
融合无监督特征的藏文分词方法研究
2017-06-01 11:29李亚超加羊吉何向真于洪志
中文信息学报 2017年2期
李亚超,加羊吉,江 静,何向真,于洪志
(西北民族大学 中国民族语言文字信息技术重点实验室,甘肃 兰州730030)
融合无监督特征的藏文分词方法研究
李亚超,加羊吉,江 静,何向真,于洪志
(西北民族大学 中国民族语言文字信息技术重点实验室,甘肃 兰州730030)
藏文分词是藏文信息处理的基础性关键问题,目前基于序列标注的藏文分词方法大都采用音节位置特征和类别特征等。该文从无标注语料中抽取边界熵特征、邻接变化数特征、无监督间隔标注等无监督特征,并将之融合到基于序列标注的分词系统中。从实验结果可以看出,与基线藏文分词系统相比,分词F值提高了0.97%,并且未登录词识别结果也有较大的提高。说明,该文从无标注数据中提取出的无监督特征较为有效,和有监督的分词模型融合到一起显著提高了基线分词系统的效果。
藏文;分词;序列标注
1 引言

藏文信息处理研究基础较为薄弱,分词研究大都是参考汉语的处理方法,结合藏文的实际情况,进行针对性的优化。藏文分词技术分类方法跟汉语分词技术分类方法基本相同,都可以分为基于规则方法和基于统计方法。基于规则方法需要词典支持,分词效果受词典影响很大,对未登录词和切分歧义处理能力较差,该研究时间长,研究成果也较为丰富。扎西次仁[2]发表的“一个人机互助的藏文分词和词登录系统的设计”可以看作是藏语分词研究开始的标志。陈玉忠[3]提出了一种基于格助词和连续特征的书面藏文自动分词方法,该分词方案结合了藏文的特点,在一定程度上解决了切分歧义和未登录词问题,是一种较为有效的基于语言规则的分词方法;祁坤钰[4]提出了一体化的藏语三级切分体系;才智杰[5]提出了基于规则的方法“还原法”,来处理藏文分词中紧缩词识别问题;羊毛卓玛、欧珠[6]提出了一种改进型的藏文分词交集型歧义消解方法。以上研究是针对藏语语言特征,借鉴汉语分词方法进行研究。
基于统计的藏文分词方法把分词问题看成序列标注问题,采用机器学习方法进行分类,最终得到分词结果。Liu[7]研究了基于分类模型的藏文数字识别,并且实现了基于序列标注的藏文分词方法[8]。史晓东[9]把基于隐马尔可夫模型的汉语分词系统Segtag移植到了藏文中,取得了91%的准确率。江涛[10]实验了基于条件随机场的藏文分词方法,该方法把藏文按照音节进行切分,采用条件随机场的机器学习方法进行标注,取得了很好的效果。李亚超、宗成庆等[11]实现了基于条件随机场的藏文分词系统,并提出了自己的藏文音节标注系统,该方法处理了紧缩词问题,并把紧缩词识别和分词统一到一个模型中,在已知的音节标注系统中取得了最好的分词效果。Li[12]在四字位的标注集下,分别实现了基于条件随机场模型,最大熵模型,最大间隔Markov模型的藏文分词系统,并对实验结果进行对比。经过实验证明,藏文分词同样可以采用基于序列标注的方法,并且可以取得较好的分词效果。
前期,也有不少学者采用统计特征进行藏文分词研究,但只是采用如频率、熵等简单统计信息,这时期的统计特征只是作为基于规则分词方法的辅助。目前,基于序列标注的藏文分词方法采用的特征较少,大都采用音节位置,标点符号等特征,针对通过从无标注语料中抽取特征来提高有监督分词效果的研究较少。
藏文分词经过了十多年的研究,取得了较多研究成果,但仍然存在许多问题需要解决,并没有形成一个成熟的分词方法或者是共享的分词系统可以使用,分词仍然是制约藏文信息处理的瓶颈问题。
本文结构安排如下: 第二部分详细介绍本文所采用的分词方法及分词特征选择,第三部分进行实验与分析,第四部分为全文的总结和下一步工作安排。
2 基于序列标注的藏文分词方法
2.1 藏文音节标注方法
基于序列标注的分词方法是汉语分词的主流方法,最新的藏文分词研究把该方法移植到藏文分词中,并取得了较好的效果。基于序列标注的藏文分词方法根据每个藏文音节在词中出现的位置,给予不同的标签,如图1所示。

