
Microblog User Recommendation Based on Particle Swarm Optimization
2017-05-09 03:14LingXingQiangMaLingJiang
China Communications 2017年5期
Ling Xing , Qiang Ma , Ling Jiang
1 School of Information Engineering, Henan University of Science and Technology, Luoyang 471023, China
2 School of Information Engineering, Southwest University of Science and Technology, Mianyang 621010, China
3 School of Mathematics Science and Computer, Wuyi University, Wuyishan 354300, China
* The corresponding author, email: xingling_my@163.com
I. INTRODUCTION
For social network services, user recommendation is an important way to establish stable relationships among users, which aims to increase user engagement. The key to the success of the recommendation is to make a reasonable evaluation of the influence of user.
Previous studies on Microblog user recommendation mainly focuses on utilizing simple statistics, such as the number of the user’s followers and the number of the user’s followees1If user A follows user B,then B is referred to as A’s followee., to build recommendation models.Due to the incapacity of the simple statistics to reveal the complex relationships among users,such an approach usually fails to generate satisfying recommendations [1-3]. For instance,using the number of followers to indicate the influence of a user often results in a “celebrity-dominated” recommendation. That is, users who have lots of followers are recommended to the target user, even if they have nothing in common with the target user. To make things worse, the celebrities themselves may be unreliable if there exist many “zombie fans”.
Currently, the strategies applied to Microblog user recommendation can be roughly categorized into three types: (i) collaborative filtering based strategies [4-7], which are widely applied to movie recommendation,music recommendation, etc. Collaborative filtering algorithms utilize the preference of a user group to recommend items to the target user, but the interest of the target user is not thoroughly analyzed; (ii) content based strategies, which utilize content and contextual feature to recommend personality photos to target users [8], or utilize the semantic patterns of regular activity to recommend user interest contents [9]; (iii) user relationship based strategies, which utilize the social circles and personal interest that the user has forwarded to recommend hotspot information or other items[10]. In addition to above strategies, recently many graph-based methods are proposed for recommendation. For example, in Wanget.al.’swork, the online video recommendation system is modeled with social network and video content, and theory of diffusion kinetic is applied to generate recommendations, with the purpose of alleviating the data sparsity and cold start problem [11].
In this paper, the authors proposed a PSO-based recommendation strategy to deal with the negative effect caused by celebrities and zombie fans.
Current studies on user recommendation are mainly based on the transitivity property of friendship. This allows us to recommend friends to users via clustering approaches based on the strong ties in social networks.In addition to the strategies mentioned above,machine learning-based strategies [12,13],top-k recommendation strategies [14,15], and time-based strategies [16] have also been proposed for Microblog user recommendation.One drawback of these studies is that all the users, whether they are targets or not, are treated with the same weights for recommendation.The specific context of the target user is not considered. As a result, the recommendations often incline to the celebrities.

