
基于无指导学习的微博评论分析方法
2017-06-01 11:29:47徐帅帅戴新宇黄书剑陈家骏
中文信息学报 2017年2期
徐帅帅,戴新宇,黄书剑,陈家骏
(南京大学 计算机软件新技术国家重点实验室,江苏 南京 210023)
基于无指导学习的微博评论分析方法
徐帅帅,戴新宇,黄书剑,陈家骏
(南京大学 计算机软件新技术国家重点实验室,江苏 南京 210023)
该文以一种有效的方法寻找出有价值的微博评论,这对于读者更高效地阅读评论,为舆情分析、文本挖掘等任务提供支持,均具有重要的应用价值。针对微博及其评论文本短小、内容发散等特点,该文提出一种基于无指导学习的微博评论分析方法,该方法通过互联网搜索引擎扩展微博文本,基于相关性计算自动构造正负训练用例,生成特定的某条微博评论分类模型,通过该模型对评论的价值性进行评估。实验结果表明,该方法能够比较好地识别出评论的价值。
微博评论;价值性;无指导学习;评论过滤
1 引言
随着互联网的普及与发展,社交媒体已经成为我们平时获取信息、与他人沟通交流的重要方式。作为社交媒体中广受大家关注的媒介——微博,更是很多公共媒体、政府机构、公司企业和社会名人发布消息、市场营销、讨论时事的重要场所。微博是一个充满活力的动态媒体,每一刻都有大量反映社会热点、民生百态的微博产生;伴随着微博的发布,海量的评论也随即产生,有的热门微博一天之内就有几千甚至上万条评论产生。
大家在关注微博的同时,发现热门微博的评论也包含了大量的有用信息。这些评论反映了大众对于热点事件的看法、评价;通过这些评论,能了解民意、民情。因此,这些评论无论对于政府进行舆情分析,还是对于商业公司进行市场调研,都有巨大的分析价值。
但是微博及其评论的发布具有很强的随意性,它们的内容具有短小、发散性强、话题广泛等特点。而且它们所包含的内容在质量上良莠不齐,还夹杂着大量的无关信息。因此,有效地筛选微博评论中的内容,提取出有价值的评论,以供进一步的舆情分析、文本挖掘使用,就显得很有必要。
据我们所知,目前还鲜有学者对微博的评论进行过深入的研究。针对这一现状,本文参考了网络短文本挖掘的相关工作,借鉴了他们的相关经验,研究了微博评论的价值性识别问题。本文提出了一种基于无指导学习的微博评论分析方法,{这种方法能够过滤微博的评论,并提取出最有阅读、参考价值的评论。这些高价值的评论,可以为进一步的舆情分析、文本挖掘提供高质量的数据;或者直接呈现给微博用户,方便他们从大量评论中直接阅读有价值部分。
2 网络短文本挖掘相关研究
微博的评论功能,是指用户可以对任何一条微博进行评论,以发表自己的看法、观点。这曾是中文微博基于中国用户习惯而设置的特殊功能,后来Yahoo Meme和Google Buzz等也都增加了评论功能。最大的英文微博网站Twitter,是没有单纯针对微博的评论功能的,但用户可以把自己喜欢的内容转发到自己的微博,转发时可以附加上自己的评论。目前,针对微博评论进行的识别分析工作还很少,所以我们借鉴了网络短文本挖掘工作中关于社交媒体和电商网站相关内容的分类和识别工作。下面我们对这两块内容做简要介绍。
2.1 社交媒体文本分类与识别问题
