
基于情感常识的微博事件公众情感趋势预测
2017-06-01 11:29:47任巨伟吴晓芳林鸿飞
中文信息学报 2017年2期
任巨伟,杨 亮,吴晓芳,林 原,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116023)
基于情感常识的微博事件公众情感趋势预测
任巨伟,杨 亮,吴晓芳,林 原,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116023)
微博日益成为一个巨大而复杂的互联网舆论平台。分析微博中特定话题的情感趋势对于了解网络舆情、分析产品销量趋势显得尤为重要。该文使用微博进行真实事件公众情感趋势预测: 首先,考虑到微博特征稀疏、上下文缺失的特性,借助词语上下位语义关系对其进行语义扩充;其次,使用语义特征和情感常识知识构造双层分类方法进行情感分析;最后,对特定事件在连续时间段内的微博使用时序情感分析方法进行公众情感趋势预测。实验证明,该情感分析方法准确率相对于传统分类方法有明显的提高,在此基础上的情感趋势预测符合事件的真实发展状况。
微博;情感分析;语义扩充;情感常识;公众情感趋势
1 引言
微博,作为Web2.0技术下的最新社交网络应用,逐渐成为网民对当前社会现象表达观点的主流平台。众所周知,Twitter是目前国外比较流行的网络微博服务平台。在国内,新浪微博是一个继Twitter之后为人所熟知的中文微博平台,允许用户每次发表少于140字的原创和非原创内容表达自己的观点、心情和实时动态。现实世界中,社会事件的演变,以及随之产生的公众情绪波动会通过一条条微博映射到虚拟世界中。以微博为桥梁,分析微博虚拟世界中的公众情感趋势变化,可以反映人们对于社会现象的真实情绪,甚至预测人们的下一步情绪变化。因此,分析事件在某一连续时间段内的微博情感趋势对于了解网络舆情甚至预测产品销量意义重大。预测某一特定话题的情感趋势包括两个步骤: 情感分析和趋势预测。
传统的情感分析也即倾向性分析,是将文本分为褒、贬、中三种情感,更细粒度的情感分析是指将文本分为“喜”“怒”“哀”“恶”“惧”“惊”“无情感”七大类。目前已经有不少学者专注于产品评论及微博的情感分析研究中。Bo Pang和Bing Liu对当前的情感分析方法通过综述方式进行总结[1-2]。传统的情感分析方法有以下几种: 机器学习方法[3];基于词典的模式匹配方法[2];基于图论中最小割原理的倾向性分析方法[4]。除此之外,Bollen提出使用目前心理学中比较成熟的情绪度量工具(profile of mood states,POMS)将文本分为六大类[5]。机器学习方法例如朴素贝叶斯、最大熵、支持向量机已经被应用于电影评论分析[6]和微博分析领域,其中Alec Go使用基于互信息特征选择技术的贝叶斯分类方法,在Twitter二元褒贬分类方法中[7],其准确率达到了81%,但是该方法在三元分类(褒、贬、中)表现欠佳(准确率只有40%)。在中文微博情感分析领域,谢丽星等人[8]提出了一种基于SVM的三元情感分类方法,结合主题相关和无关特征(比如表情符号、情感词典、情感短语及上下文),使用多层分类模型进行情感倾向性分类,效果良好。而Li等人结合社会网络分析,在使用词典的模式匹配方法的同时,考虑微博中邻居用户(关注和粉丝)的观点倾向性影响,最终确定当前微博的情感倾向性[9]。上述方法关注点在于微博内容本身及相关的元数据信息,但是考虑微博的简短性,不可避免地会造成上下文缺失和特征稀疏,由此造成的歧义为情感分析带来了挑战。