
基于Scrapy的论文引用爬虫的设计与实现
2017-05-12 09:22:54鲁继文
现代计算机 2017年9期
鲁继文
(四川大学计算机学院,成都 610065)
基于Scrapy的论文引用爬虫的设计与实现
鲁继文
(四川大学计算机学院,成都 610065)
互联网的迅速发展对于信息的发现和搜集带来巨大的挑战,至今爬虫技术已经成为互联网研究热点之一。基于Scrapy设计一个采集网页上面引用的作者和引用信息的爬虫,系统运行结果显示所设计的爬虫对于爬取引用信息,并将其整理成便于存储和理解的结果有较好的效果。
Scrapy;爬虫;引用爬取
0 引言
网络爬虫,有时称为蜘蛛,是一种系统地浏览万维网的因特网机器人,通常用于网络索引(Web Spidering)的目的[1]。Web搜索引擎和其他一些站点使用Web爬行或Spidering软件来更新他们的Web内容或其他网站的Web内容的索引。 Web搜寻器可以复制他们访问的所有页面,以便以后由处理下载的搜索引擎,以便用户可以更高效地搜索。抓取工具会消耗他们访问的系统上的资源,并且经常在没有默认批准的情况下访问网站。当访问大量页面集合时,计划,加载和“礼貌”的问题就会发生。存在不希望被爬行的公共站点的机制,以使爬行代理程序知道它。例如,包括robots.txt文件可以请求漫游器仅对网站的部分进行索引,或者根本不进行索引。
1 系统设计
Scrapy是一个可以用来爬取Web站点,提取需要的数据结构应用程序开发框架,在众多应用程序中得到广泛运用,例如:数据挖掘、信息处理或者历史数据处理等。尽管Scrapy的最初设计是用来Web抓取,但现在它也可以用使用API来提取数据 (如Amazon Associates Web Servicesi)或通用网络爬虫[2]。
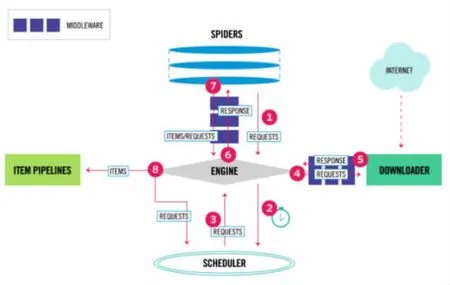
图1
首先生成用于抓取第一个URL的初始请求,然后指定要使用从这些请求下载的响应调用的回调函数。
(1)通过调用start_requests()方法(默认情况下)为start_urls中指定的URL生成请求以及将parse方法作为请求的回调函数来调用start执行的第一个请求。
(2)在回调函数中,将解析响应(网页),并返回带有提取的数据的对象,项对象,请求对象或这些对象的可迭代对象。这些请求还将包含回调 (可能是相同的),然后由Scrapy下载,然后由指定的回调处理它们的响应。
(3)在回调函数中,通常使用选择器来解析页面内容 (但也可以使用BeautifulSoup,lxml或其他任何机制),并使用解析的数据生成项目。
(4)最后,从蜘蛛返回的项目通常将持久存储到数据库(在某些项目管道中)或使用Feed导出写入文件。即使这个循环(或多或少)适用于任何种类的蜘蛛,有不同种类的默认蜘蛛捆绑到Scrapy中用于不同的目的。例如:Scrapy.Spider,Generic Spiders。我们将在这里谈论这些类型:Scrapy.Spider这是最简单的蜘蛛,每个其他蜘蛛必须继承的蜘蛛(包括与Scrapy捆绑在一起的蜘蛛,以及你自己写的蜘蛛)。 它不提供任何特殊功能。 它只是提供了一个默认的start_requests()实现,它从start_urls spider属性发送请求,并为每个结果响应调用spider的方法解析。蜘蛛可以接收修改其行为的参数。 蜘蛛参数的一些常见用法是定义起始URL或将爬网限制到网站的某些部分,但它们可用于配置蜘蛛的任何功能。Scrapy附带一些有用的通用蜘蛛,你可以使用它来子类化你的Spider。他们的目的是为一些常见的抓取案例提供方便的功能,例如根据某些规则查看网站上的所有链接,从站点地图抓取或解析XML/CSV Feed:CrawlSpider,XMLFeedSpider,CSV FeedSpider,SitemapSpider。
Requests和Responses是Scrapy用来抓去网页内容的最主要的两个对象。通常,请求对象Requests在爬虫中生成并在其生命周期中传到整个系统和,直到他们传到下载器Downloader,将执行结果返回给请求的爬虫,并将这个Requests对象释放。
请求类Requests和响应类Responses都有子类,它们是子类中不是必需添加功能的基类。下面将描述这些请求Requests和响应Responses的子类:

请求对象Requests代表了一个HTTP请求,通常由Spider产生和由Downloader执行,从而得到一个响应Responses。回调函数(调用)callback,将调用的响应这个请求(一旦下载)作为它的第一个参数。如果一个请求不指定一个回调,Spider的parse()方法将被使用。注意,如果异常处理过程中,errback将被调用。Cookies指的是这个请求的cookies,其他使用可以有两种形式,第一种使用dict:

第二种是使用dict列表:
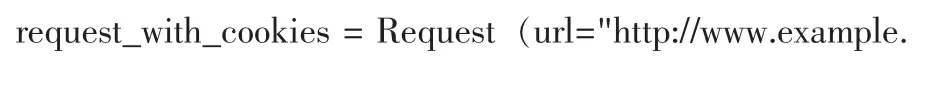
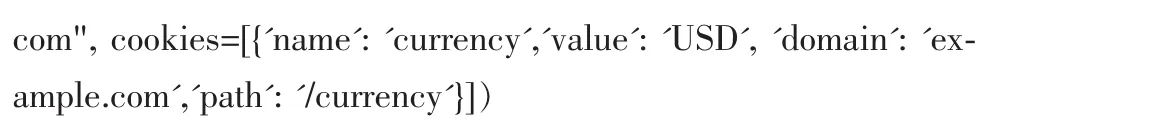
一些网站返回cookies(响应),存储下来供这个域使用,并且将在未来再次发送请求时会被发送给服务器端。这是典型的常规的Web浏览器的行为。但是,如果由于某种原因,你想避免与现有cookies合并,可以指示Scrapy通过 Request.meta将 dont_merge_cookies键设置为True。
请求的回调是当下载该请求的响应时将被调用的函数。将使用下载的Response对象作为其第一个参数来调用回调函数。例如:

2 系统实现
此项目提取http://quotes.toscrape.com/这个网页引用当中的信息,结合相应的作者姓名和标签。
本文实现了两种蜘蛛,两个蜘蛛从同一网站提取相同的数据,但toscrape-css使用CSS选择器,而toscrapexpath使用XPath表达式,通过list命令进行查看:


3 运行结果演示
如图,我们抓取部分作者和他们的引用信息,放在{}当中。

图2
4 结语
本文基于Scrapy设计了一个采集网页上面引用的作者和引用信息的爬虫,系统运行结果显示本文所设计的爬虫对于爬取引用信息,并将其整理成便于存储和理解的结果有较好的效果。
[1]Web crawler.https://en.wikipedia.org/wiki/Web_crawler
[2]Twisted Introduction.http://krondo.com/an-introduction-to-asynchronous-programming-and-twisted/.
[3]Product Advertising API.https://affiliate-program.amazon.com/gp/advertising/api/detail/main.html.
Design and Implementation Crawler of Paper Reference Based on Scrapy
LU Ji-wen
(College of Computer Science,Sichuan University,Chengdu 610065)
The rapid development of the Internet for information discovery and collection has brought great challenges,so far reptile technology has become one of the Internet research hotspot.Based on Scrapy,designs a crawler that references the author and references the information. The results of the system show that the designed crawler has a good effect on crawling the reference information and organizing it into a convenient storage and understanding.
Scrapy;Web Crawler;Reference Crawling
1007-1423(2017)09-0131-04
10.3969/j.issn.1007-1423.2017.09.030
鲁继文(1991-),男,陕西汉中人,硕士,研究方向数据挖掘
2017-02-28
2017-03-15
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
数学年刊A辑(中文版)(2021年4期)2021-02-12 01:21:02
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
电子测试(2018年1期)2018-04-18 11:53:04
数学物理学报(2018年1期)2018-03-26 08:16:37
电子制作(2017年9期)2017-04-17 03:00:46
信息安全研究(2016年4期)2016-12-01 06:07:05
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
