
随机森林算法在生物信息学中的应用研究
2017-06-05 16:37冯洁
电脑知识与技术 2017年10期
冯洁

摘要:在生物信息学的研究过程当中,经常会遇到二分类的问题。例如RNA甲基化预测、蛋白质相互作用预测、蛋白质中二硫键的预测等都属于二分类问题。要解决二分类问题,目前在机器学习中提到了很多算法。比较常用的有支持向量机(sVM)和随机森林(RF)算法。文章在研究一般RF算法的同时,进一步讨论了集成RF算法对于处理非平衡数据起到的突出作用,最后分析总结了一般随机森林算法和集成随机森林算法的优缺点。
关键词:生物信息学;二分类;随机森林;集成随机森林;非平衡数据
中图分类号:TP311
文献标识码:A
文章编号:1009-3044(2017)10-0186-02
随着后基因组时代的到来,高通量测序技术的运用,使得基因数据库和蛋白质数据库中累加了巨量的新测定的序列,而通过传统的实验手段去剖析它们的结构、功能以及遗传信息就显得十分的耗时和费力。因此人们就寄希望于通过计算机的手段去分析这些序列的相关信息。在此基础上,人们开发了很多有针对性的计算机算法模型去预测相关信息,而建立这些模型的基础算法有KNN、SVM以及RF等等。在本文当中我们主要讨论RF算法在生物信息学当中的应用。
1.一般随机森林算法
由于数据集当中的样本数都比较大、噪音比较多,导致单一的分类器构建的预测模型的预测分类效果不好,因此为了提高预测分类结果,现在大多数情况下都采用分类器集成(En-semble)的方式来构建预测模型。随机森林就是一种集成的分类器。简单来说,随机森林就是由多棵CART(ClassificationAnd Regression Tree)构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回的抽取的。也就是说,在RF内部就有特征选择的过程,这样使得我们不必再额外的对众多特征进行优化处理,简化了建模过程。RF算法流程如下:
1)采用bootstrap抽样技术从原始数据集中抽取ntree个训练集,每个训练集的大小为原始训练集的三分之二。
2)为每个bootstrap训练集分别建立分类回归树(CART),共产生ntree棵决策树构成一片“森林”,这些决策树均不进行剪枝,在每棵树生长过程中并不是全部选择M个属性中最优属性作为内部节点进行分支,而是从随机选择的m≤M个属性中选择最优属性进行分支。
3)集合ntree棵决策树的预测结果,采用投票(voting)的方式决定新样本的类别。
对于平衡数据集(正负样本的数量相等)采用RF算法能够显著提高模型的预测准确率,但对于非平衡数据集(负样本的数量要远远大于正样本的数量),由于负样本的数量过多,导致学习过程中对于大类样本的偏向性比较明显,这样建立的模型预测的结果就不尽如人意。而在的物信息学当中我们接触到的数据集大多数是非平衡的,因此对于非平衡数据的预测就显得尤为重要,在文章的下面部分将讨论两种改进的随机森林算法。
2.随机森林集成算法
2.1多个RF串联
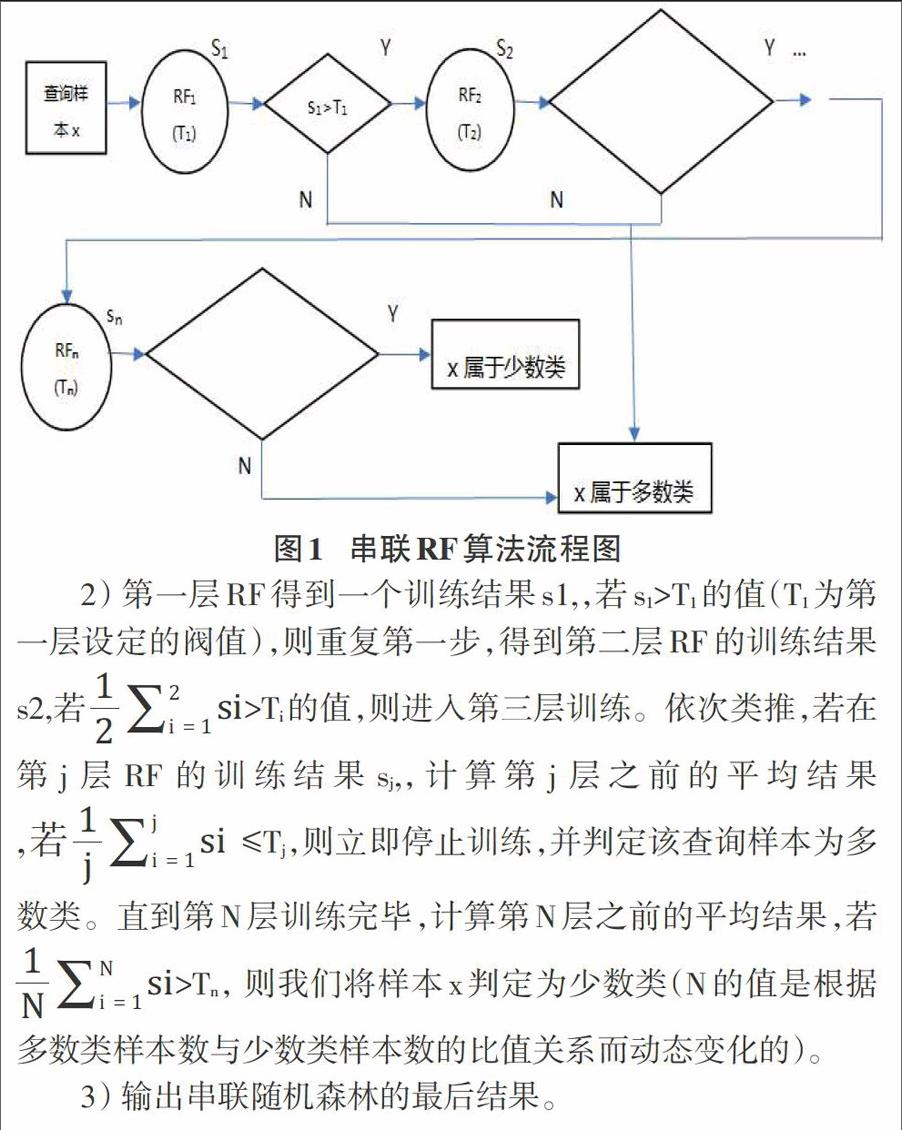
该方法的核心思想是通过多重RF串联的方式,来对一个样本数据进行多次预测,只有前面一层的RF预测值符合要求,才会进入到下一次的RF预测,当所有的RF预测结果一致通过,我们才认为是符合要求的,并将其归类为少数类。若在某一层的RF预测结果不符合要求,则立即停止,并將该样本归类为多数类。算法详细经过如图1所示。
