
基于数据挖掘的校园一卡通数据应用研究
——以石家庄学院为例
2017-06-01 12:38冯玖李俊玲张海霞郭鹏赵峰谢通
石家庄学院学报 2017年3期
冯玖,李俊玲,张海霞,郭鹏,赵峰,谢通
(石家庄学院a.信息中心;b.图书馆,河北石家庄050035)
基于数据挖掘的校园一卡通数据应用研究
——以石家庄学院为例
冯玖a,李俊玲a,张海霞a,郭鹏b,赵峰a,谢通a
(石家庄学院a.信息中心;b.图书馆,河北石家庄050035)
分析了石家庄学院一卡通的整体使用情况,随后对学生就餐消费数据进行了统计分析,详细了解了学生的就餐行为规律,最后选取某专业学生,对其就餐数据与学习成绩进行了关联分析.通过一卡通数据的研究,为学校决策者和相关管理部门提供决策支持.
一卡通;数据挖掘;关联分析
0 引言
随着校园一卡通的广泛普及和深入应用,一卡通数据库已经积累了越来越多的数据,借助相关分析方法和工具对其进行分析,可以从多角度精确了解学生的相关行为,从而帮助学校相关部门掌握学生的学习、消费及作息规律,做出科学决策.
1 数据预处理
1.1 数据来源
为了反映数据的全面性,选取石家庄学院全体在校生1个学期的数据进行统计分析.从一卡通系统中抽取2015-2016学年第2学期(2016年3-6月)共计2 086 203条刷卡记录,教务系统中抽取全体在校生基本信息及其学习成绩等数据.图1为一卡通中的原始数据.
1.2 数据预处理
由于人为错误、设备故障或传输错误等会产生噪声、冗余数据,并且数据来源于不同的部门和系统,难免存在数据类型或结构等不一致性.因此,必须对数据进行预处理后才能进行后续的数据挖掘和分析等工作.数据预处理的方法有很多,本研究采用比较常见的几种,包括数据清理、数据集成、数据变换和数据规约[1].
1.2.1 数据清理
进行数据清理的方法有缺失值的处理、噪声数据的处理等[2].首先分析一卡通中的数据,该系统存储了教职工、学生、临时工、外来人员等各种人员的数据,由于教职工、临时工和外来人员在学校的消费行为具有很强的离散性和不确定性,如果将他们的数据也加入到后续挖掘分析中,会影响分析的结果,所以只对所有在校上课的学生进行考察.经过处理后刷卡记录减少了5万余条.学生基本信息部分的数据存储在教务系统中,日常的教务教学都以此为标准,数据的准确性比较高,针对本次数据挖掘分析,需要对数据缺失的部分进行处理,比如服兵役、休学、开除、退学、缺考等原因引起的,从数据样本中删除该部分学生信息,经处理后大大提高了数据质量.
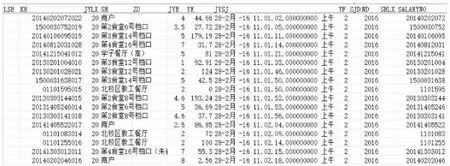
图1 一卡通数据库中的原始数据
1.2.2 数据集成
本研究使用的数据分别来自一卡通中间库和教务系统,需要进行数据集成.为了方便数据分析,决定将不同数据源的数据按要求抽取后生成excel文件再导入到目标数据库中.在数据集成的过程中,不同源数据属性相同的列存在部分冗余的可能性,在此以教务系统中数据为准,校正一卡通中的部分数据.数据库由不同的设计者设计,采用数据类型也不尽相同,比如学生学号为11位,但一卡通中对应卡号存在部分不规范数据(如图1中的KH列和SALARYNO列),需要对该部分数据进行更新,保持数据格式和内容的一致性.
1.2.3 数据变换
为了提高挖掘的效率和维度,对学生消费记录中的就餐时间格式进行拆分,转换为刷卡的日期、时间、上下午、星期等详细属性,如图2所示.
