
新浪微博隐式组织发现
2017-06-01 11:29刘程,沙灜,姜波,郭莉
中文信息学报 2017年2期
刘 程,沙 灜,姜 波,郭 莉
(中国科学院 信息工程研究所,北京 100093)
新浪微博隐式组织发现
刘 程,沙 灜,姜 波,郭 莉
(中国科学院 信息工程研究所,北京 100093)
社交网络中往往同时存在多种类型的账号,如正常个体用户、水军、僵尸粉、蓝V组织等。我们把其行为呈现为组织特性的个体账号,定义为隐式组织。隐式组织通常背后有相应的组织团队负责账号的运营,因此其行为模式呈现为组织的行为模式,有别于个体账号。隐式组织的有效发现对于社交网络中舆情传播趋势分析、广告推荐等都有重要的意义。该文以新浪微博数据为例,在数据采集系统基础上,共人工标注了583个账号,提取了22个特征,使用朴素贝叶斯和决策树算法,实现了对隐式组织的有效识别,其准确率达86.4%,并分析得出了特征的重要程度排序。实验证明了社交网络中存在隐式组织,其行为特征是可以识别的。
社交网络;隐式组织;机器学习算法
1 引言
随着社交网络的普及,社交网络中的信息传播和舆论导向作用越来越突出。这也吸引了大批人员来研究社交网络中的信息传播、网络拓扑、热点预测等方面的内容。
为了准确地研究社交网络中的内容,首先要对社交网络中的个体和组织进行有效的区分。社交网络中的个体是指以个人作为社交网络中的一个用户。社交网络中的组织是指以团体或集体作为社交网络中的一个用户,例如公司、机构等团体。在行为上社交网络中的个体用户和组织用户具有明显的差异,例如,组织用户发布的信息重点在于宣传,而个体用户发布的信息则侧重于个人观点、心情等。只有实现对个体和组织的有效识别,才能够实现后续的准确分析与预测,如关键人物的发现与跟踪、社区的发现、热点话题传播趋势分析等。
当前对个体和组织的定义,主要集中在社会学领域,通常认为: “组织是指一些在共同目标指导下协同工作的粒子所组成的集合”。社交网络通常看作物理社会在互联网上的映射,因此用户同样可以分为个体和组织。例如: 著名主持人何炅的新浪微博账号,就可以看作一个个体。而那些具有蓝色大V标识的,例如新浪财经,则明显可以看作一个组织(图1)。

图1 个体和组织
但是我们发现,还有一类账号,虽然标识为个体账号,但是其行为特征与组织基本一致,同样以新浪微博账号为例,例如: 时尚熊熊杂志、家居装修等就具有这样的典型特点。图2是组织与隐式组织的微博截图。图2(a)是典型的组织账号——新浪财经和互联网数据中心。从中可以发现组织账号通常由多人参与维护,信息量大,微博内容能够体现该组织的目的,体现出组织正规性,其微博往往具有较为固定的格式,博文内容也比较正式、丰富,比较令人信服。从图2可以发现其博文常含有标题、链接等特征,相对较长,发帖较频繁,间隔时间也比较均匀。图2(b)为典型的隐式组织账号——家居装修,是一个没有蓝V标识的个体账号,但是特征与组织极为相似。微博通常具有固定的格式,含有标题、链接等。其博文内容也比较正式,博文较长,发帖较频繁,间隔时间也比较均匀。本文将这样的用户定义为隐式组织。