一个微博在不同的背景知识下可能显现不同的情感。如: (1)“为期两天的高考开始了……”(2)“2010年世界杯即将开始!”同一时间、区间内,同样是两个事件的开始,第一个微博表达的是悲伤的情感,而第二条却透漏着喜悦。一个合理的解释: 在大众常识知识中,高考通常会给人带来紧张和不快,而世界杯则常常与“欢乐”和“干杯”相伴。因此,结合上下文背景信息进行情感分析显得尤为重要,通过营造微博存在的外部环境帮助读者理解一条微博的真实含义。综上所述,常识知识(e.g. ConceptNet[10])特别是情感常识知识对于辅助微博的情感分析有重要意义。情感趋势预测,特别是倾向性趋势预测,已经广泛应用于股市交易决策[11]、选举预测[12]、票房预测[13]等领域。传统基于文本的预测多使用统计回归模型,例如线性回归、自回归(AR)、移动平均自回归(ARMA),除此之外,分类模型(SVM)也可以应用于预测[14]。
本文通过对新浪微博特定事件的情感分析探索公众情感趋势的变化。首先,针对微博特征稀疏的特点,对微博内容进行上下位语义特征的扩充;其次,将情感常识知识引入到细粒度情感分类中,以提高分类准确率;最后,使用基于时间序列的情感分析方法预测情感趋势走向,以百度指数作为基准,对预测结果进行评价。
文章的组织结构如下: 第二部分介绍微博语义扩充、情感常识的构成以及在极性分析和细粒度情感分析中的使用方法;第三部分介绍基于情感常识库的情感分析技术及实验结果对比;第四部分是基于时间序列的大众情感趋势预测及结果分析;最后一部分为文章结论。
2 情感常识知识的构造及使用方法
目前,比较经典的情感分析问题常常被看作分类问题,使用SVM和Naïve Bayes等分类工具解决。本文借助上下位语义扩展和情感常识知识为微博添加细粒度情感标签;随后使用细粒度情感和极性之间的映射关系进行微博的极性判断。
2.1 微博上下位语义扩充
作为短文本,微博上下文缺失和特征稀疏的特性会影响情感分析的准确性。为弥补这一缺点,本文在外部数据源中挖掘上下位语义关系,对微博进行语义扩充。通过使用当前词的上位词对原有词语进行替代和泛化,达到通过背景知识扩充微博语义的效果。例如“这台宝马X5很酷!”,而通过从外部语料的上下位语义抽取得知“宝马X5”的上位词是“汽车”,于是,该句子就可以泛化为“这台汽车很酷!”,这样将“宝马X5是汽车”这一背景常识加入到微博中,再使用情感常识知识进行情感判断就显得简单。
上下位关系抽取使用的是模式匹配技术[15]。考虑到模式匹配在规范化文本中的效果显著,因此,本文选用百度百科*http://baike.baidu.com/语料作为上下位抽取来源,该语料涵盖了230 000条百科词条及相关的词条解释。模式匹配方法从中抽取了5 300条上下位词对,如表1所示。

表1 上下位词对举例
2.2 情感常识知识构造
常识知识作为背景知识的一种,对短文本理解有重要意义。为了让机器拥有人的知识背景,辅助决策是智能化发展的趋势,因此,常识知识的形式化和构造一直是人工智能领域的一个热门研究话题,其在专家系统和问答系统中扮演着重要的角色[16]。目前,有许多经典的常识知识库,包括WordNet[17]、ConceptNet[18]和HowNet*http://www.keenage.com/html/c_index.html。但是,这些常识知识都与情感无关,无法应用于文本情感分析中。本文在目前已有的二元情感常识库[19]基础上进行规范化,提出了一种更加简单、易扩展的情感常识知识构造方法。该情感常识知识包括三个主要部分: 二元情感常识、情感图式[16]、网络熟语或连续的字符串(如“稀饭”“3Q”“bt”“O(∩_∩)O”)。考虑到使用的方便性和可扩展性,本文用如下形式表示情感常识(CS):CS: (CS_category(CS_content),CS_sentiment)