1.2.4 数据规约
本次数据挖掘的目标主要是对学生食堂消费数据进行挖掘分析,因此有很多属性与挖掘目标不存在相关性或弱关联,选择放弃这些属性,比如学生基本信息表中的性别、班级、身份证号;消费记录中的卡号、余额、月份、年代;学生成绩信息中的课程名称、课程代码等信息.
通过以上数据处理,使得待挖掘分析的数据干净并且合乎要求,为以后的数据挖掘分析奠定了基础.
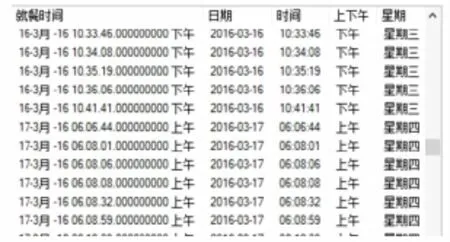
图2 就餐时间拆分图
2 一卡通数据总体分析
2.1 刷卡类别统计
通过以上的数据预处理工作,得到了待挖掘的数据.按一卡通使用类型对所有刷卡记录进行分类统计,合并种类相似的记录,经汇总得出图3信息,从中可以明显看出,有近9成的数据量为食堂就餐消费,其他依次分别为超市和商户、上机、洗浴等.
2.2 按年级统计刷卡次数
从教务系统中得出各年级学生人数在5 000左右,人数基本相同,按年级对刷卡数据进行汇总求和得出数据,如图4所示.
由图4可以明显看出随着年级的增长,学生的刷卡量呈递减趋势:其中,大一新生将近80万次,随后大二、大三以20万左右的刷卡量减少,大四毕业班已不足20万次,在学生人数基本持平的情况下,学生刷卡次数存在明显减少的趋势.以上统计结果和对学生的实际调查情况基本对应:大一学生由于初到新学校,环境相对陌生,生活、学习主要在校内,随着活动半径增大,陆续有学生到校外就餐、兼职,大四毕业班中大量学生开始找工作或进入企业实习、培训等,造成了刷卡数量的急剧减少.
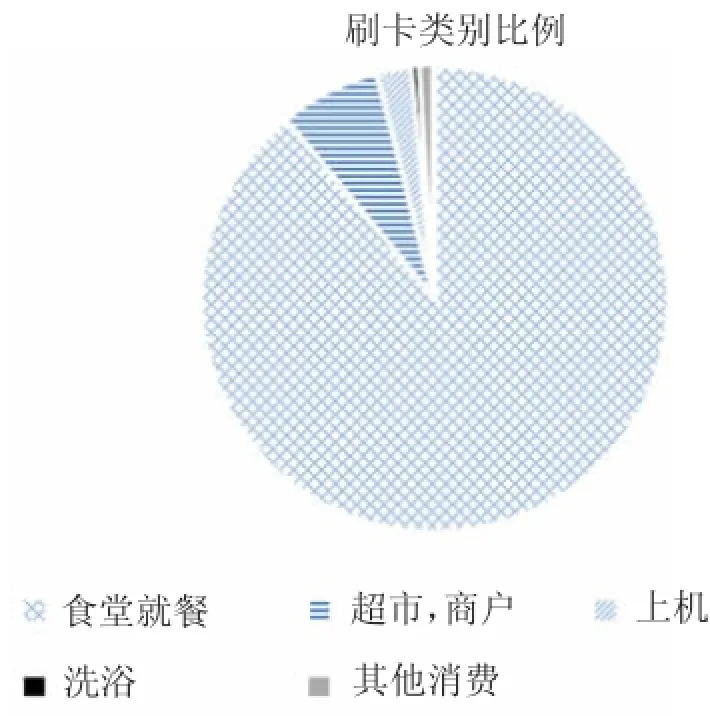
图3 各类刷卡信息比例饼图
3 就餐数据分析
3.1 贫困生预测
由于食堂饭菜相对校外较便宜,通过分析学生就餐刷卡次数、消费金额等数据,可以在一定程度上为贫困生的评选提供参考[3].分别从学生的刷卡次数、平均每次刷卡金额、消费总金额3个角度进行考察,限制条件如下:学期刷卡总次数高于350次、平均每次刷卡额低于2元、消费总金额低于1 000元.经统计汇总得出了在食堂就餐次数较多但消费金额较少的部分学生信息,如图5所示.
