
基于改进CHI特征选择的情感文本分类研究*
2017-05-10 13:00袁磊
传感器与微系统 2017年5期
袁 磊
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
基于改进CHI特征选择的情感文本分类研究*
袁 磊
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
为了提高情感文本分类的准确率,对英文情感文本不同的预处理方式进行了研究,同时提出了一种改进的卡方统计量(CHI)特征提取算法。卡方统计量是一种有效的特征选择方法,但分析发现存在负相关现象和倾向于选择低频特征词的问题。为了克服不足之处,在考虑到词频、集中度和分散度等因素的基础上,考虑文本的长短不均衡和特征词分布,对词频进行归一化,提出了一种改进的卡方统计量特征提取算法。利用经典朴素贝叶斯和支持向量机分类算法在均衡语料、非均衡语料和混合长短文本语料上实验,实验结果表明:新的方法提高了情感文本分类的准确率。
情感分类; 预处理; 卡方统计量; 特征选择
0 引 言
互联网的普及和用户的增加极大促进了电子商务的发展。和传统的购物不同,由于地域的局限性,用户缺少线下的体验,对商品的质量和卖家的情况不是很了解,更倾向于先看网络评论然后再做购买决策。同时生产厂商为了解用户需求,提高产品质量,需要了解用户对产品的购买喜好和使用后的评价意见,过去通常通过社会调查或人工手段分析这些信息,然而随着互联网信息爆发性地增长,传统人工的手段已经无法满足快速变化的市场需求。因此,如何快速自动地识别庞大的评价数据其中表达的对人物、事件、产品等的情感信息,判断用户的情感倾向,获取需要的有用信息,已成为当前的迫切需求。
文本情感分析就是在这样的背景下应运而生。与传统的文本信息处理不同,文本情感分析所关注的是文本所体现出作者的情感信息,而不是文本描述表示的内容。文本情感分析又称为意见挖掘,是指通过计算机技术对带有情感色彩的文本进行主客观性分析处理,归纳和推理得到文本的情感倾向性的过程[1]。
1 相关工作
现有的文本情感分析工作主要可以主要分为两个方向,基于情感知识的方法和基于机器学习的方法[2]。前者主要是依靠一些已有的情感词典或领域词典以及主观文本中带有情感极性的组合评价单元进行计算,来获取情感文本的情感极性;后者主要是使用机器学习的方法,对文本大量特征选择和训练模型 ,然后根据训练出的模型完成文本分类工作。本文采用机器学习的方法进行文本情感分类的研究。
文本情感分类前,需要将文本表示成计算机可以识别的方式。目前,文本文档通常采用向量空间模型[2](VSM), VSM中一个文档有多维的向量构成,每个向量是一个特征项,即文本中的单词或短语。如果直接将文本中所有的词作为特征项,会导致文本的空间向量维度过大,造成文本稀疏并且包含大量的噪声。合理的特征选择,不仅减少了分类时间,而且去除冗余的信息,提高了分类精度,所以特征选择对文本情感分类至关重要。常用的特征选择算法有:文档频率(document frequency,DF),信息增益(information gain,IG),互信息(mutual information,MI ),卡方统计量(Chi-square statistic,CHI),期望交叉熵( expected cross entropy,ECE)等。
许多学者近年来倾向于研究特征选择问题,李杰[3]对语音情感识别当中的特征进行了概述;程广涛[4]对图像领域的HOG特征进行了研究;Yang教授[5]针对文本分类问题,在分析和比较了IG,DF,MI和 CHI等特征选择方法后,得出IG 和CHI方法分类效果相对较好的结论。IG相对于其他方法计算量比较大,本文将主要对卡方统计量CHI进行研究和改进。熊忠阳[6]分析了卡方统计量的不足,并提出将频度、集中度、分散度应用到卡方统计方法上,对卡方统计进行改进;裴英博[7]提出了一种改进的CHI统计权重计算方法,引入了新的频度、相关度和分散度3个计算因子,提高了CHI统计方法在不均衡数据集上的表现;王光[8]集合CHI与IG两种算法的优点,得到一种集合特征选择方法CCIF;邱云飞[9]在原有的卡方特征选择的方法上通过增加3个调节参数以调节模型中特征项的权重,使得新的特征加权模型倾向于选择集中分布在某一类里的特征项;徐明[10]通过对微博文本特征信息的分析与研究,改进卡方统计量使其适合微博的特征提取;肖雪[11]提出最低频CHI选择算法,弥补卡方特征选择对低频词的偏袒;Jin[12]将词频和词的分布区间引入到CHI特征选择算法,提高了文本分类的宏平均和微平均。