CS_content: (“w1”, “w2”,”w3”)or
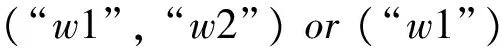

(1)
2.3 情感常识知识在情感分析中的应用
2.3.1 微博细粒度情感分析
对于经过上下位语义扩展后的微博,本文从情感常识知识入手,辅助以情感词典,进行细粒度情感分类(六类)。将每条微博使用一个六维的向量S表示,每一维代表一类情感,每一维的情感得分都由两部分组成: 情感常识知识得分Scs和情感词典得分
(2)
(3) 本文使用模式匹配和统计的方法实现情感计算,这里面要用到情感常识知识的三个组成部分: 二元情感常识知识库、情感图式和网络熟语。考虑到每个部分的表示形式不同,二元情感常识知识库由二元有序对组成,网络熟语为单个词语或者连续的字符串(“O(∩_∩)O”),而情感图式中每个节点都是一个常识条目,常识之间具有上下位语义关系,是一种结构化常识[16]。三种常识类别需要设置三种不同的计算函数。
除了情感常识知识和情感词典(下文统称为“情感标识”),微博中的否定词和转折词在情感分析中也扮演着重要的角色。结合中文的语法习惯,如果否定词修饰情感标识(即在情感标识词所在的滑动窗口中出现),原有的情感标识所表达的情感会有一定的概率发生转移,该转移概率的获取是通过对Yang等人的中文情感语料库[20]统计而来。统计表明,否定词修饰时,“喜”会转移为“恶”,而“惊”“哀”“怒”“惧”“无情感”有较大概率会转移为“无情感”。此外,在中文语法习惯中,转折词的出现多意味着对其后出现内容的强调,如“但是”“然而”,因此本文处理时使用其后出现的情感标识作为情感分析依据。
本文中,微博情感分析以句子为单位,通过标点符号(“。”“?”“!”“;”)将微博划分为长句,之后,使用标点符号(“,”“:”“…”)将每个长句划分为短句。通过短句情感的加和、归一化计算微博整体情感向量值S。短句中,计算一元情感常识知识和情感词典时,第i维的情感(ei)统计得分(NS1(ei))可做如下计算。情感词典是使用的大连理工大学信息检索实验室发布的情感本体[20],包括26 000个带有情感标签的词语。
(4)
其中,Vn是否定词集;win(w)为当前词w所在的滑动窗口。滑动窗口大小的经验值一般选择为3[21],即当前情感标识前后3个词范围内出现否定词,则当前情感会发生转移(ei→ej),转移之后的ej类情感得分会增加1。
二元或者三元情感常识知识(w1,…,wn)(2≤n≤3)情感得分(NS2(ei))计算如下。
(5)
其中,常识知识(w1,…,wn)必须在同一个短句中出现。考虑到情感图式是上下文语义关系的结构化常识,在计算机中以树形结构存储,故在进行模式匹配过程中,采用的是从叶子节点向根节点的后序遍历过程,即从下位词到上位词的语用推理过程[16],直到找到匹配节点为止,若遍历至根节点仍不存在匹配节点,则当前短句没有情感。
通过统计打分函数得到的情感统计得分经过对应维加和后,需要进行归一化处理。
(6)
其中NSx(ei)为一条微博所有子句情感标识在ei维的情感打分之和,最终的情感标签即为对应向量中的最大值:
(7)
2.3.2 微博极性分析
微博极性分析在细粒度情感分析的基础上进行,通过极性和情感之间的映射关系实现极性和细粒度情感的对接。

表3 极性和细粒度情感之间的映射关系
在前文情感统计得分NSx(ei)的基础上,句子极性得分的计算方法如下。
(8)
其中,P+为正向得分,P-为负向得分,最终极性得分P为两者中的较大值,如果两者相同且非零,则最终极性决定于微博中最后一个长句的极性;若两者同为零,则最终极性为中性。
(9)
3 基于情感常识知识的情感分类模型
在前文方法基础上,本文提出了基于情感常识知识的情感分析方法(sentiment analysis based on affective commonsense knowledge, SAACK),并将其应用于极性分类(三类)和细粒度情感分类(七类)中。
中文微博极性分类使用的是统计分类技术,分类效果较好的是基于信息增益(IG)特征选择方法的SVM分类技术[22]。为证明情感常识知识在微博短文本分析中的重要性,本文使用基于情感常识知识的规则匹配技术进行极性分类, 并以SVM分类方法[22]作为对比实验。
典型的细粒度文本情感计算方法是使用语义特征和本体的方法[23]。另外,在认知角度,一个新的文本情感认知模型(简称TACM)被提出[16],该模型使用基于情感图式和情感词典的规则匹配方法进行细粒度情感分析,实验证明在规范文本(文摘、课本、博客等)的情感分析中,该方法效果要好于前者。为证明情感常识知识和语义扩展在微博情感分析中的重要性,本文结合经典分类模型(SVM)和情感常识知识规则匹配方法,构造了双层情感分类模型,并以TACM作为Baseline进行实验验证。
本文使用的语料来自Yang等人[21]情感语料库中的微博部分,是包含51 000条带有极性和细粒度情感标签的新浪微博语料,微博涉及教育、体育、经济等领域。
3.1 极性分类模型
为证明情感常识知识在微博极性分析中的有效性,本文采用基于信息增益(IG)特征选择方法的SVM分类技术作为Baseline,其中信息增益计算公式如下。
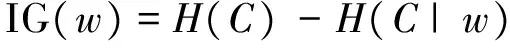



(10)
其中,P(c)表示类别分布;H(C) 表示分布P(C)的熵;H(C|w)为条件熵;特征词w的信息增益的计算方法为发现词w前后类别分布P(C)的熵值变化,熵值改变越大表明该特征词越重要。最后根据信息增益值进行排序,选择排序靠前的K个特征作为分类特征进行SVM分类。实验采用五倍交叉验证方法。结果如图1所示。
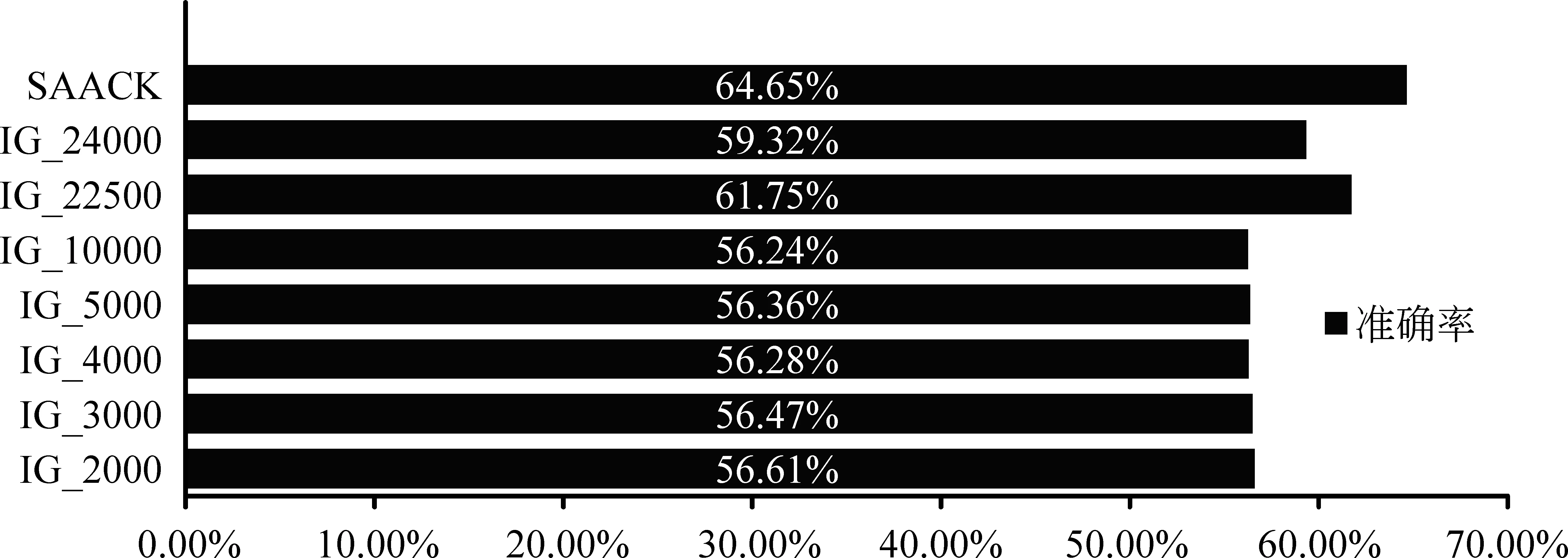
图1 极性分析准确率
其中,IG_2000表示使用IG特征选择方法挑选前2 000个作为分类特征。基于情感常识知识的情感分析方法(SAACK)相对于信息熵得到方法有比较明显的提升(3%)。结果表明机器学习方法与模式匹配方法是有区别的。机器学习方法(比如SVM)作为一个判别式模型,可以通过文本中的显性特征词进行分类,对于训练语料比较依赖。它无法从语料中学习深层次的特征或者知识。这就导致“考试开始了”这句话在使用不同的训练语料时显现出不同的情感。SAACK方法作为一种模式匹配方法,将常识知识作为先验加入到文本判断中,丰富了文本的背景知识和语义,在这点上其优于SVM。但是,这种方法也有一个不足之处在于情感常识的获取是有限的,对于未登录常识或者文本,其无法进行判断。
3.2 细粒度情感分类模型