社交媒体文本分类与识别问题中,具有代表性的问题包括: 微博话题分类、垃圾微博识别、问答类网站中高质量回答识别等。针对这些问题,现有解决办法的总体思路是: 利用机器学习的方法,将需要解决的具体问题抽象成分类问题;针对短文本内容的特点,寻找有效的特征集;人工标注数据或利用网站已有的打分机制,构造好数据集;使用合适的分类器,训练出表现良好的分类器;利用训练好的分类器解决问题。
在微博话题分类问题上,Sriram等人[1]摒弃了传统的BOW特征模型,选取一个名词性特征和七个二元特征(存在性特征),使用人工标注的数据,训练分类器,并取得了不错的实验效果。
在垃圾微博识别问题上,Liu等人[2]从微博的词汇特征、状态特征、用户特征三个角度选取了若干特征,人工标注了1 979条垃圾微博作为训练数据,并使用了朴素贝叶斯、支持向量机、逻辑回归三种分类器做了对比实验。实验结果显示,整体的识别错误率都比较低,其中支持向量机取得了最好的效果。
在问答类网站中高质量回答识别问题上,Agichtein等人[3]以问题和答案文本为中心,结合提问者和回答者相关的提问、回答历史信息,为每个问题和答案构造特征向量;通过人工阅读提问和回答,标注出一定数量的高质量问答;训练分类器,并进行分类识别。
2.2 电商网站评论分类和识别问题
总的说来,电商网站评论分类和识别问题,还是使用机器学习的方法,转化为文本分类问题来处理的。需要完成的核心任务有三个: ①针对需要分类的评论数据集,寻找合适的训练数据; ②寻找有效的特征; ③使用有效的分类器。具体过程中,针对特定的评论数据集,衍生出具有各自特点的处理方法。
现有的处理方法主要有两类: 一类是直接针对评论文本本身进行识别;另一类是先查找垃圾评论发布者,然后再将他们的评论认定为垃圾评论。
第一类方法[4-7]中,有的利用评论文本和其对应的评论者、被评论商品等相关信息来构造特征向量;有的利用了心理语言学特征来构造特征向量,通过人工标注、众包等手段人工生成,或采取其他办法获取训练数据;最后训练分类器并完成分类工作。
第二类方法[8-10]中,是通过寻找一定的行为模式,将这些行为模式抽象成特征向量,通过发现垃圾评论发布者的特殊行为和异常举动,从而确定垃圾评论发布者,并最终找到他们发布的垃圾评论。
3 中文微博评论数据分析
本文选取了在中国拥有最多用户数的新浪微博作为研究对象,爬取了“认证用户”人民日报在2013年4月21日至5月3日期间发布的微博及其评论作为实验数据。作为人民日报的官方微博,它具有相当大的影响力,发表的微博都是真实可靠的信息,对它所发表微博的评论往往也比较多。使用它的数据,帮我们排除了垃圾微博的影响;同时它发表的微博评论中,包含了大众的想法和观点,分析这些评论对于进一步的舆情分析、观点挖掘等工作具有很高的价值。
3.1 实验数据总体介绍
我们通过人工,随机选择性地阅读了一部分微博及其评论,并通过程序对这些微博和评论文本进行了一些统计和分析。我们发现微博评论有其自身的一些特点:
(1) 大多比较短小,一般为10~50个汉字;
(2) 具有很强的发散性,文字的表达形式很多样;
