
基于HBase的数值预报产品存储检索应用
2017-06-02 20:10王建荣
电子技术与软件工程 2017年10期


数值预报产品数据快速增长,传统的关系型数据库对其存储和管理能力不足,查询规模较大的历史数据时效率较低。鉴于此,基于HBase设计了分布式的数据存储模型,应用MapReduce将数值预报产品解码信息存入HBase,并将解码得到的要素GRIB文件写入HDFS。因HBase对Rowkey的一级索引支持较好,而对多条件查询支持不足,需辅助 Solr索引加以优化。HBase接收数据时自动触发协处理器同步记录到Solr,实现了HBase的二级索引。测试结果表明,最快入库速度可达每秒16145条,数据检索结果返回时效达到毫秒级,能够满足业务应用中对数值预报产品存储和检索时效的要求。
【关键词】HBase MapReduce 要素GRIB文件 解码日志文件 SolrCloud
气象数据是气象业务和科研工作的基础。近年来气象现代化业务发展迅速,气象探观测数据、各种气象产品数据都呈快速增长之势,数据种类不断增加的同时,数据规模也随着覆盖范围和精度的扩展、数据密度频次的提高而越来越大,这些数据包括结构化的数据,如自动气象站观测数据等,也包括气象卫星产品和气象雷达产品等半结构化和非结构化数据。对于结构化的数据可以通过关系型数据库进行分析、处理和计算,但对于海量的历史数据,关系型数据库存储和检索效率较低;对于数值预报产品等非结构化数据大多基于文件方式(如GRIB格式文件)存储和处理。不断增长的数据量使得关系型数据库系统负载过于饱和,影响了系统服务的时效性和稳定性。中国气象局CIMISS(全国综合气象信息共享平台)[1-2]数据库中存储多种数值预报产品信息,每行记录包含起报时间、预报时效、层次、预报要素代码、区域代码、单要素GRIB文件路径等字段,而具体的GRIB文件存储在GPFS集群文件系统中。为确保Oracle数据库稳定运行,数值预报产品记录保存3-6个月,并定时清除表空间。在业务和科研工作中,往往需要长时间序列的数值预报产品数据,并且要求实时检索,因此考虑利用分布式 架构来解决海量气象数据存储检索所面临的问题。
在分布式存储和计算技术中,Hadoop平台具有高吞吐量、高并发、高容错性、高可靠性、低成本、能扩展到云环境的优势。目前基于Hadoop生态系统的气象数据存储检索方案成为国内外研究热点。李永生等[3]选用Hadoop与HBase相结合的方式设计数值预报产品服务平台;陈东辉等[4] 详细介绍了基于HBase 的气象地面分钟数据分布式存储系统。本文选取HBase数据库实现气象数据文件的分布式存储管理,并实现前端GRIB解码入库性能优化和后端数据检索性能优化。实验测试验证了基于HBase 的数值预报产品存储与检索方案的可行性,为海量气象数据的存储和检索服务提供一種优化思路。
1 数据存储模型设计
1.1 HBase简介
Apache Hadoop是一个分布式系统基础架构,包括两大核心:Hadoop分布式文件系统HDFS和MapReduce分布式编程模型[5]。HBase(Hadoop DataBase)作为Hadoop中的一个子项目,使用Zookeeper管理集群,运行在HDFS分布式文件系统之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
Zookeeper 分布式服务框架是 Apache Hadoop的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
1.2 数据存储模型设计
研究方案将数值预报产品通过GRIB API解码[6-7]后存储在HBase中,不同的数值预报产品分开存储在不同的实体数据表中,目前实际存储了3大类数值预报产品,包括ECMWF(欧洲中期数值预报中心)发布的细网格(0.25? ×0.25?水平分辨率)的数值预报产品,JMA(日本气象厅)发布的0.5? ×0.5?水平分辨率数值预报产品,高分辨率东北半球T639数值产品。数据表以行键、列族、数据的方式存储数值产品的实体数据。数据表存储内容说明如表1所示。
data:gribpath是解码所得要素GRIB文件的在HDFS文件系统中的存储路径,GRIB包含的格点数据在Rest Web Service接口调用时作为二维数组返回。
选取表1中data:date、data:validtime和data:centre三列做数据模型展示,见表2。
行键的设计:
HBase中的行键(Rowkey)可以唯一标识一行记录。根据HBase的优化原则[8],Rowkey的长度易固定且不超过200Bytes,设计如下:AAAAATTT:yyyyMMdd:nnnmmmm:IIIIXJJJJ,AAAAA为5字母长度的英文缩写,不足5位则在其后补“9”,代表数值预报产品的预报要素名称;TTT 为预报时效;nnn表示高度层类型,mmm表示层次;IIII表示4位I方向增量,不足4位则前导置“0”;JJJJ表示4位J方向增量,不足4位则前导置0。
以ECMF数据表的行键为例:
TEMP9006:20160711:1000010:0250X0250
其含义是:对于温度要素(temp),在2016 年7 月11日00:00 起报,预报时效为未来6h的预报场,预报层次为10hPa,I方向增量为0.25?,J方向增量为0.25?。
时间戳(Timestamp):每条数据更新的历史记录,同一行键数据再次入库会记录不同的时间戳。
