
基于积分投影和LSTM的微表情识别研究
2017-04-26 08:40李竞李董东杜玉改成鹏
计算机时代 2017年4期
关键词:精度
李竞+李董东+杜玉改++成鹏
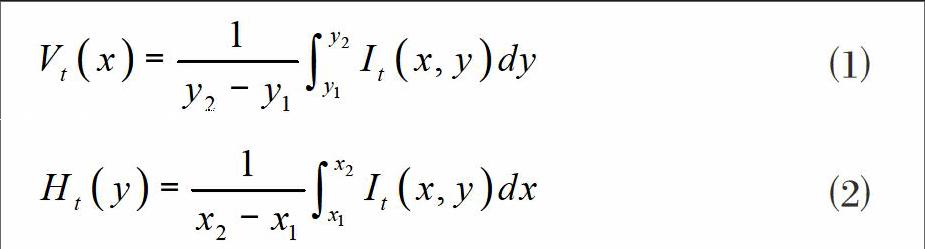
摘 要: 现有的微表情识别研究主要是利用基于局部二值模式(LBP)改进的算法并结合支持向量机(SVM)来识别。最近,积分投影开始应用于人脸识别领域。长短时记忆网络(LSTM)作为循环神经网络,可以用来处理时序数据。因此提出了结合积分投影和LSTM的模型(LSTM-IP),在最新的微表情数据库CASME II上进行实验。通过积分投影得到水平和垂直投影向量作为LSTM输入并分类,同时采用了防止过拟合技术。实验结果表明,LSTM-IP算法取得了比以前的方法更好的精度。
关键词: 积分投影; 循环神经网络; 长短时记忆网络; 防止过拟合技术; 精度; 留一法
中图分类号:TP391.4 文献标志码:A 文章编号:1006-8228(2017)04-13-04
Abstract: The existing research on micro expression recognition is mainly based on the improved LBP (local binary patterns) algorithm and SVM (support vector machine). Recently, integral projection has been applied in the field of face recognition. The long and short memory network (LSTM), as a kind of recurrent neural network, can be used to process time series data. So LSTM-IP model, which combines integral projection with LSTM, is proposed, and experimented on the latest micro-expression database CASME II. The horizontal and vertical projection vectors obtained by integral projection are used as the input of LSTM and classified, and the over-fitting preventing method is used. The experimental results show that LSTM-IP algorithm gets better results than the previous method.
Key words: integral projection; recurrent neural network; long and short memory network; prevent over-fitting; accuracy; leave-one-subject-out cross validation
0 引言
人们表情的短时间变化,也叫微表情,心理学在这方面的研究很早就开始了。近年来,有关利用机器学习的方法来对微表情进行研究的学者越来越多,其成为当前一个热门研究方向。微表情的研究成果可用于测谎[2-4]、临床诊断等方面,因為一般人即便是心理医生也很难注意到1/25~1/5秒人表情的变化[1],而这时,机器可以很好的对微表情进行自动的识别。
最近,基于积分投影和纹理描述符的方法被用在人脸识别[5],然而,很少有研究将积分投影用于包含人脸的时间序列中进行识别。微表情与人脸识别有很大不同,特征很难单从每帧图片中提取,这时就需要考虑时间轴。LSTM可以对时序数据进行分类,以前基本用在语音识别和自然语言处理的任务中,很少用于图像识别,可能是因为LSTM处理的是一维的数据,而图像是二维的数据。将图像的二维信息积分投影到一维(水平方向和垂直方向),并以此作为LSTM的输入并分类,这样就能将二者很好的结合起来。
本文构造了基于积分投影和LSTM的深度学习的模型来对微表情进行识别。得到的结果不仅比以前的基于局部二值模式(LBP)的方法好,而且也略微的优于最近基于积分投影的论文中的方法。
1 CASME II微表情数据集介绍