前述对卡方统计量改进都是对传统文本分类的改进,本文研究了不同预处理对英文评论语料情感分类的影响,同时研究传统卡方统计量特征提取的方法对情感分类结果的影响,并且分析卡方统计量的不足,在考虑到词频、集中度和分散度等因素的基础上,考虑文本的长短不均衡和特征词分布,对词频进行归一化,提出基于改进的卡方统计量特征选择算法。最后,用朴素贝叶斯和支持向量机在均衡语料、非均衡语料、混合长度语料上分别进行情感分类实验,实验结果显示,改进的特征提取方法提高了分类的效果。
2 卡方统计量及其改进
2.1 卡方统计量
卡方统计量衡量的是特征项t和类别ci之间的相关程度。假设特征t和类别ci之间符合具有一阶自由度的卡方分布,特征t对于类ci的卡方值越高,携带的类别信息越多,其与该类之间的相关性越大。特征项t对于文档类别ci的CHI 值算法式(1)如下
(1)
式中 N=A+B+C+D;ci为某一特定类别;t为特定的特征项;A为属于类别ci且包含特征项t的文档频数;B为不属于类别ci但包含特征项t的文档频数;C为属于类别ci但不包含特征项 t的文档频数;D为既不属于类别ci也不包含特征项t的文档频数;N为训练语料中的文档总数。
式(1)的结果反映了特征项t和文档类别ci之间的相关程度。统计值越大,特征项t和文档类别越相关;当CHI(t,ci)=0,表示特征项t和文档类别ci是相互独立的。
2.2 卡方统计量分析和改进
Yang[5]的研究表明,CHI特征选择方法相对于传统的特征选择方法效果要好,但仍然存在一些问题:
1)卡方统计量衡量的是特征项t和类别ci之间的相关程度,特征项对于某类的卡方值越高,其与该类之间的相关性越大,携带的类别信息越多。分析式(1),当AD-BC>0时,说明特征项t和类别ci正相关,即特征项可能出现在类别ci中,CHI统计量越大,说明特征项t和类别ci的相关程度越大,可以作为特征选择的特征项;当AD-BC<0时,说明类别和特征项呈负相关,此时计算出的CHI统计量的值越大,反而特征项t和类别成负相关程度越大。文献[13]指出,文本分类中,特征的重要性主要是由正相关因素决定的,此时的特征项t,不适合保留。所以,当AD-BC<0时,将此时特征项t的CHI置为0,在计算中不予考虑。
2)卡方统计方法只考虑了特征项出现的文档频数,而没有考虑到词频的影响,夸大了低频词的作用。如果一个特征项t只在某一类的少量文档中频繁出现,则计算出来的卡方统计量的值比较小,有可能在特征选择的时候被排除掉。但该特征项可能在某一类中具有很好的区分性。
针对此问题,将特征项的频度考虑到卡方统计量的计算当中,但以前的工作[5~11]没有考虑到每篇文档长度的不一致,实际的评论文本中,文本的长度差异可能很大。为此考虑文档的长度,提出对每篇文档的词频进行归一化方法。设训练文本中类别有类别C={C1,C2,…,Cm};训练集中类别Ci中有文本Ci={di1,di2…din};特征项t在文本dij(1≤j≤n)出现的频度为tfij;dfij表示文本dij(1≤j≤n)中特征词的个数;Ni表示类别Ci的文档总数。则特征项t在类别Ci中出现的归一化长度频度 (normalizedlengthfrequency,NLF)表达式如下
(2)
在一个类中不仅词频大小,还考虑词频的分布,一个特征项t在类别ci中的分布越均匀比集中分布要更有价值,更值得保留。提出词频分布(frequencydistribution,FD),采用式(5)衡量分布
(3)
式中 α为很小的一个数,实验中将α设为0.001。