图2 组织和隐式组织微博
定义: 社交网络中隐式组织是未带有社交网站公开的组织标识,由多人参与维护、存在其共同目的呈现组织行为特征的社交网络账户。
隐式组织为了扩大影响,他们同有标识的组织一样具有参与热点话题的欲望,对信息的传播往往起到促进作用,这种促进作用相对于有标识的组织是很隐蔽的,而且隐式组织又不像意见领袖那样引人注目。所以实现对隐式组织的有效识别对于社交网络中舆情传播趋势分析、广告推荐等都有重要的意义。
本文以新浪微博为例实现对隐式组织的有效识别。我们采集了2013年上半年的数据,去除组织和原创微博数量小于20的用户,共标注了583个用户,其中有523个个体和60个隐式组织。经分析找出了文本特性、交互特性、时间特性三类特征,共22个,其中以三个主要特征为基础,筛选出50组特征组合。共有10个训练集和对应的测试集,每个训练集由随机选取的100个个体和30个隐式组织组成,对应测试集则在剩余的用户集中采用相同方式选取。将WEKA中决策树算法(J48)和朴素贝叶斯算法,依据每组特征组合,分别进行分类实验,取10次结果的平均值,作为该组合的最终实验结果,其中朴素贝叶斯算法识别隐式组织的准确率可达到86.4%。
本文的主要贡献为:
(1) 提出社交网络隐式组织的定义;
(2) 以新浪微博为例共提取了三类22个特征,实现对隐式组织的有效发现,准确率达86.4%;
(3) 对隐式组织的行为特征等属性进行了分析,发现博文长度、发帖时间间隔对个体与隐式组织有较好的区分度。
2 相关工作
国内外对个体、组织的研究主要出现在生物学和社会学领域。目前对社交网络中个体、组织的研究相对较少,已有相关工作主要集中在水军、Spammer和僵尸粉检测方面。下面主要介绍现有的个体、组织等相关概念的定义;社交网络中水军、Spammer、僵尸粉的检测研究等。
1) 个体、组织(群体)的相关定义
许永峰提出: “组织是指一些在共同目标指导下协同工作的粒子所组成的集合”[1]。陈世明在研究群体行为时,提到群体系统的概念: “群体系统指的是由彼此之间以某种关系耦合在一起的大量个体组成的系统”[2]。于显洋以社会学角度给出了群体的定义: “群体是为实现共同目标的两个以上保持持续性相互依赖、相互作用的个体的组合”[3]。
综上所述,组织或群体的必要特征有: (1)要有多人参与,(2)要有共同目标。只有满足这两个条件,才可以构成组织或群体。
当代汉语词典中解释个体: 单个的人或生物[4]。中国考试大辞典中解释: 个体指构成总体的每一个对象或基本单位[5]。因研究任务及性质不同,个体既可指单个的人、事、物,也可指以群体为基本单位的一个个研究对象。
社交网络作为物理世界中人类社会关系在互联网上的映射,其也应该可以分为个体和组织。其组织也应该具有上述的两个必要特征。
2) Spammer及水军识别
Chen[6]提出了识别水军的四个非语义和一个语义特征,包括: 回复比、平均间隔时间、活跃天数、新闻报道数、帖子相似度。实验方法使用LIBSVM、径向基函数和十折交叉验证训练新浪数据,搜狐数据做测试集,人工标注数据集类别。实验得出: 语义特征有很好的辅助作用,但并不能完全依赖语义特征;非语义特征也非常有效,起到支柱作用。
Lin[7]基于汉语对Spam进行识别,收集了2012年7月4日到10日的4 827条正常用户的微博,1979条Spam微博。针对中文社交网络,选取的特征有词汇特征、状态特征和用户特征,采用朴素贝叶斯、支持向量机(SVM)和Logistic Regression进行分类,实验效果为: 朴素贝叶斯错误率7%,SVM错误率5.25%,Logistic Regression错误率6.5%。
Benevenuto[8]针对国外社交网络Twitter进行Spammer识别研究。采集到54 981 152个活跃用户,1 963 263 821个关系和1 755 925 520条推文。采用支持向量机,有约70%的Spamers用户正确识别,96%的非Spamers被正确识别。共提取了62个特征,如表1所示。

表1 特征信息表
McCord[9]使用传统分类器识别Twitter上的Spam,共选用六个特征,正确率达88%左右。Gianvecchio[10]研究在网络聊天室识别机器人,他们将机器人按简单到复杂分成16类,方法上在传统基础上做了改进,实验效果比传统方法更准确。Veloso[11]研究了基于文本的Spam检测,先用一种模式发现算法发现模式,然后用发现的模式训练分类算法,识别准确率达99%。国内外对Spammer、网络水军及僵尸粉的检测研究很多,都取得了较好的成绩[12-16]。
综上所述,目前社交网络用户分类通常可以分成两个步骤: 特征提取、分类方法。特征主要采用文本特征和profile特征等。分类方法大多采用传统的机器学习分类方法。
3 社交网络隐式组织发现
我们基本研究思路如下: 首先给出社交网络中隐式组织的定义;然后从内容、行为等属性中提取相关特征,基于新浪微博数据集,通过人工标注构建训练集和测试集;通过贝叶斯和决策树分类方法实现对个体与隐式组织有效分类;最后对实验结果进行分析。
3.1 社交网络隐式组织
通过引言中隐式组织的定义,我们知道,社交网络隐式组织是,未带有社交网站公开的组织标识,由多人参与维护、存在其共同目的的社交网络账户。以新浪微博为例(图3),组织用户带有公开的组织标识——蓝V,指以团体或集体作为社交网络中的一个用户,例如公司、机构等团体。而标识为名人、达人和普通用户的,则可能是个体也可能是隐式组织。