3.2 售饭口刷卡次数统计
食堂售饭口刷卡次数可以反映其饭菜质量、性价比等信息,对食堂所有售饭口刷卡次数进行统计排序,分别列出前后10名信息,如图6所示.通过图6可以看出,前10位售饭口都接近或超过5万次,其中以第2食堂第6档口遥遥领先,接近30万次,可见其火爆程度;后10位售饭口刷卡数都在8千次以下,最少的为土豆粉30号档口,不足千次.基于以上统计数据,说明部分售饭口的饭菜口味或价格等得不到学生的认同,导致就餐人数较少.
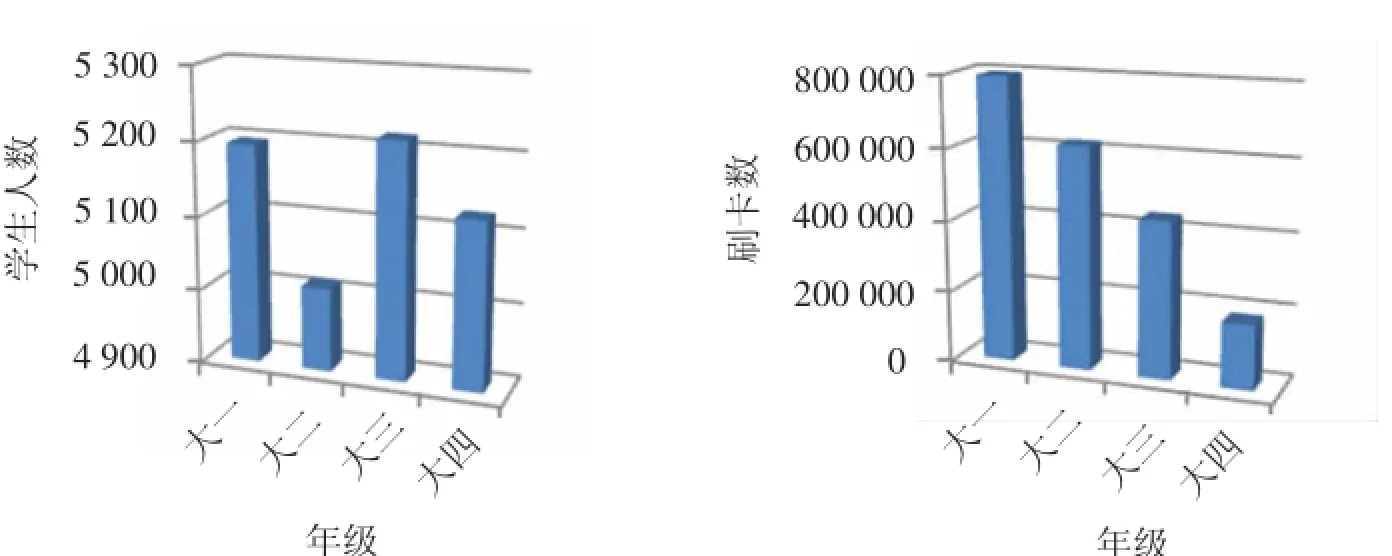
图4 各年级学生人数与刷卡数对比

图5 贫困生预测部分数据截图
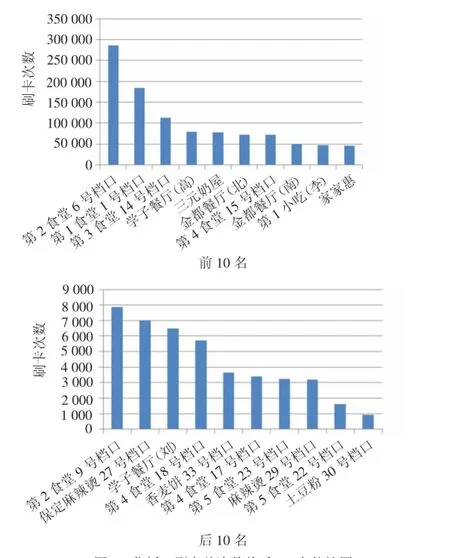
图6 售饭口刷卡总次数前后10名统计图
3.3 就餐时间分布统计
为了考察学生早、中、晚三餐时间分布,以小时为单位进行统计,生成就餐时间分布图见图7,由图7可以看出,三餐刷卡总次数大致相同,介于40-50万之间,三餐刷卡峰值区间分别为7-8点、11-13点、17-20点,早餐时间相对比较集中,午餐和晚餐呈分散趋势.图中8点至10点之间还有将近20万次的刷卡量,说明部分学生没有第一节课或者迟到,就餐较晚.
