
基于Bayesian网IP网络拥塞链路定位算法
2017-05-10 01:57:28周欣,周巍
电子科技大学学报 2017年3期
周 欣,周 巍
(西北工业大学自动化学院,电子信息学院 西安 710072)
基于Bayesian网IP网络拥塞链路定位算法
周 欣,周 巍
(西北工业大学自动化学院,电子信息学院 西安 710072)
在借助E2E路径性能主动探测技术进行内部拥塞链路推理的网络层析成像方法中,传统的利用路径探测计算链路丢包率的方法涉及线性方程组求逆,其计算量过大可能导致算法失效。对此,该文提出一种基于布尔代数的IP网络拥塞链路定位算法,通过对求解先验概率的线性方程组构造满秩系数矩阵,从而计算出各链路拥塞先验概率,再借助贝叶斯最大后验概率算法推理定位当前时刻拥塞链路集合。实验验证了该算法的有效性及准确性。
贝叶斯最大后验概率; Boolean代数; 拥塞链路推理; IP网络
如何在网络中进行快速故障定位进而保障业务的正常运作,成为IP网络故障管理的核心问题。根据端到端的测量来推断内部链路特性的方法被称为网络Tomography方法,并根据求解方式不同分为两类:第一类需要在广播探测数据包之间存在很强的时间相关性[1-2],并进行矩阵求逆;第二类利用解决布尔代数求逆的方法推导网络中拥塞链路的分布[3-4]。在第一类中,文献[5-6]利用发送多播探测数据包的方法推算网络链路丢包率,但受到现实网络中支持多播路由器的数量限制。此类方法与多播副本相比准确率较低,开发和管理的费用却很高;同时计算链路丢包率的迭代算法应用于大规模网络中的实时代价过高。在第二类方法中则是采用不相关的端到端测量值来识别拥塞链路。这里通常要假设所有链路具有相同的拥塞先验概率0P,且0P比较小。但在实际网络环境中,每个链路具有的拥塞概率不可能都相同,且当0P较大时此类算法的结果也比较差[4]。文献[7]利用ICMP回送请求来推断丢包率,但由于安全和性能等原因使得许多路由器限制了对该类请求的反映,因此实时性较差。
针对以上问题,本文使用一段时间内多个快照求路径丢包率,再利用一种基于贝叶斯网络的拥塞链路定位算法(Bayesian network–based congested link position algorithm, BNCLPA)获得链路拥塞先验概率,然后在下一次快照中使用最大后验估计(MAP)寻找拥塞链路。
1 网络和性能模型
1.1 网络建模
首先,利用贝叶斯网络模型有向图g=(ν,ε)对拥塞链路集合定位问题进行建模。其中,ν表示网络中的节点,ε表示节点间的通信链路,数量分别为nν=|ν|和ne=|ε|;VB表示所有优势点的集合且 nB为其中的点数,Ps,t为从源点s到目的节点t所经过的路径,表示优势点之间路径的集合且其中的路径数为nP=nB(nB−1)=|P|。对于一个已知的g=(ν,ε) 和 P,按照下述方法计算选路矩阵D(nP×ne):若路径Pi包含链路ej则Dij=1,否则Dij=0。D的一行对应一条路径,一列对应一条链路。若D的某一列为全零,则丢弃这些列得到矩阵D(nP×nc),nc表示非零链路的数量且 nc≤ne。εc表示至少被P中的一条路径所包含的链路集合且|εc|=nc。图1所示的IP网络共有9个节点和9条链路,其中节点1和2为源节点,节点6~8为目的节点,路径与链路的对应关系如表1所示。
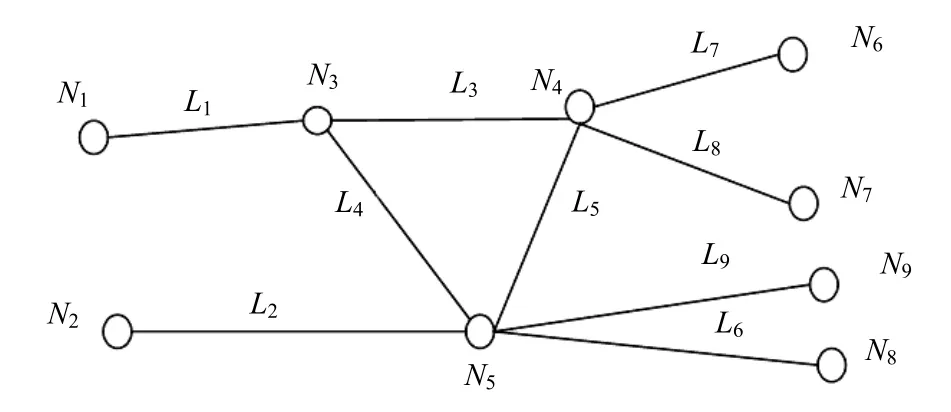
图1 IP网络

