
基于用户分裂的资源扩散算法
2017-06-05 14:14曹宏斌林中琦
中国电子科学研究院学报 2017年2期
曹宏斌,张 亮,林中琦
(山东农业大学计算机科学与工程学院,山东 泰安 271018)
基础理论
基于用户分裂的资源扩散算法
曹宏斌,张 亮,林中琦
(山东农业大学计算机科学与工程学院,山东 泰安 271018)
对智能手机应用的个性化推荐进行了研究,提出了一种基于用户分裂的资源扩散算法,算法把偏好随时间维度发生变化的用户看作多个用户,即采用用户分裂思想,从而引入时间上下文信息,更充分的利用数据信息,提高了推荐算法的准确率;对移动应用进行聚类,得到更多类别,优化推荐结果。实验表明基于用户分裂的资源扩散算法提高了推荐结果的准确率。
推荐系统;时间上下文;用户分裂;图模型;移动应用
0 引 言
个性化推荐是20世纪90年代被作为一个独立的概念提出来,推荐系统本质是联系用户和项目的媒介,联系方式有3种[1]:第一种是分析用户喜欢的项目,为其推荐相似项目;第二种是找到与用户A有相似兴趣的用户B,将用户B喜欢的项目推荐给用户A;最后一种是通过分析用户数据,从而得到用户特征,推荐包括这些特征的项目。根据推荐算法的不同,推荐系统可以分为如下几类:协同过滤系统;基于内容的推荐系统;基于用户-项目二分图网络结构的推荐系统以及混合推荐系统[2]。
在大数据时代[3],针对海量移动应用,研究者提出了很多算法,Woerndl等[4]基于已有用户在相似环境下的安装信息为新用户推荐移动应用。Yan Bo等[5]通过收集用户的详细使用记录,利用基于项目的协同过滤算法为用户进行移动应用推荐。Christoffer等[6]通过引入隐式反馈和上下文感知,较好地解决了冷启动问题。Yan Zheng等[7]提出了基于信任行为的移动应用推荐系统。这些方法在很大程度上提高了推荐的质量,但是需要多维度的上下文信息,比如安装信息、详细使用记录、隐式反馈的统计信息等,这些信息的收集和处理需要更多的资源,增加了系统实现的复杂度,而且现存的旧系统不具备相关的信息收集和信息处理模块,不利于算法的推广应用。本文借鉴文献[8]的工作,提出了一种基于用户分裂的资源扩散算法,通过利用已有的时间上下文信息,提高了推荐算法的准确率。
1 资源扩散算法
周涛等[8]等认为在一个由m个用户和n个项目构成的推荐系统中,如果用户u选择过项目i,则在用户u和项目i之间存在一条边,所以推荐系统可以表示为一个m+n个节点组成的二部分图(bipartite network),利用用户-项目二分图模型进行个性化推荐的主要任务就是计算用户顶点与其没有直接相连的项目顶点之间的相关性,据此提出一种基于资源扩散的推荐算法。算法模拟了物理学中的物质扩散,当物质浓度在整个空间差异较大时,在分子布朗运动的影响下,高浓度区域的分子将向低浓度区域扩散。在推荐系统中将项目集合看作具有一定初始资源(浓度)的分子聚集空间,通过用户-项目二分图网络结构进行资源扩散,得到资源重新分配的结果,并根据分配结果对用户进行项目推荐。
假定二分图G(X,Y,E),其中项目集合X={x1,x2,…,xn},Y={y1,y2,…,ym},边集E。
设g(xi)≥0表示表示集合X中第i个节点的初始资源,g(yl)是Y中的第l个元素的资源值,资源由X扩散到Y。
(1)
其中k(xi)是xi的度数,ail是n×m的邻接矩阵

(2)
最后,资源从Y回流到X,此刻X上的权值为
(3)
得到公式
(4)
其中
(5)
整个过程可以表示为g1=Wg。其中W={wij}n×n是资源转移矩阵,是集合X中元素经过两步扩散进行资源重新分配的结果,每一列元素和为1,wij代表了资源从节点xj转移到节点xi所占的比例,0≤wij≤1。

