
基于随机森林的乳腺癌计算机辅助诊断
2017-04-20 07:56全雪峰
软件 2017年3期
全雪峰
(南阳医学高等专科学校 卫生管理系,河南 南阳 473061)
基于随机森林的乳腺癌计算机辅助诊断
全雪峰
(南阳医学高等专科学校 卫生管理系,河南 南阳 473061)
为提高乳腺癌诊断的准确性,该文提出了一种基于随机森林算法的乳腺癌诊断方法。用 UCI数据集提供的683例乳腺肿瘤患者进行了分类识别,5-折交叉验证结果表明,采用新方法检测乳癌平均准确率达到96.93%,优于概率神经网络识别方法,说明了其在乳腺癌计算机辅助诊断方面的可行性。
随机森林;乳腺癌;计算机辅助诊断
0 引言
乳腺癌是一种危及妇女健康和生命的恶性肿瘤,是导致女性癌症死亡的第二大原因[1]。根据世界卫生组织的报道,每年有超过120万女性被诊断患有乳腺癌[2]。因此早期诊断、积极预防已成为迫切需要解决的问题。随着人工智能技术的迅速发展,运用计算机辅助诊断乳腺癌已受到越来越多的关注,并取得了不少成果。刘琼荪[3]等提出基于径向基神经网络的乳腺癌分类模型,对100个检测样本的平均误识率为23.5%。毛利锋[4]等采用决策树方法对乳腺癌进行判别,准确率达到96%以上。刘兴华[5]等人利用支持向量机进行乳腺癌识别,最佳平均分类准确率达到96.24%。徐胜舟[6]等人提出结合遗传算法的支持向量机乳腺癌诊断新方法,AUC值达到了0.908。唐思源[7]等人利用支持向量机对癌细胞的识别,取得了较好的正确识别率。
随机森林是一种比较新的机器学习模型,它在没有显著提高运算量的前提下提高了预测精度。黄衍[8]等人指出,在多分类问题上,随机森林的泛化能力明显优于支持向量机。文献[9-10]指出支持向量机比BP神经网络具有更高的泛化能力。目前,随机森林已被应用于多个领域[11-12]。模型本文提出了一种基于随机森林的乳腺癌识别方法,并使用UCI数据集验证模型的性能,结果显示该方法具有较好的分类准确率。
1 随机森林
随机森林是一种集成树形分类器[13],由多个决策树(h(x,θi), i=1,2,…)组成。其中h(x,θi)是用分类回归树CART算法构建的没有剪枝的分类决策树,θi是独立同分布的随机向量,决定单棵树的生长速度。在给定输入向量 x的情况下,每个决策树分类器通过投票来决定最优分类结果。
随机森林一般构造过程如下:
(1)利用自助法(bootstrap)重抽样技术从原始样本集中有放回地随机抽取 k个新的自助样本集,以此形成一个分类器。
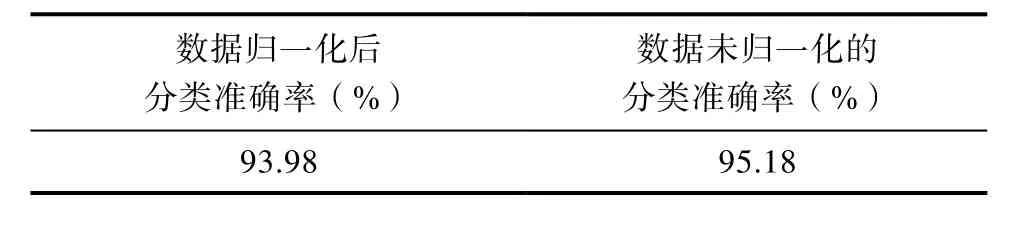
(2)每个自助样本集生成单棵决策树。在树的每个节点处M个特征中随机抽取m(m (3)重复步骤(2),构建k棵决策树,形成随机森林。 (4)根据每棵决策树的投票结果,选出票数最多的一个分类。 节点不纯度的度量方法是Gini准则[14]。设P(ωj)是节点n上属于ωj类样本个数占训练样本总数的频率,则Gini不纯度表示为: 2.1 数据选取 本文所用数据来自UCI数据集[15]。该数据集是美国威斯康星州医院用针吸细胞学方法所得到的乳腺癌样本,共有699个。每一样本具有9个特征,分别为:肿块密度(Clump Thickness)、细胞大小均匀性(Uniformity of Cell Size)、细胞形状均匀性(Uniformity of Cell Shape)、边界粘连(Marginal Adhesion)、单个上皮细胞大小(Single Epithelial Cell Size)、裸核(Bare Nuclei)、微受激染色质(Bland Chromatin)、正常核(Normal Nucleoli)、有丝分裂(Mitoses)。所有特征的属性值都是1~10的整数,1代表正常状态,10代表极不正常状态,值越大表示该患者乳腺肿瘤恶性的可能性就越大。整个数据集中,有少量属性值缺省,以“?”表示。考虑到实验数据的全面性,本文剔除了含有缺省属性的病例,剩下病例中确诊为良性的有444例,确诊为乳腺癌恶性的有239例,共计683个样本。 