
一种融合个性化与多样性的人物标签推荐方法
2017-06-01 11:29熊锦华程学旗
中文信息学报 2017年2期
颛 悦,熊锦华,程学旗
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100190)
一种融合个性化与多样性的人物标签推荐方法
颛 悦1,2,熊锦华1,2,程学旗1,2
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100190)
针对人物标签推荐中多样性及推荐标签质量问题,该文提出了一种融合个性化与多样性的人物标签推荐方法。该方法使用主题模型对用户关注对象建模,通过聚类分析把具有相似言论的对象划分到同一类簇;然后对每个类簇的标签进行冗余处理,并选取代表性标签;最后对不同类簇中的标签融合排序,以获取Top-K个标签推荐给用户。实验结果表明,与已有推荐方法相比,该方法在反映用户兴趣爱好的同时,能显著提高标签推荐质量和推荐结果的多样性。
人物标签推荐;多样性推荐;标签冗余;标签质量
1 引言
随着网络的社会化属性越来越明显,新兴的社交网络,如国外的Facebook、Twitter、LinkedIn,国内的新浪微博、人人网等,将人们更紧密地结合在一起。据新华网第32次中国互联网络发展状况统计报告,截至2013年6月底,我国微博用户已达到3.31亿,比2012年底增长了2 216万[1]。社交网络已经变为人们生活的一部分,人们将各种信息发布到社交网络上与朋友分享,这使得基于社交网络的人物研究变得越来越重要。社交网络强调以人为核心,一切活动和资源均围绕人与人之间的互动。在这些社交网络中,人们为了表明自己的兴趣爱好、职业特征,常常选择一组词汇或者短语对自身进行标注,进而将自身与一组词汇或者短语建立联系,这些标注词汇或者短语通常被称为标签(tag)。图1展示了新浪微博用户“李开复”的标签信息。
利用用户标注的标签信息可以帮助解决好友推荐、社团发现、人物搜索等问题。为了获取更准确的标签,许多网络服务提供了标签推荐的功能,来帮助用户进行标签标注。实际上,在社会化标签系统中的标签推荐已经有许多研究,例如,网页标签网站Delicious为网页增加标签、论文书签网站CiteULike为论文增加标签、音乐网站Last.fm对音乐增加标签。目前,社会化标签系统中的标签推荐方法主要包括: (1)基于内容的标签推荐技术[2-5],主要利用标注资源内容特征进行标签推荐; (2)基于关系图的标签推荐技术[6-12],主要利用社会化标签系统中的三元组关系进行标签推荐。由于社交网络中的人物标签和社会化标签的标注资源、标注目的及标注模型都有很大的区别,因此社会标签中关于标签推荐的相关工作不适用于社交网络中人物标签推荐。

图1 新浪微博用户李开复的标签信息
2 相关工作
随着社交网络的发展,人物标签推荐慢慢引起人们的注意。目前,人物标签的推荐方法主要分为两类: 基于社交关系的标签推荐和基于微博内容的标签推荐。
2.1 基于社交关系的标签推荐
Lappas等人[13]利用社交网络中的关注关系建立社会支持网络(social endorsement networks)来挖掘Twitter人物标签。作者认为用户具有多个不同方面的兴趣特征,用户粉丝根据用户某一方面兴趣特征而关注了他,因此用户的粉丝特征能够反映出用户不同方面的兴趣爱好。例如,Twitter用户Lance Armstrong的粉丝群体分别因为Cycling、Charity和Cancer Awareness等标签特征而关注他。文章中,作者首先获取用户的粉丝发布的微博消息并进行预处理,然后使用改进的主题模型进行人物标签推荐。
陈渊等人[14]对用户的关注人数、粉丝数和发布的微博数为标准对用户信息进行分析,认为用户关注的对象是比用户粉丝更能反映出用户感兴趣的话题。由此,使用用户关注对象的标签推荐给用户,并把用户粉丝作为关注对象较少时候的补充,具体思路是: 首先,收集用户关注人的标签构建候选标签集,然后,使用标签统计次数作为其权重;然后,对候选标签排序,每个标签的得分(推荐度)为标签自身的权重乘以该标签在用户微博中出现频次加1;最后,选取候选标签中Top-K个标签推荐给用户。