图3 新浪微博标识与用户对应图
经过在国内外不同的社交网站上进行调研,可以发现个体和隐式组织用户在文本和行为等方面的不同特征,如表2所示。

表2 个体和隐式组织特征对比表
3.2 特征选取与数据集人工标注
根据个体和隐式组织的不同特点,将数据集标注为两类: 个体和隐式组织。每一个用户由三个人标,选被标类别较多的为待标用户最终类别,以此来解决标注分歧。实验采用了2013年新浪微博上半年的数据作为标注数据集。共采用了514 585条微博,3 678个用户,除去组织用户和原创微博数小于20的用户,共标注了个体523个,隐式组织60个。
最终确定了文本特性、交互特性、时间特性三类共22个特征。如表3所示。

表3 特征说明表
在文本特性中,组织用户需要有相对固定的格式表现内容的可靠性,加上微博的短文本特性,使得组织用户的博文size较大,并常常附上url,以便使浏览者更详细地了解信息;相对应的个体用户比组织用户的微博更灵活、随意,博文意图往往是表露心情,而表情符号是常用的表示心情的快捷方法,所以emotion(带有表情的博文所占比例)特征偏多于组织用户。在交互特性中,四个特征均一定程度地体现出用户与他人交互的意愿,个体略高于组织用户,其中reply区别较为明显。在时间特性中,组织账号是由指定的某个现实中的人或多人维护的,故组织的interval_minute和meanblog要比大多数个体用户高,variance比多数个体用户低。
3.3 隐式组织分类
使用WEKA中的分类方法。通过对22个特征进行分析,我们以size、reply、interval_minute三个特征为主,共筛出50组特征组合。训练集由随机选取的100个个体和30个隐式组织组成,对应的测试集在剩余的数据集中随机选取100个个体和30个隐式组织,共随机选取十组。用朴素贝叶斯和决策树算法在10组训练集和测试集、50组特征组合上进行分类,取平均值作为实验结果。根据结果的Kappa statistic值对特征组合进行排序,并得出特征重要程度排序。
4 实验结果及分析
4.1 实验结果
Kappa statistic用于评判分类器的分类结果与随机分类的差异度,是各方面的综合衡量指标,因此本文选用Kappa statistic值对结果进行排序。由于篇幅的限制,实验结果不一一列出了。以下是两种方法最佳的实验结果。
实验一 实验方法采用J48算法,特征组合: size,reply,at,interval_minute。该实验的Kappa statistic 平均值为0.6654,是J48算法排序第一的组合。

表4 实验一分类结果

表5 实验一评价表
实验二 实验方法仍使用J48算法,特征组合: topic, combine_title, size, reply, topic_forward, combine_title_forward, combine_url_forward。该组和是J48算法正确率最高的特征组合。

表6 实验二分类结果

表7 实验二评价表
实验三 实验方法使用朴素贝叶斯算法,特征数: 12,特征组合: title_topic, meanblog, variance, interval_minute, topic_forward, url_forward, combine_url, combine_url_forward, size, title, topic, forwardcomments。该实验的正确率和Kappa statistic在两种方法的所有组合实验中最高,其中Kappa statistic达0.7102。

表8 实验三分类结果

表9 实验三评价表
我们依据50组特征组合实验,选出Kappa statistic值大于0.5的特征组合,给每个特征打分,所得分数是出现的次数,未出现的特征分数为0,分数高说明该特征对个体和隐式组织的区分程度越好。据此规则,得出前10个特征排序表,如表10所示。

