
研究汉语语言模型的规模对统计机器翻译系统的影响
2017-04-18 12:59刘林付琦武丽萍
电脑知识与技术 2016年35期
刘林+付琦+武丽萍
摘要:文章主要针对汉语语言模型规模大小的具体情况以及语法元数在英汉统计机器翻译系统的影响进行研究分析。在研究过程中,主要是通过相应的模型进行实验,通过相应的研究分析,最终表明层次短语的翻译系统的翻译效果明显高于基于短语的翻译系统,对于不同语言的模型来说,其元数以及规模对具体的翻译效果都具有很大的影响。
关键词:语言模型;基于短语的统计机器翻译系统;层次短语
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)35-0198-02
在汉语言翻译工作开展过程中,语言模型占据着重要地位,特别是在统计机器翻译、语音识别、汉语分词、自动纠错过程中,其应用范围十分广泛。就现阶段来说,机器翻译过程中,主要使用的是n语言模型。此种模型在应用过程中,其结构较为简单,人们在研究过程中只是知道其大小以及n语言的元数对翻译的质量具有较大的影响,但是,并不知道造成影响的具体情况,因此,文章在研究过程中主要针对现阶段较为流行短语的统计翻译系统和基于层次短语的统计翻译系统的影响。
1 英汉统计翻译系统中汉语语言模型的应用分析
统计语言型根本目的是为了能够对字符串s概率分布P(s)进行展示,假如让w1l=(w1,…wl),表示长度为I根本字符,Wi代表一個重要元素,基本上都表示一个单词。在汉语语言模型中,其主表示为一些以汉语句子为基础所分离出的生词。在翻译工作不断的发展过程中,短语统计机器翻译系统代表着目前翻译的发展方向,此系统在实际的利用过程中,基本上都是将某个短语看成一个翻译单元,系统在翻译中,首先都是把源语言的句子S拆分成j个短语:S1S2…Sj,在对每个Sk,k=1…j,利用翻译模型,可以将翻译目标转变为Ti。最后利用调序模型以及语言模型输出翻译结果,输出n个翻译较好的结果TI。短语翻译模型在实际的翻译应用过程中,能够对翻译过程中较短的句子进行翻译。通过对P.Koehn等人的研究结果进行分析显示;当语句长度能够拓展到3个单词以上,翻译系统的整体性能性能没有明显的提升,并且相应的数据稀疏问题也逐渐增多。并且,在大多数情况下,简单的语言翻译模型不能对短语之间的顺序进行有效的调整。
工作人员在研究过程中,为了解决短语的翻译模型不能对短语之间的顺序进行有效的调整的情况,笔者通过研究分析,提出了采用基于层次短语的翻译模型尝试解决短语的翻译模型不能对短语之间的顺序进行有效的调整的问题。主要的思路为:在研究过程中,不同的语言句子由相应的层次化短语组成,设定层次化短语主要由两部分组成,即子短语与单词,在实际训练时借助同步上下文无关文法,从双语对齐的语料中选择相应的语言知识,进而获得带有相应变量的基本短语对以及短语结构。但是,本质内容都一样,都是SCFG形成的式子。翻译系统模型中同步上下文无关文法的应用,能够保证该翻译模型最大化的接近语言翻译要求。同时,在翻译的过程中并不需要借助其他语言知识。因此,该翻译模型在实际应用的过程中采用形式化语法。基于层次短语的统计机器翻译系统实际应用的具体步骤为:首先,在实际的翻译过程,需要借助层次化短语对部分语句进行层次化翻译,并按照实际状况将翻译过后的语句进行连接,进而获得完整的翻译句子。
2 汉语语言模型的规模对统计机器翻译系统的影响实验分析
1)语料预处理及语言模型训练
该实验在实际的研究分析过程中,主要采用的是我国在2007年SSMT评测中的新闻领域英中翻译测试集作为开发集,训练数据采用全部语料(该语料由SSMT077评测以及NISTMT077提供),训练实验的主要数据来源为美国国家标准技术研究院(NIST)MT07评测和SSMT07评测提供的全部语料。全部语料中包含了四千万句汉语单语语料,按照过滤原则(处理后语料中句子的全部词汇是否全在SSMT07中出现)对双语对齐语料进行筛选,通过过滤选择合适的双语对齐语料。
在英文语料预处理的工作包括以下几个方面:①词串化、②乱码过滤、③双字节字符处理等,在预处理的过程中需要把全部的大写字母都转换成为小写字母等。对于中文语料预处理工作内容为:剔除乱码,双字节字母替换,分词等工作内容。在实际的工作开展过程中,分词主要采用工具是计算过程中所研发的ICTCLAS3.0.
