
利用框架语义知识优化事件抽取
2017-06-01 11:29陈亚东王潇斌杨雪蓉姚建民朱巧明
中文信息学报 2017年2期
陈亚东,洪 宇,王潇斌,杨雪蓉,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
利用框架语义知识优化事件抽取
陈亚东,洪 宇,王潇斌,杨雪蓉,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理重点实验室,江苏 苏州 215006)
事件抽取旨在把含有事件信息的非结构化文本以结构化的形式予以呈现。现有的基于监督学习的事件抽取方法往往受限于数据稀疏和分布不平衡问题,具有较低的召回率。针对这一问题,该文提出一种利用框架语义优化事件抽取的方法,引入框架类型作为泛化特征,在此基础上进行框架类型和事件类型的映射,然后结合框架类型识别模型和事件类型识别模型进行协作判定,以此优化事件抽取的召回性能。实验结果显示,针对触发词(事件类型)识别任务,相较于仅使用事件类型识别模型,该文提出的框架语义辅助的事件类型识别模型能够提高抽取召回率6.44%(5.74%),提高F值1.45%(0.83%)。
事件抽取;信息抽取;框架语义
1 引言
事件是一种描述特定人、物、事在特定时间和特定地点相互作用的客观事实。事件抽取(event extraction)作为信息抽取的一个重要研究方向,旨在从自由文本中自动识别出事件信息,并以结构化的形式予以呈现。根据ACE(automatic content extraction)事件抽取的任务定义,事件抽取包含四个子任务: 触发词识别(trigger identification)、事件类型识别(event type determination)、事件元素识别(argument identification)和事件角色识别(argument role determination)。图1中给出了一个完整事件结构表述,其中,“射杀”是该事件的触发词,所触发的事件类型为Die。事件的三个组成元素“60岁的默罕默德”、“加巴利亚难民营附近的家中”和“火箭弹”分别对应Die事件模板的三个元素标签,即“Victim”、“Place”和“Instrument”。
现有的基于监督学习的事件抽取方法,往往受限于数据稀疏和分布不平衡问题,具有较低的召回率。原因在于,英文事件抽取语料的样本数目较少,仅有3 966条句子级的事件描述,且事件类别样例分布存在不平衡的问题。例如,ACE中事件类型共有33种,其中,事件类型为Attack的样例数目为1 537,占总样例数的28.76%,而事件类型为Nominate和Extradite的样例数分别只有12和7,占总样例数的0.22%和0.13%。事件类别样例数目过少和样例分布不平衡的问题,往往导致机器学习模型的训练出现偏差。比如,学习模型在样本稀疏的事件类型上训练不充分,难以有效识别相关事件,或者,学习模型始终倾向于判别样本数较多的事件类型,形成偏见。这类偏差直接负面影响基于监督学习的事件抽取性能。
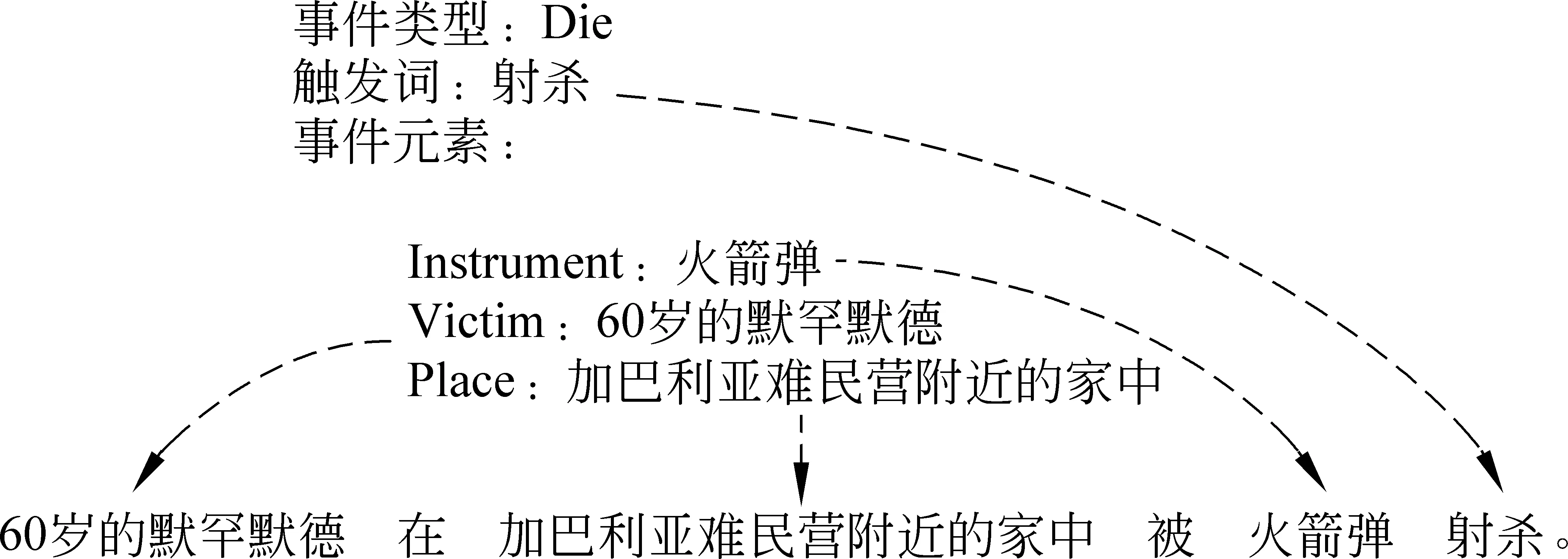