Fig. 1 Topology illustration of Microblog user network
Moreover, in early studies on user recommendation, the recommendation strategy values the number of followers too much. Hence,the recommendation results are corrupted by those zombie fans. To overcome these drawbacks, in this paper we focus on the target user and apply particle swarm optimization(PSO) to user recommendation. Specifically,we propose a PSO-based algorithm to evaluate the relative influence of a Microblog user,where the update rule of the particle’s velocity is defined based on the interactions among users. The influence, together with the activity of a user and the coherence between users,are utilized by the proposed recommendation strategy to form clusters of users, from which the topKusers is chosen and recommended to the target user. Experimental results show that the proposed method has good precision and recall rate. The recommendation results are robust to zombie fans and celebrities.
II. PRELIMINARIES
2.1 Topological structure of Microblog network
Similar to other social networks, a Microblog user can establish its network by following others. Fig.1 shows a simple example. The follow relationship, fans, followees are defined as follows:
Follow relationship: If userafollows userb, denoted asa→b, thenaisb’s follower. Followerais often referred to asb’s fan, andbis referred to asa’s followee . As shown in Fig.1,there is an arrow fromdtoa, meaning thatdisa’s fan andaisd’s followee. And the weight of the arrow is 1.
Set of fans: Denote the set of a user’s followers, namely fans, asFans(·). As shown in Fig.1,Fans(a)={b,c,d,e}.
Set of followees: Denote the set of a user’s followees asFollowee(·). As shown in Fig.1,Followee(a)={b,e}.
The topology of the user network is dynamic, in the sense that it changes with the activ-ities of users and interactions among users.The objective of user recommendation is to find the user who is most relevant to the target user, by analyzing recent behaviors of users.
2.2 Particle swarm optimization
As a classic swarm intelligence-based optimization algorithm, PSO has the advantage of simple principle and easy operation [17-18].In a population of simple agents, interactions among individual agents lead to the emergence of intelligent collective behavior. This phenomenon is referred to swarm intelligence.PSO utilizes the self-organization feature of the population to find the optimal solution to a problem. That is, without a centralized control structure dictating how individuals should behave, individual interacts with each other according to its own judgment. The local behaviors have an impact on the whole population.
Each user in Microblog network is regarded as a population of intelligent agents. By functions implemented in the Microblog platform,such as posting a tweet, forwarding or commenting a tweet, following a user, searching users or tweets, etc., users share information with others. One user’s behavior is influenced by others’ behaviors. In this paper, the influence of a user is evaluated from several aspects, i.e, (i) the number of tweets that the user has posted. The more tweets a user posts,the more active the user is. (ii) The number of a user’s fans. (iii) The number of tweets that a user has forwarded. (iv) The number of tweets which are commented, liked, or tagged as “favorite” by the user. Details of the evaluation method are described in Section 3.
The behavior of a Microblog user is affected by both the cognitive level of the user and the network environment. In Microblog network, since users interact with others, the long-term behavior of a user shows characteristics of both stability and gradual change.Stability means that the internal factors, which affect the cognitive level of users, change slowly. Hence these factors impose inertial constraints on users’ behavior. The gradual change in user’s behavior is resulted from the social interactions among users. A user continuously receives tweets shared by its friends.Naturally, one’s values and interests change gradually with its friends. In the macroscopic view, the population of Microblog users has a de-centralized structure and the self-organization characteristic. Considering that such a population fits the principles of proximity,diversity, stability, and adaptability, we model Microblog users as agents in an intelligent swarm.
2.3 Data preprocessing
According to the “six degree of separation”and the “weak-tie” theory in social networks,we utilize the second contacts and the third contacts of the target user for recommendation. Second contacts refer to the fans of a user’s fans. Third contacts refer to the fans of second contacts. A formal definition of second contacts is given by

whereF1(u)=Follow(u)denotes the fans of the useru, i.e., the first contacts ofu. Note that users inF1(F1(u)) who directly follow the useruare removed from the second contacts. Also, if the user itself shows inF1(F1(u)), it should be removed. Similarly, the third contacts can be defined as

Denote the union ofF2(u) andF3(u) asR_U(u). We use this set of users to compute recommendations for the useru.
When using Microblog services, users generate various types of data, including user profile data, Microblog status data, user relationship data, and interactive behavior data, etc.The former three types of data are exploited in this paper for user recommendation. More specifically, given a set of users, we use the API (Application Program Interface) provided by Sina Weibo2http:// weibo.com/to collect each user’s basic information (e.g., the number of fans) and the tweets it has posted. Some meta data about the tweet, such as the creation time, the number of times it has been forwarded, etc., are recorded.The content of the tweet is not used. We also use the API to obtain the set of fans and fol-lowees for each user. Based on the relationship data, a network of users can be constructed.Details of the data types are listed in Table I.

Table I Microblog datatypes
2.4 User characterization
Based on above analysis of the topological structure and Microblog data types, we choose the following three indices to characterize a Microblog user:
(i) User Activity.The activity of a user is measured by the frequency of participation of Microblog services, or more specifically, by the average interval of creation time between two consecutive tweets. The shorter the interval is, the more active the user is. A formal definition of user activity is given by