图1 资源扩散算法
得到用户的项目偏好向量,元素值的大小反应了用户对项目的偏好程度。
2 基于用户分裂的资源扩散算法
Lathia等[9]发现直接从历史记录中得出推荐结果的算法,若不考虑时间因素,尽管在测试集上有良好表现,但在实践中效果不佳。本文引入时间上下文信息,把随时间发生偏好变化的用户分裂为多个用户,即采用用户分裂思想引入时间信息,来改进资源扩撒算法。
基于用户分裂的资源扩散算法描述:m个用户,用U={u1,u1,...,um}表示,每个用户有在不同的时间选择不同的项目的时间的属性,用P={p1,p2,…,pm}表示,n个项目,用I={i1,i2,…,in}表示,s个项目标签,用T={t1,t2,…,ts}表示。数学模型表示为一个具有m+m+n+s个节点的四分图G(P,U,I,T,E)。
在计算用户的推荐列表时,通过以下步骤:
STEP1:资源扩散(如图2),对用户U-项目I使用资源扩散算法得到项目I中元素的资源分配结果,存储为资源转移矩阵
STEP2:项目聚类,为缩小标签粒度,增加标签数量,对项目数量大于阈值的标签进行标签内项目聚类,如图3(a)变换到3(b)。项目ia和ib的相关性越大,wij和wji的值越大,越接近1,即ia和ib间的距离d

令项目I元素间的距离为
使用K-means算法在标签内进行项目聚类,细化标签,得到标签集合T1;
STEP3:用户分裂,使用用户分裂思想,把偏好随时间维度发生变化的用户分裂成多个用户,对发生用户分裂的用户进行推荐时,使用分裂思想得到的新用户可以作为历史用户参与算法运算,如图3(b)变换到3(c)。