根据以上分析,我们可以得知串联随机森林算法的核心思想就是通过一层层深入的训练模式能够极大的提高对少数类样本的预测精度,使得算法的准确率得到较大的提高。能很好地克服非平衡数据带来的模型偏向性问题。
算法流程:
1)判定多数类样本数与少数类样本数的比值是否大于等于设定的非平衡系数值(该系数值有程序设计者设定),若满足要求,则从多数类中随机抽取与少数类样本数相同的样本,与少数类组成一个平衡的样本子集,用于下一层的RF训练,并转第二步。注意被抽取的多数类样本将被从多数类样本集中剔除掉。
2.2多个RF并联
在生物信息学的学习过程当中,我们经常会对一条核酸序列或蛋白质序列提取相关的特征信息,若特征维数较多,彼此之间的组合可能会降低模型的预测准确率。因此,我们可以将每一维特征都作为一个特征向量,用一个单独的RF进行训练。这样,我们可以得到与特征维数相等的RF训练模型,再通过对这些RF模型的输出结果进行投票,得到最终的预测结果。该算法的流程图如图2所示。
算法步骤:
1)将待处理的序列用特征向量表示,并且将n维特征向量分解成若干个特征向量子集,每个子集可以是一维也可以是多维(n为奇数)。
2)对于每一个特征子集(一级),我们都训练一个RF模型。因此,若有n级就会训练n个RF模型,最后得到n个标签(类别)。
3)对n个标签进行投票统计,确定最终的类别标签。
这种RF集成模式称为并联模式。通过这种模式可以最大限度地发挥每一个特征子集对于模型构建起到的决定性作用,确保整个算法更加公平。避免了由于特征之间的互相影响而使得模型预测准确率不高的问题。
3.三种RF算法优缺点分析
11_一般RF
优点:对于平衡类数据能够起到较好的分类作用,由于其只有一层的原因,算法的耗时相对较短,模型的建立相对简单。
缺点:不适合对非平衡数据进行分类。
2)串联RF
优点:能很好地克服非平衡数据带来的偏向性问题。由于预测结果是层层递进的,所以提高了模型最后的预测效果。
缺点:由于其往往由多层RF串联构成,对于每一层的阀值的设定是一个难题。并且,多层结构提高了模型构建的复杂度,算法的运算耗时较长。
3)并联RF
优点:与串联RF相似,能很好地克服非平衡数据带来的偏向性问题。其将特征维数分解的方式能极大地提高各维特征对于最后类别认定起到的贡献程度。避免了多种特征混在一起互相冲突,降低了预测结果的问题。
缺点:要训练多个RF模型,程序复杂度较高。投票方式看似公平,实则有可能降低了某些强势特征对最后分类结果的贡献程度。
4.结束语
本文通过对三种RF算法在生物信息学当中的应用研究,在阐述了一般RF算法对平衡数据进行处理的过程后,针对其处理非平衡数据时容易产生对多类的偏向性的弊端,提出了两种集成RF算法,通过对这两种集成算法的描述,使我们了解到这两种集成算法很好地克服了非平衡数据带来的学习偏向性,极大地提高了模型的预测精度。我们发现集成随机森林虽然能很好地出来非平衡数据,但其带来的计算时间增长和模型复制度的提高都对使用和学习该算法的研究者带来了不便。因此,今后的研究方向是着力于开发一种更加简单高效的算法模型。对于RF算法未来在生物信息学领域的应用,我们将进一步的进行跟踪研究。
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
中国校外教育(下旬)(2016年11期)2016-12-27
中国教育信息化·基础教育(2016年10期)2016-12-20
今传媒(2016年11期)2016-12-19
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