whereMdenotes the number of tweets that the useruhas posted,S2(u)idenotes the creation time of theith tweet posted by the useru.
(ii) Coherence between two users. According to the “six degree of separation”theory and the “weak tie” theory, we use the degree of a node in the user network to measure the strength of the intimacy between two users. LetCohe(a→b)denote the length of the shortest path between useraand userb. Considering that the user network is quite large and the weights of edges are positive (each edge has a weight 1), here we apply the Dijkstra algorithm to find the shortest path, so as to avoid repetitive storages, which are caused by identical degrees. For example, as shown in Fig.1,Cohe(a,b)=1, Cohe(a,f)= Cohe(a,b)+Cohe(b,c)+ Cohe(c,f)=3.
(iii) User Influence.As discussed in Section 2.2, the population of Microblog users can be modeled as an intelligent swarm, to which the PSO algorithm is applied to evaluate the influence of a user. Both the actions of tweeting and the interactions between users(i.e., following, forwarding, commenting) are taken into account by the PSO algorithm. The main objective of user recommendation is to discover the set of users that are most likely to interest the target user. The common interest between users is reflected by the interactive behaviors. Therefore, the characteristics of the interactions are the key basis for user recommendation. In the following section, we present a detailed description of how to use PSO to evaluate user influence.
III. PSO-BASED USER INFLUENCE EVALUATION
3.1 Standard PSO algorithm
Based on swarm intelligence, the PSO algorithm solves a problem by formalizing the candidate solutions as a population of particles, and moving the particles around in the search-space according to simple mathematical formulae over the particle’s position and velocity. The velocity of a particle is determined by both individual experience and social knowledge. The direction of the particle movement is mainly determined by the best position found by the particle itself (i.e., the local best position) and the best position found by the whole population (i.e., the global best position). After a certain number of iterations,particles will move to the position corresponding to the optimal solution.
Considering a population consisting ofNparticles. At iterationt(t=1,2,…), the velocity of particleiis denoted asvi,t, and the position of the particle is denoted asxi,t. Denote the local best position aspbesttand the global best position asgbestt. The velocity and the position of the particle in next iteration are defined as
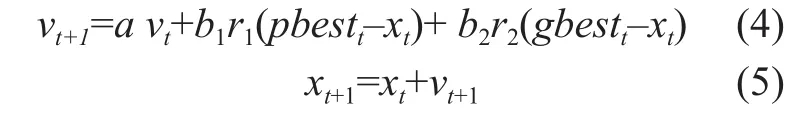
whereais the inertia weight,b1is the acceleration factor with respect to individual cognition, andb2is the acceleration factor with respect to social cognition,r1andr2are two random values uniformly distributed within[0, 1].
3.2 Applying PSO to user influence evaluation
The reason that we apply PSO to evaluate user influence is two-fold. On one hand, all relevant users are involved in the evaluation of a user’s influence, so that the result is not determined by the single user. On the other hand, characteristics of the Microblog user network, such as de-centralized and self-organized, are taken into account. To adapt to the problem of user influence evaluation, we make some modifications to the standard PSO algorithm by using the specific characteristics of Microblog social networks.
Denote the target user byAand the user set byU={A}+UR, whereUR={u1,u2,…,un}denotes the set of users relevant toA.WhenAinteracts with the useru1by taking the actionb, the increment ofA’s influence is defined as


where

Based on the interactions among Microblog users, we incorporate the three indices discussed in Section 2.4 into the design of the PSO algorithm. More specifically, the update rule of the velocity of a particle is define as
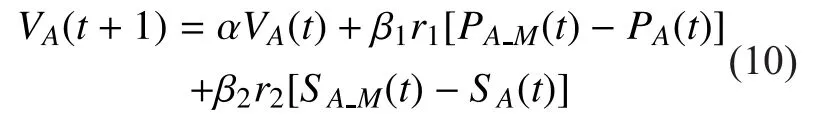
whereVA(t+1) denotes the velocity of userAat iterationt+1. The first itemreflects the inertia of the particle. The section itemis determined by personal experience, wheredenotes the value of personal experience that the particle obtained in current iteration, anddenotes the best value of personal experience that the particle has obtained so far. The third itemis determined by social knowledge, wheredenotes the value of social experience that the particle obtained in current iteration, anddenotes the best value of social experience that the particle has obtained so far. The three factorsandcontrol the impact of inertia, personal experience, and social experience respectively.
Personal experience is the knowledge that the user directly learns from its own behaviors. In this paper, we collect the same number of tweets for each user. Hence the number of tweets is not used to evaluate user influence.Instead, the actions that a user takes on other users’ tweets, such as forwarding, commenting, and liking, are considered. Compared to commenting and liking, the forwarding action has much more impact on the propagation of information. Consequently, the forwarding action is more relevant to the influence of a user.Therefore, only the forwarding action is used to evaluate personal experience. Formally, the value of personal experience that the userAobtains from forwarding the tweets posted by useru1is defined as

