
基于Hadoop的云平台参数优化
2017-06-07 08:04:53张岩,王研
沈阳师范大学学报(自然科学版) 2017年2期
张 岩, 王 研
(1. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034; 2. 沈阳师范大学 教育技术学院, 沈阳 110034; 3. 中国医科大学 生物医学工程系, 沈阳 110013)
基于Hadoop的云平台参数优化
张 岩1, 王 研2,3
(1. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034; 2. 沈阳师范大学 教育技术学院, 沈阳 110034; 3. 中国医科大学 生物医学工程系, 沈阳 110013)
作为中间件的软件框架,Hadoop可以对大量数据进行分布式处理。基于Hadoop的云平台参数的优化可以提高系统的处理性能。使用VMware虚拟机技术在单机上配置多个虚拟计算机节点,实现满足实验环境的Hadoop完全分布式平台,并且进行集群测试。对Hadoop平台的相关参数进行优化配置,利用TeraSort程序对参数优化前后进行了对比测试,分析了测试结果。实验表明,参数优化对Hadoop平台性能具有较大的影响。在实际工程的全局部署之前,可利用或借鉴本方法,以应用环境为基础,充分考虑硬件配置情况、集群数量和数据大小等因素,进行样本的调优实验,获得最优的云平台组合参数。
Hadoop; MapReduce; 参数优化; 虚拟机
0 引 言
参数优化是对Hadoop平台进行性能优化的重要策略之一。Hadoop在各个配置文件中的参数都有其默认值,默认值是hadoop根据一般情况给出的一个参考值,并不是具体问题的最优解,要根据实际情况(软硬件配置,网络条件,集群数量,处理的job大小等)来调整最优值,而每一个实际的具体问题所面临的情况是不同的,因此只能由Hadoop的运维人员进行手工参数调整,使Hadoop平台达到一个最佳的效能。参数优化面临的问题:1)Hadoop总共有190多个可以配置的参数,每一个参数都有可能对集群的性能产生一定的影响,完全优化就要考虑到所有的参数;2)参数和参数之间是有相关性的,当相关的参数都达到最优解的时候,它们组合到一起对于集群的优化不一定是最优的,要对相关参数进行排列组合进行优化;3)一个集群的参数优化达到最佳,将参数全部移植到另一个集群,不一定会得到最佳的效果,即使在同一个集群上,执行不同的任务其参数的最佳解也是不同的。所以参数优化意味着巨大的工作量,实现完全优化具有相当大的难度。
1 参数优化的实验环境
1.1 参数调优涉及的主要文件
