
基于科学工作流的海量海底观测数据处理研究
2017-05-12 11:29:13宋靖东汤友华
海洋技术学报 2017年2期
宋靖东,汤友华,李 秀,马 辉
(清华大学深圳研究生院 信息学部,广东 深圳 518055)
基于科学工作流的海量海底观测数据处理研究
宋靖东,汤友华,李 秀,马 辉
(清华大学深圳研究生院 信息学部,广东 深圳 518055)
近些年来,在处理由海底观测网站收集到的庞大观测数据的研究中,需引入新的科学工具来支持所需的高性能分布式计算环境。而科学工作流在先进信息基础设施研究中得到广泛重视,成为未来科研环境的具体实现工具。针对这一问题,提出了基于Kepler科学工作流的海量海底观测数据处理解决方案,并且研究了系统调用Hadoop集群进行海量数据处理的两种方式及其优缺点;通过实验,对比分析了该两种方式与传统Java编程模式调用Hadoop集群进行数据处理的效率问题,证明了Kepler调用集群的高效性。
科学工作流;Hadoop集群;Kepler
随着科学技术的进步,现代大型海底观测网的数据采集能力远远超于传统的海底采集方式,在海底电缆的电力保障下可以长期不间断地进行数据采集与传输,单个大型的海底观测网每日获取的数据量就已达到GB级,年管理数据达到TB级,成为不可忽视的海量数据资源。海量的观测数据为科学研究提供了新的机遇,为更多的未解问题提供了探索依据,但是同样面临着大数据处理带来的急需新的科学工具的问题。虽然硬件技术在不断发展,但是单纯的单节点计算机完全不可能完成海量数据的运行处理,集群技术、分布式计算技术成为人们的研究重点。同时海洋科学家更需要一种可以屏蔽底层计算设计、直接方便调用的计算工具完成其专业领域内的相关研究的工具。
目前研究者针对海洋领域内各个方向的数据处理研究工作较多。如文献 [1]基于SOA(service oriented architecture)的概念,通过在设计中引入本体技术完成对异构数据的统一描述,从而实现海洋领域的信息集成与共享。文献[2]通过在台风海洋网络气象信息系统中引入时空数据模型实现对多源异构气象数据的一致描述与集成融合。文献[3]基于大型网络数据库Oracle构建了一个ARGO(array for real-time geostrophic oceanography)海洋观察数据存储模型,并结合GIS(geographical information system)和遥感技术实现了海量ARGO数据的高效存储、管理和分析。文献[4]基于改进的卡尔曼平滑器,通过检潮仪的海平面测量数据估计冰川的融化速度。文献[5]设计了一个逐步校正的模型用于融合SWAN (simulating waves nearshore)模型产生的海浪预测数据和部分实测的海浪数据,从而提高对海面状况估计的准确率。这些研究工作促进了针对海洋某一领域的研究或小范围数据处理的进步,但不能满足对海洋大数据进行处理的相关要求。本文针对海底观测所遇到的海量数据处理问题,通过对目前科学工作流系统的研究,提出了基于科学工作流的数据处理方案,并且研究了在科学工作流平台上进行Hadoop集群调用的具体方式以及对比传统集群调用的效率问题。
1 相关技术
1.1 科学工作流