whereNFAu1denotes the number ofu1’s tweets that userAhas forwarded in current iteration,|F2(u)|=1026 denotes the total number of tweets that userAhas forwarded. If userAforwards zero tweets in current iteration, then the value of personal experience is set to 0. Con-sidering all the users in UR, we use the vectora=0.8 to denote the personal experience that the userAobtains in current iteration.
UserAlearns the social experience from other users’ behaviors, including forwarding,commenting or liking the tweets posted byA.Formally, the value of social experience that userAobtains from the interactions with useru1is defined as

The first item in the right-hand side of above equation denotes the experience obtained from forwarding, whereis the weighting factor,NFu1,Adenotes the number ofA’s tweets that have been forwarded byu1in current iteration,denotes the number ofA’s tweets that have been forwarded by all the other users in current iteration. The second item denotes the experience obtained from other interactions, whereis the weighting factor,NCPFu1,Adenotes the number ofA’s tweets that have been commented or liked byu1in current iteration,NCPAdenotes the number ofA’s tweets that have been commented or liked by all the other users in current iteration. Considering all the users in UR, we use the vectorto denote the social experience that the userAobtains in current iteration.
3.3 Experiment for user influence evaluation
To validate the effectiveness of the proposed PSO-based algorithm, we prepare a data set consisting of a center useruand its first/second/third contacts. Specifically, there are 56461 users in the set, and |F1(u)|=29,|F2(u)|=1026, |F3(u)|=55406. For each user, we collect 300 tweets that it posted recently. The parameters used in the algorithm are set as follows:. The initial velocity of the user is set to 0.The initial positions of users are randomly set based on the number of users. The initial value of user influence is defined as
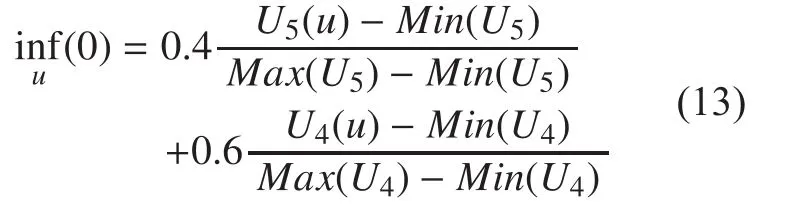

Fig. 2 Experiment results of user influence evaluation
We divide all the tweets into 20 groups and run the PSO algorithm on each group to evaluate user influence. Fig.2 shows the results corresponding to 2000 users in different phases of the iterative process. As we can see,after the first iteration, different users have similar influence. This is due to the initial settings of user influence. As defined in (12), the two weighting factors are set to 0.4 and 0.6 respectively, which implies that the number of a user’s fans has small impact on the initial value of user influence. Hence, initially users have similar influence. After the first iteration,only a few users improve their influence by posting many tweets or actively interacting with others. As the iterative process continues,the influence of users becomes more diverse.From an overall perspective, the change of user influence shows the following properties:
(i) Some users always have low influence.Such users occupy a small portion in the whole population. This is mainly due to that the tweets posted by these users have low-quality content, which means they are unattractive to other users. The users themselves are inactive,i.e., they barely interact with others.
(ii) Some users have high influence at the beginning, while the influence decreases with time. Such users are probably old users who registered the Microblog service long time ago, which implies they have many fans and posted many tweets. As a result, initially, these users have high influence. While as time goes by, due to the low quality of tweets or some reasons, the influence of these users decreases,which means the viscosity of the users decreases. It is necessary to recommend friends to these users, so that the whole user viscosity can be improved.
(iii) Some users have low influence at the beginning, while the influence increases with time. These users may be newly registered users who have high activity. Though the users may have few fans, they can improve their influence by frequently posting high-quality tweets. Such users should be recommended to others.