图1 藏文分词标记示例
为了与文献[11]的分词效果进行对比,本文采用四音节位的标记集“BMES”。B、M、E、S分别代表词的左边界、中间部分、右边界和单音节词,标记示例如表1所示,超过3音节的词中间部分都标记为M。
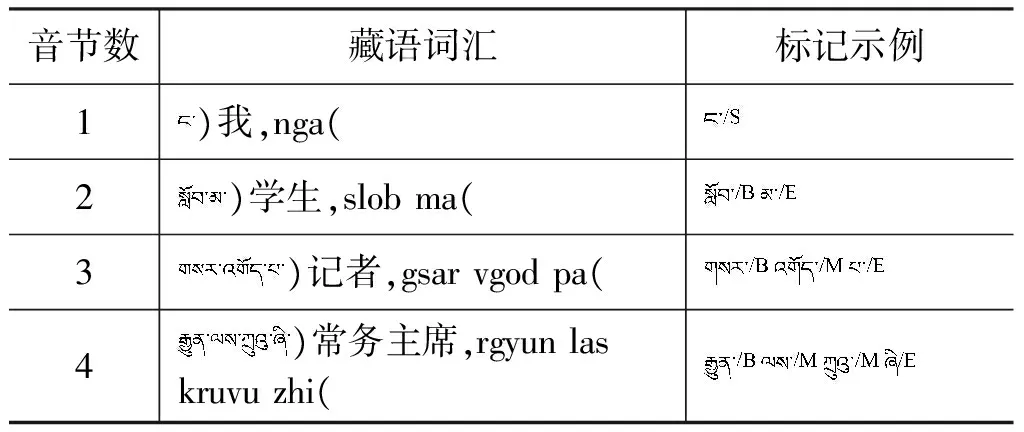
表1 音节标注示例

本文提出的藏文分词系统最重要的特点是采用从无标注语料中抽取的特征,并将之融合到有监督的分词系统中,来增强传统的分词系统效果。本实验采用的特征分为两种,分别为基线特征和无监督特征,针对特征的选取在2.2和2.3部分进行详细介绍。
本文分词流程如下: 首先,对输入的藏文文本进行预处理,紧缩词识别,得到分词基本单位;然后,采用条件随机场的序列标注方法进行标注,由CRF++*http://crfpp.googlecode.com/svn/trunk/doc/index.html实现,根据标注的结果还原出初步的分词结果;最后,对初步的分词结果进行后续处理,得到最终的分词结果。分词系统流程图如图2所示。

图2 分词系统流程图
2.2 基线特征
在本文的基线系统中,采用文献[11]所采用的特征,包括音节位置特征和类别特征,音节位置特征包含了上下文特征,如表2所示。音节类别特征分为藏文音节、藏文标点符号、汉语标点符号、英文字母、英文数字、英文符号等。基线系统是进行无监督特征分词效果的对比系统。

表2 分词特征模板
2.3 无监督特征
藏文分词缺乏大规模标注语料,从无标注语料中抽取特征,以提高有监督分词系统的效果是本文的研究目的。从无监督分词方法中受到启发,本文从无标注语料中抽取无监督特征,并将这些特征融合到基于序列标注的有监督藏文分词系统中,以此来提高本文基线分词系统效果,采用的无监督特征有以下几种。
2.3.1 边界熵
边界熵(Boundary Entropy, BE)作为无监督分词中判断切分边界的一个重要标准,广泛应用在汉语、英语等[13-14]语言的词语边界切分任务中。给定字符串S=Ci..j,
(1)
式(1)表示字符串S的边界熵,hL(Ci..j)和hR(Ci..j)分别表示字符串S的左、右边界熵。熵是对事物不确定性的度量,熵越大不确定性就越大。如果一个字符串边界的熵变大了,那么该位置是词边界的可能性也较大。如果字符串S的左、右边界熵越大,那么该字符串有可能是一个完整的词。用C0表示当前藏文音节,Cn表示相对于当前音节的音节,本文抽取的字符串的边界熵如表3所示。

表3 边界熵特征
2.3.2 邻接变化数
邻接变化数(Accessor Variety, AV)[13]表示一个字符串在上下文中的灵活程度,是对其在上下文中变化程度的度量。邻接变化数较大的字符串边界,
该边界为分词切分边界的可能性也较大。即,一个字符串出现在不同的上下文环境中,那么该字符串成为词的概率也较大。