科学工作流(Scientific Workflow,SWF)借鉴于传统业务工作流的思想进化而来[6],针对目前新的科研环境,将科学研究过程中数据下载、分析、计算、可视化等流程步骤组合在一起实现数据的处理与计算,它可以简化科研调用流程,减少科研人员在复杂计算相关工作上的精力消耗。如文献[7]构建了一个基于科学工作流的铁路行车安全评价系统,在行车数据自动收集融合的基础上建立了一个模糊综合评价的科学工作流程,实现自动对状态不佳的列车进行跟踪和评价,对有安全隐患的列车进行预警,并为管理者提供决策支持。文献[8]针对涡度相关技术获取的碳通量观测数据体量大、计算复杂、算法的更新和共享难以实现等问题开发了一个基于web service和科学工作流技术的碳通量数据处理系统,用以实现数据的整合、算法的共享、重用以及通量数据的自动化计算。文献[9]将科学工作流引入到月球数据预处理中,通过改进工作流定义元模型并详细设计数据模型和过程模型,解决了数据预处理的流程灵活配置和中间结果展示等问题,方便了科研人员对算法进行设计和改进。
经过十几年的发展,目前各大科研组织在各自的实际应用中设计和开发了很多成熟的科学工作流管理系统,其中Kepler[10]由UC Berkeley和San Diego超级计算中心联合开发的一套科学工作流系统,它基于Ptolemy II系统,以Java为底层语言,将要执行的过程步骤进行可视化的表达,从而使科研人员只需通过简单地拖拽各个功能模块就可以组成实验所需的科学工作流,大大减轻了研究人员的负担。各个功能模块之间通过各自的输入输出接口进行连接,用户可以很清晰地看到整个流程的执行顺序,而且Kepler提供了多种引导器如串行引导器、并行引导器等来决定整个流程的执行顺序。同时Kepler系统是一个开源的系统,可以方便地调用web服务和远程数据服务从而可以针对特定的领域进行二次开发。
1.2 Kepler的通用数据读取转换模块
Kepler提供了比较全面的数据读取转换模块actor供科研人员进行科学工作流的搭建。目前,Kepler支持 EML(Ecological Metadata Language)、 Darwin Core等元数据规范,可以使用相应的actor对数据集进行元数据的解析及输出。对于没有采用元数据描述的数据,如EXCEL表格数据、Web页面表格数据等,Kepler提供了Binary File Reader,URL To Local File,Line Reader,File To Array Convert等多种数据读取转换模块。此外,Kepler可以获取与DAP(data access protocol)2.0兼容数据资源;拥有DataTurbine actor可以从DataTurbine服务器上获取数据;支持FTP文件传输协议,可以实现文件的上传和下载;支持Oracle、MySQL以及本地与远程MS Access等数据库,可以使用相应的actor实现对这些关系型数据库的访问、查询和检索;对于图像数据,可以使用ImageJ actor等图像数据进行读取编辑等操作。
1.3 MapReduce与Hadoop
MapReduce是由美国谷歌公司提出的一种并行化用于处理和生成海量数据的编程模型[11],由于其简单易用性、容错能力等特点已经在各领域普遍得到应用。MapReduce框架最大的特点并不是计算程序并行化而是数据并行化,从而达到缩短时间的目的,与MapReduce框架相配套使用的是分布式文件系统,数据被分布到不同存储节点,而且计算节点与存储节点是同一节点,使得计算程序可以直接调用在本地的数据进行运行,减少了跨节点的IO传输开销。MapReduce框架的简易操作在于其提供了两个函数即map函数和reduce函数,如公式(1)~(2),编程人员只需要简单修改操作就可以实现并行化应用。
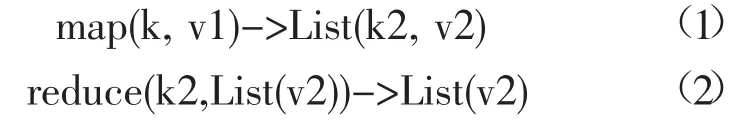
map函数和 reduce函数对数据都采用键/值对,即key/value对的形式进行处理的,作业执行时,数据被分割成若干数据块分布到各个节点,map函数并行地处理这些数据块,从中提取key/value对作为输入并产生中间key/value对存储到本地磁盘,然后框架对中间key/value对进行混洗(Shuffle)、排序(sort),具有相同key的中间结果聚集在一起,最后将结果传输给reduce函数,map函数与reduce函数都需要事前自定义完成指定的计算功能。MapReduce框架的数据处理流程图如图1所示。
