
基于语谱图提取瓶颈特征的情感识别算法研究
2017-06-05 14:15:40徐珑婷
计算机技术与发展 2017年5期
李 姗,徐珑婷
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
基于语谱图提取瓶颈特征的情感识别算法研究
李 姗,徐珑婷
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
传统的谱特征(诸如MFCC)来源于对语谱图特征的再加工提取,但存在着因分帧处理引起相邻帧谱特征之间相关性被忽略的问题和所提取的谱特征与目标标签不相关的问题。这导致了从语谱图中提取的特征丢失了很多有用信息。为此,提出了获取深度谱特征(Deep Spectral Feature,DSF)的算法。DSF的特征是把直接从语谱图中提取的谱特征用于深度置信网络(DBN)训练,进而从隐层节点数较少的瓶颈层提取到瓶颈特征。为了解决传统谱特征的第一种缺陷,采用相邻多帧语音信号中提取的特征参数构成DSF特征。而深度置信网络所具有的强大自学习能力以及与目标标签密切相关的性能,使得经过微调的DSF特征能够解决传统谱特征的第二个缺陷。大量的仿真实验结果表明,相对于传统MFCC特征,经过微调的DSF特征在语音情感识别领域的识别率比传统MFCC高3.97%。
瓶颈特征;深度置信网络;谱特征;语谱图;情感识别
1 概 述
在现今的大数据时代背景下,机器学习已成为人工智能领域中一个十分重要的研究方向。如今,越来越多的研究者考虑运用机器学习的相关知识来实现语音信息识别。实际上,提取合适而准确的语音特征参数是语音信息识别研究中的关键步骤。但是,语音特征参数的提取有两个难点:无法找到与识别目标明确相关的特征;语音信息复杂多变,过分依赖于环境、说话人、情感等因素。
目前,用于语音信息识别的特征参数主要分为三类:韵律特征、音质特征以及谱特征[1-2]。其中,谱特征的研究受到了广泛关注。并且梅尔频率倒谱系数(MFCC)在相当长的一段时间内,在语音信息识别领域占据主导地位。Sun Yaxin[3]指出了MFCC谱特征存在的两个缺陷:忽略了每个语音帧内及相邻帧之间的系数关系;忽略了语音标签信息,没有提取到与目标标签相关的特征。因此,从语谱图中提取的MFCC特征会导致有用信息的丢失。文献[4]详细介绍了采用由深度置信网络产生的堆叠瓶颈特征[5-6]作为语音识别中分类模型的输入,能够提高系统识别率。可见,BN特征能充分挖掘特征参数相邻帧之间的相关性,有助于系统性能的改善。Liu Yuan等[7]运用深度学习强大的自学习能力,提高了说话人确认的识别率。深度置信网络[8]是深度学习的一种结构,采用了预训练以及微调两种方式改善参数收敛效果,使得特征参数与目标标签相匹配。它具有非常强大的自学习能力,能够获得与目标密切相关的区分性特征,滤除无关干扰,从而解决了传统谱特征的第二个缺陷。
情感识别[9]是通过计算机处理并分析获取的语音信号,进而判断出语音的情感类型的技术,它能使计算机有更加拟人化的能力。Zhang W等[10]研究了运用DBN网络进行性别相关的和无关的情感分类,说明了基于DBN的方法具有情感识别的优秀潜能。王一等[11-13]提出了鲁棒性较强的、层次稀疏的BN特征提取方法,分别用于语音识别和语种识别,均取得了不错的研究进展。
为了挖掘相邻帧之间的相关信息以及结合监督训练的优势,首次提出了采用深度置信网络直接从语谱图中提取瓶颈特征的算法,并将该特征称作深度谱特征(DSF)。其不同于目前用MFCC特征作为训练DBN网络的输入参数,直接把语谱图作为输入特征的方法能够显著减少有用信息的缺失,进而提高识别率。为了验证目标标签与语音样本之间的相关性是否有助于提高系统性能,仿真实验比较了未经微调的目标无关的DSF特征和微调后的目标有关的DSF特征。结果表明,该算法能利用标签信息和相邻帧之间的相关信息,有效提高系统识别率,解决传统谱特征的两个缺陷。
2 相关研究
2.1 瓶颈特征
瓶颈特征产生于多层感知器(MLP)模型,最早由Greal[14]提出。当MLP中间层的隐节点数相对于其他隐层较少时,该模型将在该层学习到一个训练向量的低维表述,即瓶颈特征是一种非线性降维方式。图1是一个三层MLP提取瓶颈特征的示意图[15]。
2.2 深度置信网络
深度学习的预训练机制有效地改进了神经网络的收敛效果,为了更好地实现对输入数据的低维表示,提出使用深度置信网络来提取瓶颈特征。深度置信网络是一种能量模型,拥有强大的自学习能力,且可以采用监督训练提取目标相关特征。