汪祥等人[15]针对新浪微博中的标签预测问题,提出了基于用户交互关系的标签预测方法,该方法通过根据用户交互行为(评论、转发和提及关系)构建加权有向加权图G=(V,E,W),在交互图G中,一个顶点vi(vi∈V)可以表示为vi=(ui,Tui,Wui),其中,ui代表用户,Tui代表用户ui的标签集合,Wui是由ui与Tui中的标签的相关度组成的集合。文中利用标签在交互图G上的传播进行人物标签预测。
2.2 基于微博内容的标签推荐
Yamaguchi等人[16]提出了一种利用Twitter用户的分组名称为用户推荐标签的方法。文中首先根据用户分组列表抽取短语作为标签,然后把抽取的标签赋给所属分组列表下面的关注用户,并得到“用户-标签”的矩阵,最后计算用户和标签之间的相关得分对标签排序。但是由于用户分组所用词语的相似性,造成挖掘的标签中存在着大量的同义标签,标签推荐质量不高。
Wu等人[17]分别使用TFIDF和TextRank的方法抽取用户微博的关键词作为人物标签。文中把用户所有的微博消息作为一个文档,然后计算文档中每个词语的TFIDF权重。TextRank[18]作为PageRank算法的变种,把每个候选词作为图中的一个节点,根据候选词之间的共现关系建立节点之间的边,从而构建成一个无向加权图。候选词Vi的秩为:
(1)
其中,wji是候选词Vj和Vi所构成边的权重;E(Vi)是候选词Vi连接的候选词集合;d为阻尼系数,一般设为0.85。通过多次迭代直到收敛后,得到排列最高的K个候选词作为人物标签。从微博文本中抽取标签的方法需要很多预处理工作,包括缩写词处理、网络用语的处理、去停用词等。而且微博文本中可能没有出现能够代表用户兴趣爱好的关键词。例如,虽然用户经常谈论体育相关的内容,但关键词中没有出现“体育”。
涂存超等人[19]对微博用户的标签进行分析,提出了使用社交网络结构进行正则化的标签分发模型(network-regularized tag dispatch model,NTDM)。NTDM模型提取微博用户个人简介中的关键词,然后对关键词和标签之间的关系进行建模,同时使用社交网络中的社交关系对模型进行约束。NTDM模型是一个类似PLSA和LDA的概率模型,该模型只能够对有个人简介的用户建模,不能解决缺少个人简介或者个人简介信息过少的用户的标签推荐问题。
以上社交网络中的人物标签推荐方法没有考虑到推荐结果的多样性问题和标签推荐质量,为了解决上述问题,受到以上相关工作的启发,本文提出了一种融合个性化与多样性的人物标签推荐方法。
3 融合个性化与多样性的人物标签推荐方法
3.1 方法概述
在社交网络中,用户社交对象能够反映用户的兴趣爱好,但现有的方法没有对用户社交对象的多样化兴趣进行有效划分,进而无法从用户关注对象中获取个性化与多样化的标签。为了解决社交网络中人物标签推荐的个性化与多样性问题,本文提出了一种融合个性化和多样性的人物标签推荐方法。
该方法对用户关注对象进行划分,获取在不同兴趣上的关注对象集合,并通过对不同兴趣用户集合上的标签进行个性化排序,最终获取融合个性化和多样性的推荐标签。此外,本文使用标签冗余处理技术把语义相似、拼写错误等问题标签进行规范化,提高了标签推荐的质量。算法具体流程如下: 首先,分析用户的微博信息判断社交对象的相似性,并使用聚类算法把具有相似言论的社交对象划分到相同的类簇中,这样每个类簇中包含着具有相似兴趣爱好的关注对象,多个不同类簇能够反映出用户多样化的关注兴趣;然后,使用标签冗余处理技术对类簇中的人物标签进行预处理,把具有语义相同、语义相近、拼写错误的标签规范化为相同语义的高质量标签;最后,通过两阶段标签融合排序方法获取能够反映出用户不同关注兴趣的前K(K>0)个标签,具体流程如图2所示。
3.2 基于主题的对象划分