图1 “Die”事件实例的基本组成要素
针对上述问题,本文提出利用框架语义知识辅助事件抽取的方法。其中,框架语义表征一种场景的语义抽象,其将一类功能、状态和关系具有一致性的词汇进行归类与抽象。目前,以框架语义学为基础形成的权威知识库是FrameNet[1],其区别于现有的WordNet[2]、HowNet[3]和Wikipedia[4]等知识库,更侧重依据场景的语义对词项进行划分和归类,而非纯粹依据同义、反义或上下位关系构造词类的知识体系。比如,FrameNet将“汽车”、“轮船”和“航天飞机”归为一类,并标定为“交通工具”这一语义框架,表征“承载物体的运输装置”这样一种场景。根据FrameNet的定义,框架(Frame)可以描述一种表示事件、状态、实体或者关系的场景。利用框架语义辅助事件抽取的优势表现在如下两个方面。
1. 框架语义分析中的框架类型与事件抽取中的事件类型具有强烈的映射关系。例如,Invading(表示“入侵”这一场景)、Hit_target(击中目标)、Attack(攻击)、Fighting_activity(打击的动作)等框架可以描述Attack事件;Arrest(逮捕)、Imprisonment(监禁)框架可以描述Arrest-Jail事件; Birth(生日)和Being-born(出生)框架可以描述Be-Born事件。从以上例子中可以看出,框架类型与事件类型具有很强的相似性,本文对FrameNet中的1 019种框架进行人工划分,发现有546种框架可以描述事件,说明利用框架描述事件具有可行性。
2. 框架语义知识库FrameNet的数据规模更大,由此利用FrameNet训练框架类别识别模型,并利用这一模型对事件抽取语料进行自动标注,可额外获得标注样本的框架类型信息。数据规模上,FrameNet包含157 631条包含框架类型的例句,而事件抽取语料仅有3 966条句子级的事件描述。
下面通过例句1说明如何有效利用FrameNet的优势(包括上述事件类型的平行映射和更为丰富的样本知识)提高面向事件抽取的机器学习:
例1CoalitionfighterjetspummeledthisIraqipositiononthehillsaboveChamchamal.*来源于ACE2005语料库中的文件“CNN_IP_20030329.1600.02”。
(译文: “联合国的战斗机打击位于恰姆恰马勒山上的伊拉克据点”)
触发词→pummeled
对应事件类型“Attack”:pummeled→Attack
对应框架类型“Cause_harm”:pummeled→Cause_harm
例1中,触发词“pummeled”(译文: “打击”)表示的事件类型为Attack,但“pummeled”在ACE事件抽取语料中仅出现一次,一旦作为测试样本出现,则针对该触发词的训练样本数为0。在实验中如果对例1进行触发词识别,现有基于监督学习的事件抽取方法往往会将“pummeled”标为非触发词。换言之,训练语料中缺少“pummeled”作为触发词出现的实例及相应的上下文环境,使得训练过程面临“巧妇无米”的窘境。