本文从藏文文本中抽取长度为2、3、4的字符串的AV值,作为无监督统计特征来增强有监督分词系统的效果。抽取特征如表4所示。

表4 邻接变化数特征
2.3.3 无监督间隔标注
Voting Experts(VE)算法是一种局部最优的贪心算法,算法基于以下理论: 相对的词内部熵较低,词边界熵较高,决定词的边界只需要局部信息[14]。VE算法采用“专家”投票方式决定是否支持切分当前的序列边界。如果支持,当前边界的切分可能性增加。本文算法有两个“专家”,一个对于序列内部熵(Internal Entropy)较低的边界支持切分,计算公式如式(2)所示。
H1(seq)=-logP(seq)
(2)
seq表示切分序列,另外一个对于序列边界熵较高的边界予以支持切分。
对于一个长度为k的待分词序列,在分词中有k-1个位置需要决定是否切分。因此,整个切分序列的切分可能性有2k-1个,这样算法复杂度较高,很难应用在实际分词应用中。VE算法采用一种贪心算法,通过k-1次计算就可以切分整个序列。
VE算法在长度为k的待分词序列上,采用一个宽度为n(n 用S=C1:k=C1C2…Ck表示一个需要切分的藏文音节序列,用Gi(i=1…k-1)表示序列中Ci和Ci+1之间的间隔。每一个间隔Gi决定了Ci和Ci+1之间是否需要切分,这样可以把分词问题转化为序列间切分问题,通过采用相关的算法计算出间隔序列Gi:k-1。本文用无监督的VE算法从无标注语料中计算每个间隔Gi的值,对于超过设定阈值间隔Gi予以切分,并将其融合到有监督的模型中,作为无监督特征的一种。 本实验中,藏文分词语料题材为藏语小学语文课本,本语料由西北民族大学中国民族信息技术研究院组织人工标注。把整体语料分为测试语料和训练语料,训练语料包含93 563个词,测试语料包含17 767个词,测试语料未登录词比例为5.6%。抽取无监督特征的语料题材为藏语文初、高中课本语料,包含72万个音节。 在本文的实验中采用的实验特征如下: 实验1,采用基线特征实现的藏文分词系统;实验2,采用基线特征、边界熵实现的系统;实验3,采用基线特征、邻接变化数实现的系统;实验4,采用基线特征、边界熵、邻接变化数和无监督间隔标注实现的系统。 本实验把藏文音节串的边界熵、邻接变化数按照数值分为不同的类别,如表5所示,对于边界熵值取整数。 表5 边界熵、邻接变化数分类表 续表 对于间隔标注阈值设定,本文经过实验选取4, 即对于间隔标注值大于4的音节边界予以标记为切分边界。 下文R、P、F、ROOV、RIV分别表示召回率、正确率、F值、未登录词召回率和登录词召回率,以此作为评测分词系统效果的指标,R、P、F计算方法如下: (3) (4) (5) 从表6可以看出,与采用基线特征的分词系统相比,融合无监督特征的分词系统的各项指标均得到较大的提高,说明本文提出的从无标注语料中抽取的特征较为有效,可以明显提高基线系统的分词效果。 从实验4可以看出来,融合无监督间隔标注的藏文分词系统的未登录词召回率有了较大的提高,说明无监督间隔标注特征对于未登录词识别有较好的效果,并且与基线系统的分词系统相比,分词效果有了较大的提高。 与文献[11]相比,本文的分词系统整体效果较差的原因是本文实验的语料整体上较少,相当于前者的8.5%,另外,未登录词比例也高于前者,因此本文实验结果整体上偏低。 本文研究了从无标注藏文语料中抽取边界熵、邻接变化数、无监督间隔标注等特征,并融入了有监督的序列标注藏文分词系统中。实验结果表明本文抽取的无监督特征可以显著提高基线藏文分词系统的效果,并且可以很好地和有监督分词模型结合在一起。在后续的研究中,本文将在有监督的藏文分词系统中融合更加丰富的无监督特征,提高传统藏文分词系统的效果及分词系统的领域适应性,并研究无监督的藏文分词方法,以及资源受限条件下的藏文分词方法。 [1] 山木旦,郑绍功,扎喜拉旦,等.新编藏文字典[M].西宁: 青海民族出版社,1979. [2] 扎西次仁.一个人机互助的藏文分词和词登录系统的设计[C].中国少数民族语言文字现代化文集,北京: 民族出版社,1999: 322-327. [3] 陈玉忠,李保利,俞士汶,等.基于格助词和连续特征的藏文自动分词方案[J].语言文字应用,2003,(1): 75-82. [4] 祁坤钰.信息处理用藏文自动分词研究[J].西北民族大学学报(哲学社会科学版),2006,(4): 92-97. [5] 才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报,2009,23(1): 35-37. [6] 羊毛卓玛,欧珠.一种改进型的藏文分词交集型歧义消解方法[J].西藏科技信息,2012,1: 66-68. [7] Huidan Liu, Weina Zhao, MinghuaNuo, et al. Tibetan Number Identification Based on Classification of Number Components in Tibetan Word Segmentation[C]//Proceedings of the 23rd International Conference on Computational Linguistics (Posters Volume) (Coling 2010), 2010: 719-724. [8] Huidan Liu, MinghuaNuo, Longlong Ma, et al. Tibetan Word Segmentation as Syllable Tagging Using Conditional Random Fields[C]//Proceedings of the 25th Pacific Asia Conference on Language, Information and Computation (PACLIC-2011), 2011: 168-177. [9] 史晓东,卢亚军.央金藏文分词系统[J].中文信息学报,2011, 25(4): 54-56. [10] Tao Jiang, Hongzhi Yu, Yangkyi Jam. Tibetan word segmentation system based on conditional random fields[C]//Proceedings of Software Engineering and Service Science (ICSESS), 2011 IEEE 2nd International Conference: 2011, 7, 446-448. [11] 李亚超,加羊吉,宗成庆,等.