2.2 确定训练集与测试集 实验中采用5折交叉验证法对数据集进行分组和测试。即将数据随机分为容量大致相同的5组,每一组依次轮流作为测试集,其余部分作为训练集。对每次分组得到的训练集和测试集,用随机森林进行训练和测试。 2.3 分类器设计 在得到训练集和测试集之后就可以利用分类器进行识别了。本文采用 Matlab2013a中随机森林工具箱函数TreeBagger()创建一个随机森林分类器,利用predict()函数对测试集数据进行预测。 3.1 决策树个数对分类结果的影响 在随机森林模型中,决策树个数k影响着分类器的性能。当k值较小时,随机森林的分类误差大、性能也比较差。但是构建随机森林的复杂度与 k值成正比,若 k值过大,则需要花费较多的时间来构建随机森林。不同决策树个数与模型误差的关系如图1所示。 图1 决策树个数与模型误差关系 由图 1可以看出,当决策树个数大概大于 300以后,模型误差趋于稳定,因此本文将模型中决策树个数确定为300,以此来达到最优模型。 3.2 数据归一化对算法性能的影响 为研究数据归一化处理对算法性能的影响,使用相同的训练集和测试集,分别在归一化到[-1,1]和未归一化情况下进行算法测试,结果如表1所示。 表1 数据归一化与否对模型性能的影响 由表1可以看出,数据归一化后的分类准确率低于未归一化的分类准确率。这说明,数据是否需要归一化处理,并非一个必要条件,需根据具体情况选择。 3.3 5-折交叉验证结果 取随机森林模型中决策树个数为 300,不进行数据归一化处理,用5-折交叉验证对剔除含有缺省属性后的683个样本进行测试。由于每次所选训练集和测试集均不相同,因而其结果也不相同。某轮5-折交叉验证结果如表2所示。 表2 5-折交叉验证结果 由表2可以看出,基于随机森林算法的乳腺癌分类模型平均分类准确率达到了96.93%,说明分类准确率较高。 3.4 不同算法比较 为了与其他算法进行对比分析,本文使用相同的训练样本和测试样本,采用5-折交叉验证方法,分别与文献[5]所提支持向量机算法以及文献[16]所提概率神经网络算法做了性能对比,某轮5-折交叉验证结果如表3所示。 表3 不同算法比较 由表3可以看出,本文算法的平均准确率与支持向量机的平均准确率相当,但优于概率神经网络算法。这表明随机森林算法同支持向量机算法一样,不仅可以较好地识别出乳腺癌患者,还可以较好地识别出非乳腺癌病例,从而可以减少人为原因造成的漏诊和误诊几率,给病人带来福音。 本文将随机森林算法用于乳腺肿瘤的良性和恶性识别。从实验结果可以看出,该算法能较好的区分开良性肿瘤和恶性肿瘤,从而为乳腺癌的计算机辅助自动诊断提供了一种新的思路。 [1]E.C.Fear, P.M.Meaney, and M.A.Stuchly, “Microwaves for breast cancer detection”, IEEE potentials, vol.22, pp.12-18, February-March 2003. [2]Akay M F.Support vector machines combined with feature selection for breast cancer diagnosis[J].Expert systems with applications, 2009, 36(2): 3240-3247. [3]刘琼荪, 何离庆.基于人工神经网络的乳腺癌诊断模型[J].重庆大学学报(自然科学版), 2003, 26(4): 70-72. [4]毛利锋, 瞿海斌.一种基于决策树的乳腺癌计算机辅助诊断新方法[J].江南大学学报(自然科学版), 2004, 3(3): 227-229. [5]刘兴华, 蔡从中, 袁前飞等.基于支持向量机的乳腺癌辅助诊断[J].重庆大学学报(自然科学版), 2007, 30(6): 140-144. [6]徐胜舟, 裴承丹.基于遗传算法和支持向量机的乳腺肿块识别[J].