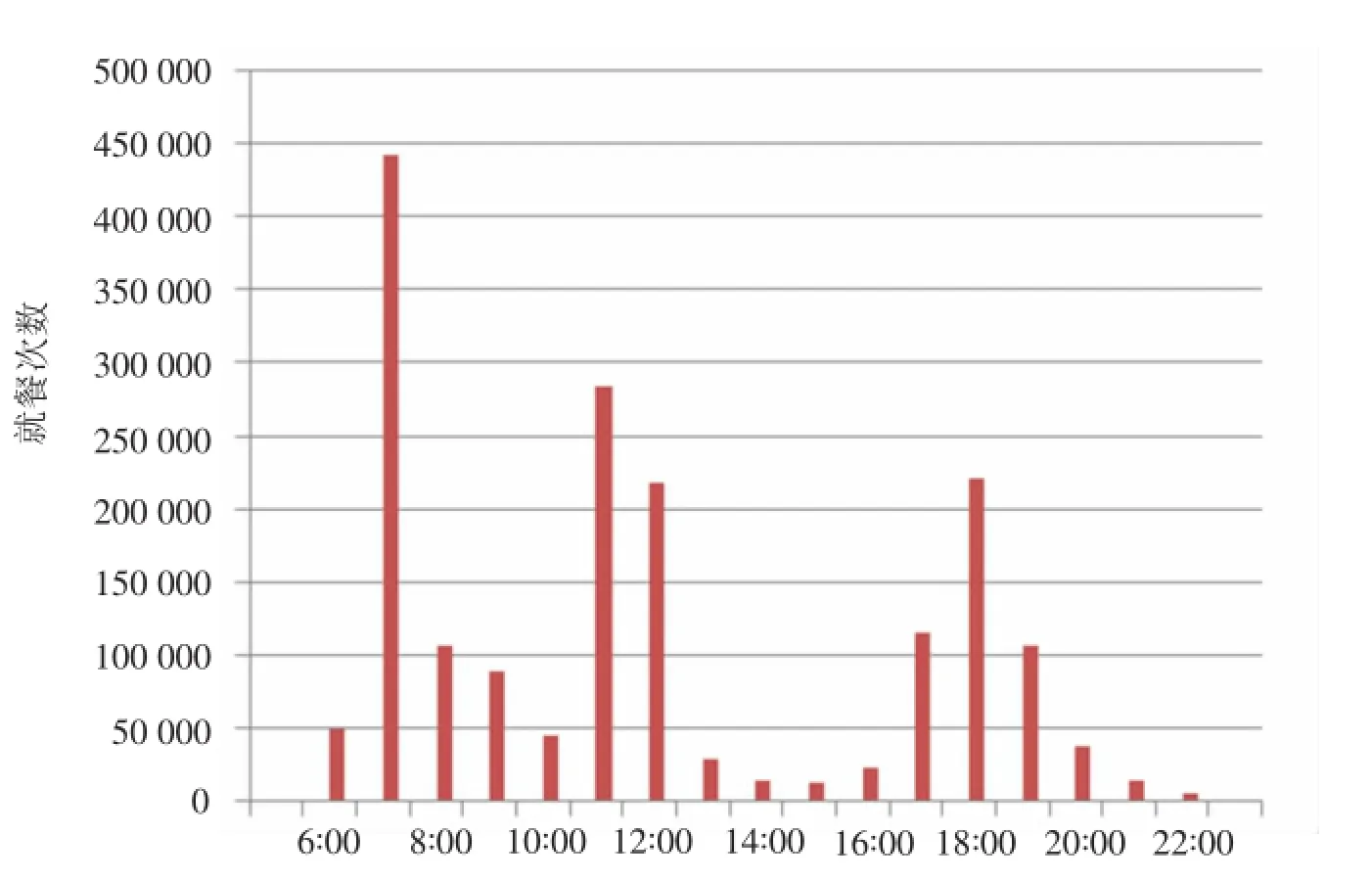
图7 在校生就餐次数分布
4 就餐习惯与学习成绩关联分析
本节考察学生就餐习惯与其学习成绩之间的关联程度,采用关联规则中常用的两个参数支持度和置信度[4],定义如下:
支持度:P(A∪B),即A和B这两个项集在事务集D中同时出现的概率.
置信度:P(B|A),即在出现项集A的事务集D中,项集B也同时出现的概率.
经调研发现,北校区学生校内就餐比例高于南校区,因此,选取北校区某专业共70名学生的就餐信息进行分析.
就餐习惯参数设定[5]:参数1:早餐总次数;参数2:及时就餐数(早7∶40之前就餐);参数3:本学期平均每次刷卡额;参数4:日刷卡数在3次以上的天数.
学生成绩参数设定:由于采用学分制,每个学生所修课程数不同,所以学生成绩采用平均学分绩点按公式(1)计算结果进行考核,按分数高低设为优、良、中、差4个等级.

本研究采用数据挖掘软件RapidMiner Studio 6.5,该软件具有拖拽操作、无需编程、运算速度快、开源等优点,挖掘流程如图8所示.