FD反映特征项t在类别中的词频分布,FD越小,说明特征项词频在类别ci分布越均匀,特征更有价值。综合考虑词频在文本中的归一化词频和词在类中的分布,形成归一化词频 (normalizedfrequency,NF)表达为
(4)
引入此公式主要解决卡方统计量只考虑文本的频数,而没有考虑词频的问题。同时考虑到实际当中文本长度的不同和FD,对词频进行了归一化的处理,通过式(4)计算得到特征t对类ci的NF。
3)为了使改进的算法适合不均衡情感文本分类,将文献[8]中阐述的集中度和分散度引入到卡方特征计算中。集中度 (concentrationinformation,CI)越大说明特征越集中在某一类当中,特征项越有价值。分散度 (distributioninformation,DI)表示一个特征项是否在一个类中均匀分布,DI越大表示该特征项在一个类中的分布越广。假设A表示含有此特征t的类ci的文档数,B表示含有特征项t,但不属于ci类的文档数,C表示不含有特征项t的类ci文档数。集中度CI和分散度DI分别表示为
(5)
(6)
改进后的算法,考虑到词频和FD,更加倾向于选择特征词出现的NF多,且均匀分布在一个类的特征,同时去对负相关的情况进行了处理,改进后的词频归一化卡方统计量(normalizedfrequencyChi-squarestatistic,NF-CHI)特征提取算法,其计算式如下
(7)
3 实验结果与分析
3.1 实验数据设置与流程
实验数据与工具:对于中文文本分类存在分词问题,分词的准确率会影响分类的结果,而英文一个单词就可以表示一个特征项,不会因为分词对文本分类的结果造成影响,所以选择英文电影评论语料。选择斯坦福学者采集的英文电影评论语料[15],其中包含12 500个正向情感语料,12 500个负向情感语料。
情感分类一般包括预处理、特征选择、特征表示、特征加权、分类训练和分类结果衡量。对英文文本进行预处理,包括去除停词、词形还原(lemmatization)和词根还原(stemming)。词形还原是把一个任何形式的语言词汇还原为一般形式(能表达完整语义),例如将“drove”处理为“drive”,在根据停词词典去除停词;词根还原指抽取词的词干或词根形式,例如将“effective”处理为“effect”,本文将对预处理的方式进行研究,找到最佳的预处理方式。
进行特征选择,采用传统的卡方特征统计量(CHI)与本文提出的NF-CHI特征选择算法。本文使用文本分类中常用的TF-IDF权重算法计算向量中各特征词的权重值。
本文采用Weka3.6数据挖掘开源工具进行文本分类验证,输入各文档的特征权重值文件。分别采用朴素贝叶斯 (naive Bayes,NB) 算法和支持向量机(SVM)算法进行分类实验。在平台的设置中,采用十折交叉验证,即将数据集分成10份,轮流将其中的9份作为训练语料,1份作为测试语料,最后输出平均得到的结果。
3.2 实验效果评价标准
文本分类的性能评价指标主要是召回率R准确率P和F值(F1-measure)。
假定:类别ci的分类结果中,a为分类器将输入文本正确地分类到类别的个数,b为分类器将输入文本错误地分到了某个类别的个数,c为分类器将输入文本错误地排除在某个类别之外的个数。具体公式如下
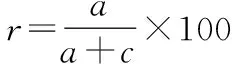
(8)
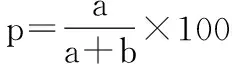
(9)

(10)
3.3 实验结果与分析
实验1,不同预处理对文本分类结果的影响,对英文文本的预处理包括去停词,词形还原,词根还原。首先定义以下4个数据集:数据集DN0,原始语料不进行任何处理;数据集DN1,在数据集DN0基础上进行词形还原;数据集DN2,在数据集DN1基础上进行去除停词操作;数据集DN3,在数据集DN2基础上进行词根还原。从语料库中选择2 000篇正向语料,2 000篇负向语料,采用CHI提取400维特征,采用TF-IDF权重算法加权,分别SVM进行分类,其准确率见表1。
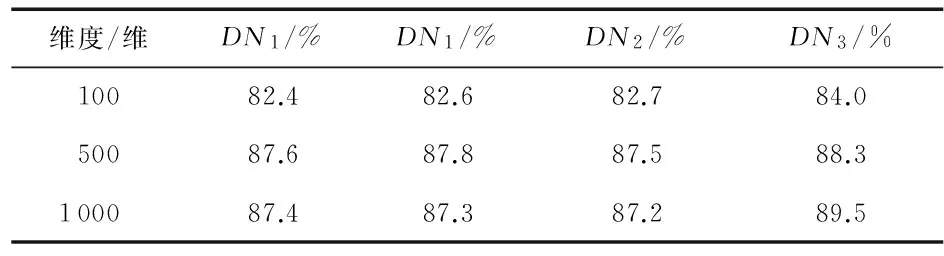