列族(Column Family):每种数值预报产品的表结构基本相同,每张表只设一个列族data,其包含的列(Column Qualifier)有data:date、data:validtime、data:centre、data:gribpath等。HBase存储的都是Byte数组。
2 基于Solr的二级索引设计
2.1 Solr简介
Apache Solr是一种开源的、基于 Lucene的全文检索引擎,支持XML、JSON 和python等常用输出格式。而SolrCloud[9-10]是基于Solr和Zookeeper的分布式搜索方案,使用Zookeeper作为集群的配置信息中心。
2.2 SolrCloud的工作模式
SolrCloud中包含有多个Solr Instance,每个Solr Instance中包含多个Solr Core,Solr Core对应着一个可访问的Solr索引资源Replica(复本),当Solr Client通过Collection访问Solr集群时,便可以通过Shard分片找到对应的Replica,从而就可以访问索引文档了,如图1所示。
在SolrCloud模式下,同一个集群里所有Core的配置是统一的,Core有Leader和Replication两种角色,每个Core一定属于一个Shard,Core在Shard中扮演Leader还是Replication由Zookeeper自动协调。
2.3 二级索引设计
HBase在存储时,默认按照Rowkey进行排序(字典序)并通过Rowkey及其range来检索数据,在HBase查询的时候,有以下几种方式:
(1)通过get方式,指定Rowkey获取唯一一条记录;
(2)通过scan方式,设置startRow和stopRow参数进行范围匹配;
(3)全表扫描,即直接扫描整张表中所有行记录。
HBase对Rowkey的一级索引支持较好,按Rowkey查询的响应时间达到毫秒级。HBase内置Filter(过滤器)特性以支持多条件查询的二级索引。但HBase的Filter是直接扫描记录的,如果数据范围很大,会导致查询速度很慢。因此基于Solr来实现二级索引,满足Rowkey之外的多要素数据检索需求。
基于Solr的HBase多条件查询原理:将HBase表中涉及条件过滤的字段和Rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的Rowkey值,再根据Rowkey从HBase中进行查询,返回记录集,如图2所示。
设计SolrCloud索引的关键问题是合理的配置索引字段。Zookeeper统一管理XML格式的Solr索引字段描述文件文件:managed-schema,SolrCloud各实例(Instance)共享同一个managed-schema。具體配置如下:
……
3.2 HBase协处理器
HBase的协处理器[12](Coprocessor)分为两类,Observer和EndPoint:Observer相当于关系型数据库中的触发器,EndPoint则相当于存储过程。其中Observer的代码部署在服务端,相当于对API调用的代理。选用RegionObserver观察者接口(API),其提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
3.3 HBase协处理器向Solr写索引
实时更新数据需要获取到HBase的插入、更新和删除操作:拦截put和delete操作,将其内容获取出来,同步写入Solr。HBase协处理器定义以及同步数据到Solr的主要代码:
public class SolrIndexCoprocessorObserver extends BaseRegionObserver {
@Override
public void postPut(ObserverContext
String rowKey = Bytes.toString(put.getRow());
try {
Cell cellEdition = put.get(Bytes.toBytes("data"), Bytes.toBytes("edition")).get(0);
String strEdition = new String(CellUtil.cloneValue(cellEdition));
Cell cellDate = put.get(Bytes.toBytes("data"), Bytes.toBytes("date")).get(0);
String strDate = new String(CellUtil.cloneValue(cellDate));
……
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", rowKey);
doc.addField("edition", strEdition);
……
// 写入缓冲
SolrWriter.addDocToCache(doc);
}
Solr中的每条Document(SolrInputDocument对象)对应HBase表里的一条记录。HBase记录写入SolrCloud的性能优化:默认情况下HBase每写入一条数据就会触发一次postPut,比较耗费网络IO,因此先将Document缓存在List中并采用两种方式批量提交:
(1)当缓存达到设定的阈值时立即提交到SolrCloud;
(2)定时提交。
最后需要通过HBase Shell为相关产品数据表添加协处理器。
5 性能测试
5.1 测试环境
(1)软件及版本:
hadoop-2.6.0;