在社交平台上,用户发布的微博信息能够反映出用户的兴趣爱好和职业特征,新浪微博中一条微博消息最长允许140个字符,其文本短小且信息量少。为了能够充分挖掘用户的行为特征,我们抓取用户近三个月的微博短文本作为用户的语义空间,把用户聚类问题转化为文本聚类问题。对于微博短文本,由于关键词出现的次数很少,传统的文本聚类方法不能从语义上理解微博文本之间的联系,无法获得较好的聚类效果。
本节中我们使用主题模型(Latent Dirichlet Allocation,LDA)获取用户微博内容潜在的主题特征及其在各个主题上的概率分布。利用LDA生成一篇文档的过程如图3所示。
LDA模型是由Blei、Ng和Jordan于2003年提出来的,主要用来对文档建模。在LDA中,文档集中的所有文档按照一定的概率共享隐含主题集合,而隐含主题集合则按照一定的概率共享特征词集合。LDA可通过对文字隐含的主题进行建模,挖掘出文字背后的语义关联,克服了传统信息检索中文档相似度计算方法的缺点。
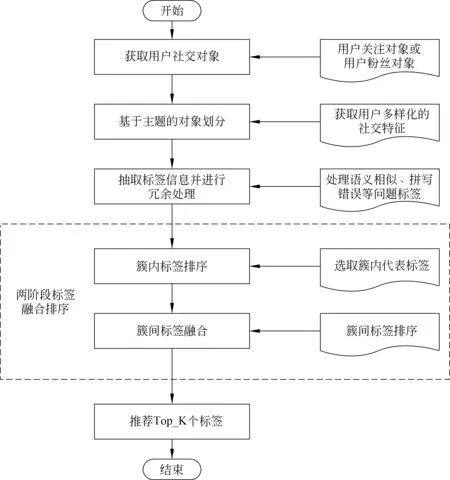
图2 融合个性化与多样性的人物标签推荐方法流程

图3 利用LDA生成一篇文档的过程
LDA模型主要问题在于如何对超参数α和β进行参数估计。LDA的提出者使用EM-变分法进行超参数的训练,但该方法的序列过程较为复杂,不适合大规模文本处理。为了克服EM-变分法的缺点,2004年Thomas Griffiths和Mark提出了用吉布斯采样(Gibbs sampling)的方法学习LDA模型。吉布斯采样是利用Dirichlet分布和多项分布之间的对偶性,只对隐含变量z进行采样,得到两个参数分布: “文档-主题”分布和“主题—词语”分布。
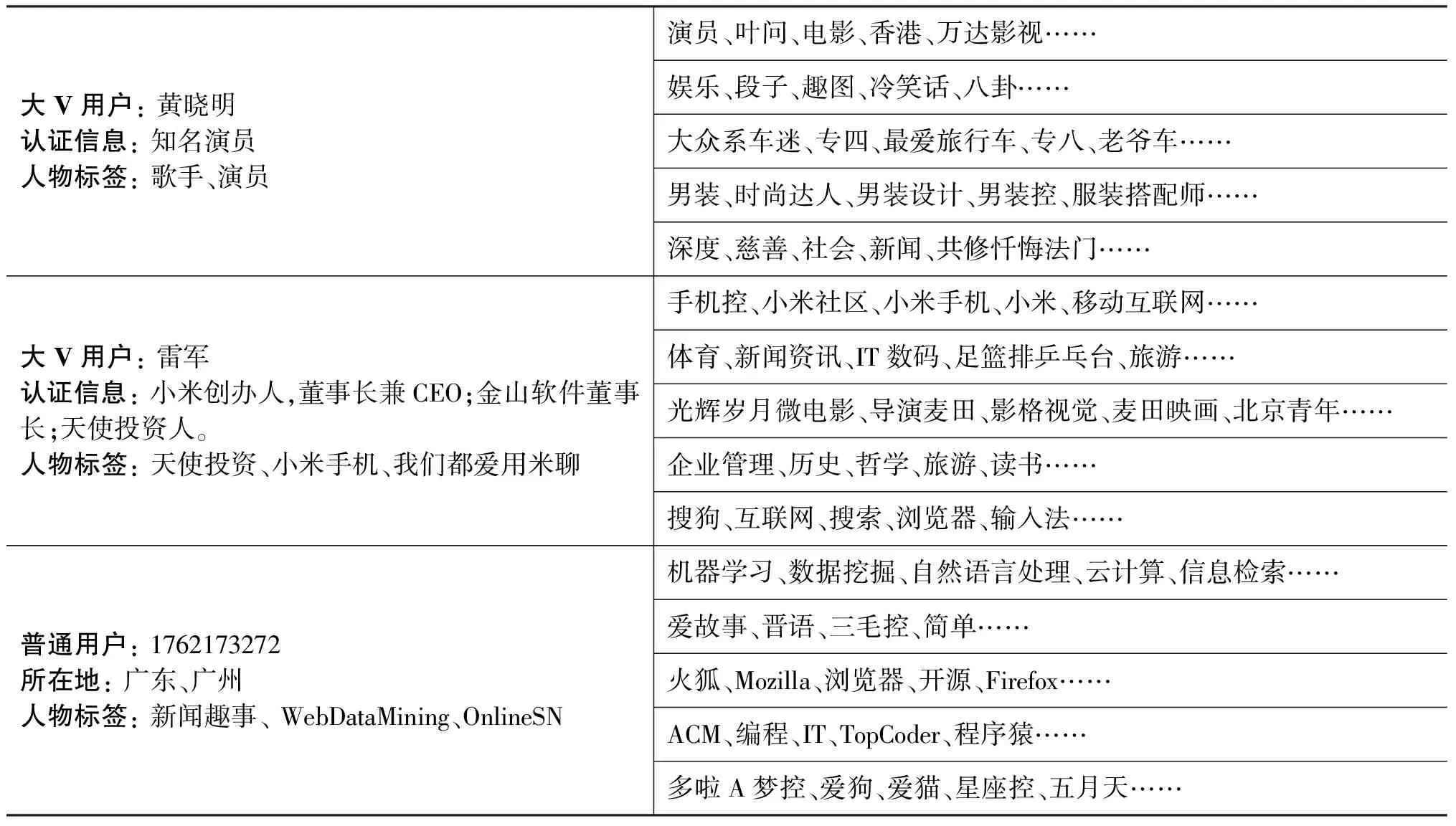
本章将使用吉布斯采样的方式进行LDA模型学习。图4阐释了LDA主题模型进行文本处理的大致过程,在该图中,文档集D={d1,d2,…,dN},文档集D中的词语集合W={w1,w2,…,wM},主题Tdi=[t1,t2,…,tK],N为文档个数,M为文档集中的词语数,K为通过LDA训练后的主题个数,其中M 图4 N×M的文档-词语矩阵经过LDA转化为N×K的文档-主题矩阵 使用LDA模型引入用户微博的隐含主题,每个用户可以表示为在语义空间上的主题向量,然后,使用传统的聚类算法对用户进行聚类分析,完成用户聚类的过程。通过计算每个用户在主题集合上的概率向量的余弦相似度,可以得到两个用户在微博主题上的相似度。对于用户ui和用户uj的相似度可以使用其对应的微博文本di和dj在隐含主题向量Tdi与Tdj的相似度计算。其对应的公式如式(2)所示。 (2) 在把用户语义空间表示为隐含主题层次上的向量模型基础上,进一步利用K-means聚类方法对用户在主题层次进行聚类分析,最终把用户关注对象划分为多个不同语义空间的类簇,每个类簇反映了用户的特定方面的社交特点。通过获取用户类簇中的人物标签信息,得到由相似言论用户的标签构成的标签类簇,这些标签类簇能够反映出用户不同方面的兴趣特点。 3.3 标签冗余处理 人物标签的同义词、缩写词、繁简转化、双语词等造成了标签的冗余性,如果过滤掉这些冗余的标签,不仅能够减少标签推荐中的噪声,提高推荐的准确率,而且能够得到高质量的推荐标签。标签聚类通过把冗余标签聚到一起并把标签簇的优质标签推荐给用户,能够很好地解决标签冗余性的问题。社交网络中人物标签具有以下特点: (1) 标签短小且含有缩写词、错误拼写等现象,不能提供足够的信息进行相似度计算; (2) 标签中含有新词、网络用语等不规范词语,基于同义词典进行语义扩充的方法不适用于人物标签; (3) 标签没有用户标注历史和标签共现特征,不能通过标签之间的共现关系进行相似度计算。 为此,本文提出一种基于Web搜索摘要扩展的标签相似度计算方法。在Web网页集合中,标签作为关键词在网页中的上下文信息,能够对标签内容进行扩充以方便计算文本之间的相似度。由于网络文本的高速增长,搜索引擎提供一种有效的方法动态更新和组织管理这些网页文本。