(3) 包含大量的网络新生词汇;
(4) 除了中文,还夹杂着不少英文字母、符号、数字等字符。
3.2 评论价值性定义
Jindal等人[4-6]在研究电商的垃圾评论识别时,将垃圾评论分为三类: 虚假评论、只针对某品牌的评论、没有评价内容的评论,他们的这一分类被许多后来研究商品评论的学者所认同。但这一分类很难适用于微博的垃圾评论识别中。
电商网站中的商品评论针对的是某个具体的商品,因此针对这个商品的各方面特征和使用情况的真实陈述才是有用的评论,其他的评论都可以认为是垃圾评论。微博评论则有很大的不同: 在微博本身就具有很强随意性的情况下,它的评论具有很强的发散性,可以是针对微博的一段评价,或讲述评论用户遇到的类似事情,或由这条微博联想到的其他事情;有的评论用户还通过评论与微博作者或其他评论者交流。
结合微博评论的特点,我们认为,对于微博评论价值性的定义,应该从文本相关性的角度来判断。关于文本的“相关性”,赵玉茗[11]在她的博士论文中做了详细的分析。参考了赵玉茗的研究成果,再结合微博评论的特点,我们认为: 评判微博与其评论相关性的标准,应该是以我们大多数人的知识储备为基础的,从语义、信息角度来看,微博与其评论所描述的抽象概念是否有重合的地方: 如果有,就是相关的;如果没有,就是不相关的。从评论价值的大小来说,如果抽象概念重合的地方比较多,那么这条评论的价值就大;如果重合的地方比较少,那么这条评论的价值就小。最终的评判标准,应该是以人的判断结果为依据。
从人的主观角度来讲,我们阅读到的微博评论,有的用几个字表达自己的喜怒哀乐,有的爆个粗口,有的发布一个简单的表情,有的很认真地写出几十上百个字详细地表达评论者的看法,很显然,最后一种评论要比前几种评论的参考、阅读价值大得多。
本文的研究目的,就是找出与微博内容不相关的垃圾评论;在剩下的评论中,对评论的价值进行打分,价值大的评论得分就高,价值小的评论得分就低。
3.3 实验数据中评论价值性的分布情况
为了了解实验数据中评论价值性的分布情况,我们请了三位与本文工作无关的同学,对评论进行了人工阅读,并标注出所阅读评论的价值大小。根据微博评论数目的分布情况,我们选取了五条微博作为代表,它们具有的评论数目分别是299、1 393、3 984、6 518、14 864。对于每条微博,从它的评论中随机抽取出200条评论。
每位同学在阅读完微博及其200条抽取出的评论后,需要给每条评论一个打分,分值有四种: 0分、1分、2分、3分,打分的原则如下:
(1) 0分: 评论与微博内容无关(例如广告),只是单纯转发,只是单纯@某人,只有一串无意义的字符等;
(2) 1分: 评论与微博内容相关,但评论内容很简单,包含的有效信息量很少,例如只有一两个词组,或一个简短的句子;
(3) 2分: 评论与微博内容相关,具有比较完整的语句,比较完整地表达了自己的观点或叙述了相关的事情;
(4) 3分: 评论与微博内容相关性很强,详细表达了自己的观点或看法,或者给出了建议,或者谈了相关的一些事情。