Hadoop参数调优主要涉及core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml四个文件。core-site.xml为Hadoop的核心属性文件,参数影响决定着Hadoop的核心功能,文件独立于HDFS与MapReduce。hadoop-env.sh为Hadoop的参数文件。主要是完成各个进程的内存划分以及部分环境设置。hdfs-site.xml为Hadoop的参数文件。主要是完成HDFS的端口、目录以及HDFS和namenode之间的通信设置。mapred-site.xml为Hadoop的参数文件。主要完成map、reduce和JobTracker的设置[1]。
1.2 参数调优涉及的主要参数
Hadoop框架可以设置的参数很多,如果不针对特定场景的应用,可以考虑以下参数的优化,来满足一般应用情景的性能调优。具体包括:
HDFS,dfs.block.siz,Mapredur,io.file.buffer.siz,io.sort.m,io.sort.spill.percent,mapred.local.dir,mapred.map.tasks & mapred.tasktracker.map.tasks.maximum,mapred.reduce.tasks & mapred.tasktracker.reduce.tasks.maximum,mapred.reduce.max.attempts,mapred.reduce.parallel.copies,mapreduce.reduce.shuffle.maxfetchfailures,mapred.child.java.opts,mapred.reduce.tasks.speculative.execution,mapred.compress.map.output & mapred.map.output.compression.codec,mapred.reduce.slowstart.completed.maps[2]。
本实验选取io.file.buffer.size,dfs.block.size,mapred.map.task,mapred.reduce.tasks,mapred.tasktracker.map.tasks.maximum进行实验[3]。在相对应的实验部分将对选取原因进行说明。
1.3 实验软硬件配置
实验机使用2台电脑,一台作为系统宿主机,一台作为远程控制终端机。宿主机配置为CPU core i3,4核,8 G内存,终端机配置CPU Pentium4,2核,4 G内存。Hadoop平台宿主机安装windows7,VMware10.0.2虚拟机,ubuntu12.04 server,Hadoop1.2.1,java-JDK JDK-7u45-linux-i586 。远程控制终端安装windows7,Xmanager.Enterprise.5.0.0517[4]。
所有优化测试均用TeraSort程序测试2 GB数据完成。具体硬软件见表1[5]。

表1 实验平台软硬件配置
2 参数优化的方法和过程