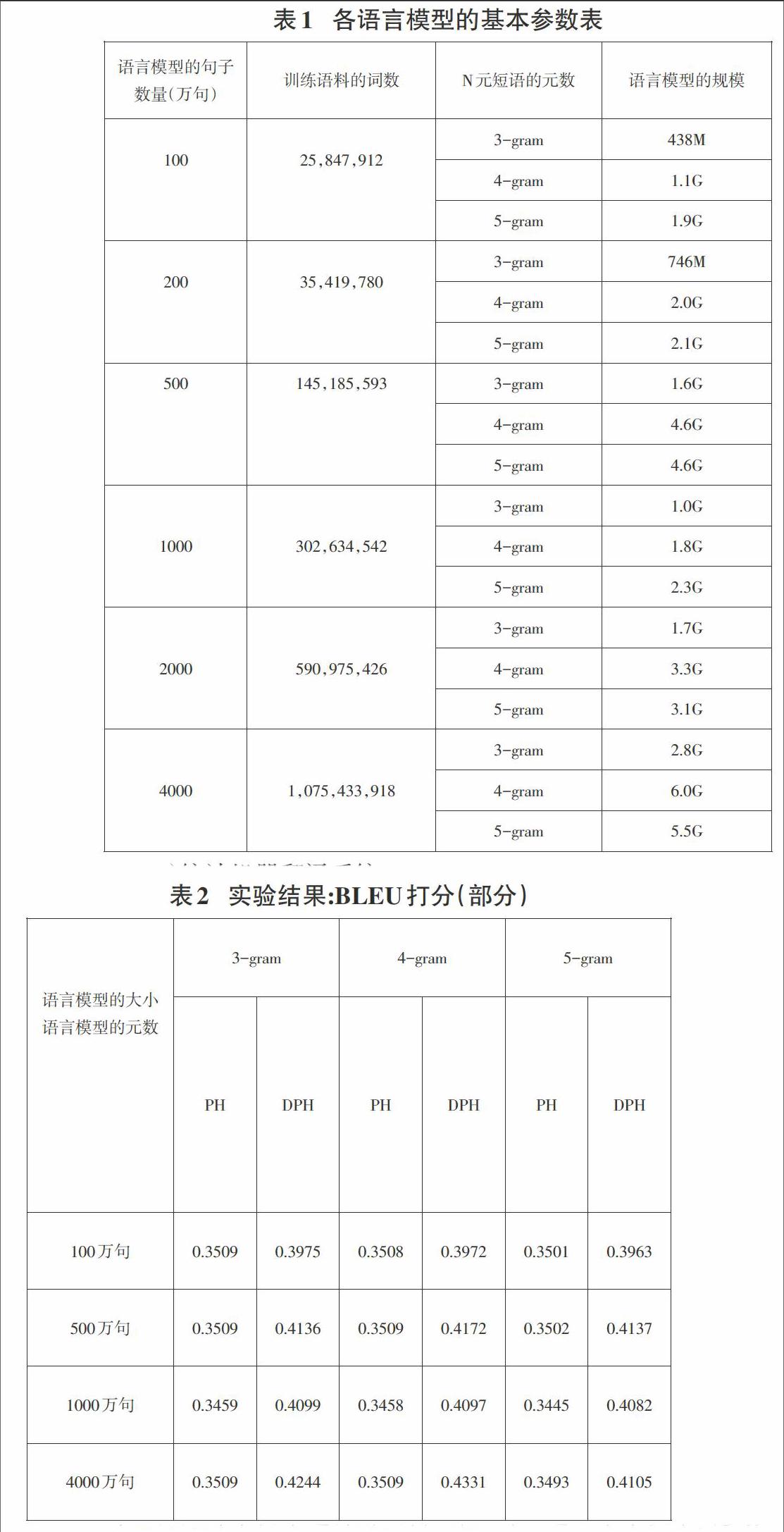
如果采用SRILM工具包训练语言模型,语言模型都是根据训练集规模实际情况以及n元语法的元数对其进行不同的划分,在划分过程中,根据语言模型的大小进行划分,可以划分成六种不同的元语法,分别为100、200、500、1000、2000、4000(万句),对于小语言模型句子,全部是从最后一种大语料库中选择。依据不同的n元语法元数,可以划分成三种不同的元语法,分别为3、4、5元语法。所有语言模型的参数表示为:
该实验所采用的翻译系统是由基于层次短语和短语的统计机器翻译系统组成。一方面,对于基于短语的统计机器翻译系统,能够从大规模双语预料中选取相应容量的短句,再采用GIZA++对齐训练词。解码器在进行搜索时采用柱搜索法,搜索过程中利用以下特征:①IBM扭曲模型、②方向概率、③短语惩罚、④句子长度惩罚、⑤扭曲概率、⑥n元语法语言模型、⑦双向词汇化概率、⑧双向短语翻译概率。另一方面,对于基于层次短语的统计机器翻译系统,其主要作用是为系统提供参考,从大规模双语预料中训练出翻译模型所需要的双语预料。层次短语统计机器翻译系统的概率计算需要借助短语系统的线性对数,在实际计算过程中使用以下5个特征:①规则特征(如数字、时间以及人名规则等)、②句子长度惩罚、③N-gram语言模型、④两个方向的词汇概率、⑤两个方向的短语概率。
3 实验结果
在实验过程中,根据不同大小、元数划分的语言模型分别输入到基于层次短语的统计机器翻译系统以及基于短语的统计机器翻译系统中进行解码,在解码时上述两个系统中的参数配置不变,翻译模型保持一致,实验不需要对未登陆词进行处理,选取SSMT2007新闻领域测试集为测试集。最后,对最终的翻译结果进行BLEU打分,具体如下表所示:
在上述表格中,两个英汉翻译系统所选用的训练数据一致,并且基于短语的英汉翻译系统的打分值结果比基于层次短语英汉翻译系统BLEU打分结果差。但是不管采用哪种系统,当语言模型大小为4000万句,元数为4元,其表现效果最好,具体的打分情况为0.3509 和 0.4331。通常来说,当增加语言模型规范时,将会提高BLEU打分,但是在实际应用中受到硬件条件的限制,尤其是在内存相对较小的状况下,将会增加训练语料,会对系统造成一定的影响,训练语料增加时应该做好剪裁工作。