相对地,在FrameNet中,“pummeled”触发框架类型Cause_harm的例句有10句,训练样本充分,从而使利用FrameNet训练的框架类别识别模型往往可以准确地将例1中的“pummeled”判别为Cause_harm框架类型。那么,如果存在一种先验的映射知识,使得框架类型“Cause_harm”与事件类型“Attack”的一一对应关系成为已知条件,则事件抽取系统可借由这一对应关系,有效判别出“pummeled”是“Attack”事件的触发词。而框架类型与事件类型的映射关系,可通过两者蕴含的共同词项这一桥梁,予以概率计算与关联判定。比如,在事件抽取语料中,触发Attack事件的词项包括“strike”、“punch”、“beat”、“stab”、“kick”,而这类词在FrameNet中隶属于框架类型Cause_harm,借助这类词项反映出的框架和事件类型的共性,可将Cause_harm与Attack以较高的概率建立映射,并以此支持上述“pummeled”的事件类型判定。
由此,本文提出一种利用框架语义知识辅助事件抽取的方法,该方法首先利用FrameNet训练得到的框架类型识别模型对事件抽取语料进行标注,然后将得到的待测词的框架类型作为泛化特征,加入到事件识别模型中的特征集合中,在此基础上,再将框架类型映射到事件类型,最后利用事件识别模型和框架识别模型进行协作判定。经过10倍交叉验证的实验结果显示,触发词识别和事件类型识别的性能分别达到67.81%和65.39%,优于仅使用事件识别模型系统达1.45%和0.83%。
2 相关工作
2.1 基于监督学习的事件抽取
Grishman等[5]将事件抽取任务分为三个模块: 事件类型识别模块、元素识别模块和角色识别模块,然后用最大熵模型分别对以上三个模块进行训练,接着整合三个模块,根据各个模块的输出结果联合抽取句子中的事件。Ahn等[6]针对事件类型识别和事件角色识别任务,整合MegaM和Timbl两种机器学习方法,首先使用MegaM分类器对当前词进行二元分类来判断其是否是触发词,然后使用多元分类器Timbl指定当前词所属的事件类别,并对每一种事件训练一个分类模型,用于确定事件元素的角色。Chen等[7]将事件类型识别和角色识别看作序列标注问题,采用最大熵隐马尔科夫模型(maximun entropy hidden markov model, MEMM)识别出句子中的触发词类型和角色类型。Chen等[8]针对中文事件抽取,使用两个联合模型,分别将事件触发词识别和类型识别,以及事件元素识别和角色识别作为两个整体任务,进而防止错误传递的情况。 Li等[9]针对中文事件抽取存在大量未登录触发词问题,提出一个结合中文词语的形态结构和原义去推测未知触发词的方法,旨在提高中文事件抽取系统的召回率。Li等[10]采用基于结构化感知机的联合模型,将事件类型识别和事件角色识别看作一个任务,分析并检验了多种局部和全局特征,达到目前事件抽取性能的最高值。
2.2 基于直推式方法的事件抽取