2.1 io.file.buffer.size参数优化
在core-site.xml中,io.file.buffer.size参数表示流文件缓冲区大小,缓冲区用于临时存储hadoop读取的hdfs文件和写入到hdfs的文件,以及map的输出。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4 KB。通过增大缓冲区的大小能够减少I/O次数,进而提高系统性能。虽然较大的缓存可以提供更高的数据传输速度,但这也就意味着更大的内存消耗和延迟[6]。在进行具体参数优化时,采用以下方法:
1) 添加如下xml代码:
2) 分别将参数值设置为4~256 KB,优化测试结果如表2所示。

表2 io.file.buffer.size优化测试结果
从表2中的测试结果来看,io.file.buffer.size参数对集群的性能影响较大,取8 K的时候所用的测试时间最短。限于实验用集群较小,资源有限,所以当该参数配置增大时,造成了内存消耗过大而使集群的性能降低,导致测试时间增长。总体观察整个表可见,CPU耗时折线趋于稳定,说明io.file.buffer.size参数对于CPU的耗时影响不大,对集群的整体负载、网络间通讯耗时有一定的影响。
2.2 dfs.block.size参数优化
dfs.block.size是hdfs-site.xml中的一个重要参数,该参数指定一个数据块的上限,默认大小为64 M。fs.block.size参数对于MapReduce的执行效果有直接的影响,在分布式文件系统的性能调优中非常关键,具有实际的性能调优意义。从Hadoop的框架运行原理来看,map是并行式处理任务的,如果block的大小不一样,那么较小的先执行完毕后,要等待较大的执行完才能继续进行后续的任务,导致更多的时间消耗。所以,怎样配置该参数使block数据块的大小一致,从而使所有的map任务同时完成成为该参数调优的关键[7]。
参数调优的具体方法是,根据被处理数据块大小选择一个能将其整除的数作为分片block的大小,以保证数据快大小一致,map并行同时完成。考虑TeraSort程序测试2 GB的数据可以分割成2个大小为1 G的文件。若选择fs.block.size为96 M上限,每个文件将会分割为10个96 M的数据块和一个64 M的数据块,2个文件即为20个96 M数据块和2个64 M数据块。Hadoop框架的运行机制是根据数据块数产生执行函数map的个数,则将产生22个map,其中执行2个64 M数据块的map先执行完毕,然后进入等待其余20个执行96 M数据块的map完成,增多了map资源,延长了处理时间。若选择fs.block.size为128 M,则将产生16个map函数,各个函数可以同时完成,不会造成资源和时间的浪费。
1) 在hdfs-site.xml中添加如下配置内容:
2)分别将block大小设置为32 M、64 M、96 M、128 M、256 M,对Hadoop的性能进行调优测,测试结果如表3所示。

表3 dfs.block.size优化测试结果表
从表3中的测试结果来看,对于2 G的被处理数据,当dfs.block.size选择为64 M和128 M时,可以分割相同大小的数据块,所以性能较好,效率也比较接近;当dfs.block.size选择为96 M时,处理时间变长;当dfs.block.size选择为32 M时,由于产生的map数过多,形成了大量合并计算,浪费了内存以及CPU资源,增加了网络传输的消耗,导致运行不成功;当dfs.block.size选择为256 M时,由于产生的并发map数过小,执行效率比较低,性能较差。
2.3 mapred.map.task参数优化
参数mapred.map.task包含在mapred-site.xml文件中。该参数是用来配置集群中map task数量的。它和mapred.reduce.task两个参数对于提升集群的运转速度有重要的作用。mapred.map.task的默认值是输入文件的总体大小与HDFS文件块大小的比值[8]。如果增加task的数量,则有利于负载平衡,减少任务失败的代价,同时也会增大系统的开销。
Hadoop默认情况下mapred.map.tasks参数为total_size/block_size,通常默认值为理论上map task数的最小值,所以设置值必须大于默认值[9]。
对于本实验2 G的数据,前面的实验已经证实块大小为64 M和128 M,系统性能效果较好,太大或太小都影响效率。因此map task应设置为2 048 M/128 M=16块或者2 048 M/64 M=32块。即map数在16到32之间预期效果较好。所以实验采用16、20、24、28、32五个map数进行测试。
1) 在mapred-site.xml中添加如下配置内容:
2) 分别将tasks设置为16、20、24、28、32,对Hadoop的性能进行调优测,测试结果如表4和图1所示。

表4 mapred.map.tasks优化测试结果表
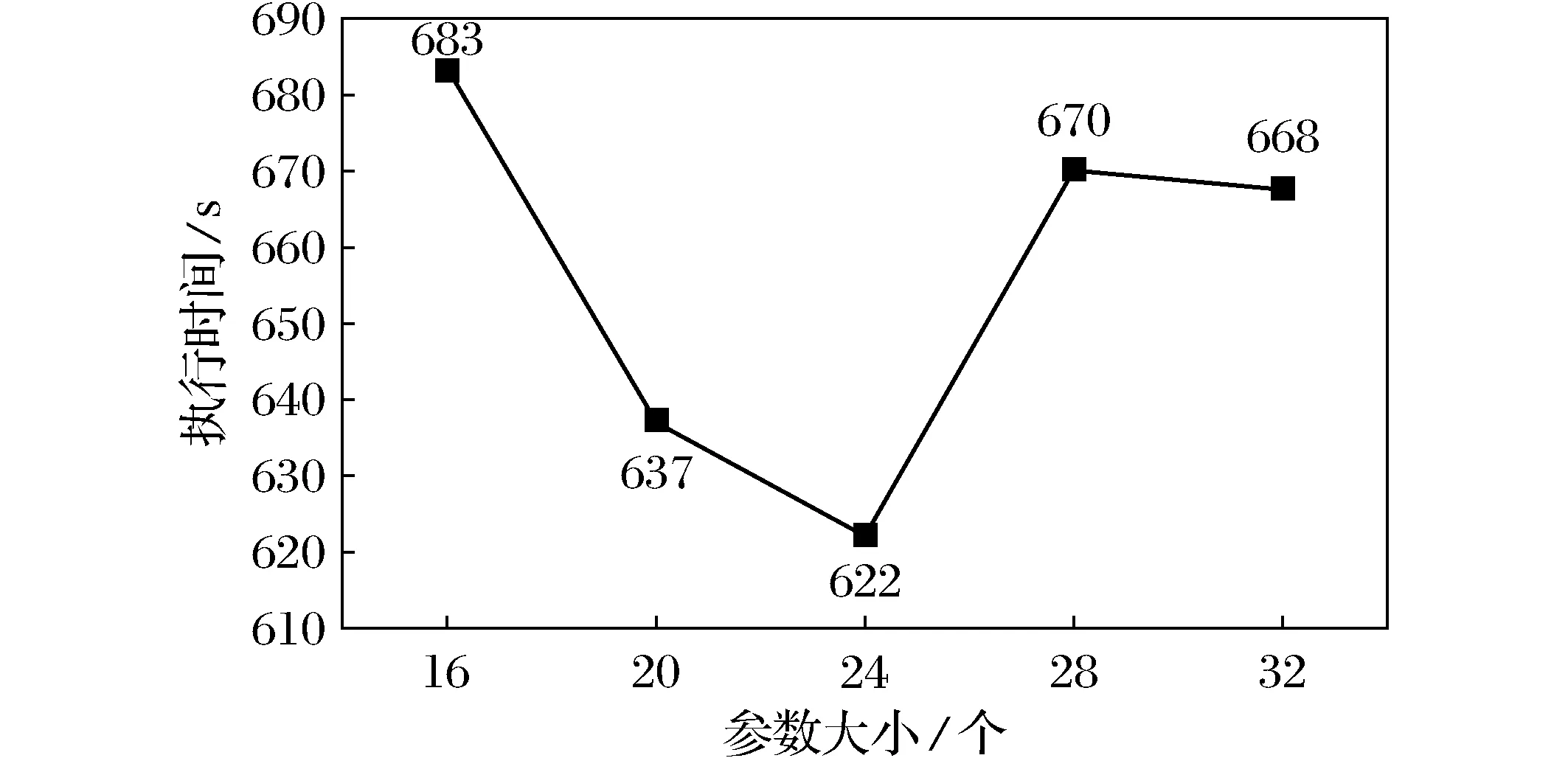
图1 2 GB文件TeraSort测试mapred.map.tasks优化Fig.1 2 GB TeraSort test mapred.map.tasks optimization
从测试结果图1来看,Map Task 数量对系统性能有很大影响。当mapred.map.tasks为24时,速度相对最快,而在最大32和最小16时,速度相对较慢,实验证实了之前的预期结果。
2.4 mapred.reduce.tasks参数优化