Fig. 3 The rank of user influence

Fig. 4 The framework of Microblog user recommendation
In Fig.3, we sort the users according to their influence and remove users whose influence is smaller than 1. As we can see, after 20 iterations, there are 2483 users who have relatively high influence, and only a few users have very high influence. Specifically, only 118 users have influence larger than 4. These users should be given high priority in user recommendation.
IV. PSO-BASED USER RECOMMENDATION
4.1 Recommendation strategy and evaluation metrics
Based on the PSO-based user influence evaluation algorithm proposed in the previous section, we design a user recommendation system. As illustrated in Fig.4, the system consists of three modules, i.e., the data collection module, the data processing module, and the recommendation generation module.
To validate the effectiveness and correctness of the recommendation system, here we chooseprecisionandrecall, which are commonly used in top-K recommendations, as the evaluation metrics. By referring to the realFollowrelationships between users, we divide the recommendation results intopositive resultsandnegative results. Positive results mean that the users recommended to the target user are actually the users followed by the target user. While negative results mean that the recommended users are not followed by the target user. Denote the number of positive results asP, the number of negative results asN.Denote the number of users that are followed by target users but not recommended asT. The precision and recall of the recommendation system can be defined as
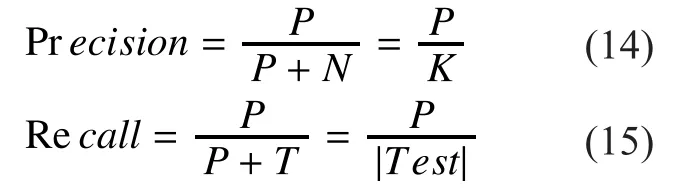
Considering that precision and recall are two inter-constraint measures, we define
F1-Measureto indicate the system performance:

4.2 Experimental results
We use the same data set in Section 3.3 for experiment. The set consists of one central useruand the user’s first contactssecond contactsthird contactsFor each user inwe calculate its activity, coherence, and influence via the methods described in Section 2 and Section 3. We randomly choose 60% users fromF1(u) and their second/third contacts as training data, the rest users inF1(u) and the corresponding second/third contacts are used for test.
We construct three groups of training-test sets and run the recommendation algorithm on each group. The first test set consists of 16896 users, and we run the algorithm to recommend 3 users (i.e.,K=3) to the center useru. Table 3 shows the information of the recommended users. The second test set consists of 13544 users, and we run the algorithm to recommend 5 (i.e.,K=5) users to the center useru. Table 4 shows the information of the recommended users. The third test set consists of 16772 users, and we run the algorithm to recommend 8 users (i.e.,K=8) to the center useru. Table 5 shows the information of the recommended users.
From Table II~Table IV we observe that :(i) ordinary users occupy a large portion in the recommended users. WhenK=3, all the three recommended users are ordinary users, i.e.,users who have not been verified. WhenK=5,only one of the recommended users is verified.WhenK=8, 75% of the recommended users are not verified. The result implies that the recommendation system proposed in this paper can effectively eliminate the effect caused by celebrities. (ii) The distribution of the number of recommended user’s fans is reasonable. As we can see, among the recommended users,some have a small number of fans, some havehundreds of thousands of fans. Most of the recommend users have much less fans than the celebrities, while the numbers of their fans are above the average. The result that the recommended users have a certain size of fans implies that a large fan base does not have a decisive impact on the recommendation result,and the proposed recommendation system can effectively handle the zombie fans. (iii)The first contacts in the test set occupy a large portion in the recommended users. Roughly speaking, the corresponding portion can be treated as the precision. When K equals 3, 5 and 8, the precision is 66.7%, 60% and 50%,respectively.

