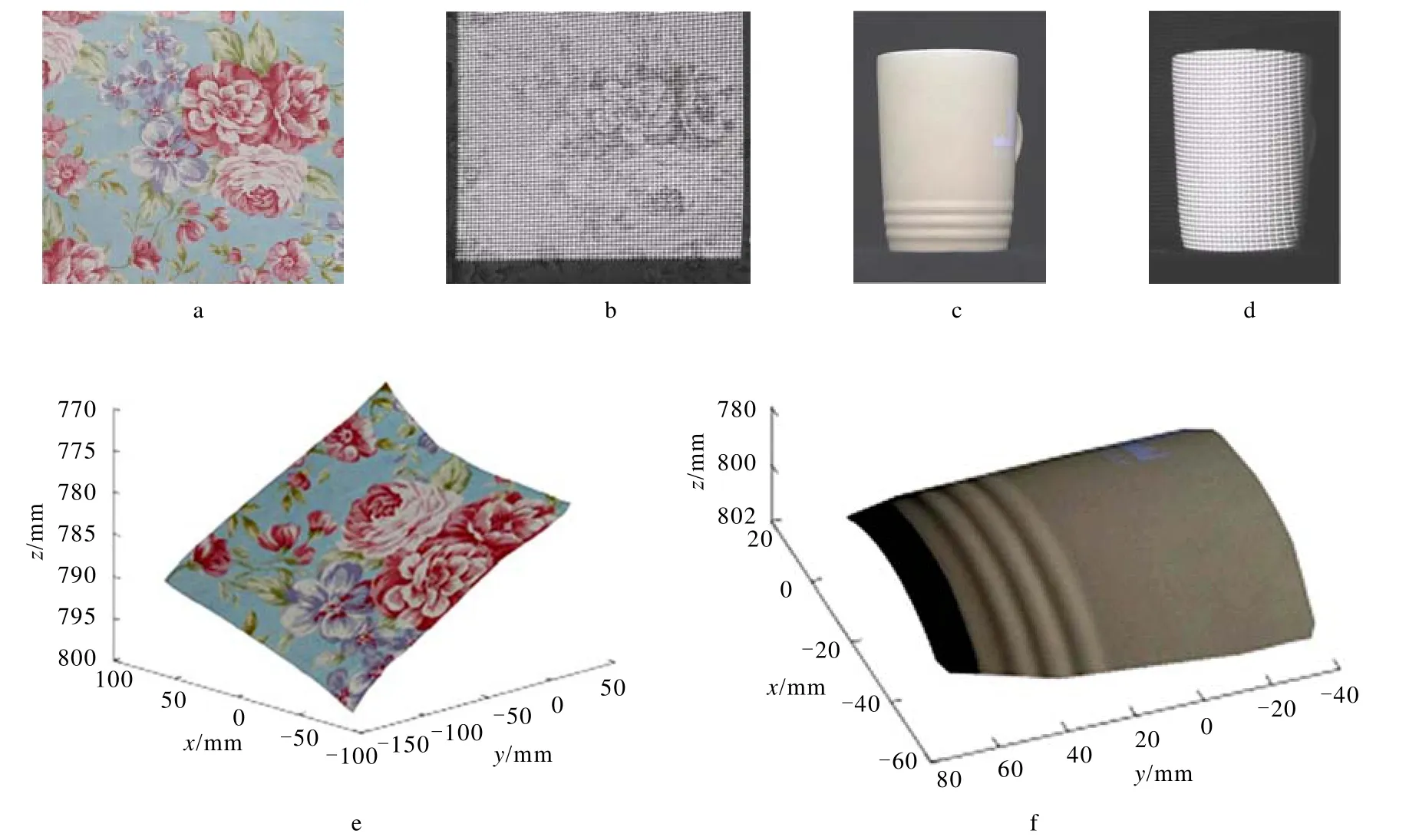
图4 目标对象与三维重建
由此可见,在解码阶段采用训练好的卷积网络对编码符号进行分类识别,可以很好的实现目标对象的三维重建效果.