我们将三位同学对同一条评论的打分相加,因此每一条评论的打分从0分至9分不等,共有10个等级: 分数越高,意味着该评论的价值越大;如果分数为0,说明三人一致认为这条评论是与微博内容无关的垃圾评论。五条微博评论的价值性分布如图1所示(图中的5条线,分别代表了拥有299、1 393、3 984、6 518、14 864条评论的微博)。
从图1中可以看出:
(1) 不同微博,它的评论价值性分布是不尽相同的,没有一个统一的分布形态;
(2) 垃圾评论是广泛存在的,不论哪一条微博,都有相当数目的垃圾评论;
(3) 每条微博都有一定数量的高价值性评论,对于得分大于等于7的评论,说明至少有一个人认为该评论是具有高价值的,我们把这样的评论认为是高价值的评论。

图1 5条微博评论的价值性分布
4 基于无指导学习的微博评论分析方法
针对微博评论的相关特点,本文提出了一种无指导学习的微博评论分析方法,将微博垃圾评论的识别和对评论价值的评估放在一起完成。
总体的思路是: 将识别问题抽象成分类学习问题;采用合适的方法,自动寻找出高质量的训练用例;针对具体微博生成专属于该微博的评论分类模型,通过该模型对评论的价值性进行评估,剔除出垃圾评论,并对其余评论的价值打分。
具体的步骤分为四步,下面我们分别介绍这些步骤中的关键技术。
4.1 微博文本的扩展
每条微博及其评论的字数都被限制在140字以内,它们都属于短文本。与传统的文本不同,短文本因为其字数少,在缺少足够上下文信息的环境中往往容易引起歧义;在为其构造特征向量时,都非常稀疏。所以,那些对于传统文本分类问题能够取得不错效果的机器学习和文本挖掘算法,在处理短文本问题时,往往就不太适用[12-13]。
基于短文本的特点,很多学者做了相关研究,总的说来,针对短文本分类的解决办法,都是寻找合适的方法来扩展和丰富短文本的表达,以达到增加短文本信息量的目的。
本文在处理微博及其评论的时候,需要比较每条评论与其微博的相关性有多大。我们一样也面临着怎样合理、有效地丰富短文本表达的问题。针对微博及其评论具有的随意性、发散性、含有大量网络新生词汇和新兴表达方式等特点。我们提出了利用互联网中搜索引擎的帮助,来扩充微博文本表达的办法。具体做法如下:
(1) 对微博文本进行分词,提取出其中的名词;
(2) 将这些名词两两组合作为关键词,在搜索引擎中搜索,得到网页摘要,我们实验中只取了前100条摘要;
(3) 对这些网页摘要进行分词,并提取出名词;
(4) 将第(1)步和第(3)步中的名词放在一起,作为对微博文本的扩充。
需要说明的是,我们只对微博文本进行扩充,而对每条评论不进行扩充。我们的目的,是确定一条评论与微博是否相关,以及相关度有多大;微博是中心,评论是围绕微博涉及的概念与话题而存在和展开的。因为微博最多只能有140字,在这么少的文字里,只单纯依靠其词汇层面的文本来与具有相当大发散性的评论进行相关性比较,不能得到很好的结果,所以需要对微博文本进行扩充。
4.2 特征向量的构造
我们的工作核心,是找出微博与其评论在概念和话题层面的相关性,语法结构层面和词汇形态层面的相似性相对显得不是那么重要。所以,我们关注的重点是微博与其评论文本中所包含的有实际意义的词组。鉴于此,我们为微博及其评论构造特征向量时,决定使用向量空间模型。向量中每一维度的值反映了相应词语在文档中的重要性,本文采用了TF-IDF模型计算每个词语的权重。