mapred.reduce.task参数是mapred-site.xml中用来配置集群中运行的reduce task数量的,Hadoop为它配置的默认值为1,适当的提高该参数的数值有利于提升集群的效率[10]。考虑到本实验环境中的集群资源有限,根据上一个参数优化的结果,即mapred.map.task为24时,适当增大mapred.reduce.task参数的大小,分别取reduce task数量为1、2、3、4、5、6进行测试。
1) 在mapred-site.xml中添加如下配置内容:
2) 分别将tasks设置为1、2、3、4、5,对Hadoop的执行时间性能进行调优测试,测试结果如图2所示。
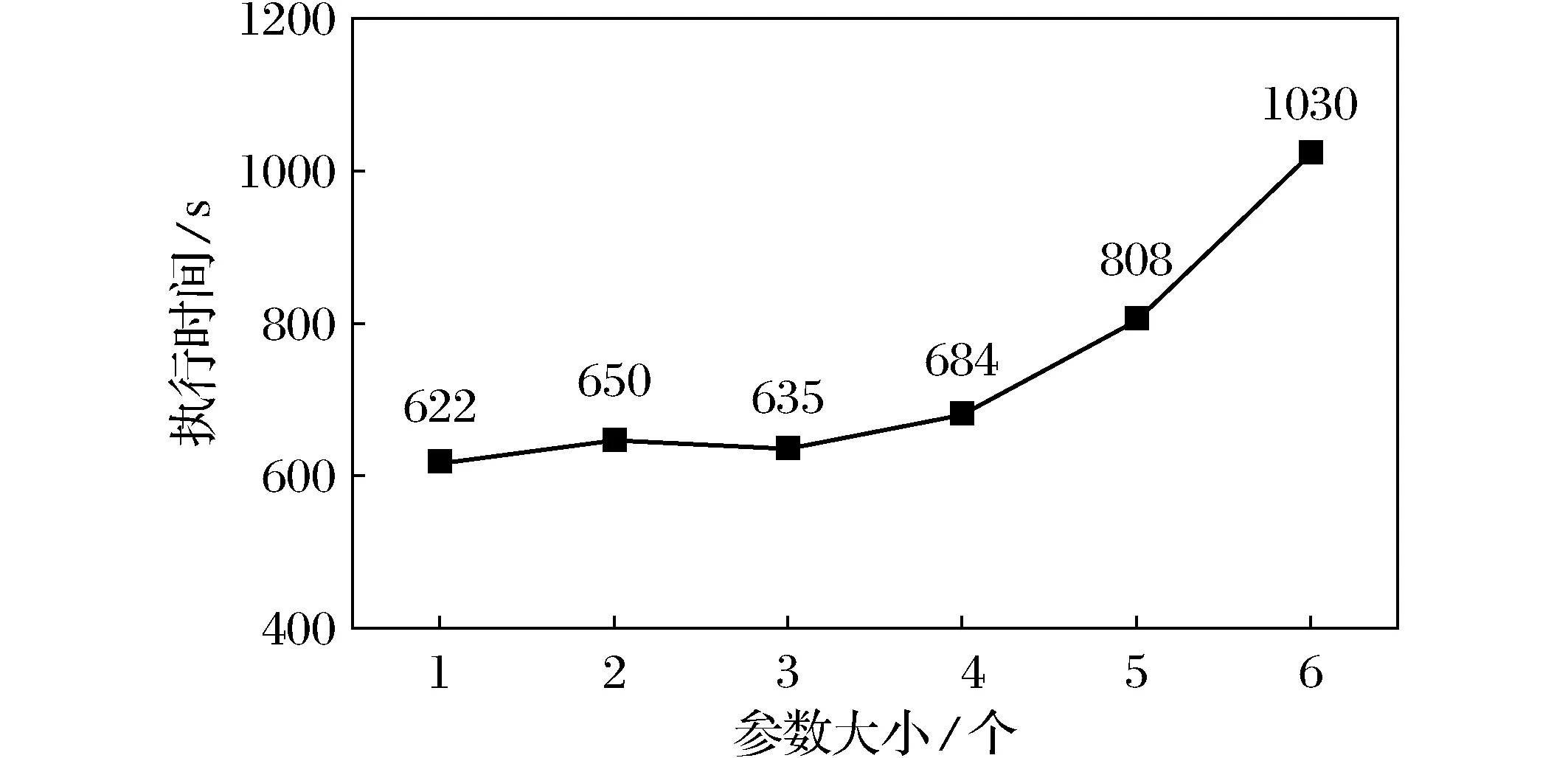
图2 2 GB文件TeraSort测试mapred.reduce.tasks优化Fig.2 2 GB TeraSort test mapred. reduce. tasks optimization
从测试结果图2来看,可以得出如下分析结论:
1) 由于map与reduce进程之间在运行时执行时间有重合,因此map时间与reduce时间之和大于总时间。
2) 当 reduce task 的值小于节点数3时,总时间与map时间变化并不大,当超过3以后,时间随reduce task的值增大而显著增大。
3) 当reduce task的值在3以内时,reduce执行时间随reduce task的值增大而减少,这是由于增加了reduce的并行度,当reduce task的值超过节点数3时,reduce执行时间就会显著增加。
4) reduce task 的数量应该设置为接近 slave 节点数量,或者适当大于节点数,不宜设置为比节点数量大太多。
2.5 mapred.tasktracker.map.tasks.maximum参数优化
mapred.tasktracker.map.tasks.maximum参数是mapred-site.xml文件中用来配置一个Tasktracker最多可以同时运行的map任务数量的,其默认值为2,也就是一个节点最多同时只能执行2个map,则3个datanode同时能够执行6个map,本实验运行时集群情况如图3所示。

图3 2 GB文件TeraSort测试mapred.tasktracker.map.tasks.maximum优化(a)
mapred.tasktracker.map.tasks.maximum参数应该根据CPU的性能来调整,具体策略是mapred.tasktracker.map.tasks.maximum设置为节点的CPU的cores数目或者cores数目减1比较合适,此时的运行效率最高[11]。根据本实验实际情况测试,每个虚拟节点的虚拟CPU内核数为2时,系统运行效率相对较好。按照mapred.tasktracker.map.tasks.maximum设置为CPU核数或者CPU核数减1时的运行效率最高策略,可以将mapred.tasktracker.map.tasks.maximum设置为2。根据图3数据所示,Nodes的值为3,即图3中的Map Task Capacity的值为6时,可以获得较好的运行性能。