图1 提取瓶颈特征的结构图
2.2.1 限制玻尔兹曼机(RBM)
限制玻尔兹曼机[16]要求可见层只和隐含层连接。可见层和隐含层之间的分布满足指数分布,伯努利和高斯分布是最常用的分布形式。
设RBM模型参数为θ,可见层v以及隐含层h,则联合分布为p(v,h;θ),定义为:

(1)

可见,层向量边缘概率分布如式(2)所示:

(2)
对于伯努利-伯努利分布和高斯-伯努利分布的限制玻尔兹曼机,其能量函数分别如式(3)和式(4)所示[11]:

(3)

(4)
其中,wi,j为可见单元vi以及隐单元hj之间的连接权重;bi和aj为相应的偏置项。
RBM的训练需要计算条件分布,伯努利-伯努利RBM条件分布如式(5)和式(6)所示:
(5)
(6)
而高斯-伯努利RBM条件分布如式(7)和式(8)所示:
(7)
(8)
其中,σ(x)=1/exp(x)为sigmoid函数。
最大化对数似然函数logp(v;θ)可以优化RBM的参数集,更新式定义为:
Δwij=〈vihj〉data-〈vihj〉model
(9)
其中,〈vihj〉data为训练样本中vi和hj发生的概率;〈vihj〉model为该模型中vi和hj发生的概率。由于〈vihj〉model计算困难,常用Gibbs采样来替代〈vihj〉model[17]。
2.2.2 训练深度置信网络
将RBM栈式连接就组成了深度置信网络,对DBN每一层的RBM网络逐层训练,便可以得到预训练的DBN网络。预训练DBN网络的最后一层RBM输出到softmax分类器即达到分类的目的。Softmax函数如式(10)所示[8]:

(10)
其中,l=k表示输入被分为类别k;λik表示最后一层隐单元hi和类别k之间的权重;ak表示相应的偏置;Z(h)表示归一化项。
通过以上分类方法,采用监督训练可以对整个预训练后的网络进行微调(fine-tune)。即整个网络结构的训练分为两步:先逐层预训练;再微调整体结构。
3 深度谱特征(DSF)算法
3.1 语谱图
语谱图是语音能量时频分布的二维平面图,横坐标是时间,纵坐标是频率,具有连通时频两域的特点。而MFCC特征产生于语谱图,其提取流程为:将每帧的语谱经过Mel频率滤波器组滤波后,再进行对数能量计算,然后经过DCT变换即可获得一帧的MFCC,而整幅语谱图则可获得一条语音的MFCC系数矩阵。
图2为语谱图和MFCC提取流程图[18],下半部分为基于语谱图提取MFCC特征参数的流程图。

图2 语谱图和MFCC提取流程图
由此可见,对语谱图特征进行再加工提取可获得传统的谱特征,这一步会导致部分有用信息的丢失,造成MFCC的两个缺陷。
3.2 深度谱特征模型
从语谱图中提取相邻帧谱特征用于深度置信网络训练,进而从隐层节点数最少的瓶颈层获得瓶颈特征,得到深度谱特征(DSF),DSF特征提取流程见图3。

图3 深度谱特征提取模型
另外,DSF特征被分为两类,分别为未经微调的DSF特征(即第2步中不采用微调步骤)和微调后的DSF特征。下面分别将这两种特征命名为目标无关DSF特征和目标相关DSF特征。
该模型提取DSF特征算法如下所示:

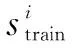
(2)使用分割后数据训练结构参数为[M1,M2,M,M2,M1]的DBN网络,满足M (3)去掉包括分类器在内的下三层网络,得到瓶颈特征提取结构。 输出:DSF特征Dtrain和Dtest,其中若第2步有微调,得到目标相关DSF,否则为目标无关DSF。 旨在从语谱图中提取比传统谱特征MFCC更有表达力的DSF特征,证明DSF特征能够克服MFCC特征的两个缺陷。为此,分别设计了两组实验来证明:DSF特征在语音情感识别上比MFCC特征具有更强的区分能力。 4.1 实验语音库及实验设计 为了验证上述算法的有效性,基于柏林库(EMO-DB)[19]进行仿真。柏林库由10个不同的人(5男5女)录制而成,包含7种不同的情感。挑选其中四种情感,分别是害怕、快乐、平静以及生气,共427条语句构成实验语音库。 为了保证仿真是性别和说话人无关的,首先对语音库进行随机打乱,再采用四折交叉验证,最后多次实验求平均。支持向量机(Support Vector Machine,SVM)[16]和高斯混合模型(GMM)[20]是实验中用到的分类器。 采用三层DBN,隐层节点数为1 288,瓶颈层节点数为36。参数设置[21]依据实验结果调整得到,其中权重衰减系数0.005,冲量0.9,批大小5,迭代次数50。 4.2 基于DSF特征的情感识别 语音情感识别在人机交互领域发挥着重要作用,其目的是让计算机像人一样识别出人类情感,赋予机器更人性化的能力[22]。设计了两个实验来证实DSF能解决MFCC的两个缺陷,提高语音情感识别率。第一个实验分别比较了目标相关DSF、目标无关DSF、传统MFCC特征的情感识别率,分别采用线性SVM和32阶的GMM分类器,进而验证了提取DSF特征算法的可行性。另外,实验也比较了上述两种特征与MFCC串联、三种特征串联组成融合特征的情感识别率。实验结果如图4所示。 由图4可知,目标相关DSF特征能利用标签相关性和相邻帧之间的联系,使SVM系统的平均识别率比目标无关DSF、MFCC特征分别高12.65%、3.97%;GMM分类器趋势一样,但是性能提高不明显。另外,基于SVM的目标无关DSF特征识别结果较差,比传统MFCC特征的识别率低8.68%,可见依据标签信息训练DBN网络这一步十分关键。但是,当把各个特征融合后,发现识别率并没有比传统MFCC特征提高太多。可见,融合可以补充一些相关信息,但是也会造成冗余,反而导致识别率下降。 图4 各种特征的情感识别结果对比 第二个实验选用目标相关DSF特征作为特征参数,用SVM分类器获得每种情感识别率的矩阵,实验结果如图5所示。 害怕/%快乐/%平静/%生气/%害怕/%75.367.2514.492.90快乐/%11.7666.180.0022.06平静/%2.450.0097.550.00生气/%1.577.870.0090.55 图5 目标相关DSF特征的情感识别矩阵 由图5可知,平均识别率可达88.77%。其中,快乐的识别率最低,因为快乐的发音特性与害怕、生气都很相似,三者的情感激活度都很高[23],所以仅仅深度谱特征不能很好地区分这三种类别的情感。但是该特征对平静和生气的识别性能很好。因为这两种情感的效价维和激活维差异较大。 为了解决传统谱特征存在的缺陷,提出了深度谱特征的算法。它把相邻帧的语谱图特征串联起来,再直接用来训练深度置信网络,最后从中间的瓶颈层获得瓶颈特征,即为深度谱特征。实验结果表明:提出的目标相关DSF特征能充分利用标签相关性,相对于SVM分类器的MFCC特征,系统平均识别率提高了3.97%。另外,该特征还考虑了相邻帧间的关系,进一步提高了识别率。今后,还要进一步研究合适的网络参数设置和网络结构,比较不同的分类器性能。并且把该DSF特征运用于多维说话人信息识别中。 [1] Kinnunen T,Li H.An overview of text-independent speaker recognition:from features to supervectors[J].Speech Communication,2010,52(1):12-40. [2] Samantaray A K, Mahapatra K,Kabi B, et al.A novel approach of speech emotion recognition with prosody, quality and derived features using SVM classifier for a class of north-eastern languages[C]//2nd international conference on recent trends in information systems.[s.l.]:IEEE,2015:372-377. [3] Sun Y,Wen G,Wang J.Weighted spectral features based on local Hu moments for speech emotion recognition[J].Biomedical Signal Processing and Control,2015,18:80-90. [4] Tuerxun M,Zhang S,Bao Y,et al.Improvements on bottleneck feature for large vocabulary continuous speech recognition[C]//12th international conference on signal processing.[s.l.]:IEEE,2014:516-520. [6] Zhang Y,Chuangsuwanich E,Glass J R.Extracting deep neural network bottleneck features using low-rank matrix factorization[C]//ICASSP.[s.l.]:[s.n.],2014:185-189. [7] Liu Y,Qian Y,Chen N,et al.Deep feature for text-dependent speaker verification[J].Speech Communication,2015,73:1-13. [8] Safari P,Ghahabi O, Hernando J. Feature classification by means of deep belief networks for speaker recognition[C]//23rd European signal processing conference.[s.l.]:IEEE,2015:2117-2121. [9] Pal A,Baskar S.Speech emotion recognition using deep dropout autoencoders[C]//International conference on engineering and technology.[s.l.]:IEEE,2015:1-6. [10] Zhang W,Zhao D,Chen X,et al.Deep learning based emotion recognition from Chinese speech[M]//Inclusive smart cities and digital health.[s.l.]:International Publishing,2016:49-58. [11] 王 一,杨俊安,刘 辉,等.基于层次稀疏 DBN 的瓶颈特征提取方法[J].模式识别与人工智能,2015,28(2):173-180. [12] 李晋徽,杨俊安,王 一.一种新的基于瓶颈深度信念网络的特征提取方法及其在语种识别中的应用[J].计算机科学,2014,41(3):263-266. [13] 陈 雷,杨俊安,王 一,等.LVCSR系统中一种基于区分性和自适应瓶颈深度置信网络的特征提取方法[J].