4.3 训练用例的自动选取
针对微博评论识别问题,如果能够通过人工去阅读所有的评论,先标注出跟微博内容不相关的垃圾评论,再从剩下的评论中找出高价值的评论,这样得到的训练数据质量是最高的。但在现实中,这将耗费巨大的时间和精力,同时有限的人手也不可能将浩如烟海的所有微博及其评论都阅读一遍。
如果有一个办法,不需要人工的参与,就能自动将质量最好的数据抽取出来,也就是将价值最大的评论和价值最小的评论抽取出来,用它们作为训练用例来训练分类器,那么将会取得不错的效果。我们在本文提出的方法,就是希望做到这一点。
通过对评论数据的仔细观察,我们发现高质量评论和垃圾评论有一些很明显的特征:
(1) 高质量评论: 出现的名词与微博所包含的话题和概念有很强的相关性,所包含的字数往往也比较多。
(2) 垃圾评论: 主要有两种情况,一种就是字数很少,或者仅仅是一个转发、一个@“某人”;另一种是字数很多,但内容完全就是跟微博无关的广告、求关注,或其他杂乱的文字。
总的说来,我们发现: 与微博越相关的评论,它的价值性往往越大;与微博越不相关的评论,它的价值性往往越小。针对这些特点,我们认为,通过比较评论与微博的相关性,那些最相关和最不相关的评论,就是我们想寻找的高质量训练用例。
本文的做法是: 将每条评论与扩展后的微博进行相关性的比较,根据相关性的大小对评论进行排序;将排在最前面的n条评论和排在最后面的n条评论分别作为训练用例的正负例(n的取值根据实验中具体的评论数目来定)。利用这些高质量的训练用例,训练出分类器后,再对评论进行预测分类。
在比较评论与扩展后微博相关性的问题上,我们使用了赵玉茗[11]在她论文中提到的“系统相似性模型(system similarity model,SSM)”,并做了简单改造。
对于两个句子A与B,在向量空间模型中,它们的向量表示分别为:
语句A=(x1,x2,…,xm),m=|A|;语句B=(y1,y2,…,yn),n=|B|。
它们的系统相似性计算公式为式(1)。
(1)
其中,对于语句A中的词xi,在语句B中存在与其有最大相似度的词yj,这两个词之间的相似度,就是μi。为了排除两个词之间相似度过小时对语句相似性的干扰,我们设置了一个阈值μ0,将相似度小于该阈值的词语对剔除。对于词语之间相似度的计算,我们采用了基于知网的语义相似度计算方法。
4.4 垃圾评论识别与评论价值评估
为了完成垃圾评论识别与评论价值评估这两个任务,我们采用了逻辑回归分类器。逻辑回归(logistic regression)是当前比较常用的一种机器学习方法,具有求解速度快、应用方便等特点。
我们选择逻辑回归分类器的原因在于: 该模型可以用于估计某种事件发生的可能性大小,而不仅仅只是单纯地分类。我们可以用逻辑回归计算出的概率值对应地表示评论价值的大小。
5 实验与结果分析
5.1 实验数据与评价指标
本文的实验数据,就是上文分析评论价值性分布情况时使用的五条微博及其评论。对于每条微博,将人工标注的200条评论作为测试用例。对于得分为0的评论,说明三人一致认为这条评论是与微博内容无关的,所以将这样的评论认定为垃圾评论;对于其余的评论,得分越高说明该评论的价值性越大。