图8 RapidMiner关联规则挖掘流程图
Retrieve过程:从数据库中获取待挖掘的数据集,输出到Preprocessing过程.
Preprocessing过程:对输入的数据集进行预处理,将数据集划分为若干个子数据集,降低了数据集的复杂性,使其便于管理、理解和修改.
FPGrowth过程:采用被称作FP-growth,又称为FP-增长算法来高效发现频繁项集.
AssociationRuleGenerator过程:根据输入的频繁项集生成有效的关联规则.
将学生就餐-成绩数据集应用到以上挖掘流程,得出如下关联规则,如图9所示.图9中每个参数值按学生人数平均划分为5个取值范围,形式为:参数值=rangeX[a-b],即参数值介于区间[a,b].选取Confidence(置信度)>0.889以上的关联规则.
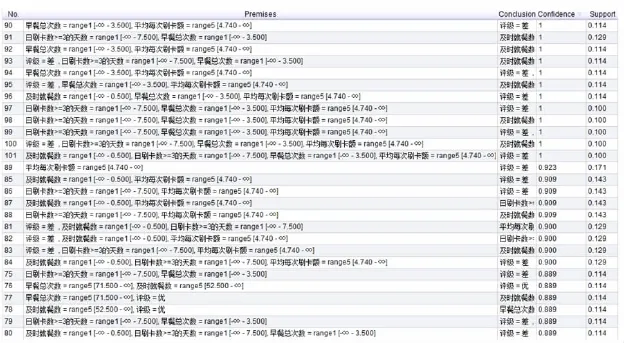
图9 学生就餐数据集挖掘结果
1)由前提(101)可推出评级“差”的置信度为1.