2014年,中科院心理研究所建立了更进一步改进的自然诱发的微表情数据库CASMEII[8]。CASMEII有26个平均年龄为22岁左右的亚洲人,9类表情(happiness, surprise, disgust, fear, sadness, anger, repression, tense, negative)组成。用来录制的高速相机为200 fps。高速相机可以捕捉更细节的微表情。CASMEII是据我们所知目前最好的自然诱发的微表情数据库。
2 基于差分图像的积分投影
Mateos等人的开拓性工作[6-7]表明积分投影可以提取同一人脸图像的共同基本特征。积分投影将人脸的特征水平和垂直投影,可以用公式⑴和⑵表示:
其中It(x,y)表示时间为t时,图像位于(x,y)时的像素值,Ht(y)和Vt(x)表示水平和垂直积分投影。直接将积分投影应用到CASME II微表情数据集上效果如图1所示。
然而,由于微表情的变化是十分微小的,若直接采用上面的积分投影会有很多噪声,从图1(c)可以看出区分不是很明显。因此,我们采用改进的积分投影方法。可以用公式⑶和⑷表示:
我们将每个视频下的2到N帧微表情的图像减去第1帧,将得到的差分图像做积分投影,效果如图2所示。
从图2的(c)可以看出,采用基于差分图像的水平积分投影效果更好,去掉了不必要的噪声。
3 长短时记忆网络
循环神经网络(RNN)可以用来处理时序数据,但它有一个明显的缺陷,就是不能记忆发生在较久以前的信息。长短时记忆网络(LSTM)[9]是一种特殊的RNN,比RNN多了一些特殊的门和细胞,可以学习长期依赖信息。LSTM结构如图3所示。
最上面横着带箭头的线包含细胞单元,作用是记忆之前LSTM单元的信息。x和+表示点分的乘法与加法,表示Sigmoid激活函数(如公式⑸),tanh表示双曲正切激活函数(如公式⑹)。
最下面圆圈中的X和最上面圆圈中的h分别表示时序输入和输出。
通用的LSTM结构可以参考图4,图4中,底层节点为输入,顶层节点为输出,中间层为隐藏层节点或记忆块。(a)描述的是传统的 感知机(MLP)网络,即不考虑数据的时序性,认为数据是独立的;(b)将输入序列映射为一个定长向量(分类标签),可用于文本、视频分类;(c)输入为单个数据点,输出为序列数据,典型的代表为图像标注;(d)这是一种结构序列到序列的任务,常被用于机器翻译,两个序列长度不一定相等;(e)这种结构会得到一个文本的生成模型,每词都会预测下一时刻的字符。
4 LSTM-IP模型
因为CASME II数据集每个视频下微表情图像帧数是不一样的,为了方便我们统一LSTM的输入,所以我们提取了最能代表这个视频微表情的10帧,同时,本文将整个数据集图像的尺寸统一到200×200像素,将原来彩色图像转化为灰度图像。通过基于差分图像的积分投影,得到一个视频下差分图像每帧图像的水平和垂直投影,一个图像可以得到一个200维的水平向量和一个200维的垂直向量,因为差分图像是后面9张减去了第一张图像,所以一个视频下共有9个水平向量和9个垂直向量,初始化两个9×200大小的一维向量分别保存水平向量和垂直向量。
本文采用图4(b)和图4(e)结合的LSTM结构,如图5所示。
顶层的X_IP表示将一个视频下9个差分图像的水平投影组成的9×200的一维特征向量作为输入,经过第一层LSTM得到9×128的一维特征向量,接着经过第二层LSTM得到9×128的一维特征向量,最后经过一层LSTM得到一个128的特征向量,Y_IP也是同样的处理过程。最后将这两部分的128的特征向量连接起来作为一个256的特征向量输入softmax分类器,结果输出属于五类微表情的哪一类。在图5的每两层之间加入一层Dropout层,Dropout的比率设为0.5。LSTM内部参数初始化采用了glorot_normal,相比较于其他初始化方法,glorot_normal效果最好。
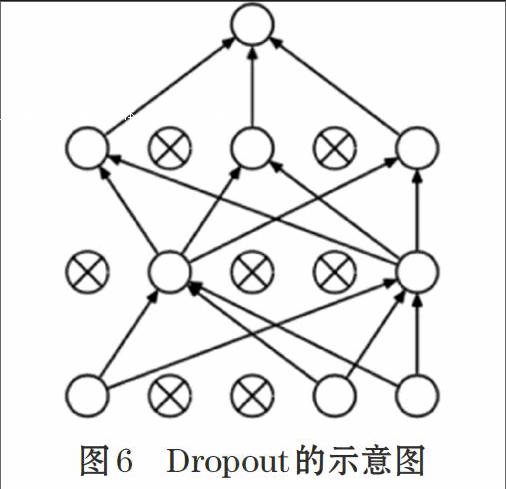
Softmax和Dropout在深度学习中都是常用的技术。Softmax是逻辑斯特回归应用于多分类的推广。Dropout[10]这种技术的作用是减少过拟合,是一种正则化技术,通过防止由完全连接的层引起神经元的参数过多,有助于减少神经网络的过度拟合问题。给定 dropout率p,其在我们的LSTM中被设置为0.5,50%单位将被保留,而另外50%将被放弃。简单地说,“Dropout”只是随机忽略一些神经元。然而在测试阶段,每个神经元的输出将通过因子1-p(保持率)加权以保持与训练阶段中产生相同的效果。如图6所示。
我们的实验采用基于Theano的keras框架,keras借鑒了Torch的搭建深度学习网络的方式,而且使用笔者比较熟悉的Python语言(Torch使用Lua语言),keras的底层可以是Theano或者Tensorflow,可能是因为keras最先在Theano开发的,经过实验比较单个GPU下,Theano的速度要比Tensorflow快,所以我们的底层采用Theano。