基于条件随机场的藏语自动分词方法研究与实现[J].中文信息学报,2013,27(4): 52-58. [12] Yachao Li,Hongzhi Yu. Study on Tibetan Word Segmentation as Syllable Tagging[C]//Proceedings of Natural Language Processing and Chinese Computing (NLP&CC 2013). 2013, 11: 363-369. [13] Haodi Feng, Kang Chen, Xiaotie Deng, et al. Accessor variety criteria for Chinese word extraction. Computational Linguistics [J]. 2004, 30(1): 75-93. [14] Paul Cohen, Brent Heeringa, Niall Adams. An unsupervised algorithm for segmenting categorical timeseries into episodes[C]//Proceedings of Pattern Detection and Discovery. 2002: 117-133. [15] Paul Cohen, Brent Heeringa, Niall Adams. An unsupervised algorithm for segmenting categorical timeseries into episodes [J]. Pattern Detection and Discovery. 2002: 117-133. [16] Kumiko Tanaka-Ishii, ZhihuiJin. From phoneme to morpheme: Another verification rsing a corpus[C]//Proceedings of the 21st International Conference on Computer Processing of Oriental Languages. 2011: 234-244. Study on Fusion of Unsupervised Features for Tibetan Word Segmentation LI Yachao, JIA Yangji, JIANG Jing, HE Xiangzhen, YU Hongzhi (Key Lab of Chinese National Linguistic Information Technology, Northwest University forNationalities, Lanzhou, Gansu 730030, China) Tibetan word segmentation (TWS) is an important problem in Tibetan information processing, while the current TWS features are mostly adopt the syllable position and syllable categories. The paper extracted unsupervised features, for example, boundary entropy, accessorvariety and unsupervised gap tagging, from unlabeled corpus,and studied the TWS merged with unsupervised features. The experimental results show that, F score increase of 0.97% compare to the baselinesystem, the method get a good performance on out of vocabulary words. From the above, we can conclude that this method can effectively distracted from unlabeled corpus, which can be combined easily with the supervised segmentation model. The method can significantly increases the effect of the baseline TWS. Tibetan; word segmentation; sequence labeling 李亚超(1986—),讲师,主要研究领域为机器翻译、词法分析、少数民族语言文字信息处理。E⁃mail:liyc7711@gmail.com加羊吉(1985—),博士,副教授,主要研究领域为藏文信息处理。E⁃mail:236164976@qq.com江静(1988—),助教,主要研究领域为复杂网络。E⁃mail:506775848@qq.com 2015-10-15 定稿日期: 2016-01-15 国家社科基金青年项目(15CYY043);国家自然科学基金(61262054);甘肃省高等学校科研项目(2016B—007);甘肃省民族语言智能处理重点实验室开放基金; 西北民族大学中央高校基本科研业务费专项资金(31920140064, 31920150089) 1003-0077(2017)02-0071-05 TP391 A3 实验设置与分析



4 结论与下一步工作

猜你喜欢
西藏研究(2021年1期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
考试与评价·七年级版(2020年6期)2020-11-02
布达拉(2020年3期)2020-04-13
快乐作文(1.2年级)(2019年9期)2019-09-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
作文周刊·小学一年级版(2018年32期)2018-01-15