细粒度情感分类使用的是双层分类模型。
第一层,将微博分为有情感和无情感。此二元分类问题使用的是基于IG特征选择方法的SVM分类技术(SVM_IG)。为验证情感常识知识的作用,在分类过程中融合了情感常识特征和IG筛选的特征(CS+IG)。情感和无情感微博分类准确率如图2所示。两种方法在不同的特征数量情况下准确率相当,但是,当特征数量到达3 000时,两者都达到峰值,这表明情感常识知识在过滤有情感和无情感微博时存在较大的噪声,无法凸显其作用。在特征数量较少时,存在一定的优势,但并不明显。
第二层,将有情感句子划分为六小类,对于多元分类来说,使用机器学习方法分类准确率比较低,主要与训练语料的大小和各类别之间的规模有关。在这层分类中,本文以文本情感认知模型(TACM)[16]作为对比实验,同时为了验证情感常识知识中每个模块的重要程度(贡献度),实验设计中使用排除法分别排除三个模块中的一个进行实验验证。
实验表明,基于情感常识知识的情感分析方法(SAACK)结果要好于对比实验(TACM),提升度为6.41%(表4)。原因在于情感常识知识作为一种隐藏的先验知识,可以弥补情感词典等显性情感标识的缺陷,丰富微博的内在含义,辅助分类。而在情感常识知识的三个模块中,各模块的重要性顺序为: 二元情感常识>网络熟语>情感图式。这是由于情感图式作为结构化常识,其构造来源于手工标注和同义扩展,是对多数公认情感诱因的描述总结,对于规范化文本的情感分析更有意义,对于微博这种形式自由、原创表达较多的文本,其意义不明显。

图2 情感和无情感微博分类准确率

Sadness/%Surprise/%Angry/%Disgust/%Joy/%Fear/%Micro⁃Average/%TACM13.363.9210.1830.9067.7221.0147.81SAACK⁃NetworkIdiom18.116.6011.0636.7474.2819.6553.50SAACK⁃Schema20.806.9512.7140.6472.6015.7653.54SAACK18.515.8811.7437.3575.2418.6854.22
4 基于时序的情感预测及实验分析
4.1 微博情感时序分析方法
微博事件情感趋势的预测采用的是时序分析方法。通过对特定事件在同一时间段的微博情感分析,进而预测现实世界在当前时间段内大众对于此事件所持有的主要情感,对下一步舆论走向或者商品口碑做预估。预测结果的准确性很大部分依赖于时间段的划分。目前,研究界对于时间段的长度选择没有指导性规则。常用的时间片切分方法是使用自然时间(小时、天、周)。本文使用天和小时作为切分单位,由于时间段过小会造成数据稀疏,而时间段过长则会造成过拟合。结合八小时工作制,本文分别选用半工作日(4小时)和一天作为一个时间片。在一个时间片Δt内的情感ei的得分(SRei(Δt))可做如下计算,如式(11)所示。
(11)
其中,Nei(Δt)为当前时间片内情感为ei的微博数量,N(Δt)为当前时间片的微博总数。同理,一个时间片内的极性得分PR(Δt)如式(12)所示,其中P(Δt)是当前时间片内褒义微博的数量减去贬义微博的数量。
(12)
对于情感趋势的评价标准,目前还没有统一的规定。本文选用百度指数*http://index.baidu.com/作为参考标准,判断情感的走势是否符合大众的关注趋势。百度指数(Rindex)是一个反应用户对事件关注度的指标。它的计算方法是以百度搜索引擎为依托,通过百度新闻中关于此事件的报道数量和用户关于此事件的实际检索数量计算得到。