图2 资源扩散

图3 用户分裂
当r1≥R时,认为用户偏好发生了变化,得到新用户ua1,即从用户ua分裂出ua1,ua1兴趣列表是D1。

持续用户分裂过程,直到所有用户分裂完毕。
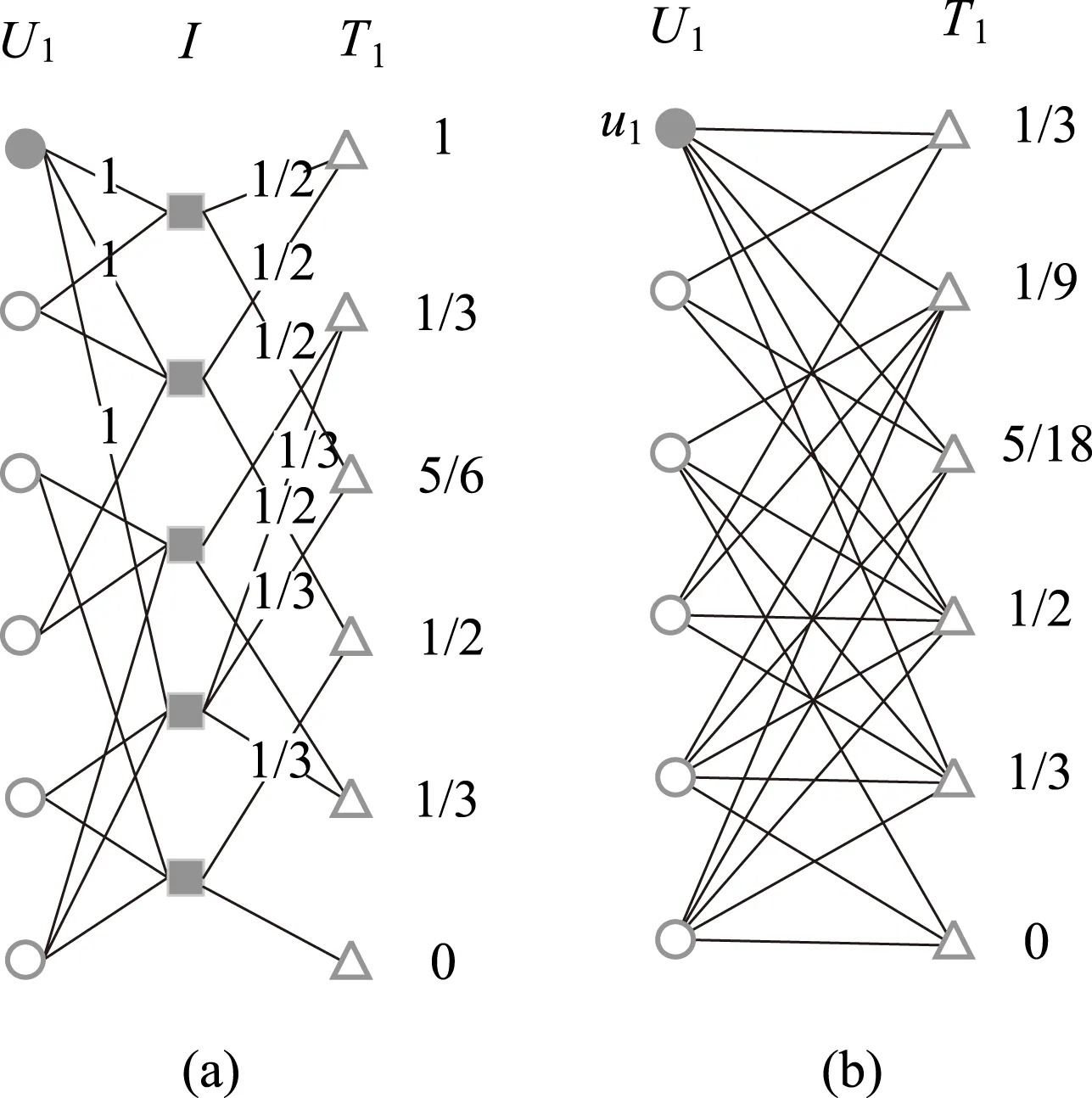
图4
STEP5:生成推荐列表,基于用户标签偏好向量,按比例推荐各个标签内项目,标签内对用户-项目使用资源扩散算法确定标签内推荐项目。
3 基于用户分裂的资源扩散算法的动态变化
在实际的算法应用环境中,用户和项目是动态变化的,这些动态变化在智能手机应用环境中主要表现为包括用户和移动应用的增加和删除。
(1)增加新用户,新用户unew加入U1,系统选取各标签内的热门项目进行推荐,然后把unew的应用下载情况映射到(U1,T1);
(2)增加移动应用,假设新移动应用inew的上传者标记了三个标签ta,tb,tc∈T,用投票算法确定inew的新标签tx,ty,tz∈T1;
投票算法描述为:若标签ta细化为标签ta1,ta2,ta3,取得下载过新应用inew的用户集合Uinew,Uinew在ta中应用下载列表为(ia:ta1,ic:ta2,…,ib:ta3,ic:ta2…,ib:ta3,ie:ta2),被下载次数最多的标签为新应用inew的标签。
(4)删除用户,当某个用户的相关应用都被删除后删除此用户。
4 实验验证与相关分析
4.1 数据集及度量标准
数据集是在2015年12月爬取360应用圈得到的,包括1065个Android 移动应用及其下载者和下载日期,每个移动应用有2至3个标签,标签由上传者从应用圈提供的27个系统标签中选取。把数据集按下载时间增序均分成5个数据子集,进行算法验证。以top20的平均查准率为度量标准。
4.2 实验结果及分析
实验中参考创新的扩散的比率[10],取R=0.16进行实验,当标签内移动应用数目大于60时进行标签内聚类。对资源扩散算法和基于用户分裂的资源扩散算法实验,得到对比表1和对比图5。
表中测试数据子集数为按时间排序的前m个子集。
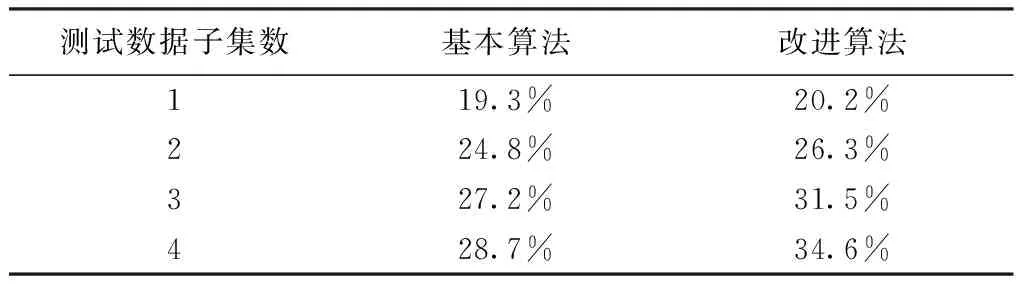
表1 算法平均查准率对比表