Table II Recommendation results when K=3
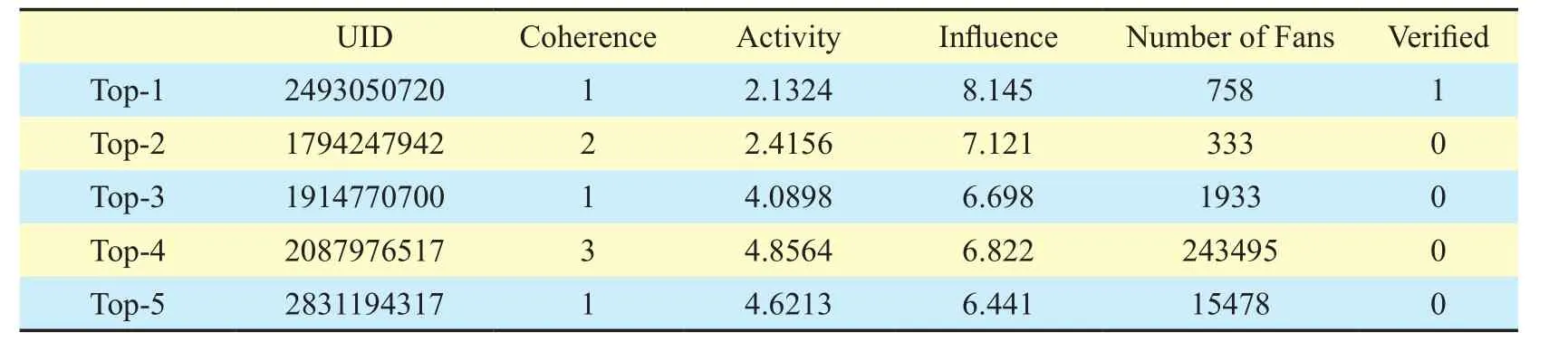
Table III Recommendation results when K=5

Table IV Recommendation results when K=8
To further evaluate the performance of the recommendation method, we test multiple values of K, i.e.,We choose the PageRank-based strategy for comparison.The basic idea of PageRank is to use the number of a user’s fans and the influence of these fans to evaluate the influence of the user. This algorithm is often used for recommending celebrities. Given a recommendation algorithm and the valuewe run the recommendation algorithm on all the three training-test sets,and the average result is reported.
As shown in Fig.5(a), the proposed recommendation method always has higher precision than the PageRank-based method. The PageRank-based method values the number of fans much, hence most of the recommended users are celebrities. While the proposed PSO-based recommendation method focuses on the interest of the target user, also the quality and the influence of the message are considered.Hence, the recommendation results are more precise.