表1 路径与链路关系
根据表1可以得到选路矩阵为:

1.2 性能建模
若已知网络拓扑和端到端的路径丢包率,则链路丢包率和路径丢包率之间为线性关系:

式中,φi表示路径Pi的传输率;φek表示链路ek的传输率。为了确定链路的传输率,需要求解式(3)。由于许多网络中的D不是满秩矩阵,即其秩r(D)<min(nP,nc),所以式(3)的解不唯一。
本文的目的是识别拥塞链路,因此可以做以下改进:阈值tl表示根据应用程序指定的极限值,当φek≥tl时认为链路ek是连通的,否则链路ek就是拥塞的;变量yi表示路径iP的状态,当iP是通的yi=0,当 Pi是拥塞的yi=1;变量xk表示链路ek的状态,当ek是通的xk=0,当ek是拥塞的xk=1。
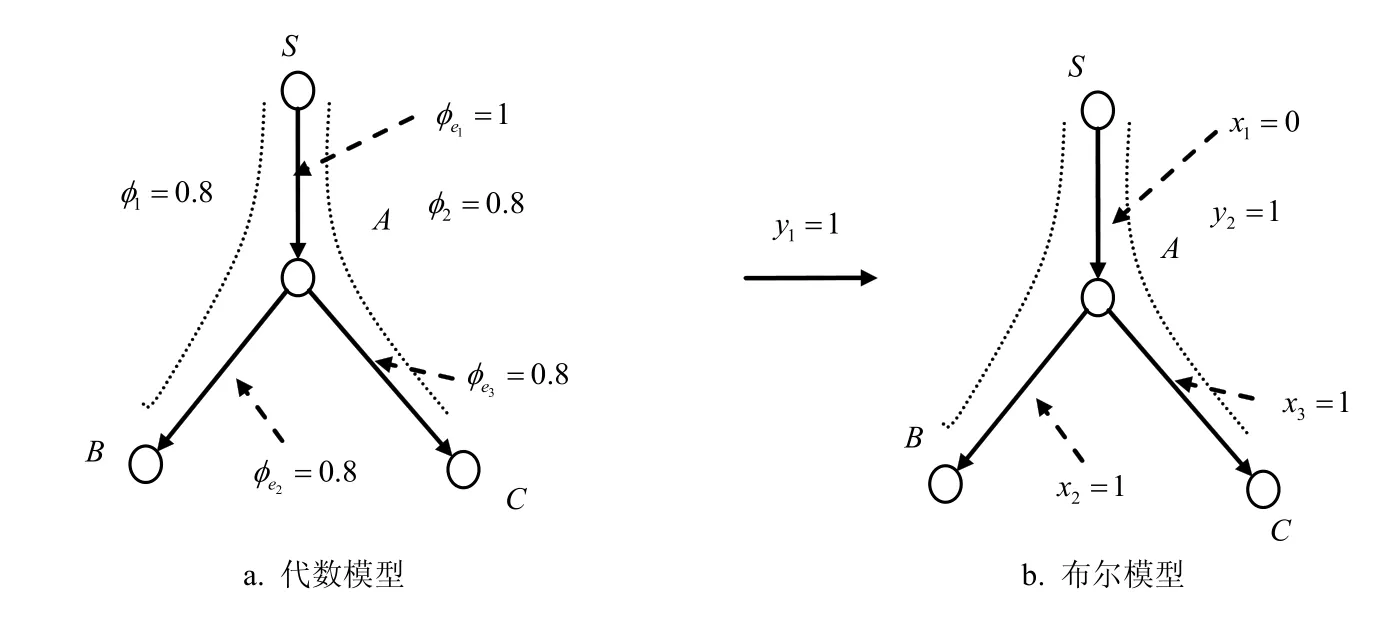
图2 代数模型向布尔模型转化
建立一个布尔线性代数方程组:

式中,‘V’表示二进制最大操作;‘⋅’表示通常的乘法操作。式(4)可以用向量表示为:

式中,dk表示矩阵D的第k个列向量。图2说明了从线性代数到布尔代数的转换。图中e1=SA是好的链路且φe1=1,e2=AB及e3=AC都是拥塞链路且φe2=0.8、φe3=0.8。令t1=0.9,则tp=0.92=0.81,路径1P(S到B)和P2(S到C)都是拥塞的。
在布尔代数中,路径传输率和链路传输率之间是线性关系,而链路状态和路径状态也呈线性关系。一般来说,当且仅当D的所有列在布尔代数中都线性无关时此方程才有唯一的解,但实际中很难满足。因此,需要利用网络中链路的其他信息来找到式(4)最有可能的解。首先,用向量表示链路状态概率,在理论上可以从端到端的测量中获得p。本文提出了一种利用BNCLP算法从较少的快照中估算p,再把p作为一个链路状态的先验概率,利用已知信息寻求确定真正拥塞链路的方法。
2 BNCLPA算法
BNCLPA算法的原理框图如图3所示。

图3 BNCLPA算法原理框图
2.1 先验概率学习
首先,设链路概率向量为p,检测网路链路集合的概率为Pp,X是nc维随机二进制向量,Y为nP维随机二进制向量。若链路状态概率满足对任何y有 Pp(Y=y)=P(Y=y),则p=。为了避免传统方法中使用最大期望(expectation-maximization, EM)算法求解p时的计算代价过高且不具备全局收敛性的问题,本文利用数学期望求解的方法对式(4)进行推导,求出链路x的概率值。
对所有1≤ i≤np,有:
由于 r(D)<min(np, nc),所以需通过高阶矩阵空间相关特性提供更多的信息。定义Yij为二进制随机变量,当路径i及j正常时Yij=0,否则Yij=1,则:

对所有满足1≤ i≤j≤np的(i,j)对,定义:
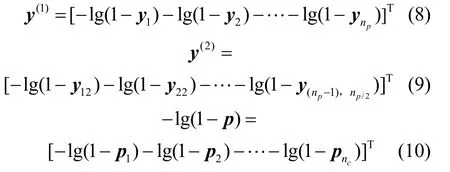
结合式(6)和式(7)系统线性方程组为:
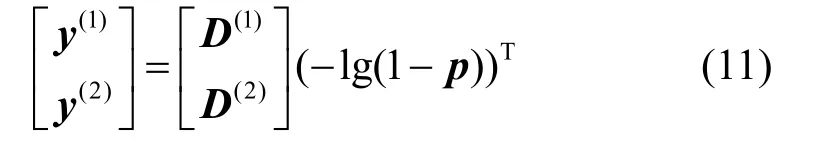
由此可构造满秩矩阵。在实际网络中可以化简选路矩阵来减少求解式(11)的计算复杂度。如图1所示的IP网络,若根据m次快照测得ya=0,则L1、L4、L6全部为通的,把式(2)中的矩阵D进行化简得到:
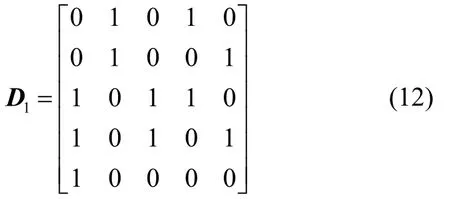
然后进行初等行变换得到:

根据D1和D2得到最大线性无关组组成矩阵为:

D3即式(13)中的D[1]。将D3进行最大化操作得到:

从D4中选出一行加入到D3中,形成的满秩矩阵D5,即为式(13)所需满秩矩阵:

而对于式(13),选择D2第一行与D3构成一个满秩矩阵,得到式 (11)中D(2)=[0 1 0 1 1],。通过对取逆可求得链路的先验概率p。而在nc这条链路中,未参与式(11)计算的链路的概率值为0。
2.2 拥塞链路定位算法
设定已知信息选路矩阵为D(np×nc),网络中np条路径最近一次快照值为Y,已求得链路状态的先验概率为P。首先,定义最大评分参量argmaxxPp(X=x|Y=y)为拥塞链路集合的最大后验估计,Pp(⋅)为条件概率,则由贝叶斯公式可得:

式中,Pp(Y=y)仅依赖网络状态检测,与x的选择无关,故最大评分参量可表示为:

由于链路状态xk是独立随机变量,则:

在给定X=x,Yi=0且Dikxk=0或等价于(1−Dik)xk= 1时,有:
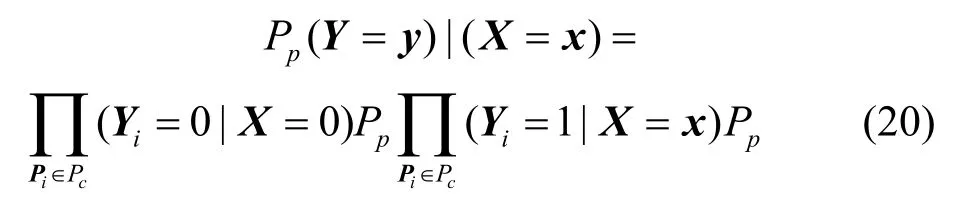
可知概率为1或者0。定义R为从D[1]中移除所有正常路径行以及其对应链路的所有列,Rε是R中列的集合,那么对于链路集合χ∈Rε,所有的拥塞路径至少覆盖一条链路在χ中,有:

取对数再移除与x的取值无关的项得到:

3 仿真实验及结果分析
对于主动探测技术,网络拓扑在很大程度上影响了探测结果,从而影响到故障诊断的结果。Brite[8]拓扑产生器是网络仿真实验中常用的网络拓扑生成工具,它可以生成3种网络拓扑模型Waxman[9]、BA[10]和GLP[11]。其中BA模型和GLP模型都是幂率类型,而GLP模型更接近于实际网络的结构特征,可以较准确地模拟真实IP网的拓扑情况。因此,本文采用Brite产生的GLP模型来进行仿真实验。
在仿真实验中,需要在不同的网络拥塞层次下对算法进行评价。本文使用丢包模型LM1[4],其中拥塞链路的丢包率分布在0.05~1之间,好链路的丢包率在0~0.01之间。每条链路都有一个指定的丢包率,所以每条链路的实际丢包都遵循Gilbert过程,链路的状态在不丢失任何数据包与丢失所有的数据包之间来回波动。
本文利用Java语言中的Eclipse开发平台模拟端到端到探测、拥塞事件及算法推理。在求解链路拥塞概率pk时,考虑到式(13)中的系数矩阵是一个稀疏矩阵,采用迭代法来求解。同时,在求解pk时实现Java程序对Matlab程序的调用,以更方便有效地得到计算结果。
1) 拥塞率f对DR和FPR的影响。由Brite拓扑生成器产生100个节点的拓扑,拥塞链路的百分比f∈[0.1,0.45],步长为0.05,连接某节点的总链路数d=7,学习先验概率时的快照次数m=40,拥塞链路的门限值t=0。从图4中可以看出,随着f的增加,算法的检测率DR和误检率FPR会越来越低。


图4 DR和FPR随f的变化趋势图
2) 快照次数m对DR和FPR的影响。拓扑规模分别为100、200和300个节点,m在5~100之间变化,d=7,f=0.1,t=0。从图5中可以看出:当m<30时,DR较低而FPR较高,说明快照次数太少无法准确得到链路的先验拥塞概率,导致算法的DR较低而FPR较高,因此在推断网络故障时快照次数不能低于30;但是m并不是越大越好,若m过大如超过40后,DR并不会继续升高而FPR也不会降低,同时主动测试时发包数量过多会导致网络负载增加、时间成本过大,影响算法的时效性。因此,在学习链路的先验拥塞概率时,应使30≤m≤40。

图5 不同拓扑规模的DR和FPR随m的变化趋势图
3) 拓扑规模对DR和FPR的影响。生成的网络拓扑规模在50~350之间变化,f=0.1,t=0,d=7, m=30。从图6可以看出:DR随着拓扑规模的增大而呈下降趋势,并在一定的范围内有所波动,但是下降的幅度不大,速度也不是很快;而FPR随着拓扑规模的增大,而呈上升趋势,并在一定的范围内有所波动,但是上升的幅度不大,且上升的速度也不是很快。这说明BNPDA算法对拓扑规模的变化具有较好的稳定性。