为了有所比较,除了本文提出的方法,即基于微博扩展的无指导学习评论价值分析(microblog extension based unsupervised comment analysis,MUCA),我们还做了两组对比实验:
(1) 在选择训练用例时,从每条微博的评论中随机抽取若干评论,使用人工的方法进行评判,之后的训练、测试流程与本文提出的方法一样,为了方便,我们将该方法简称为MNTD(manual notate training data);
(2) 对微博内容不进行扩展,其他的训练用例寻找、分类器训练、测试方法与本文提出的方法一样。
在对微博内容不进行扩展的对比实验中我们发现,因为微博本身文本的内容太短小,所以当它的评论与其进行相关性比较时,几乎所有的评论与其相关性都为0,所以接下来自动寻找训练用例的工作就根本无法进行下去。
这个结果也证明了,在比较微博与其评论这类短文本之间的相关性时,对微博短文本进行扩展的必要性。所以我们的实验结果对比,在本文提出的方法与人工寻找训练用例的方法之间进行。
对于人工寻找训练用例的方法,我们需要额外给它标注训练用例,我们请了一位与本文工作无关的同学(该同学不在上文中标注评论价值性的同学之列)来标注训练用例。具体标注训练用例的个数,与MUCA自动选取的训练用例个数一致。
在介绍训练用例的自动获取时,我们需要分别提取相关性排名最前和最后的评论作为正负例。这里,我们分别提取了排名分别在最前和最后的15%、10%、5%、2.5%、0.5%的评论,得到了五组实验结果。
人工标注数据是非常耗时、耗精力的一件事,对于拥有14 864条评论的微博,如果标注其30%的评论,需要标注4 440条评论,工作量太大,所以我们只人工标注了一部分的评论,来做对比实验。人工标注的评论数目统计表如表1所示(未标注的数据用井号示意,下同)。
在垃圾评论识别方面,我们使用了准确率作为评价指标;在评论价值识别方面,我们使用了NDCG作为评价指标。
NDCG是信息检索领域里对于排序结果进行评判的常用指标,是对DCG的一种归一化处理。它的思想就是: 排序的结果列表中,价值越大的评论出现在越靠前,排序的效果就越好。DCG的计算公式如式(2)所示。
(2)
其中,reli是第i位评论的得分;不同位置处的评论,其重要性是不一样的,所以给其赋予了相应的权重,对于rel1,因为log21=0,不能将其作为分母,所以我们单独将其列在最前面。
NDCG是对DCG的一种归一化处理,使得NDCG的结果介于0和1之间,便于比较。其计算公式为式(3)。
(3)
IDCG(ideal DCG)是最理想排序情况下的DCG值,是将最理想的排序结果,使用DCG的计算公式算得的一个数值。
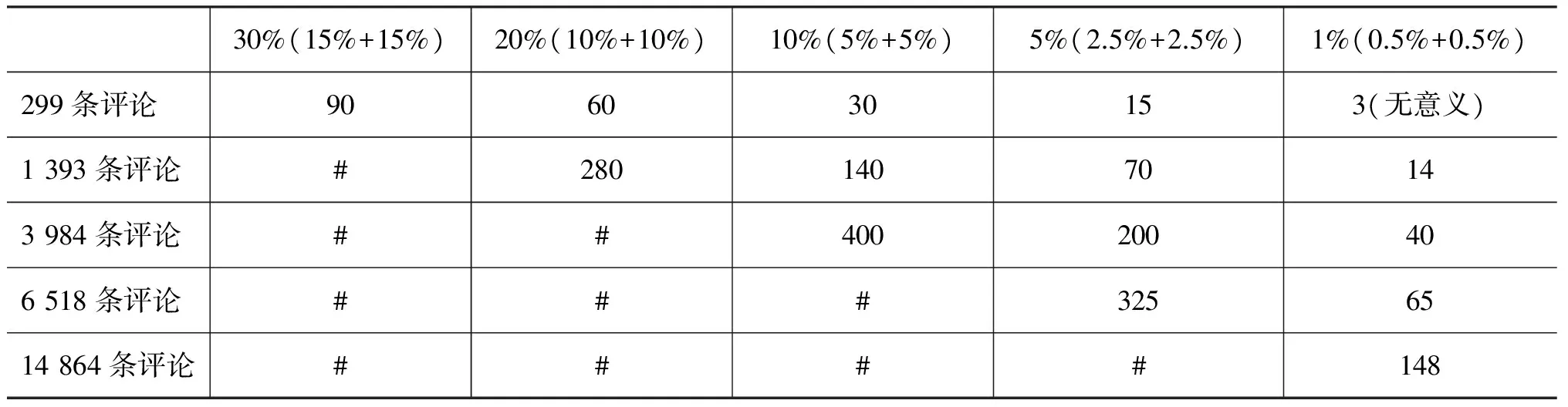
表1 人工标注的评论数目统计表
5.2 垃圾评论识别结果与分析
垃圾评论识别结果如表2所示(其中微博1~5,分别代表了拥有299、1 393、3 984、6 518、14 864条评论的微博)。