图5 算法准确率对比图
由图5可以看出基于用户分裂的资源扩散算法在实验数据集中的准确率明显的优于传统的资源扩散算法,这是由于算法采用用户分裂思想引入时间上下文信息,更加充分使用数据的时间属性,改善了算法在实际应用中的表现;随着测试子集数据的增加,两种算法平均查准率都有所增大,而基于用户分裂的资源扩散算法增幅更加明显,说明随着数据集的增多,用户的兴趣列表增大,参与用户分裂的用户比例增加,该算法可以更加有效的利用时间上下文属性,从而提高了算法准确率。
5 结 语
基于用户分裂的资源扩散算法通过用户分裂引入时间上下文信息,提高了算法的准确率。用户分裂避免了超大用户的出现,防止超大用户对其他用户推荐结果的过度影响;为方便用户上传应用,系统一般提供粒度较大的标签供用户选取进行标记,本算法通过标签内聚类,得到更加细化的标签,解决了系统标签数量少、粒度大的问题;通过用户标签偏好进行推荐,增加了推荐结果的多样性和可解释性;在标签内通过资源扩散算法生成推荐结果,实际上分解了用户-项目二分图的网络结构,减小了算法的运算规模,提高了算法效率。
为提高推荐效用,将在进行以下方面改进:算法使用了刚性聚类[11],即聚类后各类中的元素不重合,与实际不符,虽然一个移动应用具有多个标签,缓解这个问题,但没有彻底解决,下一步将研究适合移动应用的非刚性聚类来进一步提高算法准确率。
[1] 项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012: 166-178.
[2] 刘建国, 周涛, 汪秉宏. 个性化推荐系统的研究进展[J]. 自然科学进展, 2009, 19(1):1-15.
[3] 大数据时代[J]. 中国电子科学研究院学报,2013,(01):27-31.
[4] Woerndl W, Schueller C, Wojtech R. A hybrid recommender system for context-aware recommendations of mobile applications[C]//Data Engineering Workshop, 2007 IEEE 23rd International Conference on. IEEE, 2007: 871-878.[5] Yan B, Chen G. AppJoy: personalized mobile application discovery[C]//Proceedings of the 9th international conference on Mobile systems, applications, and services. ACM, 2011: 113-126.
[6] Davidsson C, Moritz S. Utilizing implicit feedback and context to recommend mobile applications from first use[C]//Proceedings of the 2011 Workshop on Context-awareness in Retrieval and Recommendation. ACM, 2011: 19-22.
[7] Yan Z, Zhang P, Deng R H. TruBeRepec: a trust-behavior-based reputation and recommender system for mobile applications[J]. Personal and Ubiquitous Computing, 2012, 16(5): 485-506.
[8] Zhou T, Ren J, Medo M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4): 046115.
[9] Lathia N K. Evaluating collaborative filtering over time[D]. University College London, 2010.
[10] 罗杰斯. 创新的扩散[M]. 辛欣, 译. 北京: 中央编译出版社, 2002.
[11] 孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008, 19(1): 48-61.
Integrated Diffusion-based Recommendation Algorithm based on User Division
CAO Hong-bin, ZHANG Liang, LIN Zhong-qi
(School of Computer Science and Engineering, Shandong Agricultural University, Taian 271018, China)
Do some researches on personalized recommendation of smartphone application, propose a integrated diffusion-based recommendation algorithm based on user division. The algorithmregardsthe user of preference transition from time dimension as multiple users, namely user division, therefore introducing time context information and utilizing data information more fully. By clustering the mobile applications, more categorieswere gettedand the recommendation results were optimized. Experimental results indicate that the integrated diffusion-based recommendation algorithm based on user division improves the accuracy of recommendation results.
recommendation system; time content; user division; graph model; mobile application
10.3969/j.issn.1673-5692.2016.02.011
2016-12-31
2017-03-01
山东省高等学校科技计划项目(G11LG26)
TP301.6
A
1673-5692(2017)02-159-05
曹宏斌(1990—),男,山东人,硕士研究生,主要研究方向为个性化推荐;
E-mail:linbined@163.com
张 亮(1979—),男,山东人,博士,副教授,主要研究方向为智能信息处理,网络工程以及农业信息化等;
林中琦(1992—),男,山东人,硕士研究生,主要研究方向为机器学习。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