5 实验结果与分析
现在微表情识别的算法主要是基于LBP改进的算法,例如LBP-TOP[11](Local Binary Pattern-Three Orthogonal Planes)、LBP-SIP[12](LBP-Six Intersection Points)和LOCP-TOP[13](Local ordinal contrast pattern-
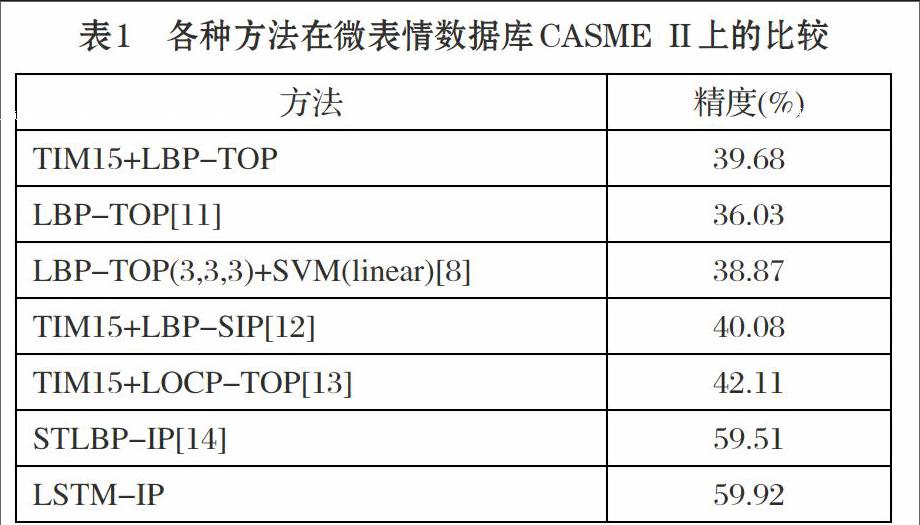
TOP)等。我们将LSTM-IP算法与以前的方法做了比较,如表1所示。
实验是在CASME II上做的,因为CASME II微表情数据集是最新最好的微表情数据集。STLBP-IP也是基于积分投影的,结合了1DLBP来提取特征。通过表1的比较我们发现,基于积分投影的算法效果好于原来基于LBP的算法,可以得出,采用提取积分投影特征的方法在微表情数据集CASME II上效果比较好。可以看出,STLBP-IP的性能优于文献[27]的重新实现,STLBP-IP的精度提高了20.64%。从表1中可知,时间插值法(TIM)可以提高LBP-TOP的性能,其中LBP-TOP增加到39.68%。然而,与STLBP-IP相比,LBP-TOP在微表情识别上的效果上有很大的差距(19.43%)。比较两种基于积分投影的方法,本文提出的方法略微好于STLBP-IP,但通过阅读STLBP-IP的论文笔者发现,这种方法存在繁琐的调参过程,比如图像如何分块,SVM核参数的选择,而本文提出的LSTM-IP算法可以自动从差分图像的积分投影中学习,调参的内容比较少,而且速度也很快。这些结果表明,LSTM-IP实现了令人满意的效果,而不是LOCP-TOP和LBP-SIP。 这部分地解释了LSTM-IP通过使用积分投影来保持形状和辨识的能力。
实验采用了留一法交叉验证,CASME II有26个subjects,通过把每个subject作为测试,其余作为训练,循环26次,最后把每次测试得到的正确视频个数相加除以总的视频数,得到识别精度,这种方法现在是微表情识别主流的验证方法。
6 結束语
基于差分图像的积分投影方法,保存了我们微表情形状的特征,然后增强微表情的辨别力。深度学习在图像识别领域已经取得了很不错的成绩,而现在深度学习的技术还没有应用于微表情识别。本文将差分图像的积分投影与LSTM结合,从实验结果上看,结果要好于以前的方法。我们认为深度学习的探索不会停止,会有越来越多新的网络模型产生,也会有越来越多的深度学习的技术应用于微表情识别。
我们将继续探索基于深度学习的微表情识别的方法及技术手段。卷积神经网络在图像识别上取得了很好的成绩,但笔者也将卷积神经网络应用于微表情上,效果并不好,可能是因为微表情在图像上变化比较细微,卷积神经网络不容易捕捉到特征,但如果考虑了一个视频时间序列的特性,也许会有比较好的结果,对此还有待进一步研究。随着技术的进步,相信微表情识别效果会越来越好,并最终能够应用于我们的生活中。
参考文献(References):
[1] Ekman P. Micro Expressions Training Tool[M]. Emotion-
srevealed. com,2003.
[2] Ekman P. Darwin, deception, and facial expression[J].
Annals of the New York Academy of Sciences,2003.1000(1):205-221
[3] Ekman P. Lie catching and microexpressions[J]. The
philosophy of deception,2009:118-133
[4] Ekman P, O'Sullivan M. From flawed self-assessment to
blatant whoppers: the utility of voluntary and involuntary behavior in detecting deception[J]. Behavioral sciences & the law,2006.24(5):673-686
[5] Benzaoui A, Boukrouche A. Face recognition using 1dlbp
texture analysis[J]. Proc. FCTA,2013: 14-19