基于直推式方法的核心思想是根据已知实例的信息推断同类型实例中的未知属性信息,现有工作主要包含跨句子(cross-sentence)、跨事件(cross-event)、跨篇章(cross-document)和跨实体(cross-entity)事件抽取。Ji等[11]沿用Yarowsky[2]的“单片断单语义”假设,将事件抽取的范围从单文档引申到话题相关的文档集合中,并且使用基于规则的方法,解决了跨句子和跨文档的触发词分类问题,将全局信息与局部信息相结合,在事件类型分类和事件元素识别中都获得了较大的性能提升。Liao等[12]提出了文档级别的跨事件推理方法,充分利用了相关事件的内容信息和事件类型一致性等特征,在事件预测和解决事件歧义性方面起到了很好的效果。Hong等[13]提出利用跨实体推理进行事件抽取的方法,其核心是充分利用实体类型的一致性特征,进一步提升了事件抽取的性能。
3 基于框架语义知识的事件抽取方法
本文工作集中于事件抽取的前两个任务: 触发词识别和事件类型识别。图2给出了利用框架语义知识辅助事件抽取的系统框架图,共包含如下三个主要模块: 框架类型识别模块,事件类型识别模块,协作判定事件类型模块。其中,框架类型识别模块利用由FrameNet语料训练得到的框架类型识别模型对事件抽取语料进行框架类型识别,其目的有两点: ①为事件类型识别模块提供待测触发词的框架类型作为泛化特征; ②为协作判定事件类型模块提供ACE训练集的框架类型标签,用于计算框架类型映射到事件类型的概率。事件类型识别模块旨在利用框架类型识别模块提供的待测触发词的框架类型作为泛化特征,对测试集进行初步的事件类型识别。协作判定事件类型模块旨在利用框架类型识别模块提供的事件抽取训练集的框架类型标签,计算框架类型映射到事件类型的概率,然后将事件类型识别模块无法识别但具有高映射概率的待测触发词的框架直接判定为相对应的事件,以此提高事件抽取的召回率。
3.1 框架类型识别模块
本文使用框架语义分析领域SEMAFOR*http://www.ark.cs.cmu.edu/SEMAFOR/开源工具实现框架类型识别模型,该框架类型识别模型由FrameNet中的157 631条例句训练得到,旨在从事件抽取语料中抽取包含框架语义信息的结构化

图2 基于框架语义知识的事件抽取系统框架图
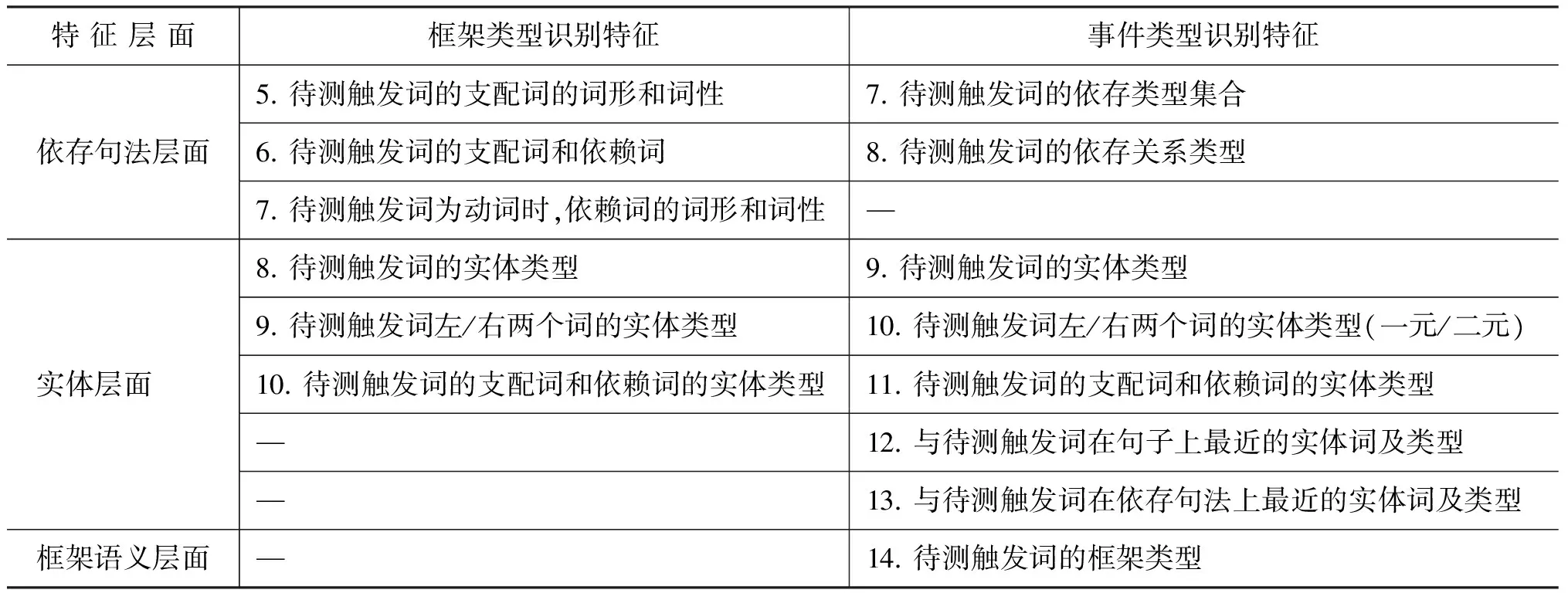
文本。如例2所示,框架类型识别模型可以抽取出待测触发词“people”、“wounded”、“Tuesday”和“airport”的框架类型分别为People(描述“人”的实体类型框架)、Cause_harm(描述“造成伤害”的事件类型框架)、Calendirc_unit(描述日期的框架)和Buildings(描述建筑的实体类型框架)。此外,SEMAFOR中的框架类型识别模型所使用的分类模型是对数线性模型(log-linear model),对数线性模型具有实现简单、构建特征方便和分类精度较高的特点,其所使用的主要特征如表1所示,这些特征主要考察了待测触发词的词汇层面、依存句法层面及实体层面的特征。
例2 114people【People】werewounded【Cause_harm]inTuesday【Calendric_unit]nearPhilippinesairport【Buildings】.