在mapred-site.xml中添加如下配置内容:
当然mapred.tasktracker.map.tasks.maximum参数值并不是越大越好,参数过大系统运行效率并不能提高[12]。下面是mapred.tasktracker.map.tasks.maximum参数值设置值过大,系统运行的测试状况。本实验设置一个节点可以同时执行最多12个map,3个节点一共可以同时执行36个map。由于mapred.map.tasks设为16,因此现在同时执行的map是最大值16个。实验运行时集群情况如图4所示。
从测试结果图3和图4来看,map过程的时间大到已经失去实际意义,因此将参数设置为2较为合适。观察图4中的运行状态数据,Running Map Tasks的值是16,Avg.Tasks/Node的值是14,数据明显反映出,集群的节点负荷不合理,系统的运行性能下降。分析造成运行时间增长的原因,图4中Map Task Capacity的值是36,Occupied Map Slots的值是16,即mapred.tasktracker.map.tasks.maximum设置为12,mapred.map.task设置为16的具体表现,可以计算出,在集群实际运行时,Map Task Capacity的占用率仅为16/36≈44.4%。所以,不合适的参数配置降低了资源的利用率,对系统的运行性能产生了负影响。
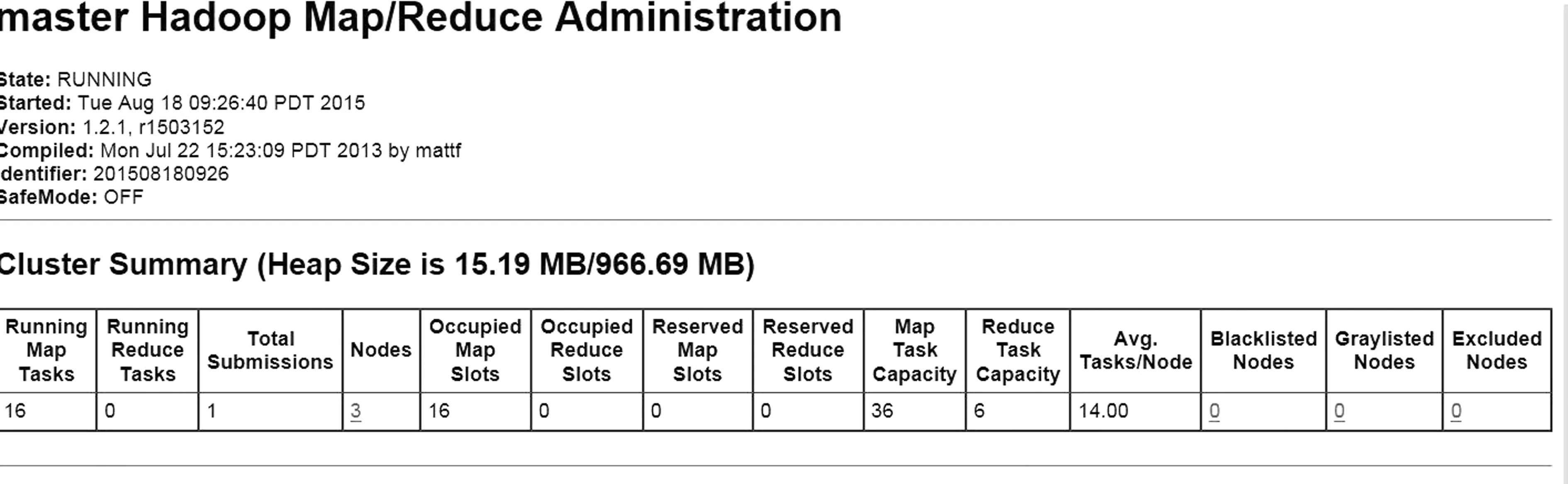
图4 2 GB文件TeraSort测试mapred.tasktracker.map.tasks.maximum优化(b)
3 结 论
本实验目的是通过对广泛使用的Hadoop云平台进行参数调优,测试参数对平台效率的影响程度,并且找到参数优化的方法。本实验所有测试均使用2 GB文件的TeraSort程序测试,对io.file.buffer.size,dfs.block.size,mapred.map.task,mapred.reduce.tasks,mapred.tasktracker.map.tasks.maximum等主要参数进行优化。实验表明,将涉及到的所有参数全部调优,测试2 GB文件的排序,运行时间结果602秒,对比参数全部采用默认值进行实验,运行时间结果639 s,优化后的运行效率提高了6%。调优的方法是对参数默认值进行测试,要慎重采用;充分考虑硬件配置情况,特别是CPU core的数量;将集群数量和数据大小等进行综合考虑;对有相关性的参数协调优化,寻找参数的最佳组合方案。
[ 1 ]WHITE T. Hadoop权威指南[M]. 3版. 北京:清华大学出版社, 2014.