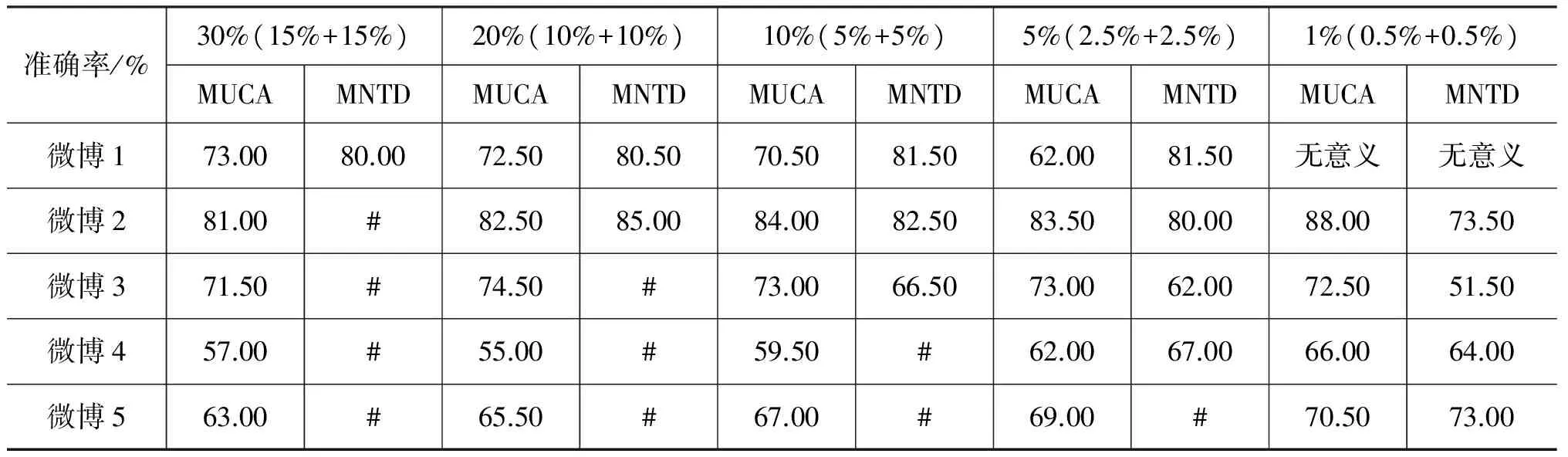
表2 垃圾评论识别结果
从实验结果中,我们可以得出一些结论:
从所有评论中抽取较高比例的评论作为训练用例时,MNTD的效果比MUCA的效果要好。但抽取较低比例的评论作为训练用例时,MUCA的效果较好。这说明,我们的MUCA在自动选择训练用例时,倾向于把质量比较高的正负用例选出来。因为MNTD的训练用例是随机选出的,所以不能够保证选出来用例的质量;但是,当人工标注的训练用例所占比例较大时,人工标注垃圾评论的质量就能够显现出来。
我们发现: 对于有的微博,使用两种方法,垃圾评论识别的效果都还不错;但另一些微博,使用两种方法,识别率都不是很理想。我们仔细阅读了这些微博及其评论,发现这跟微博评论的整体价值性有关。对于有6 518条评论的微博,它的评论中本身有价值的评论就不多;而拥有1 393条评论的微博,它的评论中有很多较有实质内容和参考价值的评论。这说明,如果该微博的所有评论里,有价值的评论越多,那么在寻找垃圾评论时,就越容易找准。
5.3 评论价值识别结果与分析
评论价值识别结果如表3所示(其中微博1~5,分别代表了拥有299、1 393、3 984、6 518、14 864条评论的微博)。
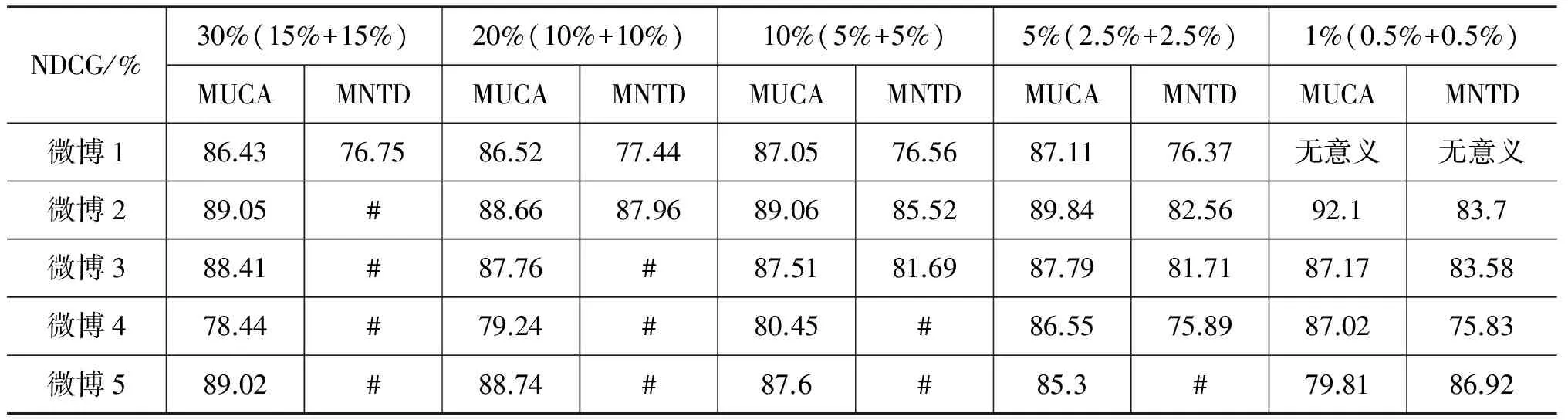
表3 评论价值识别结果
从实验结果中,我们可以得出一些结论:
总的说来,在对评论价值性的评估上,MUCA比MNTD效果要好。
不同的微博,其评论的整体价值性会有差别,如果评论价值整体较高,排序效果会好些;如果评论价值整体较低,排序效果会差些。对于评论价值性的排序任务来说,本文MUCA方法的整体性能还是比较稳定的。这也说明,使用本文的MUCA方法,能够较好地对微博评论的价值性进行排序。
6 结论
本文通过对微博评论数据的统计与分析,提出了基于无指导学习的微博评论分析方法。首先,利用互联网对微博文本进行扩展;然后,通过比较评论与扩展后微博的相似性,提取出相似性较大和较小的评论作为训练用例;最后,训练出逻辑回归分类器,并对评论价值性进行预测。该方法可以在无人工参与的情况下,针对每条微博训练出专属于该微博的评论识别分类器,利用该分类器识别出垃圾评论和评论的价值性。实验结果表明,该方法可以有效地识别出垃圾评论和评论的价值性。
在对每条评论构造特征向量时,因其内容短小,所以构造出的特征向量极其稀疏。如何更好地构造特征向量,以反映评论的价值性,是我们下一步工作的方向。另一方面,我们也在考虑如何更好地应用现有的技术手段,进行特征提取,从而找出对解决问题最重要的特征。
[1] Sriram B, Fuhry D, Demir E, et al. Short text classification in twitter to improve information filtering. [C]//Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2010, 841-842.