表1 不同预处理SVM分类器下的准确率
从表1中可以看出:采用DN3的数据集的准确率最高,即对数据集进行词形还原、去除停词和词根还原,后面的实验将采用此方案对实验进行预处理。
实验2,基于均衡语料的对比实验。从语料库中选择2 000篇正向语料,2 000篇负向语料,分别采用的传统的CHI和本文提出的NF-CHI特征提取算法提取400维特征,采用TF-IDF权重算法加权,分别SVM进行分类,结果如表2。

表2 400维度SVM分类器下两种方法对比 %
根据表2可以看出:改进的NF-CHI特征提取算法相比传统的CHI特征提取算法在提取400维特征时,改进的算法SVM分类的效果平均准确率P,平均召回率R和平均的F值都有一定的提高。说明改进的CHI提高了情感文本分类的准确率。
实验3,改进的NF-CHI方法和传统CHI的特征提取的方法在不同维度下对比实验。选取正负情感语料各2 000篇,采用SVM分类器,分别在不同维度下进行改进的卡方特征提取算法和传统的卡方特征提取算法进行实验,最后进行准确率的比较,实验结果如图1。
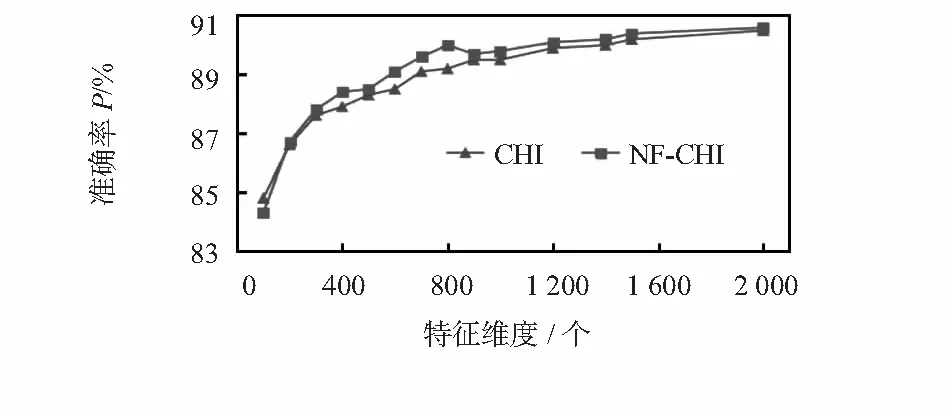
图1 不同维度下SVM分类器的准确率
从图1看出:采用SVM分类时,采用NF-CHI特征选择后的分类的准确率比传统的CHI的准确率有小幅提升。在维度为800时提升最大,达到0.8 %,准确率最高达到90.6 %。说明改进的CHI提高了情感文本分类的准确率。
实验4,基于不均衡语料的对比实验。一般真实评论中正向的评论大于负向的语料,实验选择2 000篇正向语料。1 000篇负向语料,使用NB分类器分类,在不同维度下进行NF-CHI特征提取算法和传统的CHI特征选择进行比较。不同维度的F值见实验结果图2。
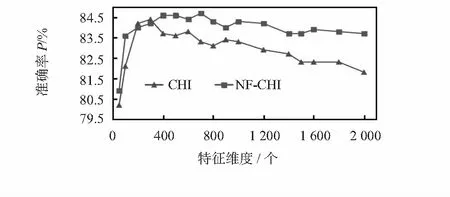
图2 不均衡语料下NB分类器F值
从图2中看出:改进后的特征选择算法分类的F值普遍比传统的CHI要高,开始随着特征维度的增加F值提高,当维度达到300,出现过拟合现象,传统CHI文本的分类F值反而下降;但改进的NF-CHI特征选择后的分类的F值仍然上升,到700维的时候达到峰值,此时F值为84.7 %。通过图2看出改进的NF-CHI的下降幅度更小,表明改进的算法更加稳定。维度在700维,本文提出的方法F值比传统的CHI提高了1.4 %。实验结果表明,本文提出的NF-CHI算法对非均衡语料同样有效。
实验5,基于混合长短文本语料的对比实验。为了验证改进NF-CHI特征提取算法对文本长短差异较大的语料同样适用,分别从正负向情感的12 500篇语料库中人工取出1 000篇长文本与1 000篇短文本,选取结果中其中长文本最短含有468单词,短文本最多含有的单词数为109个。使用SVM分类器进行分类,在不同特征选择维度下进行分类准确率对比。实验结果见图3所示。

图3 混合长短文本语料的SVM分类器的准确率
从图3中看出:本文提出的NF-CHI特征提取算法进行分类的准确率普遍高于传统的CHI, 随着维度的增加,分类效果提高,在维度达到1 400时,本文提出的NF-CHI准确率达到88.8 %。实验证明,本文提出的NF-CHI算法对混合长短文本的语料同样有效。
4 结束语
本文对情感文本分类的研究中,针对英文不同的预处理方式进行研究,发现采用词形还原,去除停词,词根还原的预处理方式准确率最高,同时针对CHI特征提取算法存在负相关现象以及倾向于选择低频特征词的问题。本文考虑词频和词频的分布,提出一种NF,并过滤掉负相关的词,引入集中度和分散度的因素,得到一种改进的卡方特征选择算法。最后采用NB和SVM算法对均衡语料,非均衡语料和混合长短文本的语料上分别进行分类实验,实验结果表明:相比传统的卡方特特征提取算法本文提出的方法提高了情感文本分类准确率。后续的工作中,对情感进行多层次的分类,并尝试融入语义层次上的特征,进一步地提高情感分类的准确度。
[1] 杨立公,朱 俭,汤世平.文本情感分析综述[J].计算机应用,2013,33(6):1574-1607.