(译文: “周二在菲律宾机场附近有114人受伤”)
3.2 事件类型识别模块
该模块在传统的事件抽取所使用特征的基础上,加入由框架类型识别模块提供的待测词的框架类型标签,以此提高事件抽取的性能。此外,该模块还为协作判定事件类型模块提供候选的事件类型,以便协作判定模块融合框架与事件的映射关系,进而提高事件抽取的召回率。本文将触发词识别和事件类型识别看作为一个整体任务,即通过事件类型识别模型赋予待测词事件类型,若事件类型不为空则认定该待测词是触发词。因此,触发词识别和事件类型识别任务共享特征集合,本文在Li[10]所采用的针对事件类型识别的特征集合的基础上,增加了框架语义层面的特征,即待测词的框架类型,并将该结果与Li的结果作对比。具体特征描述如表1所示。

表1 框架类型识别和事件类型识别的分类特征
续表
注: 单元格中的—表示特征为空。
本文采用最大熵模型*http://mallet.cs.umass.edu/(maximum entropy)作为分类器,高斯参数设为1.0。最大熵模型具有训练速度快和分类精度高的特点。事件类型识别模块主要考察待测触发词的词汇层面、依存句法层面、实体层面及框架语义层面的特征。该模块所使用的特征与框架类型识别模块使用的特征的不同之处主要用于提高召回率的三个泛化特征: ①待测触发词的同义词; ②待测触发词的Brown聚类表示; ③待测触发词的框架类型。其中,待测触发词的同义词特征取自WordNet中该词最常见意思的同义词集[14],例如“move”的最常见意思为“移动”,相对应的同义词集为“travel”、“go”、“move”和“locomote”。此外,本文通过NLTK开源工具训练ACE2005语料获得待测词的Brown聚类表示,长度取13、16和20,旨在提高事件抽取的召回率[15]。最后,本文着重考察框架语义特征作为泛化特征时的性能,只有当待测触发词触发表示事件、实体、状态或者关系的语义框架时,该待测触发词才拥有对应的框架。
3.3 协作判定事件类型模块
该模块联合框架类型识别模块和事件类型识别模块对待测触发词最终的事件类型进行协作判定,具体步骤为先通过框架类型识别模块提供的训练集的框架类型标签,计算框架类型映射到事件类型的概率,然后将事件类型识别模块无法识别但具有高映射概率的待测的框架直接判定为相对应的事件,主要包含如下两个主要工作: ①框架类型映射到事件类型的概率; ②基于高概率映射的事件获取。
3.3.1 框架类型映射到事件类型的概率
ACE定义的事件类型与FrameNet定义的框架类型具有很大的相似性和关联性,因此本文从框架语义的角度辅助事件抽取,即利用框架类型映射到事件类型。本文利用框架类型识别模块提供的具有框架类型和事件类型的训练集,通过计算框架类型和事件类型的共现概率来反映它们的关联性,如式(1)所示:

(1)
式(1)中Count(event,frame)表示事件抽取训练集中的待测触发词同时被标为事件类型event和框架类型frame的次数。相应地,Count(frame)表示待测触发词被标为框架类型frame的次数。Pro(event|frame)表示当前待测触发词框架类型为frame时,其所应对的事件类型为event的概率。
3.3.2 基于高概率映射的事件获取
本文通过计算待测触发词的框架类型映射到事件类型的概率,然后调参得到映射概率的阈值,将事件类型模块无法识别但映射概率高于阈值的框架直接判定为相对应的事件,以此提高事件抽取的召回率,具体流程如表2所示。

表2 基于高概率映射的事件获取流程

续表
4 实验
4.1 实验数据与评测方法
本文针对事件抽取中的触发词识别和事件类型识别任务,选取ACE2005(automatic content extraction 2005)的599篇英文事件抽取文档作为实验语料,共包含16 375条句子,其中有3 966句包含事件描述。为防止训练过拟合而采用10倍交叉验证的方法进行实验,即每次选取500篇作为训练集,剩余的99篇作为测试集。在3.1节框架类型识别模块中,通过SEMAFOR开源工具实现的框架类型识别模型是用FrameNet 1.5语料训练得到的,共包含157 631条包含框架描述的例句,覆盖845种语义框架。
在触发词识别任务中,系统的性能主要取决于被正确识别出的触发词的个数,即触发词识别任务仅考察待测触发词是否触发事件,而不考察待测触发词所触发的事件类型。事件类型识别任务要求触发词不仅被正确识别,并且要求触发词被赋予正确的事件类型。系统采用准确率(precision)、召回率(recall)及F值(F1-Measure)作为评价指标。
4.2 实验系统设置