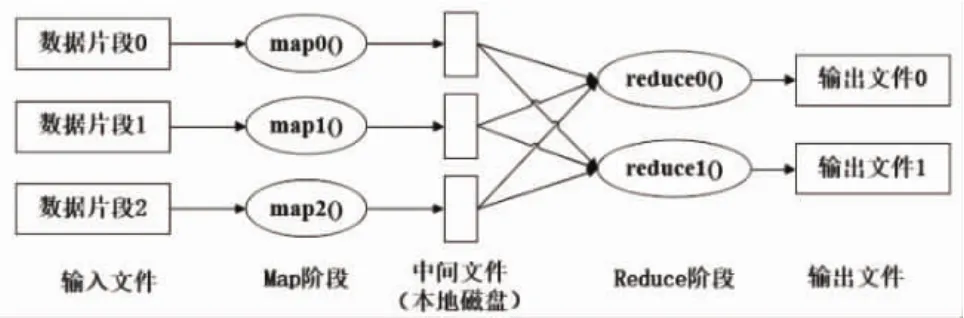
图1 MapReduce框架的数据处理流程
Hadoop是Apache基金会下的一个开源项目,它实现了谷歌公司提出的分布式文件系统以及MapReduce计算框架,其分布式文件系统称之为HDFS(Hadoop Distributed Filesystem)。该项目具备高可靠性、高扩展性、高效性以及成本低、操作简单等特点,已经被国内外多家大型公司采用,用于处理海量客户与产品数据。如文献[12-14]通过在各自的研究领域利用MapReduce将大量计算并行化,从而显著提高了算法的运行效率。
2 科学工作流调用方式
Hadoop可以方便地在价格低廉的计算硬件上进行部署,实现条件简单,同时MapReduce分布式编程模型将复杂并行化程序设计简化为两个函数的编写过程,允许没有分布式系统开发经验的人员进行并行开发。但是对专业领域的科学家,如海洋学科学研究人员来说,参照MapReduce分布式编程模型的说明文档编写出正确的计算机程序是非常困难的,而采用科学工作流的方式屏蔽底层代码为专业领域科学家使用Hadoop集群提供了便利途径。以下将详细介绍科学工作流与Hadoop集群相结合的方法。
2.1 MapReduce Actor应用方式
文献[15]提出了一个Kepler+Hadoop的通用架构,使得用户利用MapReduce编程模型可以方便地表示以及高效地执行各自领域内的专业分析。MapReduce模型控件现在已经在Kepler科学工作流系统中使用,其实际应用框架如图2所示。Kepler科学工作流系统底层开发人员将MapReduce的相关复杂程序进行封装,留出操作数据的输入输出地址供终端用户使用,同时该actor给出map函数与reduce函数的输入输出接口,而两个函数的具体实现可以根据不同的专业领域内的知识进行开发,从而构造出各种不同类型的专业领域并行化actor。而科学工作流开发者根据底层人员开发的各类基于MapReduce模型的actor构造出不同的专业工作流。
在该框架下,首先设计了一个名为MapReduce的复合控件/actor,其与整个计算过程中的其余工作流相连,而map函数与reduce函数的功能实现为其两条子工作流。在每条子工作流中又设计有专门的actor与map函数、reduce函数的接口相对应,分别为 MapInput,MapOutput与 ReduceInput,Reduce-Output。map函数、reduce函数需要在这两条子工作流中完成自定义。具体设计如图3所示,图为Kepler提供的单词计数操作。

图2 MapReduce应用框架

图3 MapReduce actor的使用
2.2 Web服务应用方式
Web服务技术具有高度的互操作性,并且根据它所实现的应用可以在任意的机器或者平台上不需借助第三方的帮助就可实现数据的交换或者应用的集成。利用MapReduce编程模型的代码开发者只需要将所写源代码发布成Web服务即可。目前主流的Web服务开源框架有Apache Axis1,Apache Axis2,Codehaus XFire,Apache CXF,JWS等,其中Axis2与CXF最为常用。
还以单词计数为例,采用Kepler科学工作流系统提供的WebService actor,右击打开属性填入Web服务地址就可调用该程序功能,添加输入、输出以及流程引导器director即可构成完整工作流,实现海量数据分析,完成单词计数,流程图与结果如图4所示。