zookeeper-3.4.6;
solr 5.5.4,使用其自帶的Jetty服务端容器,云模式运行;
hbase-1.2.2;
GRIB API 1.12.3。
(2)硬件配置:
测试环境由4台X86架构的服务器组成,操作系统均为64位CentOS 6.5。其中3台服务器构建Hadoop、Zookeeper、HBase、Solr集群,1台部署数值预报产品解码入库程序(Hadoop、HBase等客户端程序);
处理器:Intel Core i5-3470 3.20GHz;
磁盘:1TB,7.2K 600MB/s SATA III接口;
内存:16GB;
网络环境为千兆局域网。
5.2 测试对象和方法
选取高分辨率东北半球T639数值产品及其解码得到的要素GRIB文件为测试对象,均采用GRIB2编码,其平均大小为约50MB。
5.2.1 HDFS写入性能
T639数值产品共504个文件,共24.9GB,平均大小50.59 MB。客户端程序调用HDFS API的文件复制操作将T639数值产品文件写入HDFS文件系统需要347秒,平均写文件速度为73.48MB/s。
5.2.2 HBase入库性能
解码生成了504个解码日志文件,共178920条记录,耗时13s,平均写入速度13725条/s;随机抽取1000,2000,…,10000条记录入库,如图4所示。测试结果表明:随着入库记录数的增加,数据入库性能总体平稳,最快写入速度16145条/s。
5.2.3 索引完整性验证
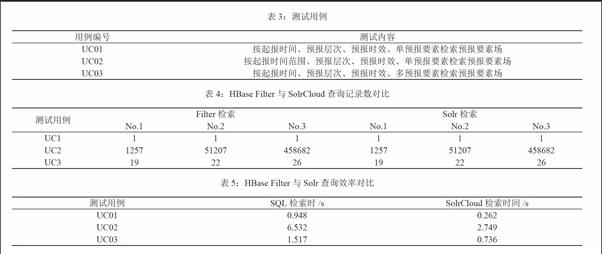
测试用例设计如表3。
在验证Solr索引完整性上,分别对基于HBase Filter[15]的条件过滤查询和SolrCloud索引查询返回的记录数对比,如表4所示。
表4中每个测试用例均做了3组对比,基于SolrCloud索引的查询记录数均和HBase Filter查询的记录数一致,说明索引完整可用。
5.2.4 HBase检索性能
将表4中HBase Filter检索换成CIMISS系统 Oracle数据库查询,且Oracle中T639数据表与HBase T639表均保留2000万条记录。考查表4中各测试用例中No.3列所需时间对比如表5所示。
由表5得出结论:无论是UC01、UC03按时间点查询还是UC02中按时间范围查询,基于SolrCloud的查询效率都高于Oracle SQL查询;SolrCloud方式按时间点的查询基本都在毫秒级返回结果。
6 结束语
本文针对关系型数据库在数值预报产品数据的存储及检索效率低的问题,研究HBase分布式数据库结合SolrCloud索引服务的数据存储与检索优化方案,设计了适合气象业务应用的数值预报产品数据存储模型,并建立Solr索引。关键技术是前端Map并行方式入库、HBase协处理器同步记录至SolrCloud。实验测试验证了该方案提高了存储效率和检索速度,能够满足业务中的时效性要求。
对于HBase 的參数调优、动态增加节点时HBase的扩展性能测试以及索引的更新维护将是下一步研究的工作。
参考文献
[1]熊安元,赵芳,王颖等.全国综合气象信息共享系统的设计与实现[J].应用气象学报,2015,26(04):500-512.
[2]杨润芝,马强,李德泉等.内存转发模型在CIMISS数据收发系统中的应用[J]. 应用气象学报,2012,23(03):377-384.
[3]李永生,曾沁,徐美红等.基于Hadoop的数值预报产品服务平台设计与实现[J].应用气象学报,2015,26(01):122-128.
[4]陈东辉,曾乐,梁中军等.基于HBase 的气象地面分钟数据分布式存储系统[J].计算机应用,2014,34(09):2617-2621.
[5](美)Tom White.Hadoop权威指南(第3版)[M].北京:清华大学出版社,2015:19-58.
[6]张苈,周峥嵘,刘媛媛.ECMWF GRIB API及其应用[A].中国气象学会气象通信与信息技术委员会暨国家气象信息中心科技年会[C].2011年.
[7]李葳.NECP FNL资料解码及数据格式转换[J].气象与减灾研究,34(01):64-68.
[8](美)Lars George. HBase权威指南[M]. 北京:人民邮电出版社,2011:344-348.
[9]郝强,高占春.基于SolrCloud的网络百科检索服务的实现[J].软件,2015,36(12):103-107.
[10]付剑生,徐林龙,林文斌.分布式全网职位搜索引擎的研究与实现[J].计算机技术与发展,2015,25(05):6-9.
[11]杨润芝,沈文海,肖卫青等.基于MapReduce计算模型的气象资料处理调优试验[J].应用气象学报,2014,25(05):618-628.
[12]邹敏昊.基于Lucene的HBase全文检索功能的设计与实现[D].南京:南京大学,2013:30-65.
[13]李永生,曾沁,杨玉红等.基于大数据技术的气象算法并行化研究[J].计算机技术与发展,2016,26(09):47-49.
[14]单剑锋,马德锦.常用Web服务技术研究[J].计算机技术与发展.2013,23(06):253-257.
[15]张叶,许国艳,花青.基于HBase的矢量空间数据存储与访问优化[J].计算机应用,2015,35(11):3102-3105.
作者简介
王建荣(1981-),男,硕士学位。工程师。主研方向为分布式数据库。
唐怀瓯,高工。
金素文,高工。
作者单位
安徽省气象信息中心 安徽省合肥市 230031