(13)
其中,Nuser(T) 是当前时间片内事件T的搜索量;Nnew(T)是百度新闻中过去30天关于该事件的报道量。之后将该比值除以事发时间段内的最大值,进行归一化。
4.2 预测结果分析
预测使用的语料是新浪微博公共主页中2010年6月7日-2010年6月13日及2011年8月21日—2011年8月27日两个时间段的全量微博。微博的内容如表5所示,每条微博都有话题标签“topic”、转发微博的标签“ttopic”以及时间信息。考虑到预测与微博事件有关,本文选择关注度较高的公众事件,过滤掉由某些企业或组织发起的宣传和公益事件,例如“在四大洲享受美味Pizza!”“iPhone美图应用”等,最终我们保留了六个事件作为实验数据(见表6)。下文以“2010年高考”“2010年世界杯”和“谢霆锋和张柏芝离婚事件”为例进行情感趋势和关注度分析。同时,我们将情感趋势图与百度指数趋势图一并对比加以解读,前者表明用户对于事件的情感变化趋势,后者表示事件受关注的程度。
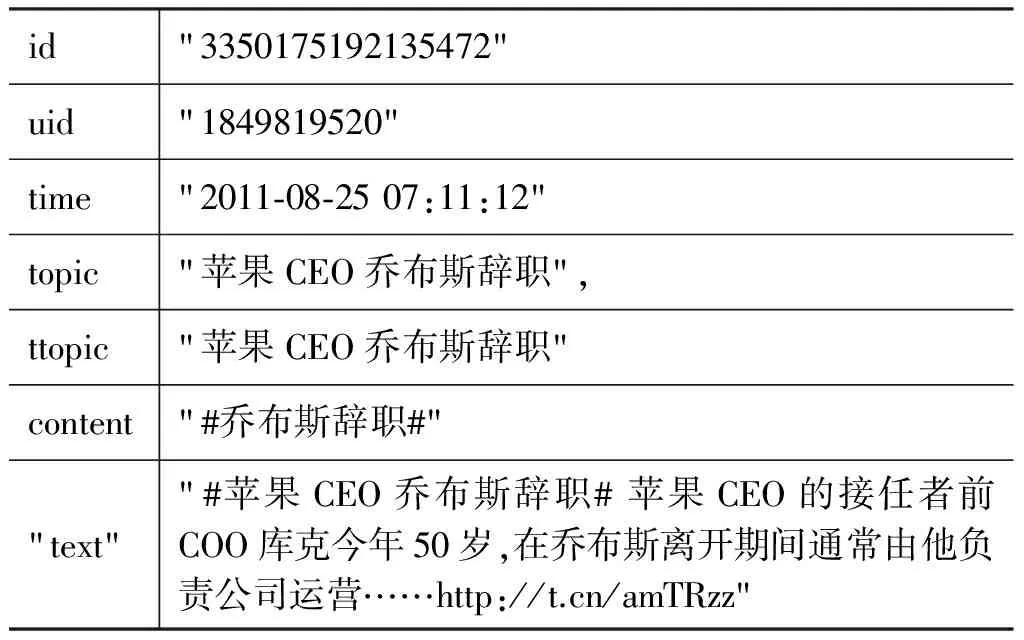
表5 数据集样例
图3为2010年高考情感趋势图,图4为同一时间段的百度指数趋势图。从图3可以看出整个高考的情感基调是“喜”,包括前期的“祝福 加 油”和 后 期
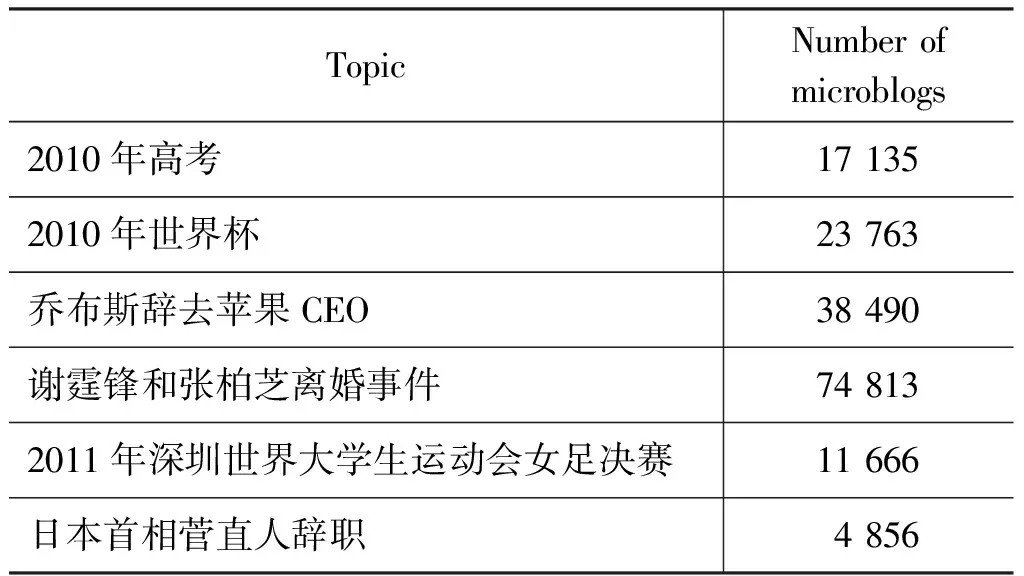
表6 数据集详情
的“解放释怀”。6月7日高考开始,百度指数显示这天用户的关注度达到了峰值(见图4)。图3中7号当天“喜”的情感占据了一半的比例,另一半是无情感,无情感这部分旨在报道事件本身,如“2010年全国#高考#今日拉开大幕,将有957万考生走进考场。6月7日,广西南宁多云,气温25~29℃,各项气象条件非常适宜考生的正常发挥……”而“喜”的情感多为祝福加油“高考的童鞋们,加油加油加油,为你祈祷。黎明的曙光已经到来!”8号和9号关注度和情感比例都有所下滑,10号关注度到达波谷,而这时正值高考题目讨论的时刻,由情感曲线可知,公众情感由“喜”转“哀”。11号达到另一个关注度高峰,对应这时的情感基调是“喜”,表达的多为高考后的释怀和对之后而来的“2010世界杯”的期待,如 “世界杯终于要开始了,哈哈,最近快憋死我了”。

图3 2010年高考情感趋势图
图5为2010年世界杯情感趋势图,图6为同一时间段的百度指数趋势图。主情感基调是“喜”。整个过程传递的是“狂欢”和“放松”的心情,例如, “世界杯月开始,让我们深呼吸下,准备开始”。世界杯开幕式在6月11日晚22:00,两图分别于11号和12号达到一个峰值。10号之前用户关注度有上升趋势,但情感曲线有些波动,具体表现为阐述对各个队伍的立场,“斗牛士军团最后一场热身赛展示了自己作为本届世界杯最大热门,其强大的实力和华丽丽的足球风格。热爱西班牙!!”“南非世界杯,我选择支持英格兰队!快来披上你支持的球队国旗吧,让大家知道你的世界杯立场!”

图4 2010年高考百度指数趋势图

图5 2010年世界杯情感趋势图
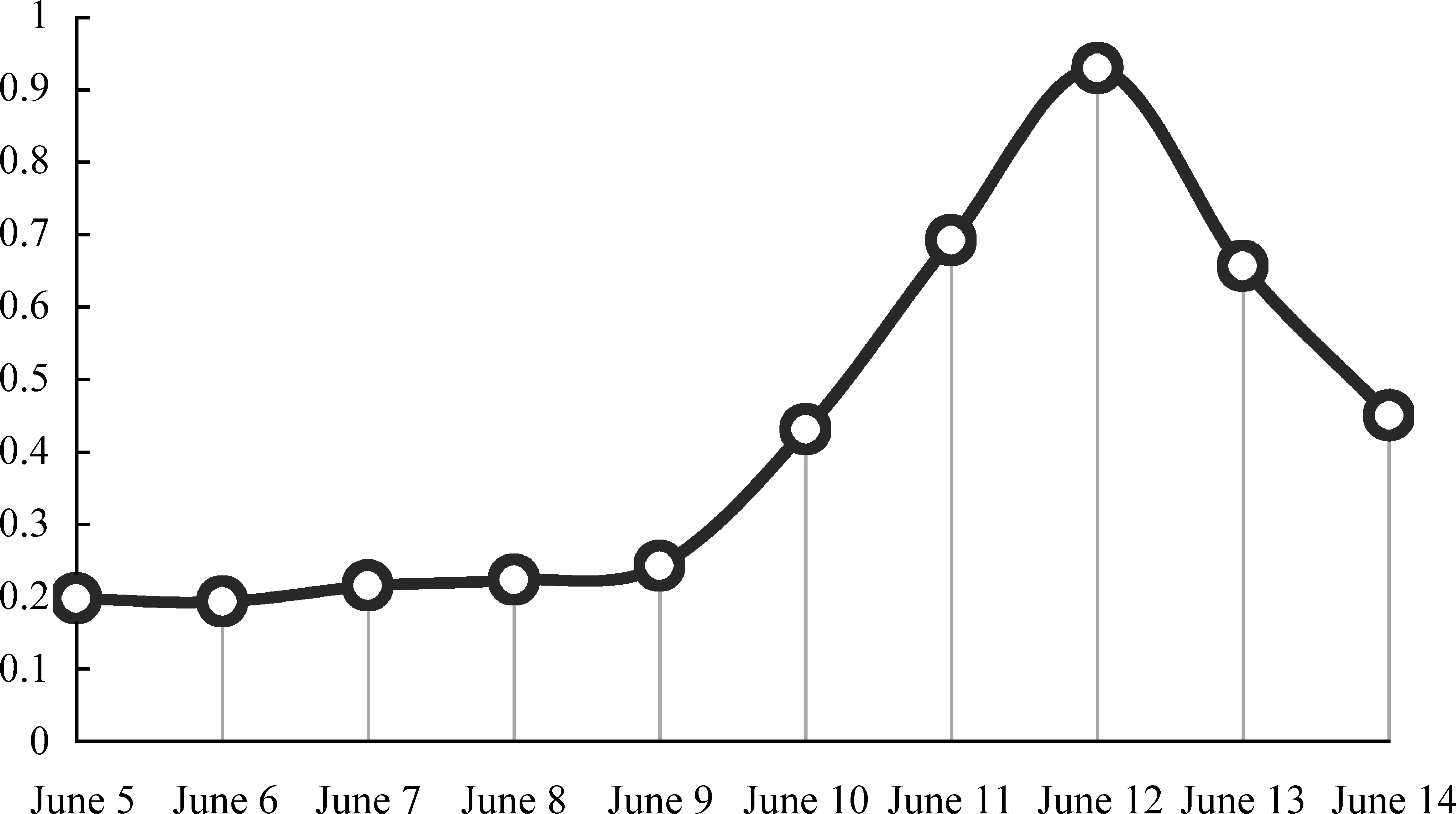
图6 2010年世界杯百度指数趋势图