为验证本文提出的将待测触发词的框架类型作为泛化特征加入到事件类型识别模块、协作判定事件类型方法对于事件抽取任务的有效性,以及选择最优特征子集的贡献程度。本文提出以下实验对比系统。
• Baseline: 使用3.2节的事件类型识别模型,但是特征中不包含待测触发词的框架类型特征;
• Frame_feature: 使用3.2节的将待测触发词的框架类型作为泛化特征的事件类型识别模型。
• Frame_combine: 融合Baseline系统和3.3节的协作判定事件类型模块,即在事件类型识别模块中不将待测触发词的框架类型作为泛化特征,但在后续的协作判定事件类型的方法中考察具有高映射概率的框架是否能正确映射到相应事件。
• Frame_feature_combine: 融合Frame_feature和3.3节的协作判定事件类型模块,即不仅将待测触发词的框架类型作为泛化特征加入到事件类型识别的特征集合中,而且还需通过后续的协作判定的方法确定待测触发词的事件类型。
• Frame_forward: 在Frame_feature系统的基础上,通过序列前向选择算法选择最优特征子集,以便更好地在特征层面上融合框架语义特征。
• Frame_forward_combine: 融合Frame_forward系统和3.3节的协作判定事件类型模块,即不仅考察最优特征子集的影响,而且还需通过后续的协作判定方法确定待测触发词的事件类型。
4.3 框架概率映射的阈值训练
为确定协作判定事件类型方法中框架映射到事件的概率阈值,进行如下阈值选择实验。如图3所示,横坐标表示映射概率的阈值(Threshold)范围从0.1到1.0(步长为0.1),纵坐标表示触发词识别和事件类型识别(F-value)的性能。当映射概率阈值取0.5时,触发词识别和事件类型识别的性能达到最高,分别为67.73%和65.27%。分析结果发现,当阈值取值过小时,部分框架所对应的事件歧义性较大或者对应的事件为空,如框架Delivery(“转移物体”场景)映射到事件TransPort、Transfer-Ownership、Be-Born、Phone-Write及事件为空的概率分别为0.12、0.08、0.04、0.04和0.72,此时若阈值取0.1,除去空事件后,框架Delivery对应的事件为Transport(“物体移动”事件),但是框架Delivery有0.72的概率无法映射到事件,如果以0.1为阈值,将框架Delivery映射到事件Transport进行协作判定时会引入较多的错误结果;而当阈值取值过大时,仅有少数框架能够映射到事件,例如框架Extradition(“引渡”场景)有0.68的概率映射到事件Extradite(“引渡”事件),若将阈值设为0.7则框架Extradition无法映射到事件。

图3 映射概率阈值选择
4.4 特征选择实验
为更好地在特征层面融合框架语义特征,本文使用序列前向选择算法(sequential forward selection,SFS)寻找最优特征子集。结果显示,在词汇层面特征中,只考虑词形特征时,F值达到52.83%。因此,该实验结果反映出词形特征在事件类型识别时具有良好的表征作用。在词形特征基础上进一步融合框架语义特征时,F值提高5.92%,说明待测触发词的框架类型与待测触发词的事件类型具有直接的关系。然后,特征子集继续融合待测触发词的依存关系类型,F值提高3.5%,反映出通过依存关系表征待测触发词具有良好的效果。接着,特征子集进一步融合Brown聚类特征,F值提高1.34%,说明Brown特征对目标词识别具有一定的泛化表征作用。特征子集继续融合待测触发词的同义词特征,F值提高1.24%,体现待测触发词的同义词具有良好的提高泛化能力的作用。最后,特征子集加入待测触发词的实体类型、词性及待测触发词在依存句法上最近的实体类型,特征子集的性能达到最高为66.04%。

表3 特征选择的实验结果

续表
4.5 测试结果与分析
本文针对触发词识别和事件类型识别的实验结果如表4所示,实验系统Frame_feature比Baseline的触发词识别和事件类型识别的性能分别高0.69%和0.66%,P值和R值也有相应的提高,说明了将待测触发词的框架类型作为泛化特征的有效性。原因在于,部分候选触发词如“pummel”(译文: “打击”)在ACE2005事件抽取语料中仅出现过一次,该样例在训练集中非常稀疏,传统的事件抽取模型容易将其判定为非触发词。但是,如果能预先获得其框架类型为Cause_harm(译文: “造成伤害”),而其他候选触发词“strike”、“punch”和“beat”等这类词隶属于Cause_harm。同时,这类词经常触发Attack事件类型,本文就能通过这类词反映出的框架和事件类型的共性,就可以在特征层面中推理出其事件类型也为Attack。为了进一步体现框架类型作为泛化特征时的作用,本文给出在事件类型识别模型中特征权重为前10的特征,如表5所示。结果显示在事件类型识别模型中特征权重排名前10的特征有6个是框架类型特征,例如特征“Frame=Killing”触发Die事件的特征权重达到1.91,说明该特征对区分Die事件的贡献程度很大。