因此,我们利用搜索引擎检索人物标签,获取搜索结果中的网页摘要对标签进行语义扩展,具体过程如表1所示。 表1 基于网页摘要的人物标签语义扩展过程 把人物标签表示为向量空间形式后,我们可以通过余弦相似度(cosine similarity)计算标签ti和tj之间的相似性,如式(3) 所示。 (3) 根据标签相似度计算方法,使用基于凝聚式的层次聚类算法进行标签聚类,使得类簇中的标签相似度高,类簇间的标签相似度低,进而获取类簇中的优质标签作为该类簇中其他标签的规范化标签,实现标签的冗余处理。 3.4 两阶段标签融合排序模型 两阶段标签融合排序模型首先是对标签类簇内的标签进行排序,选取能够反映类簇特征的标签加入推荐候选集。然后对标签类簇间的标签进行融合处理,包括标签合并、标签排序,最终获取能够融合个性化与多样性的推荐标签。 3.4.1 簇内标签排序方法 对于标签类簇内的标签,如果在兴趣领域的类簇中出现的次数多,而在整个标签系统中出现的次数较少,我们可认为它能够反映这个群体的兴趣。基于此,可使用经典的TFIDF计算每个候选集中的标签。其中TF是标签在用户候选集中出现的次数,IDF是在整个系统中标记为标签t的用户数和全部用户数的逆频率对数。对于用户u,其关注用户划分的兴趣领域为Clusteru={clusteru,0,clusteru,1,…,clusteru,m},类簇clusteru,m表示包含相同行为特征的用户群体,对于标签t,其对应的TFIDF为TFIDFt,计算公式如式(4)~式(7)所示。 (4) (5) (6) (7) 其中,U是有限的用户集合,Nt是系统中标签数量。 3.4.2 簇间标签融合方法 对于用户u,通过用户聚类和簇内标签排序方法,我们可以得到其关注对象划分的类簇集合Clusteru={clusteru,0,clusteru,1,…,clusteru,m}和由每个簇中的标签构成的带有权重的标签簇集合,其中m为用户u的聚类个数。对于用户u的每个候选标签t,其最终的权重wu,t可以表示为标签TF-IDF权重和用户与簇的相似度similarity(u,clusteru,i)的乘积,计算公式如式(8)所示。 (8) 在社交网络中,当用户与类簇中相同关注对象或者相同粉丝数越多时,他们之间的兴趣特征相似性越强。为此,用户和用户类簇之间的相似度关系可以通过用户与类簇中关注对象的相同用户关注数或者相同粉丝数来衡量。为了减少用户自身粉丝数量和关注数量对用户之间相关性的影响,我们使用Jaccard系数衡量用户与关注对象之间的相似关系,如式(9)所示。 (9) 其中,Co(u1,u2)代表用户u1和u2的相同粉丝数或者相同用户关注数,Co(u)代表用户u的粉丝数或者关注数。clusteru,i代表用户u的第i个类簇,在此基础上,用户u与用户类簇clusteru,i的相关性可表示为: (10) 4.1 数据集 目前,社交网络上的标签推荐没有标准数据集,为了合理地评价标签推荐的结果,本节选取标签数量等于10的大V用户当做标准数据集。为了确保测试集数据选取的随机性,我们采用随机数的方法来判定某一符合条件的用户是否加入测试集,最终选出200名用户作为本实验的测试集。 本节使用涂存超等人[19]统计的200万新浪微博用户信息而获取top-10个热门标签作为Baseline,该方法对任意用户都推荐当前系统中的top-10个热门标签,这也是当前标签推荐中常用的对比方法。其中,微博数据中top-10标签详细信息如表2所示。 表2 200万微博数据中top-10标签详细信息 为了验证本章提出的标签推荐方法具有多样性的特点,我们使用基于社交关系的标签推荐方法作为对比。基于社交关系的标签推荐方法是根据TF-IDF方法对用户关注对象的标签进行排序,选取TF-IDF值高的标签作为推荐结果,计算公式如式(11)~式(13)所示。 (11) (12) (13) 其中,Followu为用户u的关注对象集合,Nt为标签总数,U为有限的用户集合。 4.2 评估方法 为了证明本文提出方法的有效性,我们使用准确率和多样性这两个指标来度量标签推荐的效果。