[2] 赵妍妍,秦 兵,刘 挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[3] 李 杰,周 萍.语音情感识别中特征参数的研究进展[J].传感器与微系统,2012,31(2):4-7.
[4] 程广涛,陈 雪,郭照庄.基于HOG特征的行人视觉检测方法[J].传感器与微系统,2011,30(7):68-70.
[5] Yang Y,Pedersen J O.A comparative study on feature selection in text categorization[C]∥Proceedings of the Fourteenth Internatio-nal Conference on Machine Learning,Morgan Kaufmann Publi-shers Inc,1997:412-420.
[6] 熊忠阳,张鹏招,张玉芳.基于χ2统计的文本分类特征选择方法的研究[J].计算机应用,2008,28(2):513-514.
[7] 裴英博,刘晓霞.文本分类中改进型CHI特征选择方法的研究[J].计算机工程与应用,2011,47(4):128-130.
[8] 王 光,邱云飞,史庆伟.集合CHI与IG的特征选择方法[J].计算机应用研究,2012,29(7):2454-2456.
[9] 邱云飞,王 威,刘大有,等.基于方差的CHI特征选择方法[J].计算机应用研究,2012,29(4):1304-1306.
[10] 徐 明,高 翔,许志刚,等.基于改进卡方统计的微博特征提取方法[J].计算机工程与应用,2014(19):113-117.
[11] 肖 雪,卢建云,余 磊,等.基于最低词频CHI的特征选择算法研究[J].西南大学学报:自然科学版,2015(6):137-142.
[12] Jin C,Ma T,Hou R,et al.Chi-square statistics feature selection based on term frequency and distribution for text categoriza-tion[J].IETE Journal of Research,2015,61(4):1-12.
[13] Galavotti L,Sebastiani F,Simi M.Experiments on the use of feature selection and negative evidence in automated text categorization[C]∥Proceedings of the 4th European Conference on Research and Advanced Technology for Digital Libraries,Springer-Verlag,2000:59-68.
[14] Maas A L,Daly R E,Pham P T,et al.Learning word vectors for sentiment analysis[C]∥Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies,Association for Computational Linguistics,2011:142-150.
Study on sentiment text classification based on improved CHI feature selection*
YUAN Lei
(School of Computer and Information,Hefei University of Technology,Hefei 230009,China)
In order to improve the accuracy of sentiment text classification,different preprocessing methods of the sentiment of English text is studied,and an improved algorithm of Chi-square statistic(CHI)feature extraction is put forward.CHI is one of the most efficient feature selection methods,but there are two weaknesses,negative correlation phenomenon and tend to choose low-frequency feature words.In order to overcome these two shortcomings,on the basis of taking into account factors of word frequency,concentration information and dispersion information,considering the length of the text is not balanced and the distribution of feature words,word frequency is normalized,CHI feature extraction algorithm is proposed.Using classical naive Bayes and support vector machine(SVM)classification algorithms experiments is carried out on balanced corpus,imbalanced corpus and mixed-length corpus,and experimental results show that the new method improves accuracy of sentiment text classification.
sentiment classification; preprocessing; Chi-square statistic(CHI); feature selection
10.13873/J.1000—9787(2017)05—0047—05
2016—05—19
国家自然科学基金重点资助项目(61432004);安徽省自然科学基金资助项目(1508085QF119);中国博士后基金资助项目(2015M580532);模式识别国家重点实验室开放课题资助项目(201407345)
TP 391
A
1000—9787(2017)05—0047—05
袁 磊(1991-),男,通讯作者,硕士,研究方向为数据挖掘,Email:yuanlei_uestc@163.com。
猜你喜欢
临床肝胆病杂志(2022年6期)2022-11-25
汽车实用技术(2022年16期)2022-08-31
现代电生理学杂志(2021年3期)2021-12-05
电子制作(2017年23期)2017-02-02
中国修辞(2017年0期)2017-01-31
中文信息(2016年1期)2016-07-03
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