图7为谢霆锋和张柏芝离婚事件情感趋势图,图8为同一时间段的百度指数趋势图。对比图7和图8,该事件被媒体报道发生在2011年8月21日凌晨0点左右。以24号为分界,前半段表达的是负向“遗憾”的情感,而后半段多为正向的“祝福希望”。用户的关注度在22号达到一个小高峰,而情感趋势显示该时刻为负向情感高峰,主要表达遗憾的情感,如“从‘锋芝恋’到‘锋芝婚变’五年婚姻会毁于一旦么?”25号微博开始出现另一个关注高峰,情感趋势线也出现了正向情感高峰,如“两个纠结的人 不纠结了。”“谢霆锋我挺你,你要有更好的人来照顾你。”
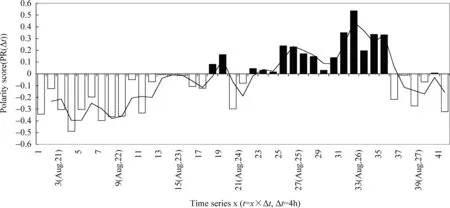
图7 谢霆锋和张柏芝离婚事件情感趋势图

图8 谢霆锋和张柏芝离婚事件百度指数图
5 结束语
微博作为互联网新型公众舆论平台正在被越来越多的研究者关注。本文试图通过新浪微博预测现实事件的情感趋势,为舆论监督、产品营销和优化提供更好的理论依据。考虑到微博的上下文缺失和特征稀疏的特点,理解微博需要一定的背景或常识知识。本文首先通过上下位语义扩展微博的语义表达,其次,结合手工标注和自动扩展的方法构造情感常识库,并在此基础上提出了基于情感常识知识的情感分析方法(SAACK)进行文本的极性分类和细粒度情感分类。在真实微博语料中的实验表明,该方法现相对于目前的分类方法(SVM)和文本情感认知模型(TACM)有明显的提升。同时,在该方法的基础上进行的情感时序分析(即情感趋势预测)和百度关注指数具有较高的吻合度。通过百度关注和情感趋势可以发现不同时间段用户的关注度及所持有的主流情感基调。
本文研究的前提是话题中途没有发生偏移,但在微博事件中话题会发生偏移。如何发现话题中的突发性子话题并预测子话题情感趋势是本文的下一步研究工作。同时,如何使用非监督和众包机制实现情感常识的动态扩展也是本文的下一步的研究方向。
[1] Pang B, Lee L. Opinion mining and sentiment analysis[J]. Foundations and trends in information retrieval, 2008, 2(1-2): 1-135. [2] Liu B. Sentiment analysis and subjectivity[J]. Handbook of natural language processing, 2010, 2: 627-666.
[3] Pang B, Lee L,Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques[C]// Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. Association for Computational Linguistics, 2002: 79-86.
[4] Pang B, Lee L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004: 271.
[5] Bollen J, Mao H, Pepe A. Modeling public mood and emotion: Twitter sentiment and socio-economic phenomena[C]//ICWSM 2011: 450-453.
[6] Joshi M, Das D,Gimpel K, et al. Movie reviews and revenues: An experiment in text regression[C]//Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 293-296.