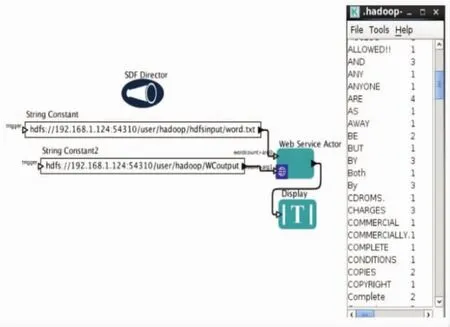
图4 单词计数Web服务调用与结果
采用该种方式调用Hadoop集群,对于专业领域的科学家来说,操作简便,只需知道所需功能的Web服务地址,添加输入输出即可,但是要求处理机与Web服务器在同一网络环境内,同时因为服务已被封装,用户不能再做任何的修改。
3 实验分析
本文已经研究了如何在Kepler科学工作流系统进行Hadoop集群的调用,进一步需要研究在所开发的系统上进行调用的效率问题。相比于传统的在Hadoop集群上直接执行Java程序,系统调用Hadoop集群必然存在各种软件调用与初始化开支,单论在执行上花费时间也必然要比传统方法多。文献[9]已经研究了采用MapReduce actor的方式调用Hadoop集群进行数据分析的效率问题,通过与传统方法的对比,得出如下三个结论:(1)使用MapReduce actor的方式比传统方法所花费的执行时间多数倍,主要的花费开支在于Kepler引擎系统的初始化以及Map和Reduce两个子工作流的调用,但是随着集群节点的增加,两种方式所花费的时间都会减少,系统调用方式与传统方式的耗时时间差成倍下降;(2)当Map任务的输入数据逐渐增加时,两种方式处理速度都会变快,当输入过大时则又逐渐变慢。输入变大则意味着Map阶段处理时间长,开支占用的百分比减少,当过大时即所需Map任务数减少,并行度下降;(3)当Map和Reduce两个子工作流的处理非常复杂时,在引擎初始化以及工作流调用上的开支占总花费时间的比例随着其复杂度的增加逐渐下降。本文主要分析第二种Web服务方式进行Hadoop集群调用的效率问题,同样采用实验对比的方式进行。
3.1 实验环境
实验环境为在100 Mbps的局域网中配置的五节点的Hadoop集群,操作系统皆为64位的Centos6.4版本。主节点master处理器为四核3.3 GHz Intel Xeon CPU,8 GB内存,500 GB硬盘;从节点1/slave1与从节点2/slave2的处理器为四核3.1 GHz Intel i5 CPU,4 GB内存,250 GB硬盘;从节点3/slave3与从节点4/slave4的处理器为四核3.1 GHz Intel i5 CPU,4 GB内存,500 GB硬盘。
3.2 效率对比实验结果与分析
实验对比了Web服务方式与传统Java编程两种方式在大规模海底图像分割问题上的时间消耗。所采用的图像分割方法为基于MapReduce的快速模糊C均值算法FFCM[16],模糊C均值算法采用隶属度将图像的像素点进行聚类,但由于面临数据量过大的问题,采用灰度直方图进行改进,加快目标函数的收敛即为FFCM,而基于MapReduce的FFCM则为算法的进一步改进,将图像数据在多个节点分割,实现并行化算法执行。实验采用的是fish4knowledge项目提供的海底视频图像,使用Hadoop的MapReduce框架处理图像数据需要使用到专门的图像处理库HIPI(Hadoop Image Processing Library),其提供了将大量图像存储到分布式文件系统HDFS上的方法,一个HIB(Hipi Image Bundle)文件即为存储在HDFS上一个图片集合。
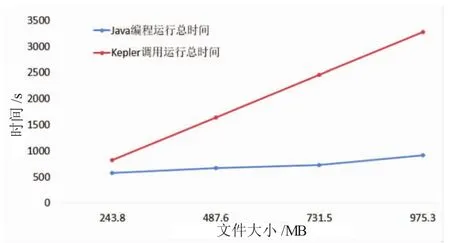
图5 五节点Hadoop集群处理时间