表4 触发词识别和事件类型识别的实验结果

续表
(注:P: 准确率(Precision);R: 召回率(Recall);F: F1-Measure)

表5 事件类型识别模型Top10特征权重
实验系统Frame_combine相较于Frame_feature在触发词识别和事件类型识别的R值分别提高5.61%和4.8%,性能分别提高0.68%和0.05%,但P值分别下降7.92%和8.39%。该结果说明协作判定事件类型方法对于召回更多的触发词和事件类型具有良好的效果,但其识别的准确率也相应地降低。原因在于,协作判定事件类型方法的性能很大程度上取决于框架映射到事件概率阈值的选取,如果映射概率阈值过小,协作判定事件类型方法召回事件的歧义性就较大,而如果映射概率阈值过大,召回的事件数目又过少,例如4.3节提到的框架Delivery映射到TransPort的例子体现这一现象。因此,只能采取折中的方法,在允许识别准确率下降的一定范围内,尽可能地提高召回率,以便使总体的性能有所提高。
本文提出实验系统Frame_feature_combine,在Frame_feature的基础上融合Frame_combine,即先将待测触发词的框架类型作为泛化特征加入到事件类型识别系统的特征集合中,然后再进行协作判别,召回无法在特征层面识别出的待测事件。实验结果显示,实验系统Frame_feature_combine的触发词识别和框架类型识别的性能达到最高,分别为67.81%和65.39%,说明了融合框架类型作为泛化特征及协作判别的有效性。原因在于,若仅使用实验系统Frame_feature考察待测词的框架类型在特征层面的贡献程度,可能会因为特征空间较大而难以有效体现待测触发词的框架类型作为泛化特征的有效性。而利用协作判定方法中召回具有高映射概率的框架所对应的事件,可以在框架与事件的共现概率层面扩大框架类型对于整个事件抽取任务的贡献程度。因此,两者融合后实验系统的性能有了进一步的提高。最后,在实验系统Frame_forward的基础上进一步融合协作判定模型,触发词识别和事件类型识别的性能达到最高,分别为68.45%和66.15%,说明在优化特征子集的前提下,进一步联合协作判定事件类型模块,可以更好地提高事件类型识别的性能。
5 总结
本文针对现有的基于有监督的事件抽取方法受限于数据稀疏和分布不平衡问题,提出一种利用框架语义知识辅助事件抽取的方法,引入待测触发词的框架类型作为泛化特征,并联合协作判定事件类型方法召回具有高映射概率的框架所对应的事件。实验结果显示,相较于传统的事件类型识别模型的方法,本文提出的利用框架语义知识的方法使召回率有了较大提升,在最终的F值也有所提高。
然而,本文提出的利用框架语义知识的方法在准确率上有一定下降,原因在于,利用框架类型信息召回的事件触发词存在部分噪声。因此,未来工作将不仅考察框架和事件的共性,也应从框架元素和事件成员这一角度考察它们的共性,例如事件Attack中的事件成员Attacker(译文: “攻击者”)与框架Attack中的框架元素Assailant(译文: “攻击者”)存在对应关系,同时考虑框架之间存在的关系,以便减小利用框架类型信息召回事件触发词存在的噪声。
[1] Collin F. Baker, Charles J. Fillmore, John B. Lowe.The berkeley framenet project [C]//Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics(ACL), Montreal, Canada, 1998, 1: 86-90.
[2] George A. Miller. WordNet: a lexical database for English [J]. Communications of the ACM, 1995, 38(11): 39-41.
[3] Zhendong Dong, Qiang Dong. HowNet and the Computation of Meaning [M]. Singapore, World Scientific, 2006.