计算机仿真, 2015, 32(2): 432-435, 440. [7]唐思源, 柳原, 崔媛.利用支持向量机对癌细胞的识别[J].软件, 2014, 35(3): 170-171. [8]黄衍, 查伟雄.随机森林与支持向量机分类性能比较[J].软件, 2012, 33(6): 107-110. [9]王宏涛, 孙剑伟.基于BP神经网络和SVM的分类方法研究[J].软件, 2015, 36(11): 96-99. [10]肖晓, 徐启华.基于SVM与BP的分类与回归比较研究[J].新型工业化, 2014, 4(5): 48-53. [11]全雪峰.基于奇异熵和随机森林的人脸识别[J].软件, 2016, 37(02): 35-38. [12]王浩.基于随机森林的网络攻击检测方法[J].软件, 2016, (11): 60-63. [13]Breiman L.Random forests[J].Machine learning, 2001, 45(1): 5-32. [14]张洪强, 刘光远, 赖祥伟等.随机森林算法在肌电的重要特征选择中的应用[J].计算机科学, 2013, 40(1): 200-202. [15]William H.Wolberg, UCI Machine Learning Repository[DB/OL].(2016-4-24).http: //archive.ics.uci.edu/ml. [16]程智辉, 陈将宏.基于概率神经网络的乳腺癌计算机辅助诊断[J].计算机仿真, 2012, 29(9): 166-169. Computer-Aided Diagnosis of Breast Cancer Based on Random Forest QUAN Xue-feng In order to improve the accuracy of diagnosis of breast cancer, this paper proposes a method for diagnosis of breast cancer based on random forest algorithm.With 683 cases of breast cancer patients from UCI data sets for identification and classification, 5-fold cross validation results show that average accuracy rate reached 96.93% by this new method for the detection of breast cancer.This is superior to probabilistic neural network recognition method, indicating the feasibility of computer-aided breast cancer diagnosis. Random forest; Breast cancer; Computer-aided diagnosis TP391 A 10.3969/j.issn.1003-6970.2017.03.012 河南省医学教育研究课题(Wjlx2015133) 全雪峰(1969-),男,副教授,主要研究方向为智能信息处理。 本文著录格式:全雪峰.基于随机森林的乳腺癌计算机辅助诊断[J].软件,2017,38(3):57-59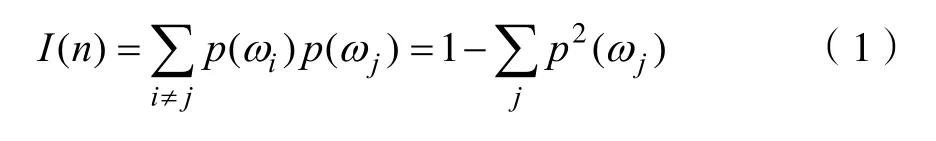
2 算法设计
3 实验结果与分析



4 结束语
(Department of Health Management, Nanyang Medical College, Nanyang 473061, China)
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
电测与仪表(2014年15期)2014-04-04