表10 特征排序表
该表与上节的特征分析基本吻合,证明了size、interval_minute对个体与隐式组织有较高的区分度。表中1、3、4、5、8、9都属于文本特性,说明其是识别隐式组织的主要特征;其次时间特性interval_minute、meanblog以及交互特性reply、forwardcomments也非常有效;而3~9之间特征的重要度都差不多,说明这些特征之间有一定的相关性。
4.2 实验结果讨论
本实验中,J48算法受特征的影响较大,四个特征已经能够达到很好的效果,随着特征的增加,效果反而变差,可能原因是存在冲突的特征。朴素贝叶斯算法好于决策树算法,受特征影响相对较小,但特征并没有显示出单调递增、越多越准确的特性,可能特征间有依赖,影响实验结果。实验中个体正确率、准确率等各项评价指标都比较高,而隐式组织的准确率并不高,可能是因为测试集个体和隐式组织数量不均衡导致的。
对于SVM分类器: 由于训练样本数量上的不均衡[17],以及样本中可能含有噪声和孤立点[18],导致使用SVM分类时效果较差,表11是21个特征组合的分类结果,其Kappa statistic值为0.2949。
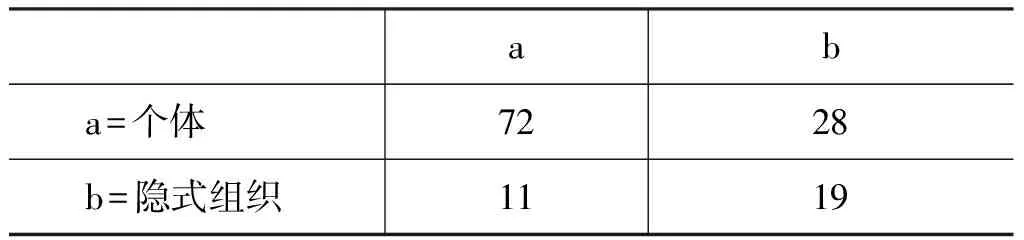
表11 SVM分类结果
SVM对隐式组织识别的准确率为40.4%。考虑到后续研究是面向大规模社交网络数据进行快速的分类,因SVM占用内存较多、速度慢,前期实验结果不理想,所以没有将SVM加入到对比实验中。
特征排序体现了特征重要程度的大致分布。我们选了特征排序在第一的size、第二interval_minute进行散点图展示,图上每个点代表一个用户,横坐标是用户的编号,纵坐标是用户的特征值,黑色的点代表该用户是个体,同理,灰色是隐式组织。
图4(a)是个体与隐式组织的size对比图,很明显隐式组织的size中心点比个体的中心点要高;图4(b)中隐式组织interval_minute都比较集中在很低的值上,说明隐式组织的发帖一般都比较频繁,而个体则相对时间间隔较长。可见我们的特征排序表能够体现出特征的重要程度。