[2] Liu L, Jia K. Detecting spam in chinese microblogs-a study on sina weibo. [C]//Proceedings of the Computational Intelligence and Security (CIS), 2012 Eighth International Conference. IEEE, 2012, 578-581.
[3] Agichtein E, Castillo C, Donato D, et al. Finding high-quality content in social media. [C]//Proceedings of the 2008 International Conference on Web Search and Data Mining. ACM, 2008, 183-194.
[4] Jindal N, Liu B. Opinion spam and analysis. [C]//Proceedings of the 2008 International Conference on Web Search and Data Mining. ACM, 2008, 219-230.
[5] Jindal N, Liu B. Review spam detection. [C]//Proceedings of the 16th international conference on World Wide Web. ACM, 2007, 1189-1190.
[6] Jindal N, Liu B. Analyzing and detecting review spam. [C]//Proceedings of 7th IEEE International Conference on. IEEE, 2007, 547-552.
[7] Ott M, Choi Y, Cardie C, Hancock J T. Finding deceptive opinion spam by any stretch of the imagination. [C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics. 2011, 1: 309-319.
[8] Mukherjee A, Liu B, Wang J, et al. Detecting group review spam. [C]//Proceedings of the 20th international conference companion on World Wide Web. ACM, 2011, 93-94.
[9] Mukherjee A, Liu B, Glance N. Spotting fake reviewer groups in consumer reviews. [C]//Proceedings of the 21st international conference on World Wide Web. ACM, 2012, 191-200.
[10] Lim E P, Nguyen V A, Jindal N, et al. Detecting product review spammers using rating behaviors. [C]//Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, 2010, 939-948.
[11] 赵玉茗. 文本间语义相关性计算及其应用研究[D]. 哈尔滨工业大学博士学位论文, 2009.
[12] Healy M, Delany S J, Zamolotskikh A. An assessment of case base reasoning for short text message classification. [C]//Proceedings of the 16th Irish Lonference on Artifical Intelligence & Coguitive Science (AICI’05), 2005: 257-266.
[13] Chen M, Jin X, Shen D. Short text classification improved by learning multi-granularity topics. [C]//Proceedings of the Twenty-Second international joint conference on Artificial Intelligence. AAAI Press, 2011, 3: 1776-1781.
Unsupervised Microblog Comment Analysis
XU Shuaishuai, DAI Xinyu, HUANG Shujian, CHEN Jiajun
(State Key Laboratory for Novel Software Technology at Nanjing University, Nanjing, Jiangsu 210023, China)
The valuable microblog comments can be supplied to the readers, or be provided to some tasks like public opinion analysis and text mining. To detect such valuable comment, this paper presents an unsupervised comments analysis method. Firstly, we use the search engine to expand the microblog text. Secondly, we use the correlation measure to get the most valuable comments and the most invaluable comments, respectively. Finally, we generate a comment classification model to assess the comment value. The experimental results show our method performs well on the task of valuable comments recognition.
microblog comment; value; unsupervised; comment filter

徐帅帅(1986—),硕士,主要研究领域为自然语言处理。E⁃mail:x_sh_sh@163.com戴新宇(1979—),博士,副教授,主要研究领域为自然语言处理和文本挖掘。E⁃mail:daixinyu@nju.edu.cn黄书剑(1984—),博士,助理研究员,主要研究领域为自然语言处理和机器翻译。E⁃mail:huangshujian@gmail.com
2015-03-19 定稿日期: 2015-04-30
国家自然科学基金(61170181);江苏省自然科学基金(BK2011192);国家社会科学基金(11AZD121)
1003-0077(2017)02-0179-08
文献标识码:
猜你喜欢
科学与信息化(2021年12期)2021-12-27 01:39:02
铁道通信信号(2019年11期)2019-05-21 03:05:46
时代英语·高二(2018年7期)2018-12-03 09:23:06
出土文献与古文字研究(2018年0期)2018-11-04 00:42:00
时代英语·高二(2018年3期)2018-06-06 05:24:36
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电测与仪表(2014年15期)2014-04-04 12:05:20
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