Fig. 5 The evaluation results. (a) Precision. (b) Recall

Fig. 6 The evaluation results of F1-Measure
Fig.5(b) shows the evaluation results of recall. As we can see, both the two methods show better performance as the number of recommended usersKincreases. This is easy to understand. As defined in (14), the denominator in the right-hand side is fixed. The larger the value ofKis, the more positive results we can get. Consequently, the recall increases withK. In other words, the more users we recommend, the higher probability that the actual followees of the target user are recommended.Compared to the PageRank-based method,the proposed method has higher recall. In Fig.6, we compare the two methods in terms of F1-Measure. As we can see, the proposed PSO-based method performs much better the other one.
V. CONCLUSION
One important issue for Microblog user recommendation is how to develop an effective method to evaluate user influence. In this paper, we proposed a PSO-based recommendation strategy to deal with the negative effect caused by celebrities and zombie fans. Compared to traditional methods which mostly rely on simple statistics (e.g., the number of fans),the proposed method utilizes the interactions among users to evaluate user influence, so as to reduce the bias in the recommendation results. Experimental results show that the proposed method can get higher precision,recall andF1-measure than the classic PageR-ank-based method.
ACKNOWLEDGEMENTS
This research was supported by National Natural Science Foundation of China(No.61171109), Applied Basic Research Programs of Sichuan Science and Technology Department (No.2014JY0215) and Basic Research Plan in SWUST (No.13zx9101). The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Reference
[1] Symeonidis P, Manopoulos A, Manolopoulos Y, “A unified framework for providing recommendations in social tagging systems based on ternary semantic analysis[J]”,IEEE Transactions on Knowledge and Data Engineering, vol.22, no.2, pp 179-192, February, 2010.
[2] Xing Ling, Ma Qiang, Zhu Min, “Tensor semantic model for an audio classification system[J]”,Science China Information Sciences, Vol.56, no.6,pp 1-9, June, 2013.
[3] Pennacchiottim M, Gurumurthy S, “Investigating topic models for social media user recommendation[C]”,In proceedings of the 20th International Conference on World Wide Web, pp 101-102, 2011.
[4] Cai Yi, Leung Hofung, Li Qing,et al, “Typicality-based collaborative filtering recommendation[J]”,IEEE Transactions on Knowledge and Data Engineering, vol.26, no. 3, pp 766-779,March, 2014.
[5] Liu Qi, Chen Enhong, Hui Xiong,et al, “Enhancing collaborative filtering by user interest expansion via personalized ranking[J]”,IEEE Transactions on Systems, Man, and Cybernetics,part B (Cybernetics), vol.42, no.1, pp 218-233,Februray, 2012.
[6] Sun John Z, Paarthasarathy D, Varshney K, “Collaborative kalman filtering for dynamic matrix factorization[J]”.IEEE Transactions on Signal Processing, vol.62, no.14, pp 3499-3509, July,2014,.
[7] Yi Huawei, Zhang Fuzhi, Lan Jie, “A robust collaborative recommendation algorithm based on k-distance and Tukey M-estimator[J]”,China Communications, vol.11, no. 9, pp 112-123,September, 2014.
[8] Tian Ye, Wang Wendong, Gong Xiangyang,et al, “An enhanced personal photo recommendation system by fusing contextual and textual features on mobile device[J]”,IEEETransactions on Consumer Electronics, Vol.59, no. 1, pp 220-228, February, 2013.
[9] Wang Zhibo, Liao Jilong, Cao Qing,et al,“Friendbook: a semantic-based friend recom-mendation system for social networks[J]”,IEEE Transactions on Mobile Computing, vol.14, no. 3,pp 538-551,March, 2015.
[10] Qian Xueming, Feng He, Zhao Guoshuai,et al,“Personalized recommendation combining user interest and social circle[J]”,IEEE Transactions on Knowledge and Data Engineering, vol.26, no.7,pp 1763-1777, July, 2014.
[11] Wang Zhi, Sun Lifeng, Zhu Wenwu,et al, “Joint social and content recommendation for user-generated videos in online social network[J]”,IEEE transactions on Multimedia, vol.15, no.3, pp 698-709, April, 2013.
[12] Zhao Zhou, Lu Hanqing, Cai Deng,et al, “User preference learning for online social recommendation[J]”,IEEE Transactions on Knowledge and Data Engineering,vol.28, no. 9, pp 2522-2534, September, 2016.
[13] Braida F, Mellob C, Pasinatoa M,et al, “Transforming collaborative filtering into supervised learning[J]”,Expert Systems with Applications,vol.42, no.10, pp 4733–4742, January, 2015.
[14] Chen Liang, Wu Jian, Jian Hengyi,et al, “Instant recommendation for web services composition[J]”,IEEE Transactions on Services Computing,vol. 7, no. 4, pp 586-598, October-December, 2014.
[15] Chen Hanhan, Cui Xiaolong, Jin Hai, “Top-k followee recommendation over microblogging systems by exploiting diverse information sources[J]”,Future Generation Computer Systems, vol.55, pp 534-543, Febrary, 2016.
[16] Zheng Nan, Song Shuangyong, Bao Hongyun, “A temporal-topic model for friend Recommendations in chinese microblogging systems[J]”,IEEE Transactions on Systems, Man, and Cybernetics:Systems,Vol.42, no. 9, pp 1245-1253, September,2015.
[17] Zhan Zhihui, Zhang Jun, Li Yun,et al,“Orthogonal learning particle swarm optimization[J]”,IEEE Transactions on Evolutionary Computation,vol.15, no.6, pp 832-847, December, 2011.
[18] Li Changhe, Yang Shengxiang, Trung T. N, “A self-learning particle swarm optimizer for global optimization problems[J]”,IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), Vol.42, no.3, pp 627-646, June, 2012.

- China Communications的其它文章
- A Reliable Routing Algorithm with Network Coding in Internet of Vehicles
- Achievable Uplink Rate Analysis for Distributed Massive MIMO Systems with Interference from Adjacent Cells
- Multi-Owner Keyword Search over Shared Data without Secure Channels in the Cloud
- A User Participation Behavior Prediction Model of Social Hotspots Based on Influence and Markov Random Field
- Ethics Aware Object Oriented Smart City Architecture
- Walsh Hadamard Transform Based Transceiver Design for SC-FDMA with Discrete Wavelet Transform