图4 个体与隐式组织的特征对比
5 结论
本文首次提出了隐式组织概念,阐述了隐式组织的特点,并对其进行识别。实验使用朴素贝叶斯算法和J48算法进行比较,多种评价指标显示朴素贝叶斯算法表现更好,识别隐式组织准确率可达86.4%,识别个体的准确率也达到89.8%。实验结果证明,隐式组织和个体用户确实存在差别,利用传统分类方法即可识别出隐式组织,但准确率还有待提升。通过特征分析得出: 任何单个的特征不能够将隐式组织识别出来。下一步工作需进一步提高标注数据集的规模,考虑社交网络结构因素,提高隐式组织识别的准确率。
[1] 许永峰, 张书玲.带组织的粒子群优化算法: OPSO[J].计算机应用与软件, 2008: 25(2): 234-236.
[2] 陈世明.基于局部信息的若干群体行为研究[D].华中科技大学博士学位论文, 2006.
[3] 于显洋.组织社会学[M].北京: 中国人民大学出版社,2004: 162-172.
[4] 莫衡. 当代汉语词典[M]. 上海: 上海辞书出版社, 2001: 1-1605.
[5] 杨学为. 中国考试大辞典[M]. 上海: 上海辞书出版社, 2006: 1-506.
[6] Chen C, Wu K, Srinivasan V, et al. Battling the internet water army: Detection of hidden paid posters[C]//Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. ACM, 2013: 116-120.
[7] Liu L, Jia K. Detecting spam in chinese microblogs-a study on sina weibo[C]//Proceedings of Computational Intelligence and Security (CIS), 2012 Eighth International Conference on IEEE, 2012: 578-581.
[8] Benevenuto F, Magno G, Rodrigues T, et al. Detecting spammers on twitter[C]//Proceedings of Collaboration, electronic messaging, anti-abuse and spam conference (CEAS). 2010, 6: 12.
[9] McCord M, Chuah M. Spam detection on twitter using traditional classifiers[M].Autonomic and Trusted Computing. Springer Berlin Heidelberg, 2011: 175-186.
[10] Gianvecchio S, Xie M, Wu Z, et al. Humans and bots in internet chat: measurement, analysis, and automated classification[J]. IEEE/ACM Transactions on Networking (TON), 2011, 19(5): 1557-1571.
[11] Veloso A, Meira W. Lazy associative classification for content-based spam detection[C]//Proceedings of Web Congress, 2006. LA-Web'06. Fourth Latin American. IEEE, 2006: 154-161.
[12] Wang A H. Don't follow me: Spam detection in twitter[C]//Proceedings of the 2010 International Conference on IEEE, 2010: 1-10.
[13] de Lima B V A, Machado V P. Machine learning algorithms applied in automatic classification of social network users[C]//Proceedings of CASoN. 2012: 58-62.
[14] Stringhini G, Kruegel C, Vigna G. Detecting spammers on social networks[C]//Proceedings of the 26th Annual Computer Security Applications Conference. ACM, 2010: 1-9.
[15] Costa H, Benevenuto F, Merschmann L H C. Detecting tip spam in location-based social networks[C]//Proceedings of the 28th Annual ACM Symposium on Applied Computing. ACM, 2013: 724-729.
[16] 王越, 张剑金, 刘芳芳. 一种多特征微博僵尸粉检测方法与实现[J]. 中国科技论文, 2014, 9(1): 81-86.
[17] 刁翠霞, 陈思凤, 刘业政. 基于SVM 求解不均衡数据集分类的主观权重约束方法[J]. 管理工程学报, 2012, 26(3): 146-150.
[18] 安金龙. 支持向量机若干问题的研究[D].天津大学博士学位论文, 2004.
Detecting Implicit Organization on Sina Weibo
LIU Cheng, SHA Ying , JIANG Bo, Guo Li
(Institute of Information Engineering, CAS, Beijing 100093, China)
Various types of account tend to be existed in Social network, including normal individual users, online water army, zombie fans, official organizations and so on. We define the individual accounts whose behavior is rendered as organizational characteristic as impli-cit organization. With a team responsible for the operations, the impli-cit organization account bears no individuals' behavior pattern, but falls in the pattern of an official organization. The effective discovery of implicit organizations have important significance for analysis of public opinion trends in the spread of social networks, advertising recommendations and so on. This paper, taking the data of SinaWeibo as an example, investigates the classification of the individuals and the implicit organizations. We manually labeled a total of 583 accounts, and summarizing 22 related features to build a Naive Bayes model and a decision tree model. Experiments demonstrate an effective identification of implicit organization by 86.4% precision.
social network; implicit organization; machine learning algorithm

刘程(1988—),硕士研究生,主要研究领域为社会计算。E⁃mail:liucheng4248@163.com沙灜(1973—),通信作者,副研究员,主要研究领域为社会计算。E⁃mail:shaying@iie.ac.cn姜波(1985—),博士研究生,主要研究领域为社会计算。E⁃mail:jiangbo@iie.ac.cn
2015-03-11 定稿日期: 2015-06-19
中国科学院院战略先导专项(XDA06030200);国家科技支撑计划(2012BAH46B03);国家自然科学基金(61272427)
1003-0077(2017)02-0139-07
TP391
A
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
派出所工作(2021年4期)2021-05-17
法律方法(2021年4期)2021-03-16
劳动保护(2019年7期)2019-08-27
福建基础教育研究(2019年11期)2019-05-28
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
CHIP新电脑(2016年3期)2016-03-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中学科技(2015年1期)2015-04-28