实验中构造了若干图像文件,每个文件所含图片张数由4 000到16 000张不等,文件大小从240 MB到970 MB不等,首先图像文件安排到五节点的Hadoop集群上运行,实验对比结果如图5所示,可以得到类似的结果,采用Kepler科学工作流系统调用Web服务使用Hadoop集群执行花费的时间约比传统Java编程直接在集群上运行多1~3倍的时间,系统调用的花费开支(包括网络传输)占了主要部分。实验中采用单独一台主机调用Web服务,Web服务代码存放在Hadoop集群的主节点上。
考虑科学工作流的可扩展性,将原任务重新安排到3个节点的Hadoop集群上运行,并且与上一实验五节点结果进行对比,得到表1。由表可知,节点的增加,可以加速运算的进行,但是系统调用的开支在总的执行时间中仍占较大部分,主要因为实验中所用分割算法较为简单。

表1 Hadoop集群运算对比结果
同时本文比较了两种Kepler系统调用方式的效率,仍旧采用单词计数程序,集群节点为3个,两种方式的具体工作流设计如图3与图4所示。HDFS默认的一个文件块大小为64 MB,所以实验设计文件大小从96.6 MB到782 MB不等,所得实验结果如图6所示。
由图可知,采用MapReduce actor的方式花费的时间最长,Kepler引擎的初始化与多次Map/Reduce子工作流的调用占用了绝大部分,采用Web服务调用的方式花费时间相对较小,没有子工作流的调用,程序执行过程与传统Java编程方式基本相同,耗时大约是传统方式的2~3倍,但是采用MapReduce actor的方式用户只需在Hadoop集群直接运行工作流程序即可,不关心集群的启动等问题,而采用Web服务调用的方式,用户需要首先人工启动Hadoop集群,需要了解基本的Hadoop集群运行规则以及会使用命令行输入命令。两种Kepler系统调用的方式虽然比传统方式用时偏长,但是省去了大量的程序构建时间,用户可以简单地采用Kepler科学工作流系统提供的图形化操作界面直接进行领域知识分析。

图6 3种方式集群处理时间比较
4 结束语
海洋观测数据的处理具有数据处理规模大,数据处理性能要求高、数据处理流程复杂以及协同工作等特点,因此研究能够有效利用和处理海洋观测的大数据,对整个海洋观测资源的有效整合和管理,实现数据处理无缝协同工作的数据处理工具是十分必要的。本文提出了基于科学工作流Kepler系统的海洋观测大数据处理方法,能够实现帮助海洋领域专业科学家乃至其他专业领域科学家有效使用先进大数据处理技术,提高其工作效率。
[1]杨鹏,王文俊,董存祥.海洋领域信息集成与共享研究[J].计算机工程与应用,2010,26:194-197.
[2]陈钻,李海胜.新型台风海洋网络气象信息系统的设计与实现[J].应用气象学报,2012,23(2):245-250.
[3]刘南,刘仁义,尹劲峰,等.ARGO海洋卫星观测数据处理方法及应用[J].中国图象图形学报:A辑,2005,9(11):1386-1391.
[4]HayC C,MorrowE,Kopp R E,et al.Estimatingthe sources ofglobal sea level rise with data assimilation techniques[J].Proceedings of the National AcademyofSciences,2013,110(Supplement 1):3692-3699.
[5]Butunoiu D,Rusu E.Wave modeling with data assimilation to support the navigation in the Black Sea close to the Romanian ports[C]//Proceedingofthe International Conference on Traffic and Transport Engineering,2014:27-28.