考虑到人物标签语义信息含糊或者标签含义过于单一的问题,我们通过分析以下两种信息进行标签推荐的准确率评判: (1) 标签有没有反映出用户的特征(如标签、简介等原信息)。 (2) 标签是否反映出用户微博主题特征 如果推荐结果满足以上任意条件,则认为推荐的标签为正确结果。本实验综合多位评价者的评价结果来计算推荐标签的准确率和多样性。标签准确率度量的公式为: (14) 其中,K是推荐标签个数;Ncorr是推荐K个标签的正确个数。 推荐结果的多样性是推荐算法要解决的一个重要问题,现有很多推荐多样性的评价方法,本文使用ILS(intra-list similarity)[20-22]来评价标签推荐的多样性。ILS指标评测的是推荐列表中所有推荐条目的平均两两相似性。具体计算方法为: (15) 其中,R是标签推荐列表,i和j是推荐列表中的条目,K是推荐条目的个数。ILS值越大,推荐列表多样性效果越差。 4.3 实验结果 本节分别使用热门标签推荐方法(Baseline)、基于社交关系的标签推荐方法(Simple-Relation)和融合个性化与多样性的人物标签推荐方法(Diversity-Relation)计算推荐标签数量在1~10之间的准确率和多样性。 图5展示了标签推荐结果的准确率对比,从实验中可以看出,融合个性化与多样性的人物标签推荐方法准确率优于Baseline和基于社交关系的标签推荐方法。这是由于通过对用户关注对象的划分,消弱了噪声标签对推荐结果的影响,使得推荐结果在趋于多样化的同时多角度反映了用户的关注兴趣。在实验过程中,我们发现融合个性化与多样性的人物标签推荐方法推荐的标签质量明显好于基于社交关系的标签推荐方法,这主要是因为本文方法利用了标签冗余处理技术进行了标签冗余处理,把语义相近的标签聚集一起,并选取相似标签中的热门标签作为推荐结果,使得推荐的用户标签既准确又质量高。 图5 标签推荐结果的准确率对比 图6展示了标签推荐结果的多样性对比(ILS值越低表示推荐结果的多样性越高),从图中可以看出融合个性化与多样性的人物标签推荐效果要极大地优于基于社交关系的标签推荐效果。这主要是因为融合个性化与多样性的人物标签推荐方法把用户的关注对象划分为不同的群体,使得群体内的用户具有相似的兴趣爱好,而群体之间的相似性较弱,进而在群体之上做标签推荐,这样得到的推荐标签能够反映出用户不同的兴趣点,推荐结果的多样性好。此外,融合个性化与多样性的人物标签推荐方法通过对标签冗余问题的处理,更进一步增加了标签推荐的多样性。 4.4 效果实例 本文分别以新浪微博认证用户和普通用户为例,通过本文提出的方法对用户关注对象进行聚类分析,获取类簇中的标签信息,然后通过质量权重排序得到如表3所示的标签结果。可以看出,不同类簇中的标签能够反映出类簇用户的特征,每个类簇的特征能够体现出用户关注这些对象的兴趣点。 表4展示冗余标签对标签推荐算法的影响。推荐算法给出五个标签,基于社交关系的标签推荐方法推荐的标签含有大量的相似标签,推荐结果单一,而融合个性化与多样性的人物标签推荐方法能够合并相似标签,并从多个角度推荐质量高的标签,在保证推荐个性化的同时使推荐结果更加多样化。 图6 标签推荐结果的多样性对比 大V用户:黄晓明认证信息:知名演员人物标签:歌手、演员演员、叶问、电影、香港、万达影视……娱乐、段子、趣图、冷笑话、八卦……大众系车迷、专四、最爱旅行车、专八、老爷车……男装、时尚达人、男装设计、男装控、服装搭配师……深度、慈善、社会、新闻、共修忏悔法门……大V用户:雷军认证信息:小米创办人,董事长兼CEO;金山软件董事长;天使投资人。