即“及时就餐数”在(-∞,0.5],“日刷卡数在3次以上的天数”在(-∞,7.5],“早餐总次数”在(-∞,3.5],“平均每次刷卡额”在[4.740,∞)区间的学生,成绩评级为“差”的概率为100%.
2)由前提(76)可推出评级“优”的置信度为0.889.
即“早餐总次数”在[71.5,∞),“及时就餐数”在[52.5,∞)区间的学生,成绩评级为“优”的概率为88.9%.
通过以上分析,可以得出学生的学习成绩和早餐习惯之间存在一定的关系:早餐次数多并且及时就餐的学生,其成绩相对较好(置信度为88.9%);相反,早餐次数少、不及时就餐、每次刷卡额偏高的学生其成绩评级为差的可能性偏高(置信度最多为100%),反映了差等生的成绩与就餐习惯之间的关联程度更高.图9的Support(支持度)偏低,说明虽然优等生和差等生的成绩和就餐习惯关联程度高,但该部分学生所占比例并不高.图10为学生就餐与成绩对照图,为了便于对比,在不影响总体排名情况下,采用总学分绩点代替平均学分绩点,由图中可以看出:成绩中等的学生早餐次数和及时就餐数都存在较大的起伏,所占比例达到70%.
5 合理化建议
根据以上对一卡通刷卡信息进行了初步的统计、挖掘分析,现给出相应建议:
1)由于刷卡量中就餐消费占比很大,可根据实际情况适当增加一卡通充值点,丰富一卡通充值渠道,保证一卡通的高效使用.
2)对于刷卡量较少的售饭点,可调查实际情况,建议改进饭菜质量、丰富饭菜口味等,以提高饮食服务的满意度.
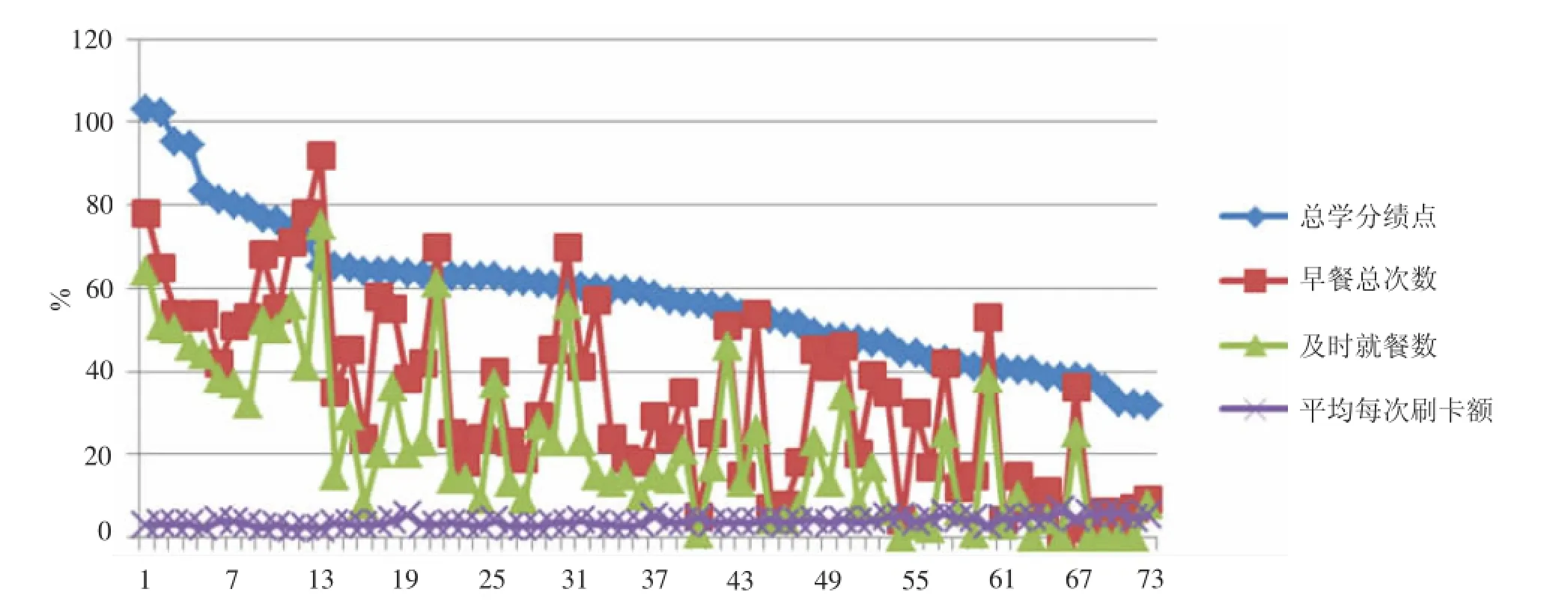
图10 学生就餐与成绩对照图
3)对不在正常时间段就餐的学生(比如上午8-10点之间的刷卡信息),可根据课表进行比对,从侧面反映其出勤率情况.