4 总结与展望
本文主要对基于结构光的三维重建技术中的编码符号识别进行了研究,建立了数据样本库,利用调整过的卷积网络Lenet-5样本库进行训练,在解码阶段用训练好的卷积网络进行识别,不需要显性提取符号特征,鲁棒性高,适用于表面复杂的目标对象.在今后的工作中,需要进一步丰富样本数据库、提高识别速率,增强实时性.
参考文献
[1] 陈彦君,左旺孟,王宽全,等.结构光编码方法综述[J].小型微型计算机系统,2010, 31(9): 1856-1863.
[2] 方玫.结构光空间编码技术的进展[J].嘉兴学院学报,2011, 23(6): 25-32.
[3] SONG Zhan, CHUNG R.Determining both surface position and orientation profiles in structured-light sensing [J].IEEE transactions on pattern analysis and machine intelligence, 2010, 32(10): 1770-1780.
[4] ALBITAR C, GAREBLING P, DOIGNON C.Design of a monochromatic pattern for a robust structured light coding [C]//IEEE International Conferenceon Image Processing (ICIP), IEEE, 2007:V1529-V1532.
[5] LEI Yang, BENGTSON K, LI L, et al.Design and decoding of an M-array pattern for low-cost structured light 3D reconstruction systems [C]//IEEE International Conference on Image Processing.IEEE, 2013: 2168-2172.
[6] MAURICE X, GRAEBLING P, DOIGNON C.Epipolar based structured light pattern design for 3-d reconstruction of moving surfaces [C]//IEEE International Conference on Robotics and Automation, May 9-13, 2011, ICRA, Shanghai: DBLP, c2011: 5301-5308.
[7] FANG Mei, SHEN Wei, ZENG Dan, et al.One-shot monochromatic symbol pattern for 3D reconstruction using perfect submap coding [J].Optik-International Journal for Light and Electron Optics, 2015, 126(23): 3771-3780.
[8] JIA Xiaojun, YUE Guangxue, MEI Fang.The mathematical model and applications of coded structured light system for object detecting [J].Journal of Computers, 2009, 4(1): 53-60.
[9] LIN Haibo, NIE Lei, SONG Zhan.A single-shot structured light means by encoding both color and geometrical features [J].Pattern Recognition, 2015, 54: 178-189.
[10] LIN Haibo, SONG Zhan.A twofold symmetry based approach for the feature detection of pseudorandom color pattern [C]//4th IEEE Conference on Information Science and Technology (ICIST).IEEE, 2014: 623-626.
[11] LECUN Y, BOTTOU L, BENGIO Y, et al.Gradient-based learning applied to document recognition [J].Proceedings of the IEEE, 1998, 86(11):2278-2324.
[责任编辑:韦 韬]
Research on Identification of Encoded Symbols of Spatial Structure Light Coding Based on Lenet-5
SONG Li-fang, LUO Bing
(School of Information Engineering, Wuyi University, Jiangmen 529020, China)
In light of decoding errors caused by the surface color, texture, and curvature of the target object when the traditional decoding method is used in the 3D reconstruction of spatial structure light encoding, this paper proposes a decoding algorithm for classifying and identifying coded symbols using the convolutional network Lenet-5 after fine-tuning in the decoding stage.Experimental results show that the recognition rate of the convolutional network-based encoding method is 96.67%, and the recognition rate is up to 0.552 ms/sample, with good experimental results for objects with surface color and distortion.The decoding method proposed in this paper is of great significance to improving the dynamic 3D measurement accuracy.
lenet-5; decoding; identification; 3D reconstruction
TP18
A
1006-7302(2017)02-0040-06
2016-12-05
广东省教育厅科技创新资助项目(2013KJCX0185)
宋丽芳(1989—),女,河南濮阳人,在读硕士生,主要从事机器视觉技术研究;罗兵,教授,博士,硕士生导师,通信作者,主要从事机器视觉及人工智能研究.
猜你喜欢
中国石油石化(2022年12期)2022-07-16
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
软件(2020年3期)2020-04-20
中国外汇(2019年19期)2019-11-26
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
腹腔镜外科杂志(2016年12期)2016-06-01