人物标签:天使投资、小米手机、我们都爱用米聊手机控、小米社区、小米手机、小米、移动互联网……体育、新闻资讯、IT数码、足篮排乒乓台、旅游……光辉岁月微电影、导演麦田、影格视觉、麦田映画、北京青年……企业管理、历史、哲学、旅游、读书……搜狗、互联网、搜索、浏览器、输入法……普通用户:1762173272所在地:广东、广州人物标签:新闻趣事、WebDataMining、OnlineSN机器学习、数据挖掘、自然语言处理、云计算、信息检索……爱故事、晋语、三毛控、简单……火狐、Mozilla、浏览器、开源、Firefox……ACM、编程、IT、TopCoder、程序猿……多啦A梦控、爱狗、爱猫、星座控、五月天…… 表4 标签冗余对标签推荐算法的影响 针对当前人物标签推荐个性化与多样性不足的问题,本文提出了一种融合个性化与多样性的人物标签推荐方法。该方法把用户的关注对象划分为不同的兴趣类簇,通过对不同类簇中的人物标签进行排序融合,得到能够反映出用户兴趣特点且多样化的标签推荐结果。下一步的工作是,如何利用用户发布内容进行人物标签抽取,以解决社交关系不足以提供丰富的标签信息的人物标签推荐问题。 [1] 新华网. 第 32 次中国互联网络发展状况统计报告[R]. 网络数据库: 中国互联网络信息中心,2013年. [2] N Zhang, Y Zhang, J Tang. A tag recommendation system based on contents[C]//Proceedings of the ECML PKDD Discovery Challenge 2009, 2009: 285. [3] Harvey M, et al. Tripartite hidden topic models for personalised tag suggestion[C]//Proceedings of the Advances in Information Retrieval. 2010: 432-443. [4] Zhang Y, et al. Combining content and relation analysis for recommendation in social tagging systems[C]//Proceedings of the Physica A: Statistical Mechanics and Its Applications. 2012, 391(22): 5759-5768. [5] Heymann P, D Ramage, H Garcia-Molina. Social tag prediction[C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval,2008. [6] Jäschke R, et al. Tag recommendations in folksonomies[C]//Proceedings of the Knowledge Discovery in Databases: PKDD 2007, 2007: 506-514. [7] Liu Z, C Shi, M Sun. FolkDiffusion: A graph-based tag suggestion method for folksonomies[C]//Proceedings of the Information Retrieval Technology, 2010: 231-240. [8] Hu J, et al. Personalized tag recommendation using social influence[J]. Journal of Computer Science and Technology, 2012, 27(3): 527-540. [9] Guan Z, et al. Personalized tag recommendation using graph-based ranking on multi-type interrelated objects[C]//Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009. [10] Zhou T, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4): 