[4] Ludovic Denoyer, Patrick Gallinari. The wikipedia xml corpus[J]. Comparative Evaluation of XML Information Retrieval Systems, 2007, 4518: 12-19.
[5] Ralph Grishman, David Westbrook, Adam Meyers. NYU’s English ACE 2005 System Description[C]//Proceedings of ACE 2005 Evaluation Workshop, Gaithersburg, USA, 2005: 5-19.
[6] David Ahn. The stages of event extraction[C]//Proceedings of ACL 2006 Workshop on Annotating and Reasoning about Time and Events, Sydney, Australia, 2006: 1-8.
[7] Zhen Chen, Heng Ji. Language specific issue and feature exploration in Chinese event extraction[C]//Proceedings of the 2009 North American Chapter of the Association for Computational Linguistics(NAACL), Blouder, Colorado, 2009, Short Papers, 1: 209-212.
[8] Peifeng Li, Guodong Zhou. Employing Morphological Structures and Sememes for Chinese Event Extraction[C]//Proceedings of COLING 2012, Mumbai, India, 2012: 1619-1634
[9] Chen Chen, Vincent Ng. Joint modeling for Chinese event extraction with rich linguistic features[C]//Proceedings of COLING 2012, Mumbai, India, 2012: 529-544
[10] Qi Li, Heng Ji, Liang Huang. Joint Event Extraction via Structured Prediction with Global Features[C]//Proceedings of the 51th Annual Meeting of the Association for Computational Linguistics(ACL). Sofia, Bulgaria, 2013: 73-82.
[11] Heng Ji, Ralph Grishman. Refining Event Extraction through Cross-Document Inference[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics(ACL), Colunbus, USA, 2008: 254-262.
[12] Shasha Liao, Ralph Grishman. Using Document Level Cross-Event Inference to Improve Event Extraction[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics(ACL), Uppsala, Sweden, 2010: 789-797.
[13] Yu Hong, Jianfeng Zhang, Bin Ma, et al. Using cross-entity inference to improve event extraction[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics(ACL), Portland, USA, 2010, 1: 1127-1136.
[14] Lingling Meng, Runqing Huang, Junzhong Gu. A review of semantic similarity measures in wordnet[J]. International Journal of Hybrid Information Technology, 2013, 6(1): 1-12.
[15] Scott Miller, Jethran Guinness, Alex Zamanian. Name tagging with word clusters and discriminative training[C]//Proceedings of the 2004 North American Chapter of the Association for Computational Linguistics(NAACL), Boston, USA, 2004, 4: 337-342.
Event Extraction Optimization via Frame Semantic Knowledge
CHEN Yadong, HONG Yu, WANG Xiaobin, YANG Xuerong, YAO Jianmin, ZHU Qiaoming
(Provincial Key Laboratory of Computer Information Processing Technology,Soochow University, Suzhou, Jiangsu 215006, China)
Event extraction aims at detecting certain specified types of events that are mentioned in the source language data. Existing methods based on supervised learning often suffer from date sparseness and imbalanced distribution, producing low recall as a reuslt. In this paper, we investigate the frame semantic knowledge to improve event extraction. Taking the frame type as general feature and mapping the frames into events, we combine the event recognition model with the frame recognition model for a joint decision. Compared to the previous event recognition model, experiments show that this method achieves 6.44%(5.74%) gain in recall and 1.45%(0.83%) gain in F1 for the task of trigger (event) identification.
event extraction; information extraction; frame semantic

陈亚东(1990—),硕士研究生,主要研究领域为事件抽取和信息抽取。E⁃mail:chinachenyadong@gmail.com洪宇(1978—),博士,副教授,主要研究领域为话题检测、信息检索和信息抽取。E⁃mail:tianxianer@gmail.com王潇斌(1991—),硕士研究生,主要研究领域为实体关系抽取和信息抽取。E⁃mail:czwangxiaobin@gmail.com
2015-03-22 定稿日期: 2015-08-10
国家自然科学基金(61373097, 61272259, 61272260)
1003-0077(2017)02-0117-09
TP391
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
通信技术(2021年12期)2022-01-25
开放教育研究(2020年2期)2020-03-31
作文成功之路·小学版(2019年8期)2019-09-18
人大建设(2019年4期)2019-07-13
小学生学习指导(低年级)(2019年4期)2019-04-22
计算机应用与软件(2018年9期)2018-09-26
读者(2017年14期)2017-06-27
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
长江学术(2016年4期)2016-03-11