[6] Mateos G G. Refining face tracking with integral projections
[C]//International Conference on Audio-and Video-Based Biometric Person Authentication. Springer Berlin Heidelberg,2003: 360-368
[7] García-Mateos G, Ruiz-Garcia A, López-de-Teruel P
E. Human face processing with 1.5 D models[C]//International Workshop on Analysis and Modeling of Faces and Gestures. Springer Berlin Heidelberg,2007:220-234
[8] Yan W J, Li X, Wang S J, et al. CASME II: An improved
spontaneous micro-expression database and the baseline evaluation[J]. PloS one, 2014.9(1):e86041
[9] Hochreiter S, Schmidhuber J. Long short-term memory[J].
Neural computation,1997.9(8):1735-1780
[10] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving
neural networks by preventing co-adaptation of feature detectors[J]. Computer Science,2012.3(4):212-223
[11] Zhao G, Pietikainen M. Dynamic texture recognition
using local binary patterns with an application to facial expressions[J]. IEEE transactions on pattern analysis and machine intelligence,2007.29(6).
[12] Wang Y, See J, Phan R C W, et al. Lbp with six
intersection points: Reducing redundant information in lbp-top for micro-expression recognition[C]//Asian Conference on Computer Vision. Springer International Publishing,2014:525-537
[13] Chan C H, Goswami B, Kittler J, et al. Local ordinal
contrast pattern histograms for spatiotemporal, lip-based speaker authentication[J]. IEEE Transactions on Information Forensics and Security,2012.7(2):602-612
[14] Huang X, Wang S J, Zhao G, et al. Facial
micro-expression recognition using spatiotemporal local binary pattern with integral projection[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops,2015:1-9
猜你喜欢
一重技术(2021年5期)2022-01-18
电子制作(2018年11期)2018-08-04
水利规划与设计(2018年1期)2018-01-31
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
测绘科学与工程(2016年5期)2016-04-17
制造技术与机床(2015年10期)2015-04-09
深圳大学学报(理工版)(2015年5期)2015-02-28
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
中国土地科学(2011年10期)2011-03-20