046115. [11] Sigurbjörnsson B, R Van Zwol. Flickr tag recommendation based on collective knowledge[C]//Proceedings of the 17th international conference on World Wide Web, 2008. [12] Durao F, P Dolog. A personalized tag-based recommendation in social web systems[C]//Proceedings of the arXiv preprint arXiv:1203.0332, 2012. [13] Lappas T, K Punera, T Sarlos. Mining tags using social endorsement networks[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, 2011. [14] 陈渊, 林磊, 孙承杰, 刘秉权. 一种面向微博用户的标签推荐方法[J]. 智能计算机与应用, 2011, 1(3): 21-26. [15] 汪祥, 贾焰, 周斌, 陈儒华, 韩毅 基于交互关系的微博用户标签预测[J]. 计算机工程与科学, 2013, 35(10): 44-50. [16] Yamaguchi Y, T Amagasa, H Kitagawa. Tag-based user topic discovery using twitter lists[C]//Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), 2011 International Conference on. 2011. [17] Wu W, B Zhang, M Ostendorf. Automatic generation of personalized annotation tags for Twitter users[C]//Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics: Los Angeles, California. 2010: 689-692. [18] Mihalcea R, P Tarau. TextRank: Bringing order into texts[C]//Proceedings of EMNLP, 2004. [19] 涂存超, 刘知远, 孙茂松. 社会媒体用户标签的分析与推荐[J]. 图书情报工作,2013, 57(23): 24-30, 35. [20] Zhang M, N Hurley. Avoiding monotony: improving the diversity of recommendation lists[C]//Proceedings of the 2008 ACM conference on Recommender systems, 2008. [21] Smyth B, P McClave. Similarity vs. diversity, in Case-Based Reasoning Research and Development[C]//Proceedings of the Springer, 2001,2080: 347-361. [22] Bradley K, B Smyth. Improving recommendation diversity[C]//Proceedings of the Twelfth National Conference in Artificial Intelligence and Cognitive Science, 2001. User Tag Recommendation with Personalization and Diversity