[ 2 ]MURTHY A C,VAVILAPALLI V K,EADLINE D,et al. Hadoop YARN权威指南[M]. 北京:机械工业出版社, 2015.
[ 3 ]HOLMES A. Hadoop硬实战[M]. 北京:电子工业出版社, 2015.
[ 4 ]张岩,郭松,赵国海. 基于Hadoop的云计算试验平台搭建研究[J]. 沈阳师范大学学报(自然科学版), 2013,31(1):85-89.
[ 5 ]王研,张岩. 基于Hadoop的云平台的实现与基准测试[J]. 沈阳师范大学学报(自然科学版), 2016,34(2):240-245.
[ 6 ]TANNIRHAS K. Hadoop MapReduce性能优化[M]. 北京:人民邮电出版社, 2015.
[ 7 ]GUNARATHNE T. Hapdoop MapReduce v2 Cookbook[M]. 2nd ed. 南京:东南大学出版社, 2016.
[ 8 ]翟周伟. Hadoop核心技术[M]. 北京:机械工业出版社, 2015.
[ 9 ]董新华,李瑞轩,周湾湾,等. Hadoop系统性能优化与功能增强综述[J]. 计算机研究与发展, 2013,50(Suppl.):1-15.
[10]李怿铭. 基于MapReduce性能优化的研究[D]. 上海:上海师范大学, 2015.
[11]康佳. Hadoop平台下的作业调度算法及应用[D].合肥:安徽理工大学, 2015.
[12]李张永. 基于Hadoop的MapReduce计算模型优化与应用研究[D]. 武汉:武汉科技大学, 2015.
Parameter optimization of cloud platform based on Hadoop
ZHANG Yan1, WANG Yan2,3
(1. Computer and Basic Mathematics Education Department, Shenyang Normal University, Shenyang 110034, China; 2. School of Educational Technology, Shenyang Normal University, Shenyang 110034, China; 3. Department of Biomedical Engineering, China Medical University, Shenyang 110013, China)
As a middleware software framework, the large amounts of data can be distributed processing by Hadoop. Based on the Hadoop cloud platform with parameters optimization techniqued, which ation can improve the processing performance of the system. The complete Hadoop distributed platform was configrated by using VMware virtual machine technology in the single node with can configurate multiple virtual machines,Implement the Hadoop distributed platform completely to meet experimental environment, and execute cluster tests. Optimization of the related parameters in the Hadoop platform configuration, and comparison test before and after the parameter optimization were tested by using TeraSort procedure, test results are analyzed. The experiments show that parameter optimization has greatly influence to the performance of Hadoop platform. Using this method can get full consideration about the hardware configuration, the cluster number and data size and other factors based on the application environment before the actual project of global deployment, and make the sample tuning experiments into obtaining the optimal combination parameters of cloud platform.
Hadoop; MapReduce; parameter optimization; Virtual machine
1673-5862(2017)02-0234-06
2016-10-13。
辽宁省科技厅自然科学基金资助项目(2015020055)。
张 岩(1968-),女,辽宁沈阳人,沈阳师范大学教授,硕士。
TP311
A
10.3969/ j.issn.1673-5862.2017.02.021
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
少先队活动(2021年4期)2021-07-23 01:46:22
装备制造技术(2020年2期)2020-12-14 03:09:16
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
沈阳医学院学报(2015年1期)2015-12-27 13:44:40
医学教育管理(2015年3期)2015-12-01 06:43:16