4)鉴于学生成绩与其就餐习惯之间的强关联性,除了要对早餐的重要性进行宣传外,还要适当增加早餐的饭菜种类、适当降低饭菜价格等,吸引更多学生及时就餐,提高学生的饮食规律性.
6 总结与展望
随着一卡通系统在石家庄学院的深入使用,未来会有越来越多的相关数据进入系统后台数据库,比如上机上网、医院诊疗、洗澡、理发等消费类数据;图书借阅、门禁出入、学生考勤等管理类数据,基于这些数据可以进行多角度、深层次的大数据分析,开发相应的数据分析与预警系统,为学校的科学管理与决策提供支持.最后,在进行大数据处理的过程中,要做好相关的身份认证、权限分级、网络隔离、数据备份等防护工作,以保证数据的安全性.
[1]TANPN,STEINBACHM,KUMARV.数据挖掘导论[M].北京:人民邮电出版社,2012:27-38.
[2]徐剑.基于一卡通数据的消费行为与成绩的关联性研究分析[D].南昌:南昌大学,2010.
[3]宋德昌.基于校园卡的学生经济状况评价方法研究[J].中山大学学报(自然科学版),2009,48(3),9-11.
[4]吴绍函,余昭平.数据挖掘中关联规则的研究[J].微计算机信息,2008,1(3),185-186.
[5]张林红,刘红梅.基于一卡通数据分析的学生早餐习惯与成绩关联规则挖掘[J].阜阳师范学院学报(自然科学版),2014,31(4),92-95.
(责任编辑王颖莉)
A Research on Application of Digital Campus Card Data Based on Data Mining
FENG Jiu1,LI Jun-ling1,ZHANG Hai-xia1,GUO Peng2,ZHAO Feng1,XIE Tong1
(1.Information Center;2.Library,Shijiazhuang University,Shijiazhuang,Hebei 050035,China)
Based on the overall use of the school card,the paper makes a statistical analysis of the student dining consumption data,and has a detailed understanding of the law of student dining behavior.Then,it discusses the relationship of dining data and academic performance of selected students.The study of the card data would provide decision support for school decision makers and relevant management departments.
one card solution;data mining;correlation analysis
TP393
A
1673-1972(2017)03-0053-06
2016-12-22
石家庄学院科研启动基金(16YB015)
冯玖(1982-),男,河北辛集人,工程师,主要从事数据挖掘、数据分析研究.
猜你喜欢
核科学与工程(2021年4期)2022-01-12
计算机应用(2018年5期)2018-07-25
电子制作(2016年19期)2016-08-24
中国交通信息化(2016年3期)2016-06-05
小学生·新读写(2016年5期)2016-05-14
新高考·高一物理(2015年5期)2015-08-18
轴承(2015年2期)2015-07-25
中国卫生(2014年2期)2014-11-12
奥秘(2014年8期)2014-08-30
电讯技术(2011年11期)2011-04-02