ZHUAN Yue1,2, XIONG Jinhua1,2, CHENG Xueqi1,2 (1. CAS Key Laboratory of Network Data Science and Technology, Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100190, China;2. University of Chinese Academy of Sciences, Beijing 100190, China) To take full advantage of user’s social characteristics and address the diversity of tag recommendation, we present a method for user tag recommendation, aiming to combine user’s social characteristics and the diversity of tag recommendation. We use topic model to get a user’s potential semantic topics from his tweets, and then cluster the users followed by this user, i.e. using the potential semantic topics to divide the users into different areas. Each area can reflect the interest that attracts the user to follow. We select several representative tags by sorting the tags in the area based on TF-IDF. Then, we combine and sort different areas of representative tags to get top-K tags for recommendation. Experiment shows that our approach not only can recommend diversity tags but also reflect the user’s interest and hobbies. user tag recommendation; recommendation diversity; tag redundancy; tag quality 颛悦(1988—),硕士,主要研究领域为自然语言处理。E⁃mail:zhuan_yue@163.com熊锦华(1972—),通信作者,博士,副研究员,主要研究领域为互联网搜索与挖掘、大规模数据处理、分布式计算。E⁃mail:xjh@ict.ac.cn程学旗(1971—),博士,研究员,博士生导师,主要研究领域为网络科学、网络与信息安全、互联网搜索与服务。E⁃mail:cxq@ict.ac.cn 2014-06-25 定稿日期: 2014-09-22 863项目(2014AA015204);国家自然科学基金(61402442);973项目(2014CB340406) 1003-0077(2017)02-0154-09 TP391 A

4 实验及结果分析




5 结论

猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
文苑(2020年4期)2020-05-30
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
汽车与新动力(2016年6期)2017-01-04
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