4 结论
综上所述,通过相应的实验分析, 我们可以看出来,对于不同系统,并不是扩大规模或者增加语言模型元数,就能够获得良好的翻译效果。而是需要考虑数据稀疏、裁剪等因素,并且在硬件条件允许的条件下,解决数据稀疏问题,并不断扩大语言模型规模,只有这样才能保证翻译结果的准确性。
参考文献:
[1] 王韦华,徐波.汉语语言模型的规模对统计机器翻译系统的影响[J].微计算机信息,2010,26(27):108-109.
[2] 银花.基于短语的蒙汉统计机器翻译研究[D].内蒙古师范大学,2011.
[3] 奚宁,赵迎功,汤光超等.统计机器翻译中多种语言模型的融合[C]//第七届全国机器翻译研讨会论文集,2011:220-228.
[4] 米莉万·雪合来提,麦热哈巴·艾力,吐尔根·依布拉音等.维吾尔语词尾对汉维统计机器翻译影响的研究[J].计算机工程,2014(3):224-227.
[5] 董人菘,王华,张晓钟等.依存句法语言模型对短语统计机器翻译性能的影响[J].计算机科学,2014,41(2):99-101.
[6] Philipp Koehn, Amittai Axelrod, Alexandra Birch Mayne, et al.Edinburgh System Description forthe 2005 IWSLT Speech Trans-lation Evaluation. International Workshop on Spoken Language Translation. 2005.
猜你喜欢
时代英语·高一(2019年1期)2019-03-13
新高考(英语进阶)(2017年10期)2017-12-23
海外华文教育(2016年1期)2017-01-20
海峡姐妹(2016年2期)2016-02-27
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