信号处理,2015,31(3):290-298. [14] Grézl F,Karafiát M,Kontr S,et al.Probabilistic and bottle-neck features for LVCSR of meetings[C]//Proceedings of the IEEE international conference on acoustics,speech,and signal processing.Honolulu,USA:IEEE,2007:757-760. [15] Gehring J,Miao Y,Metze F,et al.Extracting deep bottleneck features using stacked auto-encoders[C]//IEEE international conference on acoustics, speech and signal processing.[s.l.]:IEEE,2013:3377-3381. [16] 张春霞,姬楠楠,王冠伟.受限波尔兹曼机[J].工程数学学报,2015,32(2):159-173. [17] You Y,Qian Y,He T,et al.An investigation on DNN-derived bottleneck features for GMM-HMM based robust speech recognition[C]//China summit and international conference on signal and information processing.[s.l.]:IEEE,2015:30-34. [18] 陶华伟,査 诚,梁瑞宇,等.面向语音情感识别的语谱图特征提取算法[J].东南大学学报:自然科学版,2015,45(5):817-821. [19] Burkhardt F,Paeschke A,Rolfes M,et al.A database of German emotional speech[C]//Proceedings of Interspeech.[s.l.]:[s.n.],2005:1517-1520. [20] Anagnostopoulos C N,Iliou T,Giannoukos I.Features and classifiers for emotion recognition from speech: a survey from 2000 to 2011[J].Artificial Intelligence Review,2015,43(2):155-177. [21] Hinton G E.A practical guide to training restricted Boltzmann machines[J].Momentum,2010,9(1):599-616. [22] Mariooryad S,Busso C.Compensating for speaker or lexical variabilities in speech for emotion recognition[J].Speech Communication,2014,57:1-12. [23] Koolagudi S G,Rao K S.Emotion recognition from speech:a review[J].International Journal of Speech Technology,2012,15(2):99-117. Research on Emotion Recognition Algorithm Based on Spectrogram Feature Extraction of Bottleneck Feature LI Shan,XU Long-ting (College of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China) Traditional spectral features (such as MFCC) can be extracted from spectrogram features.However,the relation between spectral features of adjacent frames has been ignored owing to frames division.What’s worse,the extracted spectral features are uncorrelated with the labels of corresponding targets,which lead to useful feature information lost.Therefore,a new Deep Spectral Feature (DSF) algorithm has been proposed,in which DSF features have been gained by applying spectral feature directly extracted from spectrogram for Deep Belief Network (DBN) and a kind of bottleneck (BN) feature from the bottleneck layer has been obtained with least hidden layer nodes number.To deal with the first drawback,a method is proposed to extract characteristic parameters from adjacent frames that consist of DSF features.What is more,owing to strong self-learning ability and substantial relationship with target labels in deep belief network,the proposed DSF feature can supply a better solution to the second drawback of conventional spectral features.Experimental results show that the accuracy of DSF feature with proper fine-tuning outperforms traditional MFCC about 3.97% in speech emotion recognition. bottleneck feature;deep belief network;spectral feature;spectrogram;emotion recognition 2016-06-18 2016-09-22 网络出版时间:2017-03-13 国家自然科学基金资助项目(61271335);国家“863”高技术发展计划项目(2006AA010102) 李 姗(1992-),女,硕士研究生,研究方向为情感识别、多维说话人信息识别技术。 http://kns.cnki.net/kcms/detail/61.1450.tp.20170313.1547.074.html TP301.6 A 1673-629X(2017)05-0082-05 10.3969/j.issn.1673-629X.2017.05.0184 实验结果与分析


5 结束语
猜你喜欢
中国毕业后医学教育(2021年3期)2021-12-02 02:24:20
中国毕业后医学教育(2021年3期)2021-12-02 02:24:18
陶瓷学报(2021年2期)2021-07-21 08:34:58
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
中国环境监察(2016年11期)2016-10-24 05:25:16
中国卫生(2016年1期)2016-01-24 07:00:03
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
东南大学学报(自然科学版)(2015年5期)2015-03-15 00:54:56