图6 拓扑规模对DR和FPR的影响
4 结 束 语
针对现有方法在网络链路故障诊断方面的不足,本文提出了一种基于贝叶斯网的故障诊断算法BNPDA。该方法采用主动测量方式测量网络端到端的性能,需要在被测网络中部署探针硬件设备;同时主动测量时所发的探测包也会在网络中产生新的流量,增加网络负载。如何在达到监测网络的情况下,尽量减少探针的部署和探针的发包数量,以减少对网络的影响以及监测系统的维护代价,同时获取更多的网络信息是今后研究的重点之一。
[1] OGINO N, KITAHARA T, ARAKAWAET S, et al. Decentralized Boolean network tomography based onnetwork partitioning[C]//In NOMS’16: IEEE/IFIP Network Operations and Management Symposium. Istanbul: IEEE, 2016: 162-170.
[2] DENG K, LI Y, ZHU W, et al. Fast parameter estimation in loss tomography for networks of general topology[J]. The Annals of Applied Statistics, 2016, 10(1): 144-164.
[3] DUFFIELD N G. Network tomography of binary network performance characteristics[J]. IEEE Trans on Information Theory, 2006, 52(12): 5373-5388.
[4] BATSAKIS A, MALIK T, TERZIS A. Practical passive lossy link inference[C]//Proc of PAM 2005: 6th International Workshop. Boston: Springer Berlin Heidelberg, 2005, 3431: 362-367.
[5] NGUYEN H X, THIRAN P . The Boolean solution to the congested IP link location problem: Theory and practice[C]//Proceedings of IEEE INFOCOM’07: 26th Annual IEEE Conference on Computer Communications. Alaska: IEEE, 2007: 2117-2125.
[6] DUFFIELD N G, PRESTI F L, PAXSON V, et al. Inferring link loss using striped unicast probes[C]//Proceeding of the IEEE INFOCOM’01: Conference on Computer Communications. [S.l.]: IEEE Communications Society, 2001: 915-923.
[7] MAHAJAN R, SPRING N, WETHERALL D, et al. User-level internet path diagnosis[C]//Proceedings of the 19th ACM Symposium on Operating Systems Principles. New York: ACM, 2003: 106-119.
[8] MEDINA A, LAKHINA A, MATTA I, et al. BRITE: an approach to universal topology gerneration[C]//Proceedings of MASCOTS: Proceedings Ninth International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems. Washington: IEEE, 2001: 346-353.
[9] WAXMAN B M. Routing of multipoint connections[J]. IEEE Journal of Selected Areas in Communication, 1988, 6(9): 1617-1622.
[10] BARABASI A L, ALBERT R. Emergence of scaling in random networks[J]. Science, 1999, 286(5439): 509-512.
[11] PALMER C R, STTEFFAN J G. Generating network topologies that obey power laws[C]//Proc of the GLOBECOM 2000: Global Telecommunications Conference. San Francisco: IEEE, 2000: 434-438.
编 辑 漆 蓉
IP Network Congested Link Location Algorithm Based on Bayesian Network
ZHOU Xin and ZHOU Wei
(School of Automation, School of Electronics and Information, Northwestern Polytechnical University Xi’an 710072)
In the method of end-to-end (E2E) path performance active detection (network tomography), the link loss rate solution methods involve the inverse of linear equations, so its large computation complexity may lead to failure. This paper proposes a new congestion link location algorithm based Boolean model. First the nonsingular coefficient matrix of the linear system for solving prior probability is formed; then the prior probability of link congestion is calculated. Finally, based on Bayesian maximum a posteriori probability (MAP) estimator, the set of congested links can be located. The validity and accuracy of this algorithm is verified by experiments.
Bayesian MAP; Boolean model; congested link location; IP network
TP393.09
A
10.3969/j.issn.1001-0548.2017.03.010
2016 − 06 − 23;
2016 − 10 − 11
国家自然科学基金(61602383);中央高校基本科研业务费(3102016ZY024)
周欣(1982 − ),女,博士,主要从事信息处理方面的研究.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17 06:27:42
天津科技(2022年5期)2022-05-31 02:18:08
计算机与数字工程(2022年1期)2022-02-16 08:32:54
电讯技术(2018年10期)2018-10-24 02:35:00
数理化解题研究(2017年4期)2017-05-04 04:07:54
网络安全和信息化(2017年3期)2017-03-10 07:45:51
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
铁道科学与工程学报(2015年4期)2015-12-24 12:11:24
网络安全和信息化(2015年11期)2015-03-17 21:54:44