[6]Deelman E,Gannon D,Shields M,et al.Workflows and e-Science:An overviewofworkflowsystemfeatures and capabilities[J].Future Generation Computer Systems,2009,25(5):528-540.
[7]杜彦华,吴秀丽,钱程,等.基于科学工作流的铁路行车安全评价系统研究[J].铁道学报,2012,34(12):76-82.
[8]刘敏,何洪林,吴楠,等.基于Web Service和科学工作流技术的碳通量数据处理系统实现研究 [J].科研信息化技术与应用, 2013(2):50-58.
[9]谭旭,刘建军,李春来.月球数据预处理工作流模型的构建及应用[J].吉林大学学报:工学版,2015,45(6):2007-2013.
[10]Altintas I,Berkley C,Jaeger E,et al.Kepler:An extensible system for design and execution of scientific workflows[C]//Proceedingsofthe16thInternationalConferenceonScientificandStatisticalDatabaseManagement,SantoriniIsland,2004:423-424.
[11]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1): 107-113.
[12]胡爱娜.基于MapReduce的分布式EM算法的研究与应用[J].科技通报,2013(6):68-70.
[13]张晓强.MapReduce在Web日志挖掘中的应用[D].成都:电子科技大学,2011.
[14]吴文忠,易平.MapReduce在分布式搜索引擎中的应用[J].计算机系统应用,2012,21(2):249-251.
[15]Wang J,Crawl D,Altintas I.Kepler+Hadoop:a general architecture facilitating data-intensive applications in scientific workflow systems[C]//Proceedings ofthe 4th Workshop on Workflows in Support ofLarge-Scale Science.ACM,2009:12.
[16]Li X,Song J,Zhang F,et al.MapReduce-based fast fuzzy c-means algorithm for large-scale underwater image segmentation[J]. Future Generation Computer Systems,2016,65:90-101.
Research on Massive Seafloor Observation Data Processing Based on Scientific Workflow
SONG Jing-dong,TANG You-hua,LI Xiu,MA Hui
Division of Information Science&Technology,Graduate School at Shenzhen,Tsinghua University,Shenzhen 518055,Guangdong Province,China
In recent years,faced with the problem of processing massive observing data collected by the seafloor observatory networks,new scientific tools are needed to be introduced to support the high-performance and distributed computing environment.Scientific workflow has been widely attached great importance to research advanced information infrastructure,and it has become a concrete realization tool for the future research environment.To solve this problem,this paper puts forward a new solution for processing massive seafloor observing data based on the Kepler scientific workflow,and studies the advantages and drawbacks of the two methods applying for massive data processing with the use of Hadoop clusters.Compared with the traditional Java programming mode,the experiment results prove that the efficiency of the two methods using Hadoop cluster is higher,and the Kepler scientific workflow will result in high efficiency.
scientific workflow;Hadoop clusters;Kepler
TP311.5
A
1003-2029(2017)02-0065-06
10.3969/j.issn.1003-2029.2017.02.011
2016-05-27
国家高技术研究发展计划(863计划)重大项目资助(2012AA09A408);国家自然科学基金资助项目(71171121);深圳市基础研究及技术开发项目资助(JCYJ20151117173236192);基于传感网的海洋观测集成平台的研发项目资助(CXZZ20140902110505864);海底观测网岸基控制运行与数据管理系统配套项目资助(GJHS20120702113257111)
宋靖东(1991-),男,硕士,主要研究方向为密集计算、大数据处理。E-mail:tyhcjf@163.com
李秀(1971-),女,教授,主要研究方向为海洋信息。E-mail:li.xiu@sz.tsinghua.edu.cn
猜你喜欢
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
商品与质量(2019年34期)2019-11-29 03:25:51
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
测控技术(2018年5期)2018-12-09 09:04:46
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
信息安全研究(2016年4期)2016-12-01 06:07:05
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