[7] Alec G, Lei H, Richa B. Twitter sentiment analysis[R]. Final Projects from CS224N for Spring 2008/2009, The Stanford Natural Language Processing Group, June 6, 2009.
[8] 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报, 2012, 26(1): 73-83.
[9] Li D,Shuai X, Sun G, et al. Mining topic-level opinion influence in microblog[C]//Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, 2012: 1562-1566.
[10] Singh P. The public acquisition of commonsense knowledge[C]//Proceedings of AAAI Spring Symposium: Acquiring (and Using) Linguistic (and World) Knowledge for Information Access. 2002.
[11] Oh C, Sheng O. Investigating predictive power of stock micro blog sentiment in forecasting future stock price directional movement[C]// Proceedings of the ICIS. 2011.
[12] Tumasjan A, Sprenger T O, Sandner P G, et al. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment[J]. ICWSM, 2010, 10: 178-185.
[13] Liviu L, Mihaela T. Predicting Product Performance with Social Media[J]. Informatica Economica,2011, 15(2): 46-56.
[14] Gupta M,Gao J, Zhai C X, et al. Predicting future popularity trend of events in microblogging platforms[J]. Proceedings of the American Society for Information Science and Technology, 2012, 49(1): 1-10.
[15] Hearst M A. Automatic acquisition of hyponyms from large text corpora[C]// Proceedings of the 14th conference on Computational linguistics-Volume 2. Association for Computational Linguistics, 1992: 539-545.
[16] 任巨伟, 杨亮, 林鸿飞. 情感图式构造及其在文本情感计算中的应用[J]. 江西师范大学学报: 自然科学版, 2013, 37(2): 130-135.
[17] Fellbaum C. WordNet: an electronic lexical database[R]. Cambridge: MIT Press, 1999.
[18] Liu H, Singh P. ConceptNet—a practical commonsense reasoning tool-kit[J]. BT technology journal, 2004, 22(4): 211-226.
[19] 任巨伟, 杨源, 王昊, 等. 二元情感常识库建设及其在文本情感分析中的应用[J]. 中国科技论文在线精品论文, 2014, 7(4): 291-299.
[20] Yang L,Lin H F. Construction and application of chinese emotional corpus[C]// Proceedings of lecture notes in computer science(springer),2013(7717): 122-133.
[21] Wang S, Fan X, Chen X. Chinese short text classification based on hyponymy relation[J]. Journal of Computer Applications, 2010, 30(3): 603-606.
[22] 陈建美,林鸿飞,基于语法的情感词汇自动获取,智能系统学报[J], 2009,4(2): 100-106.
[23] 刘志明, 刘鲁. 基于机器学习的中文微博情感分类实证研究[J]. 计算机工程与应用, 2012, 48(1): 1-4.
[24] 徐琳宏, 林鸿飞. 基于语义特征和本体的语篇情感计算[J]. 计算机研究与发展, 2007, 44(S2): 356-360.
Public Sentiment Trend Prediction of Microblog Events Based onAffective Commonsense Knowledge
REN Juwei, YANG Liang, WU Xiaofang, LIN Yuan, LIN Hongfei
(Information Retrieval Laboratory, Dalian University of Technology,Dalian, Liaoning 116023, China)
Microblog is a large and complicated public opinion platform on the Internet. In this paper, we demonstrate how microblogs can be used to predict real world public sentiment trends of events. Firstly, considering the special properties of microblogs, absence of context and sparseness of feature, we use the hyponymy relationship between words to do semantic extension for each microblog. Secondly, with the help of semantic feature and affective commonsense knowledge, we can decide the sentiment of each microblog through constructing a double-layer text classifier. Finally, public sentiment trend prediction of each event is performed by using time series sentiment analysis of microblogs. The experiment results show that our sentiment analysis method has a better performance than state-of-the art classification methods. Besides, the sentiment trends of events are consistent with the development of the real world situation to a large degree.
microblog; sentiment analysis; semantic expansion; affective commonsense knowledge; public sentiment trend

任巨伟(1988—),硕士研究生,主要研究领域为情感计算,文本挖掘。E⁃mail:jwren1988@mail.dlut.edu.cn杨亮(1986—),讲师,主要研究领域为情感计算,文本挖掘。E⁃mail:liang@dlut.edu.cn吴晓芳(1989—),硕士研究生,主要研究领域为知识发现,文本挖掘。E⁃mail:xfwu@mail.dlut.edu.cn
2015-01-21 定稿日期: 2015-05-20
国家自然科学基金(61632011,61562080);辽宁省自然科学基金(201202031,201402003)
1003-0077(2017)02-0169-10
TP391
A
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
高技术通讯(2021年1期)2021-03-29 02:29:24
文苑(2020年11期)2020-11-19 11:45:11
时代英语·高一(2019年5期)2019-09-03 02:09:34
电脑与电信(2018年11期)2018-02-16 05:41:32
中国眼镜科技杂志(2017年10期)2017-07-10 09:17:56
信息安全研究(2016年3期)2016-12-01 06:06:41
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
河南电力(2015年5期)2015-06-08 06:01:56
